Summary
Cosmos World Foundation Model Platform for Physical AI
- 核心: 把 “video generative model” 重新定位为 Physical AI 的 world foundation model(WFM),用 pre-training + post-training 范式覆盖 navigation / manipulation / driving 三类下游
- 方法: 完整 stack——20M hour 视频→Ray-orchestrated 5 步 curation 100M clips;causal wavelet-space tokenizer (CV/DV, 4–16× 压缩);同时训 diffusion (7B/14B DiT) 和 autoregressive (4B/12B Llama-style) 两族 WFM;camera/action/trajectory/multi-view 四类 post-training 样例
- 结果: Cosmos-Tokenizer 在 DAVIS PSNR +4dB 且 12× 加速;diffusion-7B 后训 camera-cond 把 SfM 成功率从 43% 推到 82%、轨迹误差 5–8×↓;但物理对齐 (rigid-body benchmark) 大小模型表现接近,揭示 scale 不能直接解决 physics
- Sources: paper | website | github
- Rating: 3 - Foundation(video-based WFM 的 reference platform:开源 tokenizer + WFM 权重已被 CosmosReason1 / HYWorld2 / RoboticWorldModel 等一众后续工作沿用)
Key Takeaways:
- Pre-training + post-training paradigm 适用于 video WFM: 100M clip pre-training 拿 generalist,~10⁴ episode 的 task-specific post-training 拿专家——和 LLM 范式同构,给 robotics 提供了直接复用的 recipe
- Causal wavelet tokenizer 是 underappreciated building block: 在 wavelet 空间搞 video tokenization,时序因果 + 联合 image/video 训练 + FSQ 离散化,重建质量在 4×8×8 压缩下超过 CogVideoX/Omni-Tokenizer 4 dB PSNR,模型还更小更快——可直接被下游 video LLM/world model 借用
- Diffusion vs Autoregressive WFM 结论清晰: 同样数据下 diffusion 视觉质量、3D consistency、物理对齐均更好;AR 的优势是和 LLM 工具链对齐 (KV cache、Medusa、TP/SP),5B 模型可达 10 FPS 实时生成
- Physics alignment 仍未解: 在 Isaac Sim 8 个刚体场景上,4B→14B 模型物理对齐指标几乎不变,仅视觉质量随 scale 提升——说明 “scale + 视频数据” 不够,需要更明确的 physics-aware curation 或 inductive bias
- Open-weight 撬动整个 Physical AI 生态: 7 个 tokenizer + 8 个 WFM checkpoint 在 NVIDIA Open Model License 下放出,等于 “stable-diffusion moment” for video world models,后续 RoboticWorldModel/CosmosReason1/HYWorld2 都建立在这条 stack 上
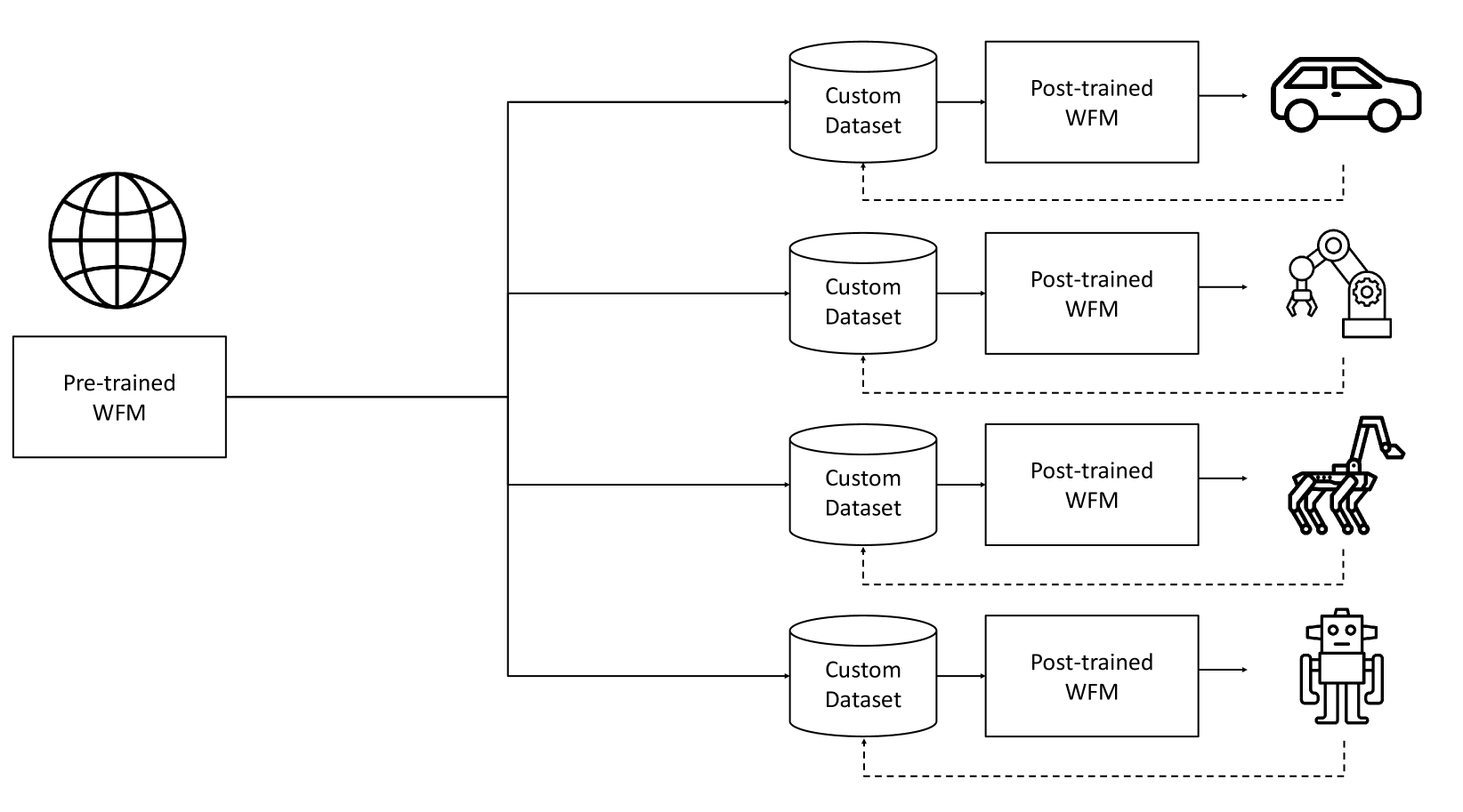
Teaser. Pre-training-and-post-training paradigm. 大规模视频 pre-train 出 generalist WFM,再用 target Physical AI 的小数据 post-train 出 specialist;条件信号可以是 action / trajectory / instruction。
1. Problem & Positioning
Physical AI(带传感器和执行器的 AI 系统)的核心 bottleneck 是数据:动作-观测交错的训练数据收集成本极高,且 exploratory action 可能损坏硬件。一个准确的 World Foundation Model (WFM) 可作为物理世界的 digital twin,让 agent 在虚拟世界里安全交互。
WFM 的形式定义:
其中 是过去 RGB 观测, 是 perturbation(action / text / trajectory…)。Cosmos 把 WFM 落到 visual world(视频)上。
论文列了 5 类潜在 use case:policy evaluation、policy initialization、policy training (model-based RL)、planning / MPC、synthetic data generation。作者诚实地写道:“this paper does not include empirical results in applying Cosmos WFMs to them”——即只交付了 platform 本身,downstream 验证留给社区。
❓ 这种 “platform paper” 模式的双刃剑:覆盖广但每一个 component 都没做穷尽的 ablation;后续要看社区能否把 Cosmos 真的接到 robot policy training loop 里。
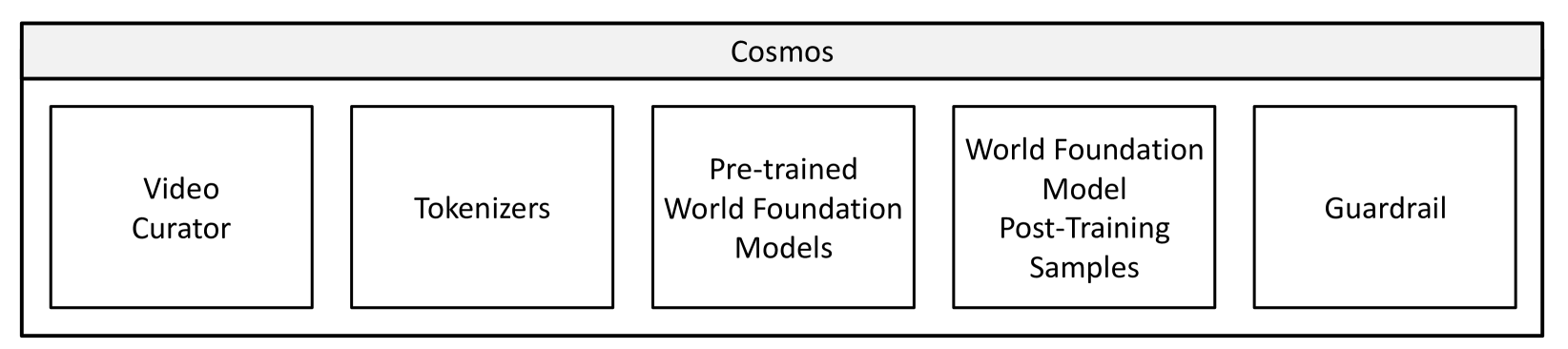
Cosmos Platform 总览(Fig. 4 的 5 个 component):video curator → video tokenizer → WFM pre-training (Diffusion 系 + AR 系) → WFM post-training (camera / action / multi-view) → guardrail。
2. Data Curation: 20M hours → 100M clips
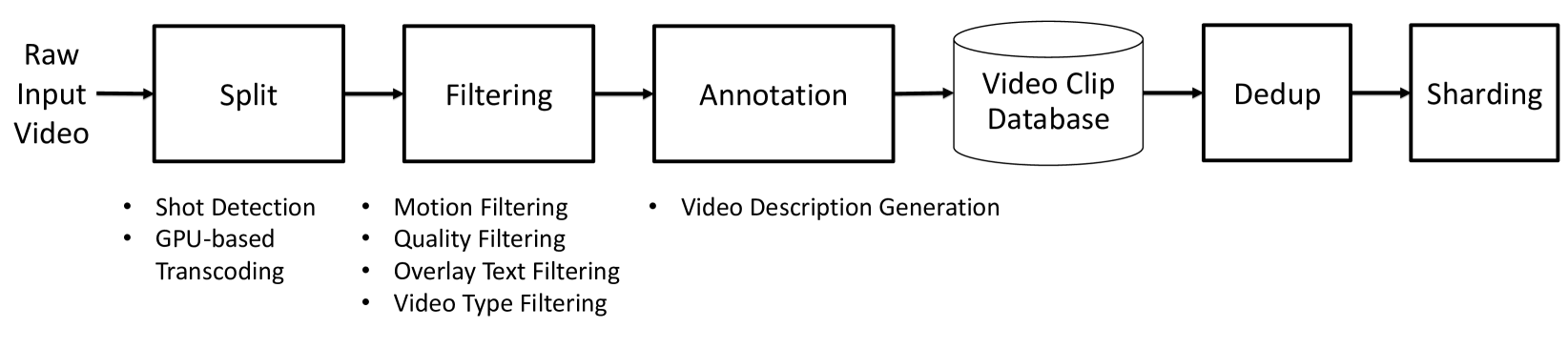
数据是 ceiling。Pipeline 5 步:splitting → filtering → annotation → deduplication → sharding。用 AnyScale Ray 做地理分布式 streaming 编排,把 NVDEC、网络带宽、GPU compute 三类资源并行起来。
目标视频分布(按 Physical AI 应用裁剪):driving 11%、hand/object manipulation 16%、human motion 10%、first-person 8%、nature dynamics 20%、dynamic camera 8%、synthetic 4%、其他 7%。
关键技术决策
- Splitting:自建 ShotBench 比较了 PySceneDetect / Panda70M / TransNetV2 / AutoShot;TransNetV2 (神经网络) 在 BBC F1 0.967 / SHOT 0.821 全面领先 hand-crafted feature 的 PySceneDetect (BBC F1 0.889 / SHOT 0.718)
- Transcoding:H100 没 NVENC、L40S 有;用 PyNvideoCodec 替代 ffmpeg 把吞吐拉到 6.5×(0.0574 → 0.3702 videos/s)。这种 “infrastructure detail” 看似无关 ML,但决定了能不能 scale 到 100M clips
- Captioning:试了 VFC / Qwen2-VL / VILA,最后用内部 13B VILA + FP8 TensorRT-LLM,吞吐相比 PyTorch FP16 提升 10×(49.6 → 470.6 tokens/s);prompt = “Elaborate on the visual and narrative elements of the video in detail”,平均 caption 559 字符 / 97 词
- Filtering:DOVER 视觉质量去掉 bottom 15%、image aesthetic 阈值 3.5、InternVideo2 embedding + MLP 检测 text overlay、video type classifier 上采样 human action / 下采样 nature
- Dedup:SemDeDup + DataComp 思路;InternVideo2 embedding 跑 GPU k-means (k=10000),去掉 ~30% 数据
- Sharding:webdatasets 按 resolution / aspect ratio / length 分桶,对齐训练 curriculum
❓ “用一个 proprietary VLM 作为 ground-truth labeler” 在多个 step 重复出现 (text overlay、video type、scene caption)。这把 VLM 的 bias 放大成了整个数据集的 bias,虽然论文承认了这点但没量化影响。
3. Cosmos Tokenizer: Causal Wavelet AE/FSQ
这是论文里最 reusable 的 building block。 同一架构同时支持 image+video、continuous+discrete,4 种组合都覆盖。
设计要点
- Encoder-decoder + 时序因果:所有 stage 只看当前和过去帧,使其 “天然适配 Physical AI 的 causal world”,且 “image = single-frame video” 让 image / video joint training 成立
- Wavelet space 操作:先做 2-level wavelet 变换把 input 分组下采样 4×(沿 x/y/t),后续 layer 在更紧凑的表示上做 semantic compression
- Spatio-temporal factorized:3D conv 拆成 1×k×k 空间 + k×1×1 时间(causal padding),attention 也是因子化的;用 LayerNorm 而非 GroupNorm 避免 latent space 出现局部高 magnitude
- Continuous vs Discrete:continuous 用 vanilla AE(latent dim=16),不带 KL prior;discrete 用 FSQ (Finite-Scalar-Quantization),levels=(8,8,8,5,5,5),vocab=64,000,不需要 commitment loss
- 训练:两阶段——L1 + VGG perceptual → 加 optical flow loss + Gram matrix loss + 大压缩率下的 adversarial loss
Capability 对比
Table 4: 视觉 tokenizer 能力对比——Cosmos-Tokenize1 是唯一全勾的(causal、image、video、joint、discrete、continuous)
| Model | Causal | Image | Video | Joint | Discrete | Continuous |
|---|---|---|---|---|---|---|
| FLUX-Tokenizer | - | ✓ | ✗ | ✗ | ✗ | ✓ |
| Open-MAGVIT2 | - | ✓ | ✗ | ✗ | ✓ | ✗ |
| VideoGPT-Tokenizer | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ |
| Omni-Tokenizer | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| CogVideoX-Tokenizer | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ |
| Cosmos-Tokenize1 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
关键结果
DAVIS 上 Cosmos-Tokenize1-CV4×8×8 拿 PSNR 35.85 / SSIM 0.920 / rFVD 10.057,分别比 CogVideoX-Tokenizer4×8×8 (29.29 / 0.864 / 19.58) 高 +6.5 dB PSNR、低 50% rFVD。Runtime:720p video tokenizer 比 CogVideoX 快约 12×(414 ms → 34.8 ms / frame),且参数量从 216M 降到 105M。
💡 这种 “更小、更快、更好” 的组合在 ML 论文里少见,通常是某种被低估的 prior(causal + wavelet)发挥了作用。
4. WFM Pre-training: Diffusion + Autoregressive 两条路线
用 10,000 H100 GPU 训了 3 个月。两条路线 head-to-head 对比,难得。
4.1 Diffusion-based WFM (Cosmos-Predict1-7B/14B)
架构总览
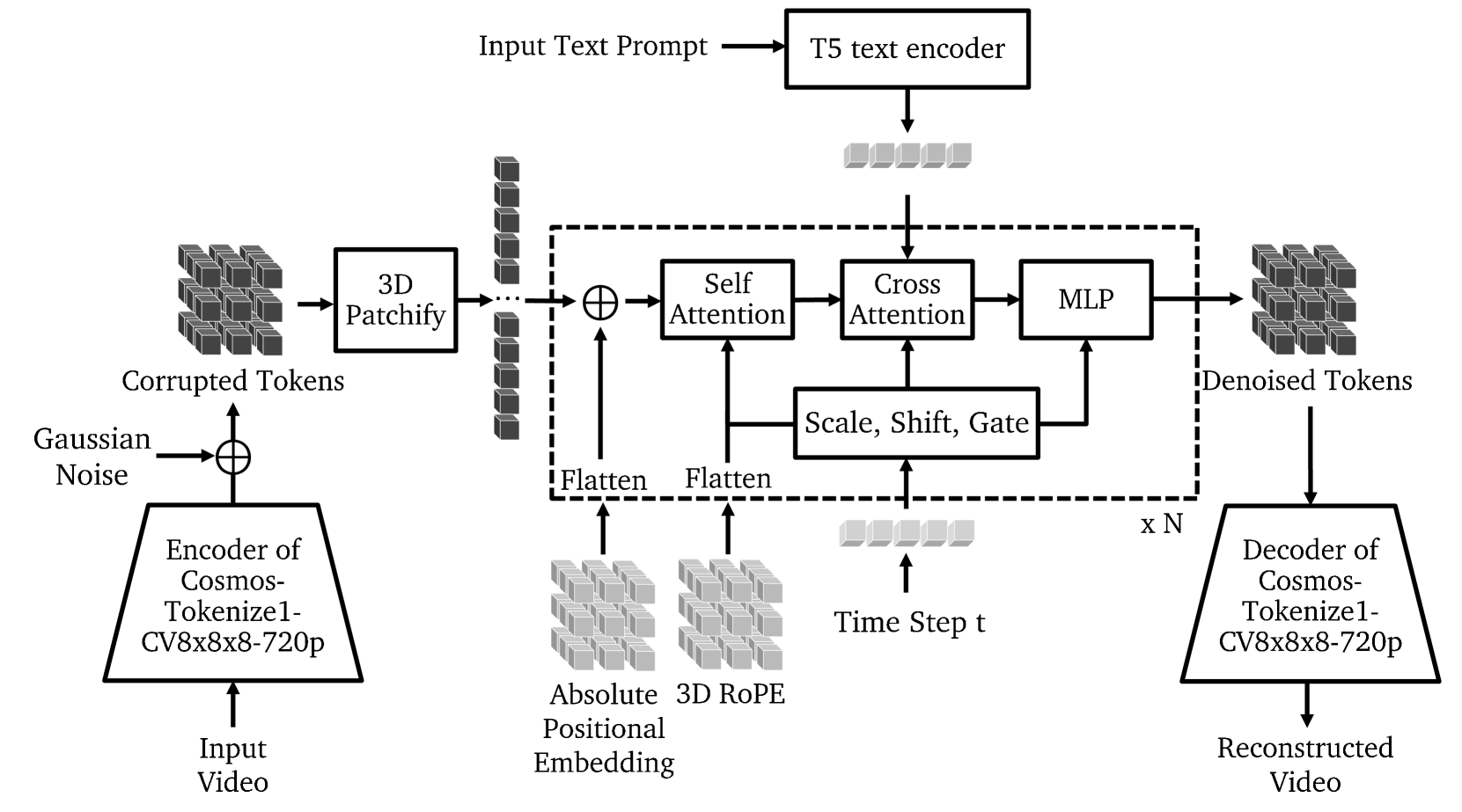
- Formulation:EDM 风格 score matching + uncertainty-based loss weighting (用 MLP 参数化);理论上和 flow matching 等价
- Architecture:DiT-based denoiser
- 3D patchification ()
- Hybrid positional embedding:3D-factorized RoPE + learnable absolute embedding;FPS-aware (rescale temporal frequency);NTK-RoPE 用于 progressive 训练时分辨率切换
- Cross-attention with T5-XXL for text conditioning
- QK-Norm (RMSNorm) 防止 attention logit 爆炸
- AdaLN-LoRA:把 DiT 的 AdaLN 用 LoRA 低秩近似,参数量 11B → 7B(降 36%)而性能不变
- Training strategy:
- Joint image+video training,domain-specific normalization 对齐 image / video latent 分布
- Video batch noise 按 √frame_count scale up 补偿温度冗余导致的小梯度
- Progressive: 512p/57f → 720p/121f → high-quality fine-tune
- FSDP (sharding 32 for 7B, 64 for 14B) + Context Parallelism (CP_SIZE=8)
- Prompt Upsampler (Cosmos-UpsamplePrompt1-12B-Text2World):基于 Mistral-NeMo-12B-Instruct fine-tune,把短的 user prompt 升级到 train-time long caption 分布
4.2 Autoregressive WFM (Cosmos-Predict1-4B/12B)
架构总览
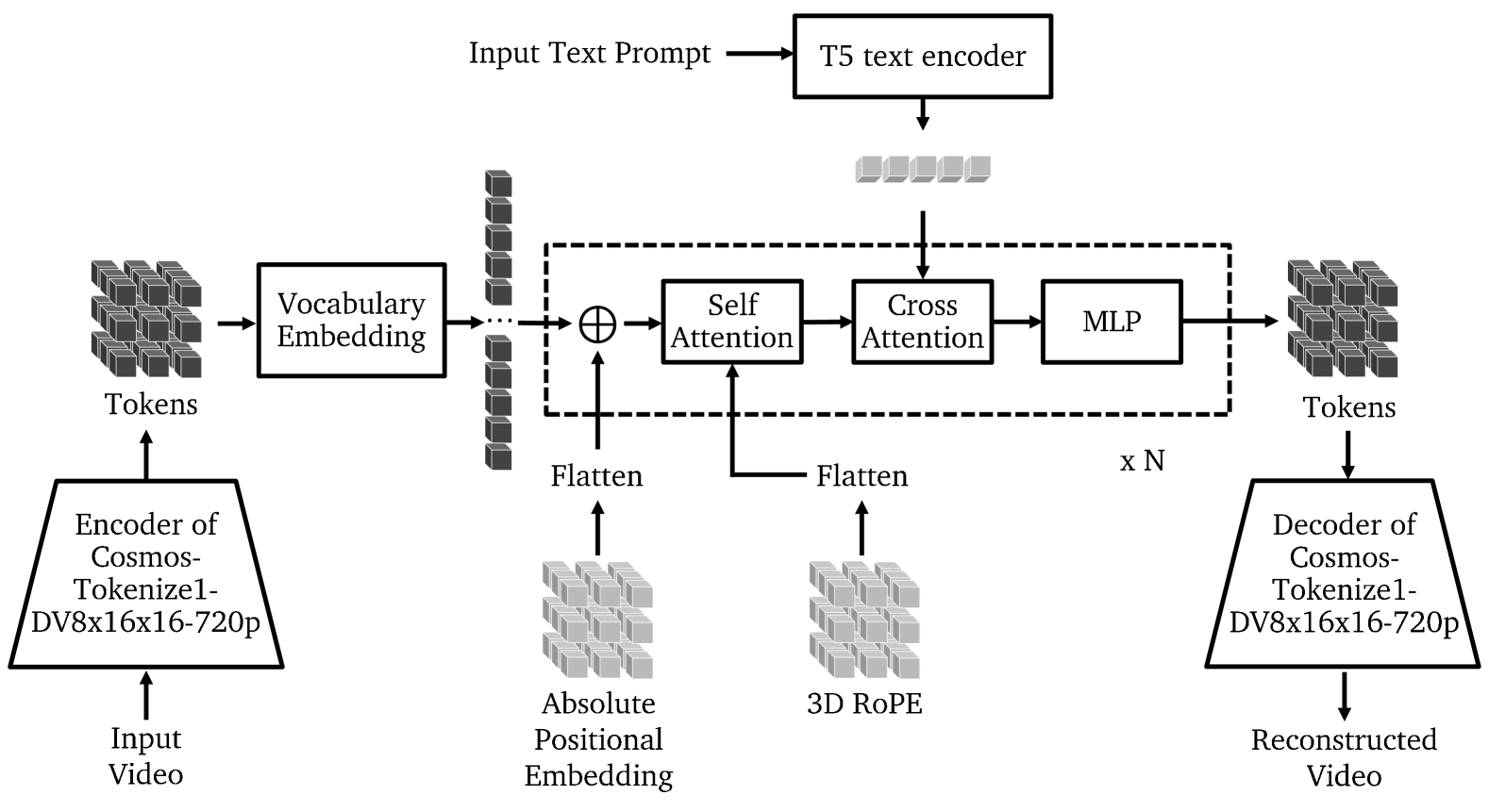
- Setup:next-token prediction with NLL loss,token 来自 Cosmos-Tokenize1-DV8×16×16 (vocab 64k);Llama3-style 架构
- 3D RoPE + 3D APE (sinusoidal):APE 直接加到 input tensor;YaRN 沿时间轴做 RoPE context extension
- Cross-attention with T5-XXL for optional text conditioning
- QKNorm + Z-loss () 防止 logit 发散,训练稳定性的 critical 选择
- Multi-stage training:
- Stage 1: 17 frame video prediction
- Stage 1.1: 34 frame,YaRN 扩 context
- Stage 2: 加 cross-attention 接入 text
- Cooling-down: linearly decay LR to 0 on high-quality data
- Inference 优化:
- Medusa speculative decoding:fine-tune 时只解冻最后两层 transformer + unembedding(避免 catastrophic forgetting),9 个 Medusa head 是 sweet spot;4B 模型 token throughput 从 444 → 894 tokens/s
- 低分辨率适配:320×512 + Medusa,4B 模型实现 10 FPS real-time
- Diffusion Decoder:用 Cosmos-Predict1-7B-Text2World fine-tune 成 DV8×16×16 → CV8×8×8 → RGB 的解码器,把 AR 模型的 blurry 输出 sharpen——典型的 “AR 提供 control, diffusion 提供质量” 的 hybrid
Table 14: AR 模型 config
| Config | 4B | 5B-V2W | 12B | 13B-V2W |
|---|---|---|---|---|
| Layers | 16 | 16 | 40 | 40 |
| Model dim | 4,096 | 4,096 | 5,120 | 5,120 |
| Cross-attn | ✗ | ✓ | ✗ | ✓ |
| Vocab | 64,000 | 64,000 | 64,000 | 64,000 |
| Activation | SwiGLU | SwiGLU | SwiGLU | SwiGLU |
4.3 Pre-training Evaluation: 3D Consistency 和 Physics Alignment
3D Consistency (RealEstate10K static scenes)
用 epipolar geometry (Sampson error + 相机姿态恢复成功率) 和 view synthesis (3DGS hold-out PSNR/SSIM/LPIPS) 衡量。
Table 19:Cosmos-Predict1-7B-Text2World 拿到 Sampson 0.355 / 姿态恢复成功率 62.6% / hold-out PSNR 33.02——逼近 real video reference (0.431 / 56.4% / 35.38),远超 VideoLDM baseline (0.841 / 4.4% / 26.23)。
⚠️ Sampson error 比 real video 还低 (0.355 vs 0.431) 是个有意思的信号——可能 Cosmos 生成的 “假静态场景” 比真视频更几何 consistent,因为没有动态物体扰动。值得追问。
Physics Alignment (Isaac Sim + PhysX,8 个 rigid body 场景)
8 个场景:free-fall、tilted slope、U-slope、stable stack、unstable stack、dominoes、seesaw、gyroscope。各 100 次 rollout,4 个相机视角。指标:PSNR/SSIM (pixel)、DreamSim (feature)、SAMURAI 追踪后的 IoU (object)。
Table 20 关键观察:
- 9-frame 条件 vs 1-frame 条件,object IoU 翻倍(0.33 → 0.59 for 7B-V2W),动力学需要看到速度、加速度
- 大小模型物理对齐基本无差:7B 和 14B 在 Avg.IoU 上接近 (0.592 vs 0.598 with 9-frame),AR 模型 4B/12B/13B 也都在 0.48–0.49 区间
- Diffusion ≥ AR 在 9-frame pixel-level (PSNR 21.06 vs 18.13 for 4B)
这是论文最 honest 的负面结果——作者明说 “all the WFMs equally struggle with physics adherence and require better data curation and model design”。Scaling-only 不能解决 physics。
5. Post-training Showcases
5.1 Camera Control (Cosmos-Predict1-7B-Video2World-Sample-CameraCond)
- Data: DL3DV-10K + GLOMAP SfM 获取相机姿态
- Method: Plücker embedding 沿 channel 维 concat 到 latent
- Result vs CamCo (DL3DV→RealEstate10K cross-domain):
| Method | SfM 成功率 ↑ | Rotation err ° ↓ | Translation err ↓ | FID ↓ | FVD ↓ |
|---|---|---|---|---|---|
| CamCo | 43.0% | 8.277 | 0.185 | 57.49 | 433.24 |
| Cosmos-CameraCond | 82.0% | 1.646 | 0.038 | 14.30 | 120.49 |
跨 domain 仍能 generalize,joystick-like 控制 (forward/backward/rotate) 即可生成 navigable 3D world。
5.2 Robotic Manipulation
两个任务、两个 dataset:
- Instruction-based prediction (Cosmos-1X dataset, 200h egocentric humanoid): text → video,T5 embed 进 cross-attention。Cosmos-7B-Sample-Instruction 在 23 episode human eval 拿 78.3% overall preference vs VideoLDM 13.0%
- Action-based next-frame (Bridge dataset): 7-DoF gripper action via embed MLP;7B-Sample-ActionCond: PSNR 21.14 / SSIM 0.82 / FVD 190 vs IRASim baseline 19.13 / 0.64 / 593
💡 7B 加 action 后 FVD 直接降 3×——和 IRASim 的对比说明 pre-trained WFM 的视觉先验对 action-conditioned 视频预测帮助巨大。这正面支持了 “pre-training + post-training” 范式可移植到 VLA-style 任务。
5.3 Autonomous Driving (multi-view)
- Data: 内部 RDS dataset,3.6M × 20s clips,6 路 surround camera,按 weather/illumination/speed/road type 平衡采样
- Architecture mod:
- View-independent positional embedding + 单独的 view embedding(避免硬编码 view dim 到 RoPE)
- View-dependent cross-attention:每个 view 只 attend 自己的 caption(每 view 单独 caption)
- 3 个 model 串联:Text2World-MultiView → +TrajectoryCond / →Video2World-MultiView 用于延长
Table 24/25: vs VideoLDM-MultiView baseline,FID 60→32、FVD 884→210、TSE 1.24→0.68、CSE 6.48→2.11;trajectory following error 仅比 GT oracle 大 ~7 cm。
6. Guardrails
Pre-Guard:keyword blocklist + Aegis (LlamaGuard fine-tune) 13 类安全分类。Post-Guard:SigLIP embedding + MLP 帧级安全分类 + RetinaFace 人脸像素化 (>20×20)。Red team 已测 10,000+ prompt-video pair。
部分 Physical AI 用户(自动驾驶、机器人)需要的 “safety” 和这里的 “content safety” 是两件事——前者关心 physically dangerous behavior,后者关心 social harm content。Cosmos 的 guardrail 解决的是后者。
关联工作
基于
- Genie: 早期 generative interactive environment / world model 想法的原型,Cosmos 是 video-scale 工业化版本
- EDM (Karras et al.): diffusion 部分的 score matching + preconditioning formulation 来源
- DiT (Peebles & Xie): 扩散 backbone 直接来自 DiT,加 LoRA-AdaLN、3D RoPE、cross-attention
- FSQ (Mentzer et al.): 离散 tokenizer 的 quantizer 选择
- Llama-3 / Llama-style: AR WFM 架构基本是 Llama
- Medusa: AR 推理加速框架
- VILA / InternVideo2: caption 和 embedding 用于 data curation
- T5-XXL: 文本 encoder
- Mistral-NeMo-12B: prompt upsampler base
- Pixtral-12B: video2world prompt upsampler
- Aegis / Llama-Guard / SigLIP / RetinaFace: guardrail 组件
对比
- VideoLDM: 几乎所有任务的 baseline——3D consistency、camera control、multi-view driving、robotic instruction following
- CamCo: camera-controllable video generation 的 SOTA
- IRASim: action-based next-frame prediction baseline (Bridge dataset)
- CogVideoX / Omni-Tokenizer / FLUX-Tokenizer / VideoGPT-Tokenizer / Open-MAGVIT2 / LlamaGen-Tokenizer: tokenizer 比较
- HunyuanVideo / MovieGen: 训练并行策略 (TP/SP) 对比
- Sora / Dream Machine / Gen-3 / Kling: video generation SOTA, qualitative reference
方法相关
- World Model domain map: Cosmos 是当前 video-based WFM 的 reference implementation
- World Model Survey: 综述里 “video-as-world” 路线的代表
- π0 / OpenVLA / VLA models: Cosmos 提供的是 video prediction backbone,VLA 是 policy backbone;二者天然互补
- CosmosReason1 / HYWorld2 / OpenWorldLib / WorldVLALoop: 后续基于或对标 Cosmos 的工作
论文点评
Strengths
- 完整的 platform thinking:data → tokenizer → 两类 WFM → 4 类 post-training → guardrail,每一层都给了 reusable artifact,这是 “stable-diffusion moment for video world models” 的工程基础
- Causal wavelet tokenizer 是 underrated 的 building block:joint image-video、causal、4 种组合全覆盖,DAVIS PSNR +4dB 还快 12×、参数更少。后续工作直接受益
- Diffusion vs AR head-to-head 对比有 evidence:在同一 platform 下用同样数据训两条路线,得出 “diffusion 视觉质量胜,AR LLM 工具链友好” 的清晰结论;hybrid (AR + diffusion decoder) 设计 elegant
- 诚实交付负面结果:Physics alignment ablation 明说 scale 不解决问题,failure case (autoregressive object 凭空冒出) 和量化的 failure rate(Tab. 18)都给出
- Open-weight + permissive license:8 WFM checkpoints + 7 tokenizers + curated benchmarks (TokenBench),下游研究 (CosmosReason1、HYWorld2、RoboticWorldModel 等) 已建立其上
Weaknesses
- 没有任何 downstream Physical AI 闭环验证:论文列了 5 类 use case (policy eval / init / training / planning / synthetic data),但 “this paper does not include empirical results in applying Cosmos WFMs to them”。所以 “general-purpose world model” 在 control loop 里到底有多 useful,论文里完全没数据——这是平台论文的硬伤
- Pre-training 数据完全不可见:20M hour 视频 + 100M clip,配比、来源、版权都是黑箱;很多 filtering / labeling 步骤依赖 “proprietary VLM”,无法复现也无法审计 bias
- Physics alignment 评估太窄:8 个 rigid-body 场景由 Isaac Sim 生成,scale-不变性可能恰恰因为这 8 个场景对所有模型都 OOD;缺 fluid / cloth / contact-rich / 多物体长时序的 benchmark
- Tokenizer benchmark 是自建的 (TokenBench):虽然 “正式 release”,但和现有 benchmark 不重叠的 metric 提升不能完全外推;DAVIS 上的 +4dB 还算 standard
- “Cosmos-0.1-Tokenizer” vs “Cosmos-Tokenize1” 命名混乱,反映出是技术报告而非精修论文——多个版本的 tokenizer 同时报告,读者需要仔细分辨
- Compute scale 不是 academic-reproducible:10,000 H100 × 3 个月。即使开源权重,自己 pre-train 一遍仍是 NVIDIA-only
可信评估
Artifact 可获取性
- 代码: inference + post-training(cosmos-predict1 repo 提供 inference 和 fine-tuning 脚本,不含 pre-training pipeline)
- 模型权重: 已发布 8 个 WFM checkpoint (Cosmos-Predict1-{4,5,7,12,13,14}B 各种变体) + 7 个 Tokenize1 checkpoint,NVIDIA Open Model License (commercially permissive)
- 训练细节: 仅高层描述——hyper-parameter 给到 Tab. 11/14,但 data mix 比例、cooling-down 配方、Medusa fine-tune 细节都不完整
- 数据集: 部分公开——pre-training data 私有 + 内部 1X / RDS dataset 不开放;TokenBench、Bridge / DL3DV-10K / RealEstate10K 评估数据公开
Claim 可验证性
- ✅ Cosmos Tokenizer 在 DAVIS / TokenBench 上的 PSNR/SSIM/rFVD 优势:Tab. 5–9,metric 标准、baseline 公开
- ✅ Camera control 的 SfM-based 评估 (82% vs 43%):Tab. 22,方法可复现
- ✅ Action-conditioned video on Bridge: Tab. 23,标准 dataset + 公开 baseline IRASim
- ✅ Medusa 加速 (~2× throughput for 4B): Tab. 15,用公开 H100 硬件可复测
- ⚠️ “Generalist WFM that fine-tunes to any Physical AI”:定性 claim,缺真实 robot 闭环数据;camera/action/multi-view 三个 showcase 都是 video prediction quality 而非 control 任务成功率
- ⚠️ Physics alignment metric:自定义 8 个场景,IoU 通过 SAMURAI 跟踪 GT 实例 mask 算——这种 metric 设计可能 systematically underestimate 大模型,因为视觉质量提升反而让 tracking failure 减少但 mask 不一致
- ⚠️ “3D consistency 接近 real video”: Sampson error 0.355 比 real video 0.431 还小,需要追问是否 artifact(生成视频可能 “过度一致”)
- ❌ “first general-purpose world foundation model platform”:Genie / WorldDreamer / DriveDreamer 等已在做类似事;“first” 是营销用语
- ❌ “will accelerate Physical AI development”: prospective claim,论文内无证据
Notes
- 个人判断: 这是 video world model 领域的 reference platform——(1) 改变了我对 “world model 工程可行性” 的判断,从 “学术 toy” 到 “可以跑 100M clip pre-training 的工业 stack”;(2) Causal Wavelet Tokenizer 是 reusable building block;(3) 在 VLA / world model 方向写 related work 时几乎必引
- 最值得追的 follow-up:
- Cosmos WFM 在真实 robot policy training loop 里的 reward shaping / planning utility——目前完全是 promise
- Physics alignment 不随 scale 提升的根因——是 data curation、loss formulation 还是 architecture inductive bias 的问题?
- AR + diffusion decoder hybrid 是否能进一步压缩到 mobile / edge 推理
- 对 VLA 研究的 implication: 用 Cosmos pre-trained WFM 给 VLA 做 future-frame supervision (类似 GR-2 思路) 可能是 cheap 的 pre-training augmentation
- 对 spatial intelligence 的 implication: 3D consistency 评估方法(SfM 成功率 + 3DGS hold-out)可作为 video-based spatial reasoning 的 evaluation primitive,比传统 FVD 更 task-relevant
- 疑问:
- 100M clip pre-training 中 driving + robotics 占比仅 ~30%,剩下大量 nature / human motion 数据对 Physical AI 任务到底贡献多少?没有 ablation
- Wavelet transform 是 fixed (不学习) 还是 learnable?论文写 “2-level wavelet transform” 暗示 fixed,但没说清
- Diffusion decoder fine-tune 用了多少数据?这是 AR pipeline 的关键最后一步,论文叙述偏简略
Rating
Metrics (as of 2026-04-24): citation=547, influential=84 (15.4%), velocity=35.29/mo; HF upvotes=82; github 441⭐ / forks=79 / 90d commits=0 / pushed 108d ago
分数:3 - Foundation 理由:已成为 video-based world model 方向的 reference platform——笔记里的 Strengths 1/5 指出 tokenizer + WFM 的开源 stack 已被 CosmosReason1 / HYWorld2 / RoboticWorldModel 等后续工作直接沿用(关联工作段亦列出),且 GitHub 上 cosmos-predict1 获得数千 star、被主流 VLA/WFM 调研(含 World Model Survey)作为代表性 citation。相比 2 - Frontier 档,Cosmos 不仅是 SOTA baseline,还提供了 de facto building block(causal wavelet tokenizer、7B/14B DiT、4B/12B AR)给下游复用;相比同档 Foundation,虽然 Weakness 1 点出缺 control-loop 闭环验证,但其 platform 属性本身已使其在方向脉络中处于必读位置。