Summary
Mind to Hand: Purposeful Robotic Control via Embodied Reasoning
- 核心: Lumo-1,Astribot 推出的 7B 级 VLA,主张让 reasoning trace 与 action 在同一 transformer 内联合优化。从 Qwen2.5-VL-7B 经”具身推理 → cross-embodiment 动作 → 带推理动作”三阶段训练 + GRPO RL,在自家 Astribot S1 双臂移动机器人上对标 π0 / π0.5
- 方法: (1) Spatial action tokenizer——AWE 路标分解 + delta EE-space k-means 聚类成 motion primitive 库,比 FAST 更紧凑且每个 token 都对应有效 motion;(2) 三阶段 pre-training (VLM 13.7B → cross-embodiment 200B → reasoning-action 193B tokens);(3) discrete pre-train + flow-matching action expert 在 fine-tune 阶段接入;(4) RL 阶段对 bbox/keypoint/waypoint/action/text consistency 五种 reward 联合优化 reasoning-action alignment;(5) 长程任务的 subtask completeness prediction
- 结果: VLM benchmark 6/7 超 base Qwen2.5-VL-7B 和 RoboBrain / Robix;6 个 fine-tuning 任务(含 Prepare Food 长程、Fold Towel 形变物)全面优于 π0/π0.5;RL 后 action NSR +23%, waypoint NSR +22%
- Sources: paper | website
- Rating: 2 - Frontier(commercial-lab VLA,spatial action tokenizer + subtask completeness prediction 是 reusable 组件,且在 π0/π0.5 上 head-to-head 领先,是 embodied-reasoning VLA 谱系里值得 baseline 的前沿工作;但无代码/权重/数据释放、核心 claim 样本量小、未 isolate reasoning 贡献,未达 foundation 档)
Key Takeaways:
- Spatial action tokenizer 是论文最值得复用的组件:AWE 路标分解 + 在 delta EE-space 上 k-means 聚类,把 action 表示成”motion primitive 序列”,每个 token 都解码为合法 motion,不会像 FAST 那样产生 invalid decoding;同时支持 top-3 sampling 抗预测错误,对数据采集噪声鲁棒
- “Subtask completeness 先判 → 再决定是否生成下一个 subtask” 是对长程 VLA 简单但有效的修补:相比 π0.5 的 hierarchical subtask prediction,避免在视觉相似状态下(半开微波炉)反复振荡,且任务已完成时能 idle 而非重复抓取
- Stage2 cross-embodiment co-training 会损害语义理解(Unseen Instructions 上反而不如 Stage1),需要 Stage3 reasoning-action 训练拉回;这印证了 π0 系工作”action fine-tuning 易侵蚀 VLM 知识”的观察
- 数据增强对 OOD 泛化是必要而非可选:同样的 data-constrained scaling law 拟合下,无 augmentation 训练在 OOD validation 上 loss 显著高于 augmented 版本——这给”靠堆 trajectory 数量提升泛化”的路线泼了冷水
- 没有 code 或 weight release——纯技术报告 + 商用产品 demo;关键复现细节(spatial action tokenizer 的聚类超参、reasoning data 全流程)在 Supp. 里部分给出,但 RL reward 权重、数据配比的精确数字未完整披露
Teaser. Lumo-1 整体架构。 同一 multi-modal transformer 同时支持 next-token prediction(discrete action tokens)与 flow matching(continuous action expert),文本侧承担 reasoning trace 生成。
Figure 1. Model Architecture.

1. Motivation
VLA 的两个长期痛点:generalization 弱、interpretability 差。论文的核心 framing 是把”为什么选这个 action”这件事从 implicit 提到 explicit——通过 reasoning trace 显式地参数化 。这条思路并不新(ECoT、CoT-VLA、MolmoAct、ThinkAct 都做过),Lumo-1 的不同是把它端到端地组织成一个完整 training pipeline(VLM → cross-embodiment → reasoning-action → RL)并 commit 到一个 production-grade 的 bimanual mobile manipulator (Astribot S1) 上。
❓ 论文反复强调 “purposeful” 和 “intent”,但在评测上 reasoning trace 的好坏 → action 成功率的 causal link 并没有被 isolate。Stage3 比 Stage2 强可能是因为 reasoning trace,也可能仅仅是因为多了一轮 target-embodiment 训练。
2. 模型架构
2.1 三个 distribution
含义:reasoning 由 instruction + 观测决定;low-level action 只 condition 在 和 observation 上,不再 condition 在原始 instruction 上——这是个值得注意的设计选择,意味着所有语义解析都被压缩进了 。这对应到 inference 时的 partial vs full reasoning mode 切换。
骨干是 Qwen2.5-VL-7B,输出端混合:
- text token + discrete action token (next-token prediction,pre-train)
- continuous action via flow-matching action expert(fine-tune 时挂上)
2.2 Spatial Action Tokenizer
这是全文方法上最实质的 contribution。流程见下图:
Figure 2. Spatial Action Tokenizer.
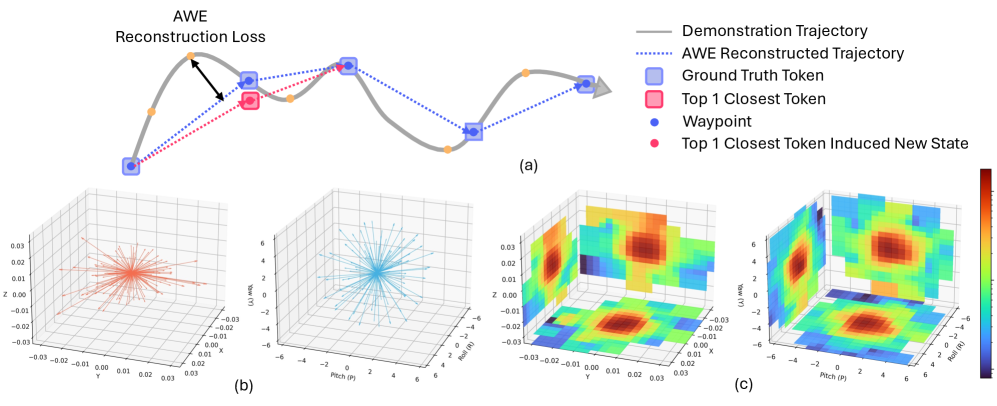
三步:
- Waypoint 分解(AWE):把高频轨迹分解为最少 waypoint 集合,使得线性插值与原轨迹的 reconstruction error 落在阈值内。Position 用 point-to-line distance,rotation 用 slerp 后的 rotational distance。两个端的阈值同步触发:translation 或 rotation 任一超阈值即新增 waypoint,左右臂 + torso 同步
- Delta clustering:在大规模多 embodiment 数据上对 delta xyz / delta SO(3) 分别 k-means(150 cluster),cluster centroid 即 motion primitive,进入 motion token library
- Token assignment(贪心 + top-3 sampling):每个 state 选”应用后最接近下一 waypoint 的 token”为 GT,但训练时从 top-3 中随机采样以增强对 inference noise 的鲁棒性
action chunk 表示固定为长度 8 的 unit:
分别对应 torso / left arm / right arm。预测时输出 8 的整数倍 token,约 40 token 对应 ≤1.33 秒 (30Hz × 40 frames)。
关键 claim:与 FAST 的 DCT 编码相比,每个 token 都对应库中的一个有效 motion primitive,因此预测错误不会产生 invalid action——这是个真实的工程优势。
我的看法:这个 tokenizer 本质是”action 上的 VQ”,思路并不前所未见(OpenVLA 的 binning、FAST 的 DCT 都是同一谱系),但用 AWE+k-means 的双重压缩 + 结构化 8-slot 模板把 cross-embodiment 的轨迹压成长度 ~5 token/end-effector 的紧凑序列,对工程 throughput 友好,可复用性较高。
2.3 Discrete + Continuous 联合表示
借鉴 Driess et al. 2025 的发现:纯 continuous 输出的 fine-tune 会破坏 VLM 的语言能力。Lumo-1 的应对:
- pre-train 阶段:discrete action token (next-token prediction) → 保住 VLM 语义能力
- fine-tune 阶段:挂上一个预先 unconditional pre-trained 的 flow-matching action expert,再在下游任务上转为 conditional
action expert 的”unconditional pre-training”是个新颖小技巧:让 expert 在大规模 robot dataset 上学 action 分布的边际,再 fine-tune 时仅注入条件,避免冷启动。
3. 训练 Recipe
Figure 3. Curated VLM data overview.

Figure 4. Data mixture distribution. Stage1 偏 spatial understanding;Stage2 主要是 cross-embodiment trajectories(AGIBot Genie-1, ARX, AgileX, YAM, Astribot S1 prototype)+ down-sample 到 5.84% 的 VLM data。
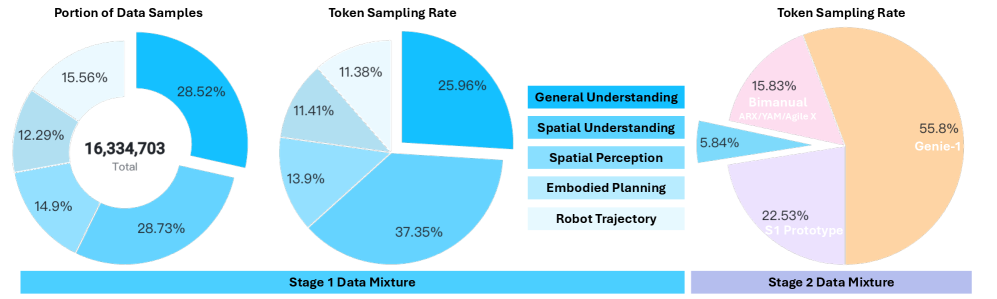
Stage 1:Continued VLM Pre-training(13.7B tokens, 7k steps, 128×H100)
目标:在 Qwen2.5-VL-7B 上加固 embodied reasoning。数据涵盖:
- General multimodal: Cambrian-10M, LLaVA-665K, Pixmo, Robo2VLM, What’sUp
- Embodied planning: EgoPlan, ShareRobot, AGIBot, Galaxea — 重构为 Next Action Prediction / Task Status Verification / Action Affordance(feasibility + achievability)
- Spatial perception: PixmoPoint, PACO LVIS, OCID-REF, RoboPoint, ShareRobot Affordance — bbox / keypoint / object part / attribute prediction
- Spatial understanding: RefSpatial, SpaceVista, 自采 Astribot Spatial Compass(用 SAM + VGGT 抽取 mask + depth → 3D bbox)
- Robot trajectory: MolmoAct + ShareRobot + AGIBot beta,做 2D head-camera 轨迹 waypoint prediction
Stage 2:Cross-Embodiment Co-Training(200B tokens, 100k steps, 128×H100)
145 个任务跨 5 个机器人平台。两个数据工程贡献值得注意:
- Intra-prompt trajectory de-duplication:同 (task, subtask) 的轨迹投影到 xy/xz/yz 三平面,离散化成 boolean occupancy grid,用归一化 XOR 距离 判定冗余,低于阈值就删——直接攻击 teleoperation 数据”中心区域过采样”问题
- Robot Trajectory Mirroring:通过水平翻转 head camera + 互换并翻转 wrist camera + y 轴翻转 + 旋转坐标系变换,把右手轨迹镜像成左手数据,矫正 operator handedness 偏差
Stage 3:Target-Embodiment Action Training with Reasoning(193B tokens, 70k steps)
平台是 Astribot S1:双 7-DoF 臂 + 4-DoF torso(含 waist rotation, hip flexion, knee 关节),垂直 reach 0–2m,水平 1.94m。
Figure 5. Sample tasks on Astribot S1.

Reasoning data 16.2M frame,分两类:
- Textual reasoning: (1) Abstract concept reasoning(“高热量带咖啡因的饮料”→“普通可乐”);(2) Subtask reasoning;(3) Visual observation description;(4) Movement reasoning(“右夹爪当前在茶壶盖右侧,向左前方移动以对齐”)
- Visual reasoning: bbox + keypoint + waypoint trajectory prediction
Reasoning training:full reasoning vs partial reasoning(仅 subtask reasoning)由 system prompt 控制,inference 时按任务复杂度选择。
长程任务的 subtask completeness prediction:相比 π0.5 的”先 predict subtask 再 act”,Lumo-1 输入额外加一个”上一执行的 subtask”,先判断它是否完成、未完成则继续执行、完成则生成下一个。优势:(1) inference 更快(subtask 持续中跳过生成);(2) 减少视觉相似状态下的歧义(“open” vs “close” 微波炉门半开时);(3) 避免双臂选择振荡
这个修改在概念上很简单,但实战意义大。π0.5 系列的 hierarchical subtask 预测确实有 instability 问题。
4. Reinforcement Learning for Reasoning-Action Alignment
GRPO 微调,问题:Stage3 后 textual reasoning 偶有错、reasoning 与 spatial / action 之间不对齐。Reward 设计:
- Visual reward: bbox IoU(仅 pick 阶段) + keypoint accuracy(仅 place 阶段) + waypoint distance(goal + DTW trajectory similarity)
- Consistency reward: 用 Qwen3-VL-32B 做 LLM-as-judge,评估 text reasonableness + text-spatial alignment
- Action reward: 在每个 action chunk 的 final timestep 上计算 position/rotation/gripper error,指数衰减聚合
- Format reward: regex 匹配 (×0.1)
借鉴 DAPO:clip-higher + 高 sampling temperature (1.6) + 小 KL penalty(0.04)来防 mode collapse。
Table. RL vs Stage3 (NSR)
| Reward | full reasoning NSR | partial reasoning NSR |
|---|---|---|
| bbox | +5.05% | – |
| keypoint | +2.69% | – |
| waypoint | +22.43% | – |
| action | +23.33% | +21.03% |
action 与 waypoint reward 提升最大,bbox/keypoint 提升有限——说明 RL 对”低层 motion 精度”的边际价值高于”高层 grounding 精度”。
❓ NSR 是 paper 自创指标(RL 优于 Stage3 的实例数减去反向);这个 metric 隐藏了”提升幅度”信息,例如 +23% NSR 可能是 50% 实例小幅领先 27% 大幅落后。Table 3 的 mean ± std 数据其实更可信。
5. 实验
5.1 VLM Benchmark (Q1)
7 benchmark(CV-Bench, EmbSpatial, BLINK, RefSpatial-Bench, SAT, Where2Place, RoboSpatial)。Lumo-1-Stage1 6/7 超 Qwen2.5-VL-7B-Instruct,多数超 RoboBrain-7B-2.0 和 Robix-7B。
关键观察:Stage2 co-training 后多数 benchmark 略掉,因为 VLM data 被 down-sample 到 5.84%——对应 paper 自己的”action 学习不完全无害”的诚实承认。
5.2 Generalizable Pick and Place (Q2-Q3)
4 个 setting:Basic / Unseen Environments / Unseen Instructions / Unseen Objects(沿用 GR-3 设计)。两个指标:IFR(identification correct)+ SR(task success)。
Figure 6. Pick and Place results.
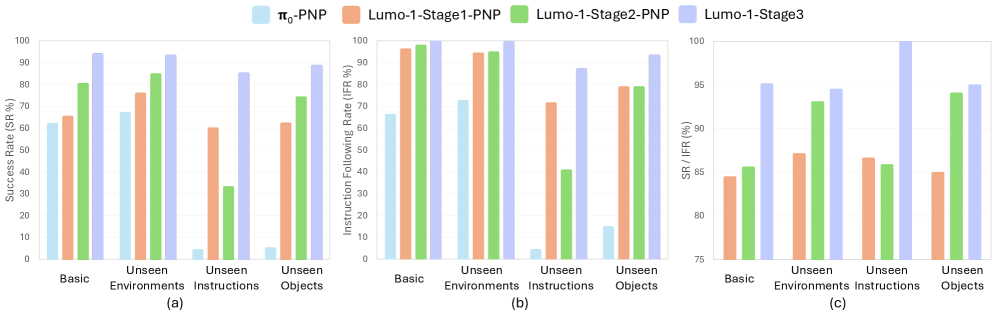
主要发现:
- Lumo-1 (Stage1→3) 单调超越 π0
- Stage2 在 Unseen Environments 上 IFR/SR 大幅领先 Stage1(86.98% → 92.95%)——cross-embodiment 训练真的提升了对环境的鲁棒性
- 但 Stage2 在 Unseen Instructions 上反而劣于 Stage1,因为 VLM data 被稀释;Stage3 的 reasoning 训练拉回来
Figure 7. Generalization & instruction following.

Figure 8. Long-horizon packing tasks.
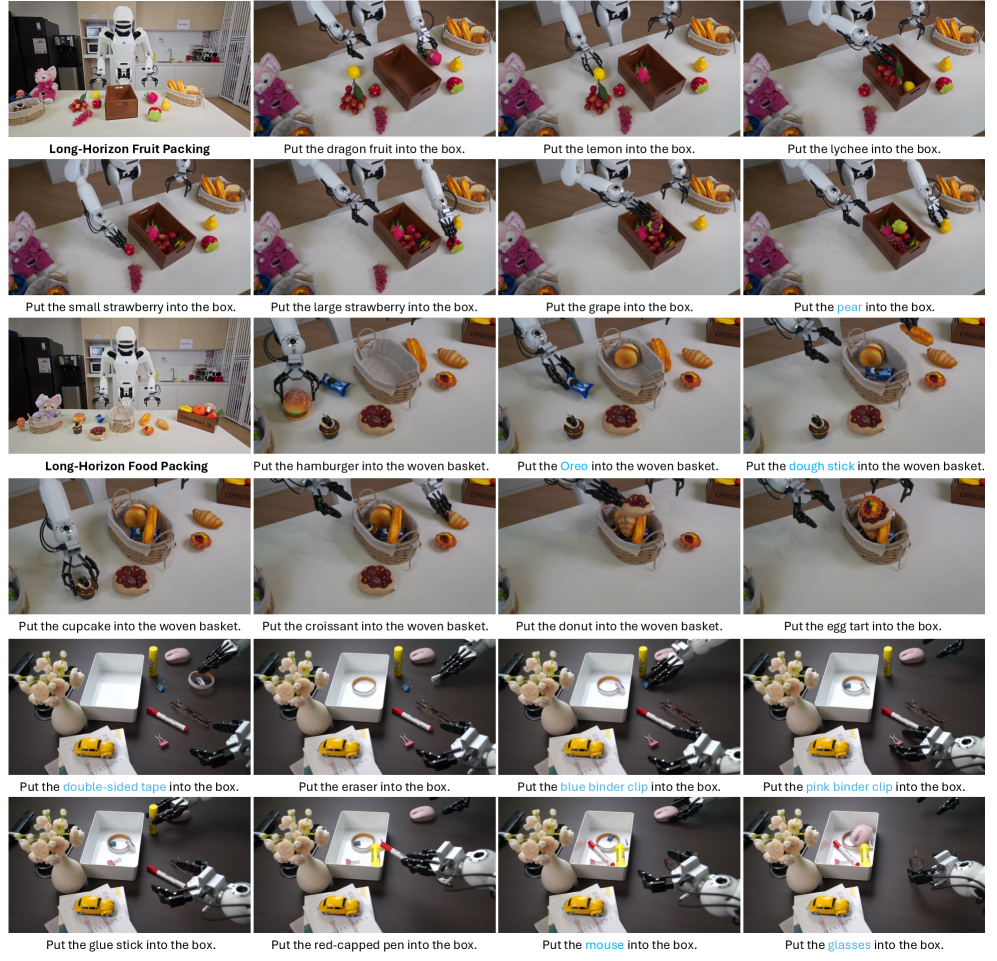
Figure 9. Adaptation to novel heights.

Figure 10. Partial vs Full reasoning. Full reasoning 在面对”high-calorie caffeinated drink”这类抽象指令时能正确解析为 cola,而 partial reasoning 直接跳到 grounding 失败;但 latency 高

Figure 11. Context-aware arm selection. 默认右臂取右侧物体,被遮挡则切左臂——这种行为是从 reasoning 中”涌现”还是直接被 demo data shaping 的,paper 未做 ablation

5.4 Post-Training (Q5)
6 个 fine-tuning 任务:Organize Stationery / Play Basketball / Serve Water / Pack a Toy / Prepare Food(长程,9 subtask)/ Fold Towel(deformable)。每任务 400 episode(Prepare Food 2855),与 π0 / π0.5 在严格控制的相同 layout 下对比。
Figure 14. Fine-tuning results. Lumo-1 在所有 6 个任务上超过 π0/π0.5。
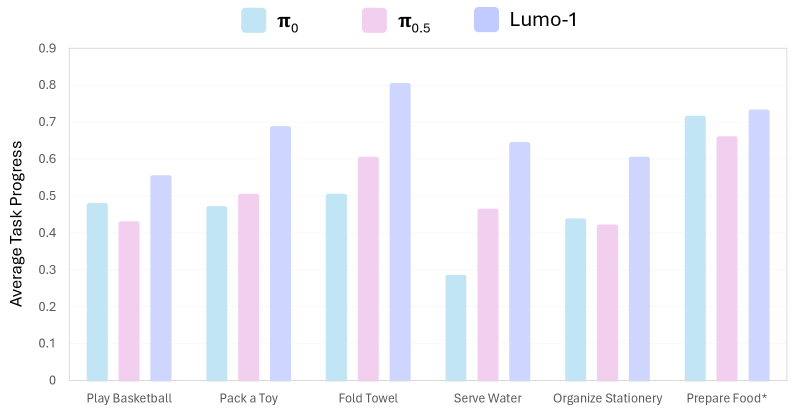
Figure 15. Subtask completeness 防止重复执行——Lumo-1 在已完成”放一个章鱼”后能正确 idle,而仅做 subtask prediction 的版本会误启动下一轮”pick up octopus”

5.5 Scaling Law (Q6)
采用 Data-Constrained Scaling Law:
Figure 16. Scaling law exploration.
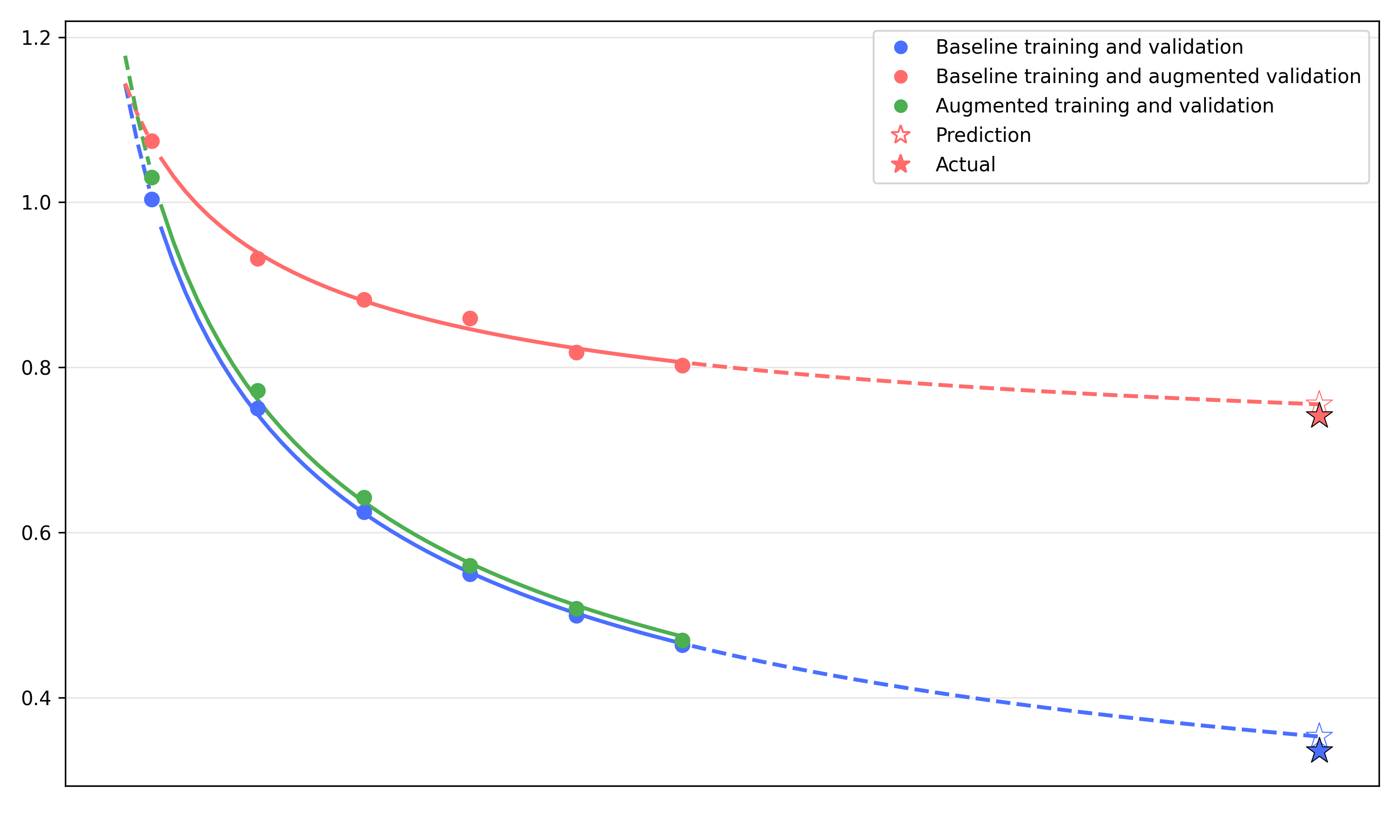
三条曲线(原始训练+原始 val / 原始训练+augmented val / augmented 训练+augmented val)。Hollow star 预测与 solid star 实测吻合,验证 scaling law 在数据受限的 robot learning 上仍然适用。
主要 take:augmentation 不可省——无 augmentation 在 OOD val 上显著差。这个结论对实际数据采集有指导意义:在搞不到更多 raw demonstration 时,砸钱搞 augmentation 比堆 trajectory 数更划算。
关联工作
基于
- π0 / π0.5: 主 baseline;Lumo-1 借鉴了 π0.5 的 hierarchical subtask prediction 思路并改进为 subtask completeness prediction
- Qwen2.5-VL-7B: backbone
- AWE (Shi et al. 2023): waypoint-based imitation 的核心算法,被用来做轨迹分解
- DeepSeekMath GRPO: RL 算法
- DAPO: RL 训练稳定化技巧(clip-higher, 高温 sampling)
- Data-Constrained Scaling Law (Muennighoff et al. 2023): 用其 functional form 拟合 robot data scaling
对比
- OpenVLA / RT-1 / RT-2: 早期 VLA,binning-based action discretization
- FAST: DCT-based action tokenization,Lumo-1 的主要 tokenizer 对照对象
- RDT-1B: bimanual manipulation 的 unified action space 设计借鉴
- RoboBrain / RoboBrain-2.0 / Robix: 专门的 embodied reasoning VLM,VLM benchmark 对照
- GR00T-N1 / GR-3: 同期 generalist VLA,GR-3 的 4-setting 评估方案被沿用
方法相关
- ECoT / CoT-VLA / MolmoAct / Emma-X / ThinkAct: reasoning-augmented VLA 谱系
- Knowledge Insulating VLA (Driess et al. 2025): 提出 continuous fine-tune 损害 VLM 知识的观察,Lumo-1 的 discrete pre-train + continuous fine-tune 直接回应
- Flow Matching (Lipman et al. 2022): action expert 用的生成方法
- SAM / SAM2 / Grounding-DINO: 数据构造时的 perception 工具
论文点评
Strengths
- Spatial action tokenizer 是真正的方法贡献:AWE + k-means delta clustering + 8-slot 结构化模板 + top-3 sampling 是一套自洽且可工程化的方案,每个 token 对应合法 motion 这点解决了 FAST decoding error 的痛点
- Subtask completeness prediction 简单有效:是对 π0.5 hierarchical pipeline 的实质性改进,能直接被其他长程 VLA 工作借鉴
- 训练管线工程上完整、文档化充分:三阶段 token 数量、step、warmup、lr schedule 在 Table 5 都有,supp 列了详细 reasoning data 构造流程,对想做类似系统的团队是有价值的参考
- 诚实记录了 cross-embodiment 训练的副作用:Stage2 在 Unseen Instructions 上劣于 Stage1,没有藏起来;论文承认这是 VLM data 被稀释的代价
- Data-constrained scaling law 在 robotics 上的实证:是少有把 LM 侧的 scaling law 形式直接应用到 robot learning 并报告拟合度的工作,给数据采集策略提供了量化锚点
Weaknesses
- 没有 isolate “reasoning trace 是否真的 help action”:Stage2-PNP vs Stage3 的差异既包含了 reasoning trace 的贡献,也包含了额外训练 epoch 和 target-embodiment 数据的贡献。需要一个 controlled ablation:同样数据但 reasoning trace 仅作为 auxiliary supervision(不影响 action condition)
- NSR 指标隐藏分布信息:+23% action NSR 可以由”50% 大胜 + 27% 大败”或”40% 全胜 + 17% 微败”产生,paper 应该报 win/loss/tie 的细分
- Baseline 不完全对等:π0/π0.5 的 fine-tuning 数据是否完全相同未细说;“strict identical setup” 描述偏定性
- 没有 code、weight、Astribot S1 dataset release:尽管是产品 paper 可以理解,但论文中提出的 spatial action tokenizer 等通用组件本可以单独开源
- 声称的”context-aware arm selection”等”涌现行为”缺乏 ablation:是 reasoning 真的 generalize 到了 collision avoidance,还是 demo data 里就有这种 behavior 被 imitation 出来?
- Q1 评估有 cherry-picking 风险:与 RoboBrain-7B-2.0 / Robix-7B 比较时,只对比了 7 个 spatial-heavy benchmark,未涉及 general VQA / 推理 benchmark;Stage1 之后的 general capability 是否退化未直接测
- 5.84% VLM data 这个数字哪来的没解释——对一个声称 “preserve general knowledge” 的 co-training 方案,这个比例的 design choice 应该有依据
可信评估
Artifact 可获取性
- 代码: 未开源(截至 v2,无 GitHub 链接)
- 模型权重: 未发布 checkpoint
- 训练细节: 高层描述 + Table 5 给出三阶段 lr/optimizer/step/warmup/GPU 数;spatial action tokenizer 的 cluster 数 (150) 给出,但 reconstruction error threshold 数值缺失;RL reward 的 未公布
- 数据集: 部分公开——大量基于开源数据 (AGIBot, ShareRobot, RefSpatial, Cambrian, LLaVA, Pixmo etc.);自采 Astribot S1 数据未公开
Claim 可验证性
- ✅ VLM benchmark 表现超过 baseline:Table 2 的 7 个 public benchmark 数字独立可复现(baseline 也是 public 模型)
- ✅ Spatial action tokenizer 比 FAST/binning 更紧凑:定义层面可推(每个 chunk ≤ 5 token vs FAST 的可变长 + binning 的 D×H),无需经验验证
- ⚠️ “surpasses π0/π0.5 across all 6 fine-tuning tasks”:每任务 10 episodes × 2 layout = 20 trial,样本量小;layout 是否泄露到训练数据无法独立验证
- ⚠️ “strong generalization to novel objects”:Unseen Objects 的 105 个 novel item 与训练 60 item 是否 visually similar、是否真的”novel”无具体描述
- ⚠️ “context-aware arm selection emerges from reasoning”:单帧定性 demo (Fig. 11),未做 ablation 区分 reasoning 贡献 vs demo bias
- ⚠️ “data-constrained scaling law applies to robot data”:3 条曲线 + 6 个 checkpoint 的拟合,样本太少难以判断是否 overfit 到这套 fitting form
- ❌ “purposeful action via embodied reasoning” 这一框架性 claim:marketing 修辞,paper 没定义”purposeful” 的可量化指标,也未与”action 不联合 reason 但同样多 epoch + 同样 data”的对照组比较
Notes
- 真正可复用的 piece:spatial action tokenizer + subtask completeness prediction。前者可以直接用在任何 cross-embodiment VLA 项目里,后者可以套到任何 long-horizon hierarchical agent
- 对 Astribot 商业逻辑的观察:他们先发了 S1 硬件 paper(Gao et al. 2025),现在补 VLA paper,整体是”硬件 + 模型”垂直整合的 strategy。模型的开放性受商业约束,论文的存在更多是 talent recruiting 和 brand building
- 对 reasoning-VLA 谱系的判断:从 ECoT (2024) → CoT-VLA / MolmoAct → π0.5 → ThinkAct → Lumo-1,“显式 reasoning trace”似乎在 community 内成为 default。但是否所有 task 都需要 reasoning trace? Lumo-1 自己也承认 partial reasoning 在大多数 case 已经够用,full reasoning latency 高。这可能暗示:reasoning trace 的边际价值集中在 OOD / 复杂语义 case,对常规 task 是 overhead。值得做一个”按需 reasoning”的工作
- 下一步可能 worth digesting:ThinkAct (2507)、π 0.6 (2511, ref 1, 还没读)
- ❓ 论文里大量提”3D understanding”,实际仍在 2D 头相机上做 waypoint projection;真正的 3D reasoning(point cloud / depth-aware policy)并未触及
- ❓ RL 阶段”action reward”用 ground-truth action 误差做 supervision,本质还是 imitation;和 outcome reward 路线(如 SimpleVLA-RL)孰优孰劣未对比
Rating
Metrics (as of 2026-04-24): citation=1, influential=0 (0.0%), velocity=0.22/mo; HF upvotes=0; github=N/A (无代码仓库)
分数:2 - Frontier 理由:在当前 reasoning-augmented VLA 谱系(ECoT → CoT-VLA / MolmoAct → π0.5 → ThinkAct)里,Lumo-1 是一个方法范式代表工作——spatial action tokenizer(AWE + k-means + 8-slot 模板)和 subtask completeness prediction 是 Strengths 1/2 点明的可复用组件,且在 6 个 fine-tuning 任务上对 π0/π0.5 head-to-head 领先,属于必须比较的 frontier baseline。未到 Foundation 档的原因是 Weaknesses 里已列明的几项:无代码/权重/数据释放、核心 claim(context-aware arm selection、“purposeful reasoning”)缺 isolation、每任务 ~20 trial 样本量小;加上商业实验室产品 paper 的 framing,目前也未见社区把它作为 de facto baseline(对比 π0 已成为 VLA 领域标配)。未落到 Archived 是因为方法贡献非 incremental,且 Astribot S1 平台 + 三阶段 recipe 对新团队有参考价值。2026-04 复核:4.5 月仅 1 citation / 影响力 0 / HF=0 / 无代码,社区采纳信号几乎缺席;但 <3mo 豁免刚过的 window + 方法组件对 reasoning-VLA 谱系的参考价值仍在,暂维持 Frontier,后续若 citation 继续停滞应考虑降至 Archived。