Summary
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
- 核心: 提出 Embodied-Native VLA 范式——physical data 从训练伊始就作为一等公民,而非事后 fine-tune;统一 manipulation 与 navigation
- 方法: Qwen3-1.7B VLM + Flow Matching action expert(共 ~2B params);三阶段 pipeline(pretraining 1.2T tokens / mid-training 200M / post-training 50M);gradient decoupling 保护 VLM 语义;Spatial Scaffolding 做 subtask→bbox→trajectory→action 的 CoT
- 结果: RoboChallenge Table30 Specialist 62.0% SR(超 GigaBrain-0.1 +10%)、Generalist 37.3% SR(远超 π0.5 17.67%),且仅 2B 参数小于 3-4B 竞争对手
- Sources: paper | github
- Rating: 2 - Frontier(Embodied-Native 范式 + gradient decoupling 是当前 VLA 研究前沿的重要参考,在 RoboChallenge 上以 2B 参数击败 3-4B 竞品;但 core claim 缺 controlled ablation 且发布时间过短,尚未成为 de facto 基线)
Key Takeaways:
- Embodied-Native vs Pretrain-then-Adapt: 把 embodied data 在 pretraining 阶段就和 web/driving 一起喂入,而不是在 internet-pretrained VLM 上 fine-tune。论文的核心 claim 是后者缺少 intrinsic physical grounding
- Gradient Decoupling 解决 catastrophic forgetting: 受 Knowledge Insulation 启发,action expert 的梯度不回传 VLM;同时 VLM 继续在 non-embodied data 上更新,保留 general reasoning
- Spatial Scaffolding 是 spatial CoT for action: 层级监督 subtask→goal bbox→EEF trajectory→discrete action,构成从 high-level semantic 到 low-level control 的 coarse-to-fine 课程
- Parameter efficiency: 2B 模型在 specialist 和 generalist 两种设定下都击败 3-4B 的 π0.5、GigaBrain-0.1、Spirit-v1.5
- 统一 manipulation + navigation: 通过 Habitat 数据 + 统一 action 表征在单一 framework 内同时支持两类任务,避免现有系统的模块割裂
Teaser. DM0 framework overview——unified pretraining over web / driving / embodied corpora 后衔接 mid-/post-training。
Model Architecture
Figure 2. Model architecture. DM0 由 (i) Qwen3-1.7B + Perception Encoder 构成的 VLM backbone,与 (ii) 基于 Flow Matching 的 action expert 组成(架构借鉴 π0)。VLM 输出 embodied reasoning text + KV cache,action expert 消费 KV cache 产出 continuous robot actions。Multi-view images 缩放到 728×728 后送入 PE,再用两层 3×3/stride-2 conv 做 4× 下采样。
推理时支持两种模式:(a) 直接从多模态观测+language 预测 continuous action;(b) 先生成文本 reasoning 再让 action expert 条件化生成动作。Joint 分布因子化为:
符号说明: 长度 的 continuous action 序列; 多模态观测(视觉 + 本体感知); 任务指令; 模型预测的 reasoning text。
Multi-Source Hybrid Training
针对 “joint optimization of language + control objectives 会侵蚀 VLM 语义表征” 的核心矛盾,DM0 采用梯度解耦策略(受 Knowledge Insulation 启发):embodied data 上 action expert 的梯度不回传 VLM;non-embodied data 上 VLM 正常更新。同时 VLM 也被监督预测 discrete action tokens,使其内部表征 encode action-relevant semantics。
两个监督目标的损失函数:
VLM 的 autoregressive loss(监督 reasoning text + discrete action tokens):
Action expert 的 Flow Matching loss:
符号说明: ground-truth action 序列; 加噪 action; 高斯噪声; flow time。
总损失 ,joint training 时 。
Embodied Spatial Scaffolding
层级化辅助监督,让模型按 abstraction level 顺序产出:
- Subtask prediction:把整体任务分解为可解释的子步骤
- Goal bounding box prediction:在 visual input 中定位目标物体/区域
- End-effector trajectory prediction:在 primary camera view 中预测 EEF 轨迹
- Discrete action prediction:输出离散 control tokens
理论动机:每一级目标都是一个 task-aligned inductive bias / structured information bottleneck,逐步压缩 hypothesis space——subtask 编码 high-level intent,goal box 强制 object-centric grounding,trajectory 对齐 action-relevant geometry。这是把 LLM 的 CoT 范式系统化引入 low-level control 的尝试。
❓ 这个 scaffolding 是 hard sequential(必须先生成上一级才解码下一级)还是 soft(共 loss 但平行解码)?论文措辞偏向 hard,但缺少 ablation 验证 “去掉某一级会掉多少”。
Training Recipe
Figure 3-4. 数据 mixture overview。 三阶段累计 1.13T tokens (pretraining) + 200M samples (mid-training) + 50M samples (post-training)。

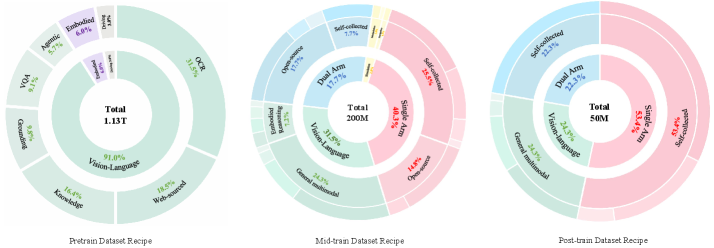
Stage 1 Pretraining(1.2T tokens / 370K steps)
VLM 在 heterogeneous corpus 上单阶段联合训练,覆盖 8 类数据:
- Knowledge:Common Crawl + StepCrawl 网页 interleaved data,LAION/COYO/BLIP-CCS/Zero 图文对,CLIP-based 平衡重采样
- Education:K-12(含 CoSyn 合成数据)、大学 STEM/医学/金融、成人考试(驾照/CPA/法考)
- OCR:image-to-text/code(PaddleOCR、SynthDog)、document-to-text/code(HTML/Markdown/LaTeX)
- Grounding & Counting:OpenImages、COCO、Merlin、PixMo
- VQA:开源 benchmark + caption 生成 QA
- GUI:Step-GUI 数据(含 atomic action trajectory + grounding)
- Driving:depth-aware detection + grounding,bbox 归一化到 [0,1000]
- Embodied:把 robot observation 上的 grounding/caption QA 也放进 pretraining,让 VLM 在最早阶段就接触 physical 场景的空间关系
优化:AdamW(β=(0.9,0.95),weight decay 0.01),batch 8192 × seq 4096。学习率两段式:900B tokens 从 5e-5 线性退火到 1e-5;后 300B tokens 从 1e-5 退火到 6e-6 并切换到更高质量 mix。
Stage 2 Mid-Training(200M samples,64×H20)
引入 action prediction,三类对齐监督在同一训练循环里联合优化:
- multimodal dialogue tokens
- discretized action tokens(VLM 预测)
- continuous action trajectories(action expert 回归)
数据 mixture(5 大类):
- Vision-Language:Cambrian-737k/10M (filtered)、LLaVA-OneVision 1.5、自采多模态(含 caption-reannotated embodied data + GUI grounding + OCR)
- Embodied Reasoning (ER):Task Decomposition / Subtask Prediction / Action QA / Temporal Reasoning / Task Progress Estimation
- Simulation:LIBERO 4 任务(Spatial/Goal/Object/Long)+ RoboTwin 2.0 50 任务 + 自采 Habitat navigation
- Single-arm:自采 Franka/UR5/ARX-5/UMI + open-source(OXE、Fuse)
- Dual-arm:自采 ALOHA + open-source(RoboMind、Agibot Alpha、Galaxea Open World)
Action 表征:horizon ,per-timestep 归一化后量化到 255-bin vocabulary 作为 special tokens 给 VLM;action expert 直接回归 continuous values。同一序列两套表示并行监督。
Conversation augmentation:每种数据组合手工设计 500 个对话模板,训练时随机选模板,防止 overfit 到固定 prompt 结构。
优化:1 epoch on 64×H20,AdamW lr 2.5e-5 → 1e-5,max seq 4096,AMP,每 sample 3 张 image with ColorJitter,per-device batch 6。
Stage 3 Post-Training(50M samples)
从 mid-trained checkpoint 继续,把 robot data 收窄到目标 embodiment(减小 distributional variance,稳定 cross-modal alignment);同时保留 resampled VL 数据维持对话能力。Hyperparameters 与 mid-training 完全一致。
实验结果
RoboChallenge Table30——Specialist
Table 1. Specialist setting on Table30 (success rate %). 30 个真实世界长 horizon tabletop manipulation 任务,覆盖 UR5/Franka/ARX5/ALOHA。
| 模型 | 参数量 | Overall SR |
|---|---|---|
| DM0 | 2B | 62.00 |
| Spirit-v1.5 | 4B | 51.00 |
| GigaBrain-0.1 | 3B | 51.67 |
| π0.5 | 3B | 42.67 |
亮点任务:arrange fruits in basket 100%(GigaBrain 60%)、plug network cable 80%(其他 0–20%)、stack color blocks 100%、search green boxes 100%。 失败任务:make vegetarian sandwich 0%、wipe the table 0%、scan QR code 0%——所有 baseline 也基本失败,说明这是 benchmark-wide 难题。
SFT setup:8×H20,per-GPU batch 4,40K-150K iterations,action horizon 50;repetitive sub-goal 任务额外加 progress supervision。
RoboChallenge Table30——Generalist
Table 2. Generalist setting (success rate / score).
DM0-Generalist 在多任务 multi-platform 联合训练后仍跨平台稳定领先,绝对值翻倍。具体亮点:stack color blocks 100/100、place shoes on rack 100/98.5、put cup on coaster 100/100、search green boxes 100/95.5——这些精度敏感的长 horizon 任务上 π0.5 几乎全 0。
SFT setup:16×H20,batch 4/GPU,200K iterations,action horizon 50。
Multimodal Understanding 保留
VQA 评测覆盖 embodied scene、lifestyle、CoT subtask decomposition、mobile context 四类(Tables 3-6 in paper)。结论:mid-training checkpoint 仍保留 scene understanding / visual grounding / attribute recognition / OCR 的 core VQA 能力,验证了 gradient decoupling 的有效性。
❓ 论文没给 mid-training checkpoint 与 base Qwen3-1.7B / 不解耦版本的定量 VQA 对比,只是定性 “retains core functionalities”。Catastrophic forgetting 究竟掉了多少未知。
Future Work
论文明确三个方向:(1) Scaling——把模型从 2B 扩到 7B/30B、加大数据规模观察 emergent physical reasoning;(2) Multi-modal Perception——加入 tactile / audio / depth 进入 unified pretraining;(3) World Model 集成——让 agent 能 mental simulation,处理超长 horizon 任务。
关联工作
基于
- Qwen3:1.7B LLM 作为 VLM backbone
- Perception Encoder (PE):视觉编码器
- Flow Matching:action expert 的生成范式(Lipman et al. 2022)
- Knowledge Insulation (KI):gradient decoupling 思路的来源
- π0:架构上参考 VLM + flow-matching action expert 的设计
对比
- π0.5:3B、Pretrain-then-Adapt 范式的代表 SOTA;DM0 在 Specialist (62 vs 42.67) 与 Generalist (37.3 vs 17.67) 都显著领先
- GigaBrain-0.1:3B、world-model-powered VLA;DM0 Specialist 领先 ~10%
- Spirit-v1.5:4B、Spirit AI 的 robot foundation model;DM0 Specialist 领先 11%
- π0:VLA flow matching 的奠基工作;Generalist 对比中 9.0% vs DM0 37.3%
方法相关
- GR00T N1:另一条 generalist humanoid 路线,同样是 VLM + action expert
- OpenVLA:早期开源 VLA,作为 “Internet-Native” 范式的代表被对比
- OpenVLA-OFT:OpenVLA 的 fine-tuning 优化变体
- Dexbotic Toolbox (Xie et al. 2025):DM0 同团队发布的 VLA 开源 codebase,DM0 集成于此
- RoboChallenge:本文使用的 real-world benchmark;30 个 long-horizon manipulation 任务
论文点评
Strengths
- Embodied-Native 理念有说服力且与现有范式形成清晰对照:把 embodied data 从 fine-tuning 后置变成 pretraining 一等公民,而非简单 scale up adapter
- Gradient decoupling + 双 action 表征是干净的工程方案:在不牺牲 VLM 语义的前提下 enable action 学习;与 π0 的 architectural 隔离思路 (action expert MoE) 形成对比,技术路线更轻
- Spatial Scaffolding 把 LLM 的 CoT 范式落地到 control:subtask→bbox→trajectory→action 的层级监督理论动机清晰,可作为后续 spatial reasoning for action 工作的 reference design
- 2B 模型击败 3-4B 竞争对手:在 Specialist (62% vs 51%) 和 Generalist (37% vs 18%) 双设定下都领先,data recipe + hybrid training 的杠杆 > 单纯 model scaling
- Generalist 设定下的领先幅度尤其突出:37.3 / 49.08 vs π0.5 17.67 / 31.27,跨任务泛化优势远超 specialist 边际,说明 Embodied-Native pretraining 真正提供了 transferable physical priors 而不只是过拟合
- 数据工程扎实且透明:1.2T tokens pretraining + 200M mid-training + 50M post-training,8 类 pretraining 数据 + 5 类 mid-training 数据来源都列出名字与混合比例
Weaknesses
- 核心 claim 缺少 controlled ablation:DM0 与 π0/π0.5 的对比同时受到 backbone (Qwen3 vs PaliGemma)、data recipe、训练规模的多重 confounding——很难分离 “Embodied-Native” 本身的贡献与 “更好的数据/backbone” 的贡献
- Spatial Scaffolding 没有 ablation:subtask / bbox / trajectory / action 四个层级各自的边际收益未量化,无法判断是不是只有最后一级 action token 监督在起作用
- Multimodal understanding 只有定性描述:保留 VQA 能力是关键 claim,但没给 base VLM vs mid-trained 的定量对比,gradient decoupling 的实际效力是 trust-me 状态
- Benchmark 单一:只评测 RoboChallenge Table30,没在社区更熟悉的 SIMPLER / LIBERO / RoboTwin 上报告,限制 cross-paper 比较——尽管 RoboTwin/LIBERO 数据已在训练集中,“in-distribution evaluation” 至少能给出 sanity check
- Navigation 评测严重不足:论文 abstract 强调 “unify manipulation and navigation”,但 30 个 evaluation 任务全是 tabletop manipulation;navigation 能力只通过 Habitat simulation 训练,没有 real-world navigation 或 mobile-manipulation 的端到端评测
- Generalist 绝对 SR 仍然低:37.3% 远超 baseline 但距离实用部署有距离;论文没讨论这个 gap 能否靠 scaling 闭合
- 复现成本高:三阶段 1.2T+200M+50M pipeline 对学术界几乎不可复现,open weights 的 fine-tuning 能否复制论文 claim 仍待社区验证
- 作者署名爆炸:50+ 人 + 跨 Dexmal / StepFun 两家公司,难以从 author list 推断 contribution density 与具体 component 责任人
可信评估
Artifact 可获取性
- 代码:inference-only。RoboChallenge inference code 已发布在 Dexbotic-RoboChallengeInference;training pipeline 整合在 Dexbotic toolbox 但 DM0 specific 训练脚本未单独披露
- 模型权重:specialist + generalist checkpoints 已发布在 HuggingFace Dexmal/dm0 collection
- 训练细节:仅高层描述。报告了三阶段的 data category、token/sample 总量、optimizer/lr/batch、GPU 数量与 iteration 数;但 mixture 内各 sub-source 的精确比例仅 Figure 4 可视化,未给数值表
- 数据集:部分公开。Pretraining 含大量 in-house StepCrawl + 自采 embodied 数据(私有);Mid-training 部分依赖开源 (LIBERO / RoboTwin / OXE / Cambrian / LLaVA-OV 1.5) 但同样混入自采数据;自采数据未公开
Claim 可验证性
- ✅ 62.0% / 37.3% SR on RoboChallenge Table30:checkpoint + inference code 已开源,社区可独立复现 evaluation;RoboChallenge 是 hosted real-robot eval service,第三方运行可降低 cherry-pick 风险
- ✅ 2B 参数量小于竞争对手 3-4B:架构开源可验证
- ⚠️ “Embodied-Native pretraining 优于 Pretrain-then-Adapt”:core hypothesis 没有 controlled ablation——同 backbone 同数据下对比 “early embodied” vs “late embodied” 的实验缺失。当前对比是 cross-paper(DM0 vs π0/π0.5)而非 cross-recipe
- ⚠️ “Multimodal understanding retained”:只有定性描述与 cherry-picked example,没有 base VLM vs mid-trained 在标准 VQA benchmark 上的定量回归数据
- ⚠️ “Unifies manipulation and navigation”:navigation 只在 Habitat sim 训练,evaluation 全是 manipulation,“unify” claim 缺乏 navigation 端的实证
- ⚠️ Spatial Scaffolding 的有效性:四级 hierarchical supervision 没有 ablation,无法验证它对最终性能的边际贡献
- ❌ 暂未识别明显的 marketing 修辞性 claim
Notes
- DM0 的核心贡献在于提出 Embodied-Native 范式,区别于 π0 系列的 Pretrain-then-Adapt。这一理念是否真正优于后者,仍需要更多 controlled ablation 验证(目前的对比存在 backbone、数据规模、数据质量等 confounding factors)
- Gradient decoupling 与 π0 的 Action Expert MoE-style 设计解决的是同一个问题(防止 action training 破坏 VLM),但技术路线不同:π0 用参数隔离 + post-training stage 解耦,DM0 用 gradient 解耦 + non-embodied data 持续刷新 VLM
- Spatial Scaffolding 的 Chain-of-Thought 式设计值得关注——这是把 LLM 的 reasoning 范式系统化引入 low-level control 的有趣尝试。但论文缺这一组件的 ablation,期待社区后续验证
- 2B 模型打败 3-4B 竞争对手,说明 data recipe + 训练策略可能比单纯的 model scaling 更重要。Future work 中 7B/30B scaling 的实验值得追踪——如果继续领先,Embodied-Native 范式的 scaling law 会是重要 evidence
- StepFun + Dexmal 联合署名值得注意:StepFun 提供 base VLM (Step3) 与 web-scale data infrastructure,Dexmal 提供 embodied data 与 robot platform 经验。这种 “VLM 公司 + Robotics 公司” 的合作模式可能是未来 VLA 研发的范式
- 与 GigaBrain-0.1 同月发布且同 benchmark,对比框架现成;但 GigaBrain 走 world-model 路线,DM0 走 hybrid training 路线,两者代表 VLA 的两个不同优化轴,值得跨 paper 拉通比较
Rating
Metrics (as of 2026-04-24): citation=4, influential=0 (0.0%), velocity=1.82/mo; HF upvotes=0; github 938⭐ / forks=82 / 90d commits=18 / pushed 2d ago
分数:2 - Frontier 理由:Embodied-Native pretraining + gradient decoupling + Spatial Scaffolding 构成 VLA 当前前沿的一条干净路线,在 RoboChallenge Table30 上以 2B 参数显著超越 3-4B 的 π0.5 与 GigaBrain-0.1(Weaknesses 也认可这是 data recipe + hybrid training 的杠杆体现),属于值得比较的 baseline。但未达 Foundation 档——Weaknesses 3 指出 core claim 缺 controlled ablation、Spatial Scaffolding 无层级 ablation、VQA retention 只有定性描述;论文 2026-02 发布社区采纳尚未沉淀,不属于”只读 rating=3 就能理解方向脉络”的奠基工作。2026-04 复核:发表 2.2 月(<3mo 豁免窗口内)4 citation / 影响力 0,但 github 938⭐ + pushed 2d ago + 近 90 天 18 commits 显示强势早期 adoption;绝对 citation 不作降档依据,维持 Frontier。