Summary
GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning
- 核心: 把 video world model 预测的 future latent + value 作为 VLA 策略的额外条件,把 RECAP 的 sparse advantage RL 升级成 “dense future state + value” 的条件化 RL(RAMP),在 GigaBrain-0.5(10K 小时机器人数据预训练)基础上做 self-improving HIL rollout。
- 方法: 4-stage iterative pipeline——(1) Wan2.2 backbone 的 world model 联合预测 future visual latent + value;(2) 用 (z, I=1[A>ε]) 条件化 fine-tune 策略;(3) HIL rollout 收集数据;(4) 联合 continual training。理论上证明 RECAP 是 RAMP 在 z 上做边缘化的特例。
- 结果: 相比 RECAP baseline,在 Box Packing / Espresso Preparation 等长程任务上 +30% 成功率,接近满成功率;GigaBrain-0.5 (foundation) 在 RoboChallenge 上 51.67% > π0.5 的 42.67%。
- Sources: paper | website | github
- Rating: 2 - Frontier(把 RECAP 推广为 latent-conditioned RAMP 的 reformulation 干净,且在 RoboChallenge / 长程任务上有实证 gain,是当前 world-model-conditioned VLA 必须对比的前沿工作,但概率框架本质是对已有方法的 generalization,不属于奠基级)
Key Takeaways:
- RECAP 是 RAMP 的特例:RECAP 的 π(a|o, I) 在概率上等于 RAMP 的 π(a|o, z, I) 对 z 边缘化的结果。论文用 information gain 论证显式 condition on z 严格优于 marginalize——在 KL 正则化 RL 框架内做了一次干净的推导,是这篇文章最有 insight 的部分。
- World model 同时输出 value + future state 比只出 value 更好:MAE 0.0621 vs 0.0838,Kendall 0.80 vs 0.73,且 0.25s vs 0.11s 推理时间换来的精度收益值得。说明 future prediction 是 value estimation 的隐式 anchor。
- Stochastic attention masking (p=0.2) 让 world model 条件在推理时可选——既能跑 “fast mode”(无 z)也能跑 “deep mode”(有 z)。这是个工程上很务实的 design,避免对 synthetic signal 的 over-reliance。
- HIL rollout 闭环是核心:第 3-4 阶段反复迭代,autonomous rollout + 人工纠错 → continual training,这套 pipeline 才是 30% 提升的真正来源,而不是单一 algorithmic novelty。
Teaser. RAMP 把 world model 预测的 future visual latent 与 value 一并喂给 VLA,闭环 HIL 自我改进。
1 问题与动机
主流 VLA(π0、π0.5、GR00T 系等)从当前观测直接预测 action chunk,存在两个根本性短板:
- Myopic observation:只看当下,缺乏对未来状态的 anticipation;
- Reactive control bias:架构偏向反应式控制而非 prospective planning。
而 web-scale 视频上预训练的 world model 在 spatiotemporal reasoning 和 future prediction 上很强。一个自然的想法:把 world model 的 future latent 作为 condition 注入 VLA,给策略一份 “look-ahead” 的 prior。
❓ 这个 motivation 论文讲得很自然,但实证上 myopic 真的是 long-horizon 失败的主因吗?也可能只是 demonstration 数据覆盖不足。Sec 4.2 的 multi-task 实验显示 world model conditioning 在 multi-task 下增益更大,间接支持了 “knowledge transfer via shared latent” 的解释,但这两种因素难以分离。
2 GigaBrain-0.5(基础 VLA)
GigaBrain-0.5 直接继承自 GigaBrain-0 的 end-to-end VLA 架构:
- Backbone: Mixture-of-Transformers,VLM 部分用预训练的 PaliGemma-2;
- Action head: action DiT + flow matching 预测 action chunk;
- Embodied CoT: 自回归 subgoal 语言 + discrete action tokens(FAST tokenizer 风格)+ 2D manipulation trajectory (用 GRU decoder 从 learnable token 回归);
- Optional state: depth 和 2D trajectory 在本版被设为 optional,方便适配不同传感器。
统一目标:
三项分别是 CoT next-token 预测、flow matching action 损失、2D trajectory 回归。Knowledge Insulation (KI) 防止语言和 action 两条流相互干扰。
预训练数据组成(Fig. 3):10,931 小时——其中 6,653 小时(61%)由 GigaWorld world model 合成(覆盖新纹理 / 视角 / 物体配置),4,278 小时(39%)来自真实机器人。
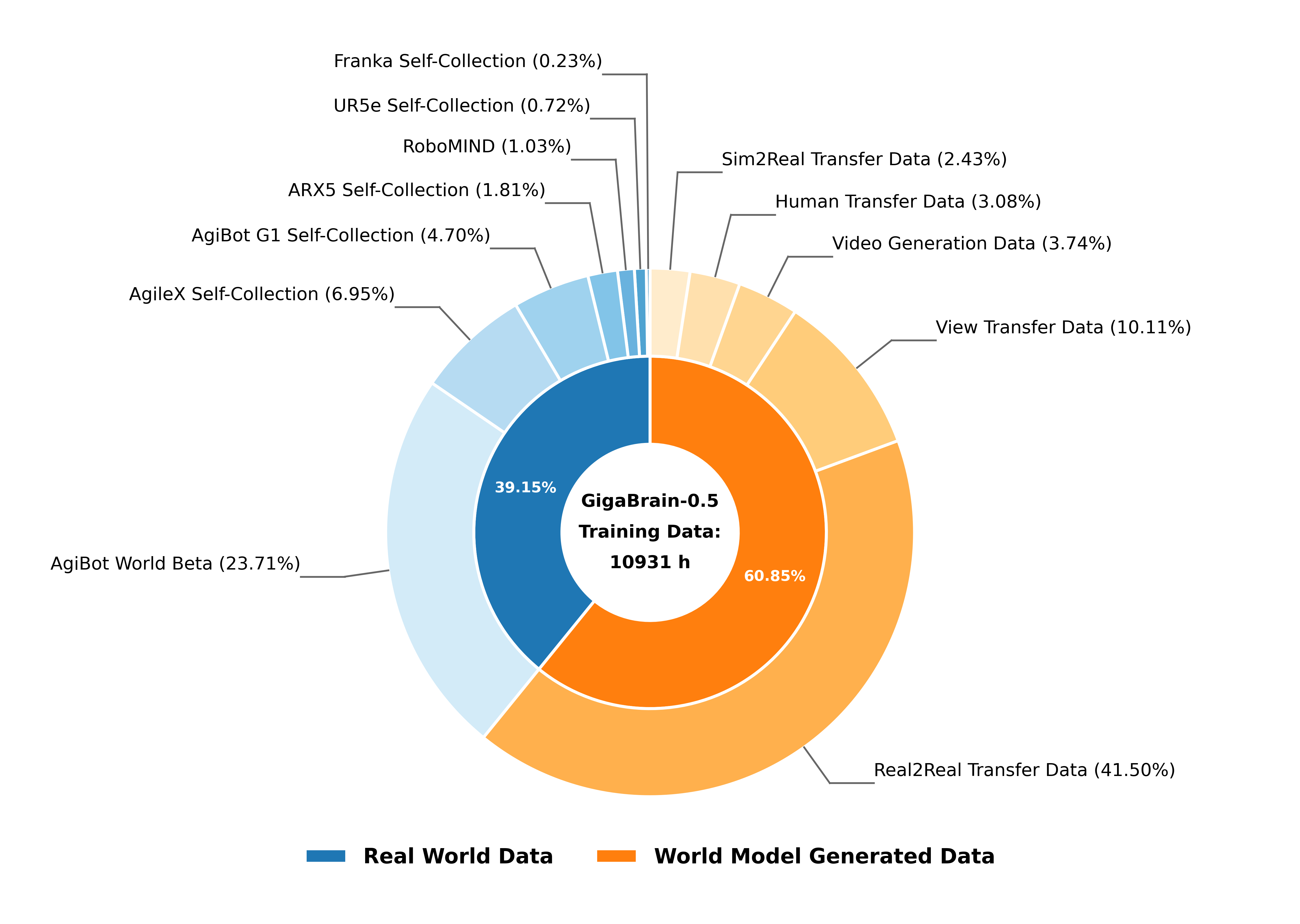
Figure 3. 预训练数据分布——合成数据占了 61%,这个比例在 VLA 文献里相当激进。
❓ 6K 小时合成数据 vs 4K 小时真实数据,这个比例下合成数据是否引入了 bias?论文没给 ablation 单独说明合成数据的边际贡献。
3 RAMP:核心方法
3.1 Formulation
把状态空间扩展为 ,其中 z 是 world model 抽出的 future latent。在 KL-regularized RL 框架下,最优策略闭式解:
为了避开数值不稳定,引入 binary improvement indicator ,假设 ,用 Bayes 把 exponential advantage 重写成条件概率比,最终目标:
RAMP vs RECAP 的核心 claim:
也就是 RECAP 等价于 RAMP 在 z 上做边缘化——RECAP 学到的是个 “average policy”,必须 implicitly compromise 所有可能的 future。RAMP 显式 condition on z,把 “对未来的平均猜测” 转成 “针对特定物理状态的精确规划”。Information-theoretically,。
这是文章最有 insight 的部分。把现有 advantage-conditioned 方法(π*₀.₆ 的 RECAP)放进一个更大的框架里,形式上很干净。
3.2 实现:4-stage pipeline

Figure 2. RAMP 的四阶段 pipeline:world model pre-training → policy training with WM conditioning → HIL rollout → continual training。
Stage 1: World Model Pre-training
按 π*₀.₆ 的做法定义 sparse reward:成功 episode 终止给 0,失败给 ,其余每步 -1。这样 value function 对应 negative expected steps-to-completion。
Latent frame injection:把 value 通过 spatial tiling projection 广播到与 visual latent 同 spatial shape,然后 channel-wise 拼接:
好处:不改 DiT 架构。Future visual obs 取 ,用 pretrained VAE 编码为 。
Backbone 用 Wan2.2,flow matching 训练:
用 4K 小时真机数据训。
Stage 2: Policy Training with World Model Conditioning
从 GigaBrain-0.5 checkpoint 初始化策略,加两路 auxiliary signal:
- Future state tokens ,过轻量 MLP 投影到 visual encoder 输出维度;
- Value-derived advantage via n-step TD:
离散为 binary ,策略以 为条件训练。
两个鲁棒性设计:
- World model 推理时只跑 1 个 denoising step,省算力;
- Stochastic attention masking 以 p=0.2 随机屏蔽 world model token,强制策略在 WM 缺失时仍 robust——后续支持 “fast mode”(无 z)部署。
Stage 3: HIL Rollout Data Collection
部署策略采集 trajectory,混合 autonomous execution + expert intervention。Autonomous rollout 比传统 teleoperation 优势在于:策略生成的是自身分布下的 action,而非模仿人类——distribution gap 更小,supervision 更有效。开发了 “intervention boundary 平滑”软件去掉手动干预带来的 temporal artifact。
Stage 4: Continual Training
用 HILR 数据 + base data 联合训练 world model 和 policy——防止 advantage 全部 collapse 到 0。继续保持 p=0.2 的 stochastic masking,避免 inference-train 的 distribution shift。
Inference 优化策略:固定 (optimistic control)。WM 条件可选:fast mode(mask 掉 future latent)vs standard mode(用 z 做 long-horizon planning)。
4 实验
4.1 GigaBrain-0.5 Foundation Performance
Pre-training:batch=3072,100K steps,FSDP v2 选择性分片 SiglipEncoderLayer 和前 16 层 Gemma2DecoderLayerWithExpert。Post-training:8 个内部任务(Juice Preparation, Box Moving, Table Bussing, Paper Towel Preparation, Laundry Folding, Laundry Collection, Box Packing, Espresso Preparation),batch=256,20K steps。

Figure 4. GigaBrain-0.5 在 8 个内部任务上 vs π0 / π0.5 / GigaBrain-0 的成功率对比。Juice Preparation 100%(GigaBrain-0 90%),Box Packing / Espresso Preparation 比 π0.5 高 10% / 20%,Paper Towel / Laundry Folding / Laundry Collection >80% 且分别比 π0.5 高 15% / 5% / 10%。
RoboChallenge:30 个标准化任务,4 个 platform(UR5、Franka、ARX5、ALOHA),中间版 GigaBrain-0.1 在 2026-02-09 排名第一,平均成功率 51.67% vs π0.5 42.67%。
4.2 RAMP 消融
Q1: WM-based value prediction vs VLM-based?
Table 1. 价值预测对比(A800 GPU 推理,~1M 帧验证集)。
| Model | Inference Time (s) | MAE ↓ | MSE ↓ | RMSE ↓ | Kendall ↑ |
|---|---|---|---|---|---|
| VLM-based | 0.32 | 0.0683 | 0.0106 | 0.1029 | 0.7972 |
| WM-based (value only) | 0.11 | 0.0838 | 0.0236 | 0.1433 | 0.7288 |
| WM-based (state+value) | 0.25 | 0.0621 | 0.0099 | 0.0989 | 0.8018 |
三个发现:(a) VLM-based 最慢(SigLIP encoder bottleneck);(b) WM (value only) 最快但精度差——纯 value 没充分利用 future prediction 能力;(c) 联合预测 state+value 是 sweet spot——精度最佳,速度可接受。说明 future state prediction 给 value estimation 提供了关键的 contextual grounding。

Figure 13. 价值预测可视化:Laundry Folding 中绿色衣物干扰折叠时 value 下降,机械臂移除干扰后 value 回升。这种 “失败-恢复” 的 value 动态正是 RAMP 比 RECAP 的 binary advantage 多出来的信息。
Q2: World model conditioning 提升 multi-task generalization?
控制实验:4 个任务(Table Bussing, Laundry Folding, Paper Towel Preparation, Box Packing),仅用 Stage-2 数据,不引入 rollout data。Single-task:每任务独立 20K steps;Multi-task:均匀混合 60K steps,batch=256。

Figure 14. 单任务 vs 多任务 ± WM condition 的成功率曲线。WM condition 在 5K-20K steps 全程稳定占优;multi-task 设置下 gap 持续扩大,Box Packing 在 20K steps 时差距达 ~30%。说明 world model 是 multi-task 知识迁移的有效介质。
Q3: RAMP vs RL baselines?
对比对象:
- GigaBrain-0.5 + AWR:weighted imitation learning baseline;
- GigaBrain-0.5 + RECAP(π*₀.₆):advantage-conditioned offline RL,相当于 RAMP 去掉 state prediction 的 ablation;
- GigaBrain-0.5 + RAMP = GigaBrain-0.5M*。

Figure 15. 三个长程任务(Box Packing, Espresso Preparation, Laundry Folding)上 RAMP 接近满成功率,Box Packing 和 Espresso Preparation 比 RECAP 高约 30 percentage points。
5 真机部署示例
论文展示了 8 个真实任务的部署,覆盖 PiPER 双臂和 G1 humanoid 两种平台。

Figure 5-12. 真机部署:Box Packing (PiPER), Box Moving (G1), Espresso Preparation (PiPER), Juice Preparation (G1), Laundry Collection (G1), Laundry Folding (PiPER), Paper Towel Preparation (PiPER), Table Bussing (G1)。
Demo Video. Espresso Preparation 长程任务的连续多次成功 rollout。
关联工作
基于
- π*₀.₆ (RECAP):RAMP 的直接 inspiration,论文形式化证明 RECAP 是 RAMP 的特例
- π0 / π0.5:VLA backbone 思路的延续(flow matching action head)
- GigaBrain-0:本文 VLA 架构(MoT + PaliGemma-2 + DiT + Embodied CoT)的直接前身
对比
- AWR:传统 advantage-weighted regression baseline
- RECAP:advantage-only 条件化 RL 的 baseline
- π0.5:foundation VLA baseline,在 RoboChallenge 上对比
方法相关
- Wan2.2:world model backbone(video diffusion)
- Cosmos / cosmospolicy:latent frame injection 策略借鉴
- GigaWorld:合成 6K 小时预训练数据的 world model
- DreamGen / ViDAR:另一类 “world model 生成 future visual trajectory + IDM 推断 action” 的范式(RAMP 走的是 conditioning 路径而非 generation 路径)
- PaliGemma-2:VLM backbone
- Knowledge Insulation (KI):防止 CoT 和 action 优化互相干扰
同方向
- π0.7:同期 VLA 工作
论文点评
Strengths
- RECAP-as-special-case-of-RAMP 的概率推导很干净。这种 “把现有方法变成自己框架的特例” 是正经的 generalization——而不是常见的 “SOTA + 0.3%” 套路。
- Joint state+value prediction 的 ablation 是有信息量的:value-only 反而精度差且鲁棒性弱,说明 future state prediction 不是装饰,而是 value estimation 的隐式 regularizer。
- Stochastic masking 让 world model 条件在推理时可选——直接产生 fast / standard 双模式部署,工程上很务实,比强绑定 WM 的方案更实用。
- HIL rollout 闭环把 “data engine” 写明白了,包括 intervention boundary 平滑这种工程细节,对 reproducibility 比纯算法描述更有价值。
- 多机器人平台真机验证(PiPER 双臂 + G1 humanoid)减少 single-platform overfitting 嫌疑。
Weaknesses
- 方法本质上是 RECAP + future latent injection——novelty 主要在概率框架的 reformulation 和工程实现,algorithmic 增量有限。30% 提升究竟来自 z 还是 HIL rollout 数据本身,没有 isolated ablation(即固定 z 不变,只比较 RECAP 和 RAMP 在同样 rollout pipeline 下的差距)。
- “理论上证明 RECAP 是 RAMP 的特例” 是一个比较弱的 theoretical result:本质就是边缘化 z;这并不能说明 RAMP 一定更好——更高的 conditional entropy reduction 也意味着对 z 质量的敏感性更强。如果 world model 预测有偏,RAMP 反而可能比 RECAP 更脆。论文没讨论这个 failure mode。
- World model 用 Wan2.2 backbone + 4K hours 真机数据——预训练成本极高,复现门槛高于论文表面看起来的 “method swap”。
- RoboChallenge 上对比的是中间版 GigaBrain-0.1(51.67%),不是最终的 GigaBrain-0.5 或 GigaBrain-0.5M*,时间窗(2026-02-09)也很短。“国际榜单第一” 的修辞需要打折。
- 缺少 failure mode 分析:哪些任务即使 RAMP 也失败?world model 预测错时策略行为是什么?这种 negative result 比 30% 提升更有 insight。
- 数据组成 6K 合成 + 4K 真机 缺少边际贡献的 ablation——合成数据的实际 contribution 不清楚。
可信评估
Artifact 可获取性
- 代码: GitHub
open-gigaai/giga-brain-0是 GigaBrain-0 的 repo,未确认本文 GigaBrain-0.5M* 的 RAMP / world model 训练代码是否同 repo 提供。论文未明确说明 RAMP 实现是否开源 - 模型权重: 未在论文或 project page 中说明发布
- 训练细节: 仅高层描述——给了 batch size、step 数、FSDP 选项,但 RAMP 的关键超参(α, β, ε, p, γ, n, , λ)大多未列出
- 数据集: 私有(GigaAI 内部 + GigaWorld 合成);RoboChallenge 数据集 736GB 已开源
Claim 可验证性
- ✅ RAMP > RECAP / AWR 约 30% 提升:Fig. 15 + 真机 demo 视频,可验证(虽然真机评估方差大)
- ✅ WM (state+value) > VLM-based / WM (value-only):Tab. 1 数据齐全,~1M 帧验证集
- ✅ WM conditioning 提升 multi-task generalization:Fig. 14 单/多任务对比直接验证
- ⚠️ “RECAP is a special case of RAMP”:数学上的边缘化等价是对的,但说 RAMP “necessarily better” 隐含了 world model 预测 z 足够准这一前提——论文没量化 z 的预测误差对策略性能的影响
- ⚠️ GigaBrain-0.5 在 RoboChallenge 排名第一:用的是中间版 GigaBrain-0.1,时点 2026-02-09,榜单快速变化;对比基线只列 π0.5
- ⚠️ Self-improving via HIL rollout:闭环描述清晰,但没给迭代轮次 vs 性能曲线,“iterative” 的实际收益不可量化
- ❌ “world’s first large-scale embodied AI evaluation platform featuring real-robot testing”(描述 RoboChallenge):marketing 修辞,不是本文 claim 但顺带带入
Notes
- 这篇文章的核心贡献其实是把 RECAP 的形式化推广到 latent-conditioned setting——从 “advantage-as-condition” 到 “(advantage, world model latent)-as-condition”。从 mental model 角度,RAMP = RECAP + state prior。
- World model 从 “用来生成训练数据”(DreamGen 路线)转向 “作为 inference-time condition”,是值得关注的范式转变。前者扩数据、后者扩信息维度。两者非互斥——RAMP 的 Stage 1 也用了大量真实数据训 world model。
- “Stochastic attention masking 让 condition 可选” 是个值得复用的设计——任何要把 auxiliary signal 注入 frozen backbone 的场景都可以借鉴,避免 train/inference gap。
- ❓ 真正可以推翻 RAMP > RECAP 假说的实验:在同一个 HIL rollout dataset 下,分别训 RAMP 和 RECAP(即 ablate 掉 z),看差距。论文 Fig. 15 的对比看似严格但没说清楚 RECAP baseline 用的是不是同一份 rollout data。
- ❓ World model 推理用 1 步 denoising 就够吗?这个简化假设值得 ablation——多步 denoising 是否能进一步提升 z 质量从而帮助策略?
- 与 DreamGen 的对比很有意思:DreamGen 走的是 “WM 生成视频 → IDM 反推 action”,RAMP 走的是 “WM 提供 latent 作为 policy 的 condition”。前者用 world model 当 data engine,后者当 inference-time auxiliary。这是 world model for VLA 的两条主线。
Rating
Metrics (as of 2026-04-24): citation=3, influential=0 (0.0%), velocity=1.3/mo; HF upvotes=61; github 2491⭐ / forks=193 / 90d commits=12 / pushed 44d ago
分数:2 - Frontier 理由:Strengths 列出的 “RECAP-as-special-case-of-RAMP 概率推导” 和 “joint state+value prediction 的 sweet-spot ablation” 属于 world-model-conditioned VLA 方向上有清晰 insight 的前沿贡献,且 RoboChallenge 上 51.67% vs π0.5 42.67% + 长程任务 +30% 是目前必须对比的 baseline 水准。但方法本质是 RECAP + future latent injection 的 reformulation(Weakness 1),预训练依赖 10K 小时私有数据、代码/权重未明确开源(可信评估),尚未形成方向的 de facto 标准,不够 Foundation;同时又明显不是 incremental/niche,所以不是 Archived。