Summary
CycleVLA: Proactive Self-Correcting VLAs via Subtask Backtracking and MBR Decoding
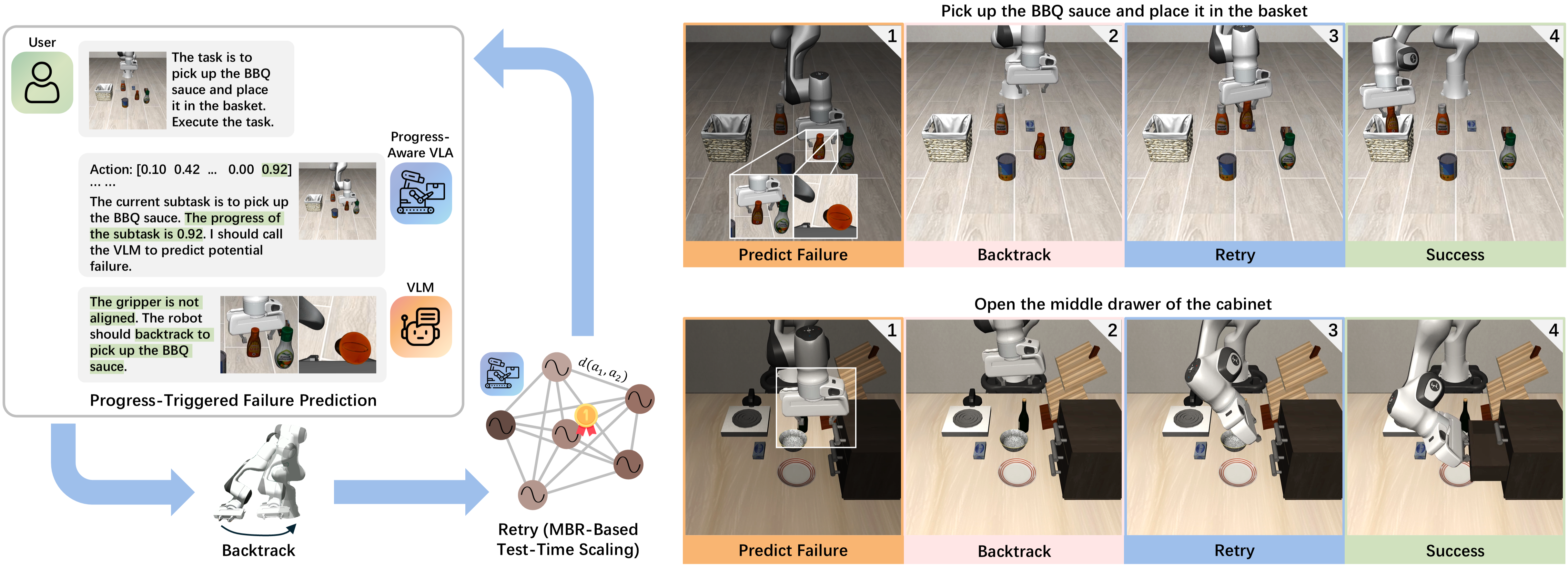
- 核心: 给 VLA 装上 “在 failure 完全发生前察觉并回退重试” 的能力,思路是把 demo 切成 subtask、让 VLA 学会预测 stop+progress 信号、在 subtask 边界让 VLM 判定是 transit 还是 backtrack,回退后用 MBR decoding 选最 consensus 的 action chunk
- 方法: (a) LLM-based subtask 切分 + 9 维 action(7 robot + stop + progress)finetuning;(b) 在 progress≥0.9 处由 VLM 决定 transit/backtrack,回退靠 reverse-execute 已记录的 delta actions;(c) 从 N=8 个 stochastic 采样里用 L2 距离做 density-based MBR 选 medoid
- 结果: LIBERO 平均 95.3 (vs. GR00T N1 93.9),LIBERO-Long 93.6 (+9.2 over base);MBR 让 under-trained VLA 涨 6-10 pts,over-trained 涨 3-5 pts;总 inference 开销 ~30%
- Sources: paper | website | github
- Rating: 2 - Frontier(proactive self-correction 的 framing + MBR zero-shot test-time scaling 的系统化验证是该方向的前沿参考,但 pipeline 工程化程度高、真机缺席,距离 foundation 还有距离)
Key Takeaways:
- Failure 集中在 subtask 边界:作者把这一观察当作核心 prior——progress 接近 1 的瞬间是最可能 fail 的瞬间,也最适合做 intervention check。这让 VLM call 频率天然受控。
- Stop 与 Progress 分离:stop 信号要精确(决定 transition),progress 信号只需 “接近完成” 即可(决定 VLM 何时被调用)。两者拼到 9 维 action 里联合 regress,无需新 head。
- MBR 作为 zero-shot test-time scaling:不依赖 verifier/reward model,直接在 N×N pairwise distance 里选 density-高的 medoid。weak model 收益更大(+9 pts on 200K ckpt)。
- Backtracking 靠 reverse-execute delta actions:这个简洁实现的硬约束是 reversibility——dynamic / contact-rich / irreversible 任务会破坏前提。
Teaser. CycleVLA 的整体 cycle:(a) progress-aware VLA 推到 critical transition;(b) VLM 判断 fail 与否;(c) backtrack 后 MBR 重试,循环至成功或超时。
Background & Motivation
现有 robot failure 处理范式几乎都是 post hoc——错误已经发生才识别(conformal prediction、anomaly detection、VLM-based recognition)和修正(residual policy、retrospective replanning)。但很多 failure 一旦发生就不可逆(玻璃杯摔碎、车冲出车道)。
CycleVLA 的目标:让 generalist VLA 拥有 proactive self-correction——在 failure 完全 manifest 之前察觉并 recover,不需要外部 intervention。
Key insight:
- 大量任务 failure 出现在 subtask 边界(pick→place 的瞬间、insert 的对齐瞬间)
- progress 接近 subtask 完成 时提供了强 cue(“peg 还没卡进去前就能看出 misalignment”)
最接近的工作是 PAINT(XieTSF22)和 Bellman-Guided Retrials(err_du),但前者依赖人介入,后者不针对 generalist policy。
Method
CycleVLA 由三块拼成:
Part 1: Progress-Aware VLA via Subtask Decomposition
Subtask-decomposed dataset 构造(ECoT-style):
- LLM 提议 subtask:给定任务指令 ,prompt GPT-4.1 输出最小原子 subtask 序列 ,词表受限(move / rotate / open / close)。
- 抽取 movement primitives:在 4-step 滑动窗口内对 robot proprio 做 state-diff,阈值化得到离散 movement label(move forward/backward/…、rotate cw/ccw、open/close gripper、stop)。
- 抽取 gripper state segments:用三组 gripper threshold 投票得到 close/idle/open 标签,做后过滤去除孤立 idle。
- Subtask-trajectory 对齐:
- 若 LLM-subtasks == gripper-state-segments,直接对齐到 segment 时间戳
- 否则,把 movement primitive 序列 downsample 到 ≤100 步,再 prompt LLM 推断 subtask 边界(必须无 gap、覆盖全 trajectory)
Figure 2. Pipeline for constructing the subtask-decomposed dataset

Subtask Finetuning with Extended Action Dims:把 7 维 end-effector delta action 扩成 9 维:
- : 二值 stop signal,标记 subtask 终止
- : subtask progress(normalized 时间步),离散到 0.1 bin
stop 与 progress 分开预测的理由:stop 必须精确(决定 transition),progress 只需 “接近 1”(决定 VLM 何时被调用)。Following NaVILA,oversample 每个 subtask 的最后一步 8x 强化 termination detection。两个新信号 jointly regress 为 scalar,不引入额外 head。
Part 2: VLM-based Failure Predictor & Subtask Backtracking
Figure 3. CycleVLA 整体架构

当 VLA-predicted progress 触发 时,query 一个 off-the-shelf VLM(GPT-5.2,temperature 1.0),输入:
- 同步的 third-person + wrist-mounted 双视角图像
- 当前 subtask + 完整 subtask list
VLM 输出 CoT reasoning 和决策:transit(进入下一 subtask)或 backtrack(回退到最早能 restore missing precondition 的 subtask,例如物体掉了→回到 grasp subtask)。
Backtracking 实现:通过 reverse-execute 已记录的 delta actions 把 robot state 还原到目标 subtask 的起点。这是个简单但强假设——要求 state transition reversible。
Part 3: MBR Decoding as Test-Time Scaling
回退后从相同起始 state 重试 subtask。从 采 个 stochastic action chunk hypotheses(diffusion-based action expert,靠不同 random seed 改 noise sampling):
Equation. Sampling-based N×N MBR objective
含义:MBR 选择在 hypothesis 集合内距离其他所有 hypothesis 平均最近的那一个——倾向于 policy 输出空间中的高密度区域。这背后是 imitation learning 假设:成功行为聚集在高密度区。
Distance 实现:把每个 hypothesis 的 translational + rotational delta 累积成预测 trajectory,用 6H 维特征向量 计算 L2 距离。
Density-based 变体(Appendix C 说的实际实现,区别于教科书 MBR):
- 计算 r-NN radius 作为 local density estimate(, 时 )
- 找最 dense 点作为 pocket center
- 在 pocket 内选 medoid 作为最终 action chunk
❓ 这跟标准 MBR 已经很不一样了——本质是 mode-seeking 而不是 risk-minimizing。论文写法上把它当作 MBR 的 variant,但 ablation 没有 standard MBR vs density-MBR 的直接对比。
Inference Algorithm
Alg. 1 在每个 subtask 内交替两个 phase:
- Monitor phase: 持续 rollout 直到 progress 信号被 confirm 触发 检查;调 VLM 决定 transit / backtrack
- Complete phase: 持续 rollout 直到 stop 信号被 confirm
Confirm 机制(Appendix D):避免噪声触发——要么连续 2 步 high signal,要么 first_seen 后 ≥2 个 low-step 又出现 high signal。
每个 subtask 最多 次 retry,超过则强制完成。
Experiments
Setup
- Backbone:OpenVLA + diffusion-based action expert(refer 到 OpenVLA-OFT 实现)
- Benchmark:LIBERO 四个 suite(Spatial / Object / Goal / Long),各 10 task × 50 rollout × 3 seed
- 训练设定:4×A100 40GB,500K steps,LoRA rank 32,batch 64,action chunk H=8,open-loop 执行全 8 步
- 关键差异:四 suite 联合训练(更难),不像 OpenVLA 那样每 suite 独立训
- VLM:GPT-5.2 (temp 1.0),progress threshold ;MBR ,L2 距离
LIBERO Performance
Table I. LIBERO success rates (单位 %)
| Method | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| Diffusion Policy | 78.3 | 82.5 | 68.3 | 50.5 | 72.4 |
| Octo-Base | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 |
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| TraceVLA | 84.6 | 85.2 | 75.1 | 54.1 | 74.8 |
| SpatialVLA | 88.2 | 89.9 | 78.6 | 55.5 | 78.1 |
| ThinkAct | 88.3 | 91.4 | 87.1 | 70.9 | 84.4 |
| CoT-VLA | 87.5 | 91.6 | 87.6 | 69.0 | 81.1 |
| FPC-VLA | 87.0 | 92.0 | 86.2 | 82.2 | 86.9 |
| GR00T N1 | 94.4 | 97.6 | 93.0 | 90.6 | 93.9 |
| CycleVLA | 97.6 | 98.1 | 91.7 | 93.6 | 95.3 |
LIBERO-Long 提升最显著(+3 over GR00T N1),符合 “subtask 边界 backtrack 对长 horizon 任务最有用” 的故事。
Effectiveness on Under-Trained VLAs
Table II. Recovery on under-trained VLAs
| Ckpt | Spatial w/o → w/ FC | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| 200K | 84.7 → 89.1 (+4.4) | 82.0 → 90.2 (+8.2) | 63.6 → 74.2 (+10.6) | 62.3 → 66.5 (+4.2) | 73.2 → 80.0 (+6.8) |
| 350K | 88.4 → 94.8 (+6.4) | 93.8 → 97.5 (+3.7) | 72.6 → 79.4 (+6.8) | 77.9 → 85.3 (+7.4) | 83.2 → 89.2 (+6.0) |
| 500K | 91.1 → 97.6 (+6.5) | 95.3 → 98.1 (+2.8) | 86.5 → 91.7 (+5.2) | 84.4 → 93.6 (+9.2) | 89.3 → 95.3 (+6.0) |
观察:CycleVLA 把 200K ckpt 推到接近 350K-no-FC 的水平,把 350K 推到接近 500K-no-FC,用 inference 时间换 training 步数。这是个有用的 framing。
MBR Analysis
Table III. Effect of N(hypothesis 数)on
| Method | SR | N=4 random/MBR | N=8 | N=16 | N=32 | N=64 |
|---|---|---|---|---|---|---|
| 200K | 73.2 | 72.9 / 78.2 | 71.7 / 78.5 | 71.9 / 81.2 | 72.2 / 79.7 | 72.3 / 79.7 |
| 350K | 83.2 | 80.5 / 88.0 | 80.3 / 90.2 | 80.2 / 91.3 | 80.4 / 92.3 | 80.7 / 92.2 |
| 500K | 89.3 | 90.8 / 94.1 | 90.2 / 95.5 | 91.1 / 95.7 | 90.7 / 95.7 | 90.4 / 95.6 |
关键发现:
- Random selection ≈ base policy SR——marginal behavior 没变
- MBR consistently 好;N 从 4→8 收益最大,>16 plateau
- Weaker model 收益更大(200K +9 vs 500K +5),契合 LLM 文献里 “弱模型从 hypothesis selection 收益多” 的模式
Table IV. Distance metric 消融(N=8)
| Method | SR | Random | cos | ||||
|---|---|---|---|---|---|---|---|
| 200K | 73.2 | 71.7 | 78.7 | 78.5 | 77.8 | 74.1 | 73.5 |
| 350K | 83.2 | 80.3 | 89.7 | 90.2 | 88.2 | 87.5 | 86.9 |
| 500K | 89.3 | 90.2 | 94.7 | 95.5 | 94.3 | 94.4 | 94.8 |
≈ > > cos / corr。作者解释:translational components 沿 trajectory dense,rotational sparse,magnitude-based metrics 比 direction-based 更适配。
Runtime
Table V. End-to-end inference 时间分解(秒)
| GPU | VLM | Action Rollout | Action Sampling | MBR | Backtrack | Total |
|---|---|---|---|---|---|---|
| A10 | 12.9 (6.0%) | 147.6 (68.6%) | 47.9 (22.2%) | 0.003 (<0.1%) | 6.9 (3.2%) | 215.3 |
| A100 | 15.3 (19.9%) | 44.7 (58.1%) | 11.9 (15.5%) | 0.002 (<0.1%) | 5.0 (6.5%) | 76.9 |
CycleVLA 让总 inference 时间增加 ~30%。MBR 本身计算成本可忽略;瓶颈仍在 VLA action rollout。GPU 越强,VLM API latency 占比越大。
Ablations
Table VI. Component 消融
| Variant | SR | Time (s) |
|---|---|---|
| w/o MBR (random selection) | 92.5 | 302.4 |
| alt VLM (LLaMA-3.2-11B) | 92.8 | 172.6 |
| w/o stop + last-action oversample | 91.1 | 186.8 |
| always-on MBR (UB) | 96.9 | 464.3 |
| pred. failure cutoff (LB) | 79.7 | 110.2 |
| CycleVLA (main) | 95.3 | 215.3 |
关键 takeaway:
- 去 MBR 掉 ~3 pts,但靠 retry-up-to-R 还能 recover 一些
- 换小 VLM(LLaMA-3.2-11B)SR 略降但更快——小模型更倾向 transit 而非 backtrack(保守)
- 去 stop + last-action oversample 触发过早终止(progress spurious high)
- always-on MBR 是 upper bound,但 runtime double
- “predicted failure 即终止” 作为 LB 揭示 VLM sycophancy:被问 “会不会失败” 时 VLM 倾向认同,导致 ~10% drop
❓ “VLM sycophancy” 这个解释挺有意思,但作者并没设计一个无 leading question 的 prompt 对照实验来 isolate sycophancy 与 VLM 真实的 failure-detection 能力。
Limitations(论文自己列的)
- Backtracking 假设 reversible state——dynamic / irreversible 场景失效
- MBR 多 forward pass 增加 latency,不利于高频 contact-rich control
- 真机实验未做(“to be added in the near future”)
关联工作
基于
- OpenVLA: Backbone VLA,被加上 diffusion action expert(OpenVLA-OFT 风格)
- OpenVLA-OFT: 提供 diffusion-based action expert 的实现框架(GitHub repo 看起来直接 fork 自此)
- ECoT: 提供 movement primitive 词表与抽取流程;subtask 分解 prompt 风格相似
对比
- GR00T N1: LIBERO 上的 prior SOTA,CycleVLA 的主要对手
- FPC-VLA: LIBERO-Long 上 prior 强 baseline (82.2),被 CycleVLA 超越
- PAINT (XieTSF22): “proactive self-correction” 概念的源头,但需人介入
- Bellman-Guided Retrials: 同样做 backtrack,但不针对 generalist policy
- RoboMonkey, Rover, V-GPS: 其他 VLA test-time scaling 工作,依赖 verifier / reward model;CycleVLA 主打 verifier-free
方法相关
- MBR Decoding (Kumar & Byrne 2004; Eikema & Aziz 2022): NLP 经典;论文借用 N×N pairwise sampling-based 形式
- Subtask 分解相关: π0.5、dexvla、NaVILA(last-action oversampling 来自此)
- Backtracking in navigation: Tactical Rewind (Ke et al. 2019)、SmartWay (Shi 2025)
- Octo: LIBERO baseline 之一
论文点评
Strengths
- 问题 framing 干净:proactive vs post hoc 的对立 + “failure 集中在 subtask 边界” 的 prior,直接催生整个 pipeline,每个组件都对应清晰的子假设。
- Stop / Progress 分离有 taste——明白哪个信号需要精确、哪个不需要,避免不必要的 head 工程。
- MBR 是 nice 的 zero-shot baseline:不需要训 verifier 或 reward model 就能拿到 +5~10pts,且 weaker model 收益更大的 trend 与 LLM 文献一致,可信。
- Ablation 覆盖较全:MBR 距离度量、N 扫描、VLM backbone 替换、UB/LB 变体都做了,pred-failure-cutoff 作为 LB 是巧妙的设计,能 isolate VLM 的 false positive 影响。
- Runtime 透明:直接给百分比拆解,~30% 开销的 trade-off 对读者是清楚的。
Weaknesses
- 真机实验缺席——LIBERO 是 simulation,且作者承认 backtracking 假设 reversibility,但真实 manipulation 大量场景违反这个假设(contact-rich、deformable、liquid)。“to be added” 的 promissory note 在 VLA 这种以泛化为卖点的领域很伤说服力。
- “Density-based MBR” 与论文 main equation 不一致:paper body 给的是 standard sampling-based MBR (Eq. 4),但 Appendix C 说 “Rather than selecting the hypothesis with minimum average distance (standard MBR), we use a density-based variant”。这本质是 mode selection 而不是 risk minimization,但全文叙事和 ablation 都按 MBR 走,没有 standard MBR vs density variant 的直接对比。
- VLM dependency 是隐藏成本:用 GPT-5.2 cloud API 做 failure prediction 引入了 latency 与可重复性问题(temp=1.0 + 闭源模型 + sycophancy issue)。LLaMA-3.2-11B 替换实验显示 SR 只掉 2.5 pts 但更快,反而暗示作者其实可以走更轻量路线。
- Subtask 切分依赖 LLM + 离线 demo 的 proprio——这个 pipeline 是 dataset-specific 的预处理,迁到无 demo 的新场景需要重做。“我们用 GPT-4.1 + manual gripper threshold” 的 recipe 很难 scale 到 OXE 量级数据。
- 没和 PAINT、Bellman-Guided Retrials 直接 head-to-head 比较——这两个被 related work 标为最相关,但实验只跟 GR00T N1 / FPC-VLA 等 SOTA VLA 比 raw SR,没有 controlled “同样 base VLA + 不同 self-correction 策略” 的对比。
- LIBERO-Long 涨 9.2 pts 而 LIBERO-Goal 反降(CycleVLA 91.7 vs GR00T N1 93.0)——作者没解释。如果 backtracking 在某些 task type 上反而有害,需要 case study。
可信评估
Artifact 可获取性
- 代码: Repo 存在 (https://github.com/dannymcy/cyclevla_code),但截至本笔记日期 (2026-04-20) README 仍是 OpenVLA-OFT 模板的直接复制,未提供 CycleVLA 自己的 install / run 说明。可推测代码 fork 自 OpenVLA-OFT 但实际状态未知。
- 模型权重: 未在论文中说明发布的 checkpoint 名字
- 训练细节: 完整(Table VIII 列出 LR / batch / steps / LoRA rank / chunk size / oversample factor / image augmentation)
- 数据集: LIBERO 公开;subtask-decomposed 版本是基于 LIBERO 用 GPT-4.1 生成的,论文未声明是否会发布该衍生数据
Claim 可验证性
- ✅ CycleVLA 在 LIBERO 平均 95.3,超过 GR00T N1 (93.9):Table I 数字,joint-training 设定明确
- ✅ MBR 给 under-trained VLA 带来 +6~10 pts:Table III 多 N 多 ckpt 一致 trend
- ✅ Inference 总开销 ~30%:Table V 双 GPU 数据透明
- ⚠️ “MBR 是 effective zero-shot test-time scaling for VLAs”:仅在 LIBERO + 单一 backbone (OpenVLA + diffusion expert) 上验证;其他 VLA 架构(autoregressive、flow matching policies)和真机任务上是否成立未知
- ⚠️ “Failures 集中在 subtask transitions”:作者把它当 motivation 和论文骨架,但没有一个量化 study(例如 “X% 的 failure 发生在 last 10% of subtask”)支撑该 prior 在 LIBERO 之外的普适性
- ⚠️ VLM-based backtrack 的有效性:依赖 GPT-5.2 闭源 + temp=1.0,结果可重复性弱;LLaMA-3.2-11B ablation 显示性能差不多,也意味着 sophisticated VLM 不是必需,但论文没探究这点
- ❌ “Proactive self-correction” 这个 framing 略 marketing:实际机制还是 “在 progress=0.9 处 query VLM 看会不会 fail”,本质仍是依赖一个 reactive failure detector,只是 detector 触发得早。“Proactive” 容易让读者以为 VLA 自身具备 anticipation 能力
Notes
- 整套 pipeline 的逻辑链条很清晰,但每一环都是 engineered 的——LLM-prompted subtask 切分、threshold-tuned gripper detection、density variant of MBR、reverse-execute backtracking、VLM CoT prompt——加起来像 swiss army knife 而不是 simple/scalable/generalizable 的方法。从 first principle 看,真正 elegant 的方向应该是把 “anticipation + recover” 直接 bake 进 policy(用 RL 或 world-model based planning),而不是堆三个 hand-crafted 系统。但作为 first attempt 这是合理的工程切入点。
- 一个值得关注的 negative signal:LLaMA-3.2-11B 替换 GPT-5.2 几乎不掉点,说明 VLM 在这个 setup 里的 contribution 主要是 trigger backtrack 这个动作,而不是精细的 failure recognition。这反过来可能暗示一个更简洁的设计:用 progress 阈值 + 简单 heuristic(比如 gripper state mismatch)就能替代 VLM call。
- LIBERO-Long +9.2 vs GR00T N1 是最强卖点。但 LIBERO 这个 benchmark 已经被多家刷到 90+,gap 越来越像 noise;真正的 test 应该在更长 horizon、更多 contact、有 partial observability 的任务上。
- 想做的对照:把 CycleVLA 的 backtracking 部分接到 π0.5 上(已有 subtask 分解能力),看 self-correction gain 能否迁移到 hierarchical-by-design 的 VLA。
Rating
Metrics (as of 2026-04-24): citation=2, influential=0 (0.0%), velocity=0.56/mo; HF upvotes=N/A; github 2⭐ / forks=0 / 90d commits=0 / pushed 227d ago · stale
分数:2 - Frontier 理由:问题 framing(proactive vs post hoc self-correction)和 MBR-as-test-time-scaling 的系统化实证(Table III 跨 ckpt 跨 N 的一致 trend、weak model 收益更大)足以作为 VLA self-correction 方向的前沿参考,也是后续工作的合理 baseline。但这不是 foundation 档——pipeline 重度依赖 engineered 组件(LLM-prompted subtask 切分、reverse-execute backtrack、closed-source VLM)、真机实验缺席、density-MBR 与 main equation 的 standard MBR 不一致,distance 未来成为 de facto 范式的概率有限;且发表时间仅两个多月,外部采纳信号尚不足以支撑 3 档。2026-04 复核:3.6 月 2 citation / 影响力 0 / github 仅 2⭐ 且 stale(pushed 227d、近 90 天 0 commit),社区采纳与维护信号均偏弱;按 <3mo 豁免刚过的边缘处理,方法 framing 仍保留 indexed 价值,暂维持 Frontier,下轮若仍停滞应降至 Archived。