Summary
Fast-dVLM: Efficient Block-Diffusion VLM via Direct Conversion from Autoregressive VLM
- 核心: 直接把预训练 AR VLM (Qwen2.5-VL-3B) 单阶段微调成 block-diffusion VLM,比”先文本扩散再多模态”的两阶段路径在同等 budget 下显著更好
- 方法: Direct conversion + block-size annealing + causal context attention + auto-truncation mask + vision-efficient concatenation + self-speculative decoding + SGLang/FP8
- 结果: 11 个多模态 benchmark 上短答平均 74.0 与 AR baseline 持平,端到端 6.18× 加速;MMMU-Pro-V long-form 仍落后 1.7 点
- Sources: paper | website | github
- Rating: 2 - Frontier(diffusion VLM 方向一个清晰 actionable 的 direct-conversion finding + 完整 system stack,但 main thesis 未做 budget scaling 验证、long-form 差距未解决、加速归因混淆算法与工程,属 frontier 参考而非 foundational)
Key Takeaways:
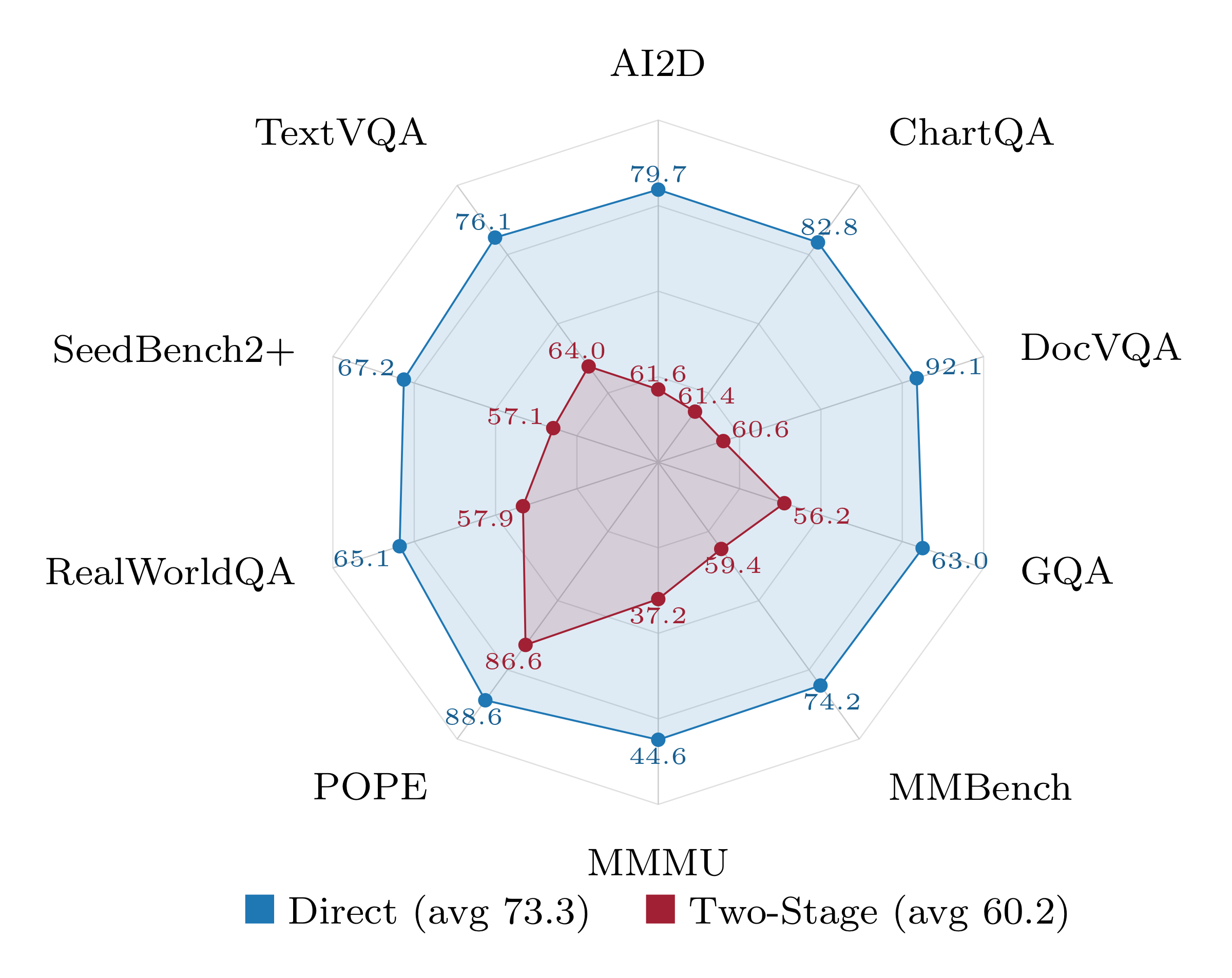
- Direct > Two-stage 不是 ceiling 差异,是 budget 利用效率差异:Direct path 73.3 vs Two-stage 60.2(同 2M 样本同 1 epoch),diff 高达 +31.5 (DocVQA)、+21.4 (ChartQA)、+18.1 (AI2D)。多模态对齐一旦放弃就要重新学,损耗远超直觉。
- Causal context attention 是不可去掉的组件:去掉后平均掉 22.5%,MMMU-Pro-V 直接掉 58.9%。block-level bidirectional context 看似”对称更优雅”实则破坏 AR 预训练表示,且让 self-speculative verification 无法 piggyback。
- 加速主要来自系统栈而非算法:算法层 (MDM + spec decode) 只有 1.98×,剩下的 3× 来自 SGLang 调度 + FP8。把”6.18× speedup”拆开看,diffusion VLM 的算法增益其实有限。
- Long-form generation 是 block-diffusion 的结构性短板:MMMU-Pro-V CoT 上 MDM 比 AR 落后 4.9 点,speculative 才追到 1.7 点;论文承认”sequential coherence over many tokens”对 block-parallel 不利。
Teaser. Overview of Fast-dVLM——三联图:(a) MMMU-Pro-V 上 accuracy vs speedup,Fast-dVLM 接近 AR baseline;(b) 与 Qwen2.5-VL-3B 在 11 benchmark 上的 near-lossless 对比;(c) 累计 6.18× 端到端加速分解。
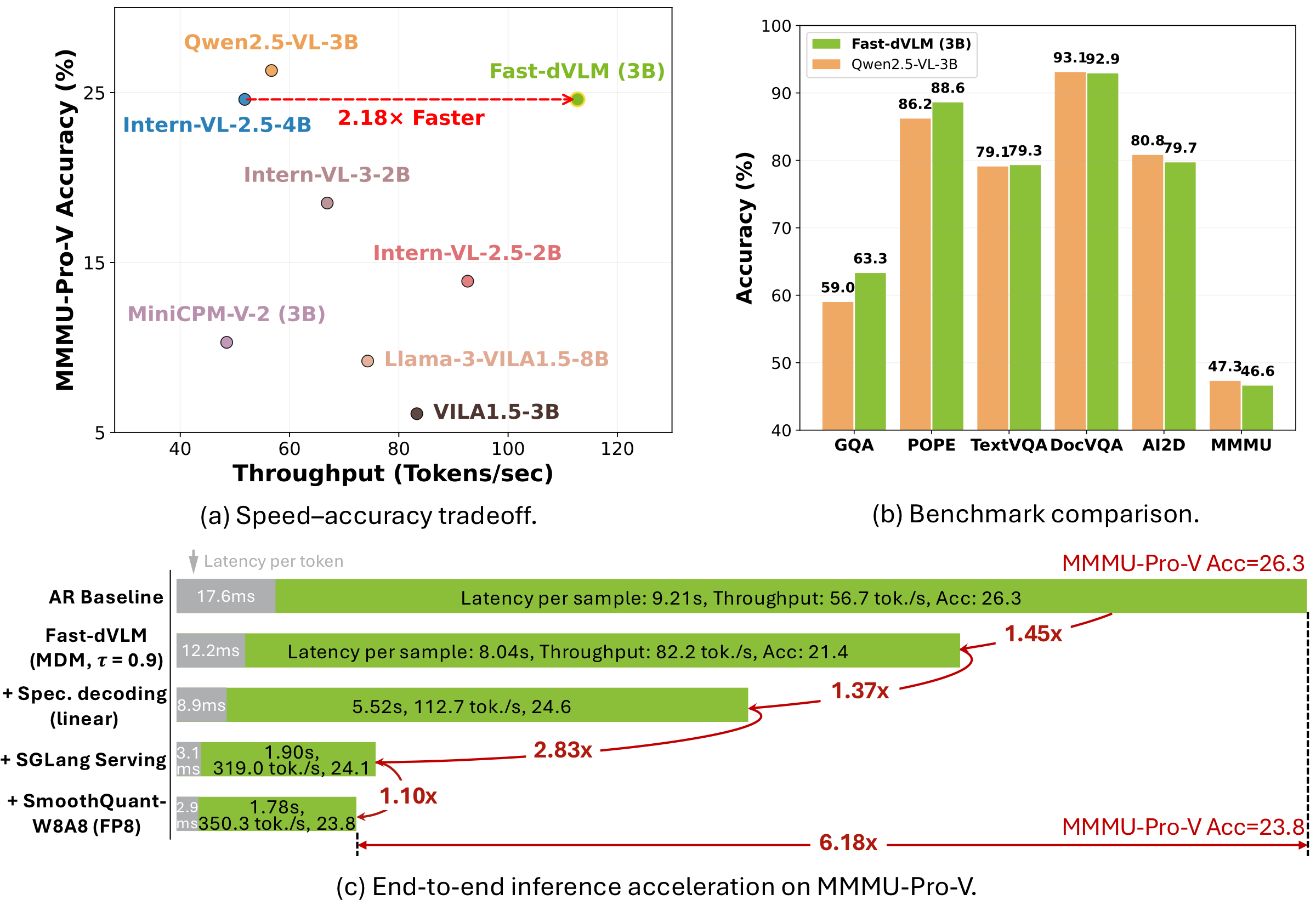
Demo Video. Fast-dVLM-3B vs Qwen2.5-VL-3B realtime throughput
问题与定位
VLM 部署在 robotics / autonomous driving 等 physical AI 场景时,工作负载是 batch-size-1:每台机器/车独立处理自己的观察流。AR decoding 在这个 regime 下是 memory-bandwidth-bound——为生成每个 token 都要把整个模型权重 load 一遍,但只用了 compute 的一小部分。Block-diffusion 通过一次 denoise 多个 token,把工作负载推向 compute-bound,能更好利用硬件并行。
但把 diffusion 扩到 VLM 上有四个具体挑战:
- 转化策略:预训练 AR VLM → diffusion VLM 是 two-stage(先文本扩散再多模态)还是 direct(一步多模态扩散微调)?
- 多轮边界:响应可能极短(如单字母选项),最后一个 denoising block 会越界进入下一轮 prompt,泄露未来信息。
- 训练效率:noisy-clean 双流拼接会把 vision embedding 复制到两个 stream,但 vision token 从不被 corrupt,纯属浪费。
- Causal 兼容性:block-level bidirectional context 会破坏预训练的 causal 结构,并让 AR-style speculative verification 无法用。
方法
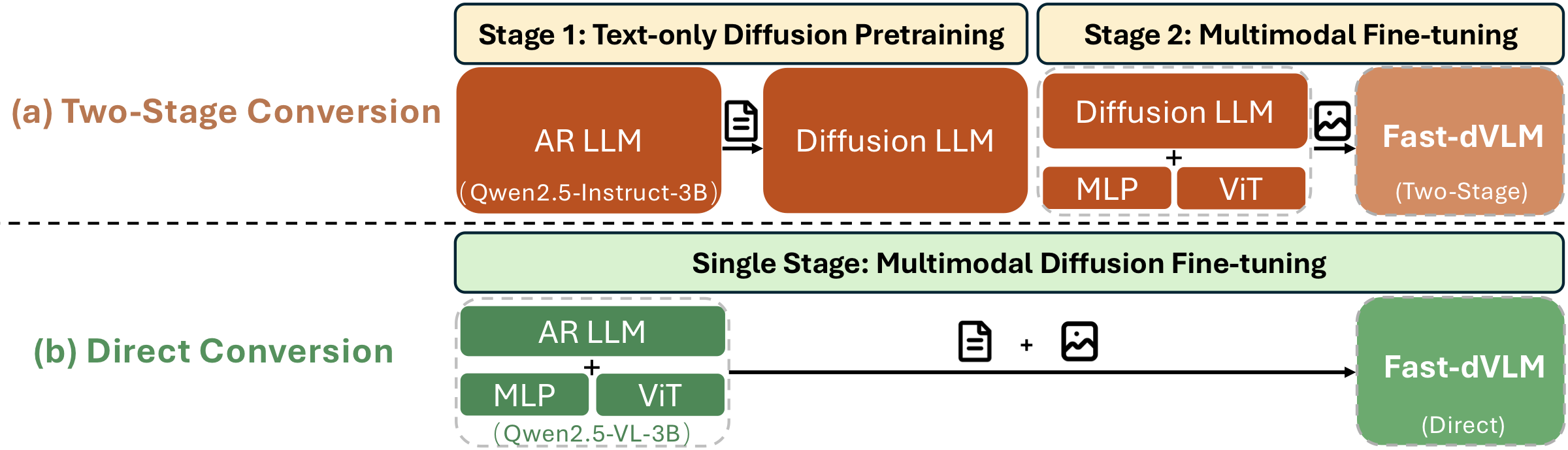
直接转化 vs 两阶段:核心实证
两条路径都从 Qwen2.5-VL-3B 出发,使用相同的 ~2M 多模态样本、单 epoch:
- Two-stage:先用 300K 文本样本按 Fast-dLLM v2 配方把 Qwen2.5-Instruct-3B 变成 diffusion LLM,再接 vision encoder + projector 多模态微调
- Direct:直接对完整 AR VLM 做单阶段 block-diffusion 微调
Figure. AR-to-diffusion 两条转化路径
结果:direct path 平均 73.3 vs 60.2,10/10 benchmark 全胜;diff 在 knowledge/reasoning-heavy 任务上最大(DocVQA +31.5、ChartQA +21.4、AI2D +18.1)。论文的解释(也是它的 main thesis):两条路径ceiling 相近,但 direct path 因为继承了 VLM 预训练阶段已经获得的多模态对齐,单位 budget 利用更高。Two-stage 从 text-only LLM 出发要把这套对齐重新学一遍。
❓ “ceiling 相近” 是个未被实验验证的假说——只有同等 budget 下的对比,没有把 two-stage 训到饱和的曲线。如果给 two-stage 更多数据,它能否追上?这个问题在论文里用”hypothesize”带过了。
Figure. Radar chart 对比
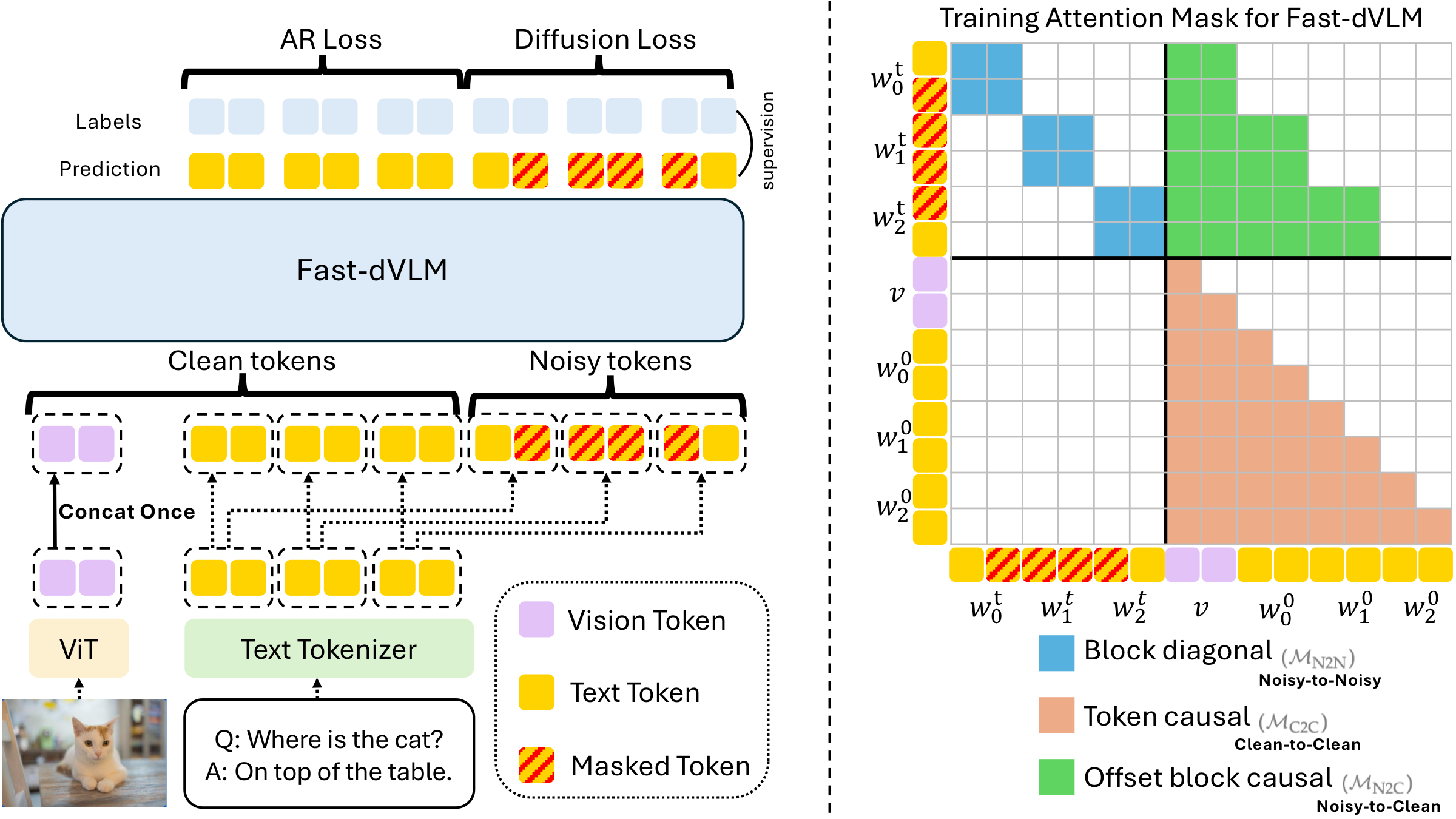
训练架构:Three Attention Rules
设输入序列为 ,仅对 response text token 加噪生成 noisy stream ,与 clean stream 拼接为 。Attention mask 三条规则:
- N2N ():noisy token 在自己 block 内双向互相 attend,支持并行 denoising
- N2C ():noisy token attend 之前 block 的 clean context,包括 vision token
- C2C ():clean stream 内部 token-level causal attention——这是与 Fast-dLLM v2 (block-level context) 的关键差异,保留 AR 表示并支持 self-speculative 的 AR verification
Figure. Training architecture and attention mask(B=2)
训练 Recipe 四件套
-
Block-size annealing:candidate sizes ,按训练进度 取 。先学小 block 的精细 denoising,再升级大 block 的大 corruption span。Ablation 显示去掉 annealing 平均掉 4.4%,MMMU-Pro-V 单项掉 32.5%。
-
Auto-truncation mask:把每条响应的最后一个 block 在响应边界处截断,避免 N2N 让 noisy token attend 到下一轮 prompt 的 token。去掉它平均掉 3.7%,MMMU 掉 14.4%。
-
Vision-efficient concatenation:vision embedding 只放 clean stream,noisy stream 只含 text 位置(vision 通过 N2C 被 attend)。Qwen2.5-VL-3B context 2048 下,peak memory -15.0%、训练时间 -14.2%,且无损。这是少数纯 engineering 优化但收益明确的点。
-
Joint objective:
第一项是 diffusion loss(noisy stream),第二项是 causal LM loss(clean stream)。两个 head 共享 。前者学并行 denoising,后者保住 AR 生成能力。
推理:Causal Context + Self-Speculative Decoding
每个 block 由一个 AR step 从 cached causal context 生成第一个 token 作为种子,剩余 位填 [MASK] 并迭代 denoise。这与训练时的 causal attention 模式天然对齐。
Self-speculative block decoding:diffusion mode 一次性 draft 所有 个 token,causal mode 自回归地 verify,接受最长 matching prefix 并裁剪 KV cache。两个变体:
- Linear:每 block 两遍 forward(draft + verify)
- Quadratic:fuse verify 和下一 block 的 propose 到一遍 forward,输入 token
❓ Quadratic 在 Tokens/NFE 上更高,但 wall-clock TPS 更差——因为 的非标准 attention pattern 现有 kernel 没优化。这是个典型的”理论增益被工程实现卡住”的例子。
系统集成:SGLang + FP8
接入 SGLang 的 scheduler,扩展支持 alternating bidirectional-draft / causal-verify attention,共享同一 paged KV cache。叠加 SmoothQuant W8A8 (FP8) 量化。
实验
Main Results:Short-answer 持平、Long-answer 仍落后
11 个 benchmark,VLMEvalKit 评测,单 H100 batch=1:
Table. 主结果对比(diffusion VLMs 中 best/2nd-best)
| Model | AI2D | ChartQA | DocVQA | GQA | MMBench | MMMU | POPE | RWQA | SEED2+ | TextVQA | Avg | MMMU-Pro-V | Tok/NFE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen2.5-VL-3B (AR) | 80.8 | 84.0 | 93.1 | 59.0 | 76.9 | 47.3 | 86.2 | 65.1 | 68.6 | 79.1 | 74.0 | 26.3 | 1.00 |
| LaViDa | 70.0 | 59.0 | 64.6 | 55.5 | 70.5 | 43.3 | 81.4 | 54.5 | 57.7 | 60.3 | 61.7 | 10.5 | 1.00 |
| Dimple | 74.4 | 63.3 | 37.7 | 59.2 | 74.6 | 45.2 | 86.2 | 55.4 | 51.7 | 61.6 | 60.9 | 12.4 | 1.00 |
| LLaDA-V | 77.8 | 78.3 | 83.9 | 53.4 | 82.9 | 48.6 | 81.8 | 63.2 | 68.7 | 64.7 | 70.3 | 18.6 | 1.00 |
| Fast-dVLM (MDM) | 79.7 | 82.8 | 92.1 | 63.0 | 74.2 | 44.6 | 88.6 | 65.1 | 67.2 | 76.1 | 73.3 | 21.4 | 1.95 |
| Fast-dVLM (spec.) | 79.7 | 83.1 | 92.9 | 63.3 | 74.3 | 46.6 | 88.6 | 65.1 | 67.2 | 79.3 | 74.0 | 24.6 | 2.63 |
- Short-answer:spec 变体平均 74.0,与 AR baseline 完全打平,diffusion VLM 中 8/11 项最优
- Long-answer (MMMU-Pro-V):MDM 21.4 (-4.9)、spec 24.6 (-1.7),仍未追上 AR
- GQA (+4.0)、POPE (+2.4):bidirectional context 在 holistic visual reasoning 上反而优于 AR
Ablation:Causal Context 是命门
Table 3. Recipe 消融
| Setting | MMBench | MMMU | POPE | MMMU-Pro-V | RealWorldQA | SeedBench2+ | Avg |
|---|---|---|---|---|---|---|---|
| Full recipe | 72.4 | 43.0 | 85.1 | 15.1 | 61.1 | 66.9 | 57.3 |
| w/o causal context | 58.5 (-19.2%) | 29.9 (-30.5%) | 71.1 (-16.5%) | 6.2 (-58.9%) | 60.0 | 40.5 (-39.5%) | 44.4 (-22.5%) |
| w/o annealing | 68.6 | 43.4 | 81.4 | 10.2 (-32.5%) | 58.4 | 66.8 | 54.8 (-4.4%) |
| w/o auto-truncation | 68.4 | 36.8 (-14.4%) | 84.3 | 13.5 | 61.0 | 67.1 | 55.2 (-3.7%) |
Causal context attention 是远超其他组件的核心——去掉它平均掉 22.5%,MMMU-Pro-V 几乎崩了 (-58.9%)。这个数字其实是论文最重要的实验结果之一:它解释了为什么 Fast-dLLM v2 的 block-level context 直接搬过来不行,必须改造。
推理加速分解
Table 4. 加速 stack 分解(MMMU-Pro-V)
| Setting | MMMU-Pro-V | TPS | SpeedUp |
|---|---|---|---|
| AR baseline | 26.3 | 56.7 | 1.00× |
| Fast-dVLM (MDM, τ=0.9) | 21.4 | 82.2 | 1.45× |
| + Spec. decoding (linear) | 24.6 | 112.7 | 1.98× |
| + SGLang serving | 24.1 | 319.0 | 5.63× |
| + SmoothQuant-W8A8 (FP8) | 23.8 | 350.3 | 6.18× |
值得注意的两点:
- 算法贡献只占总加速 1.98×——SGLang 调度 (×2.84) 和 FP8 量化 (×1.10) 贡献了剩下大部分
- 每加一层都不是免费:SGLang 让 accuracy 从 24.6 → 24.1,FP8 再到 23.8。“6.18×” 与最高 accuracy 24.6 不同时成立
Figure. Threshold τ 对 accuracy / tokens-per-step 的影响
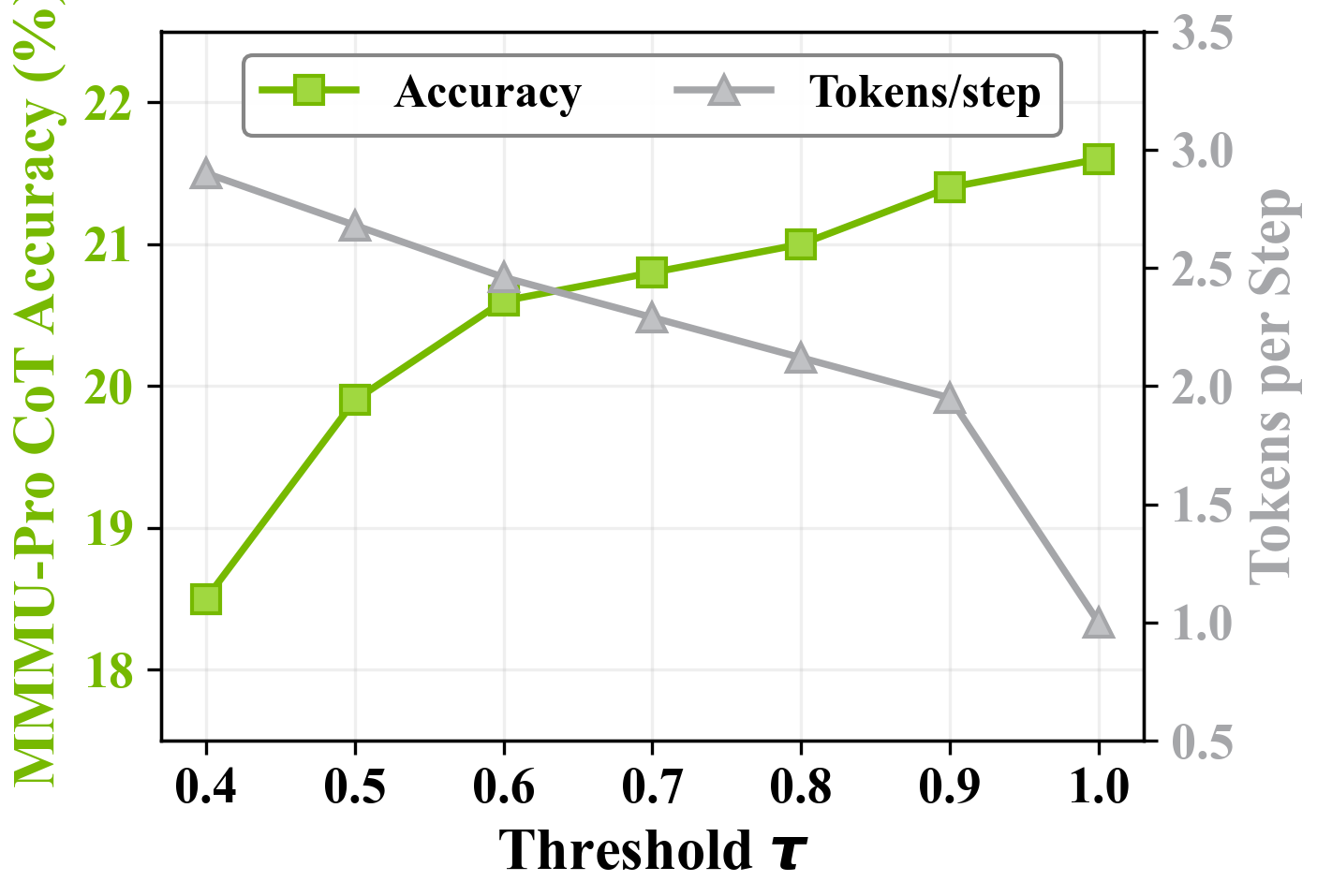
τ=0.9 是 sweet spot:throughput 翻倍 (1.95 tok/step) 几乎不掉精度。τ=0.4 推到 2.90 tok/step 但精度掉到 18.5。
Figure. Linear vs quadratic spec decoding 在不同 block size 下
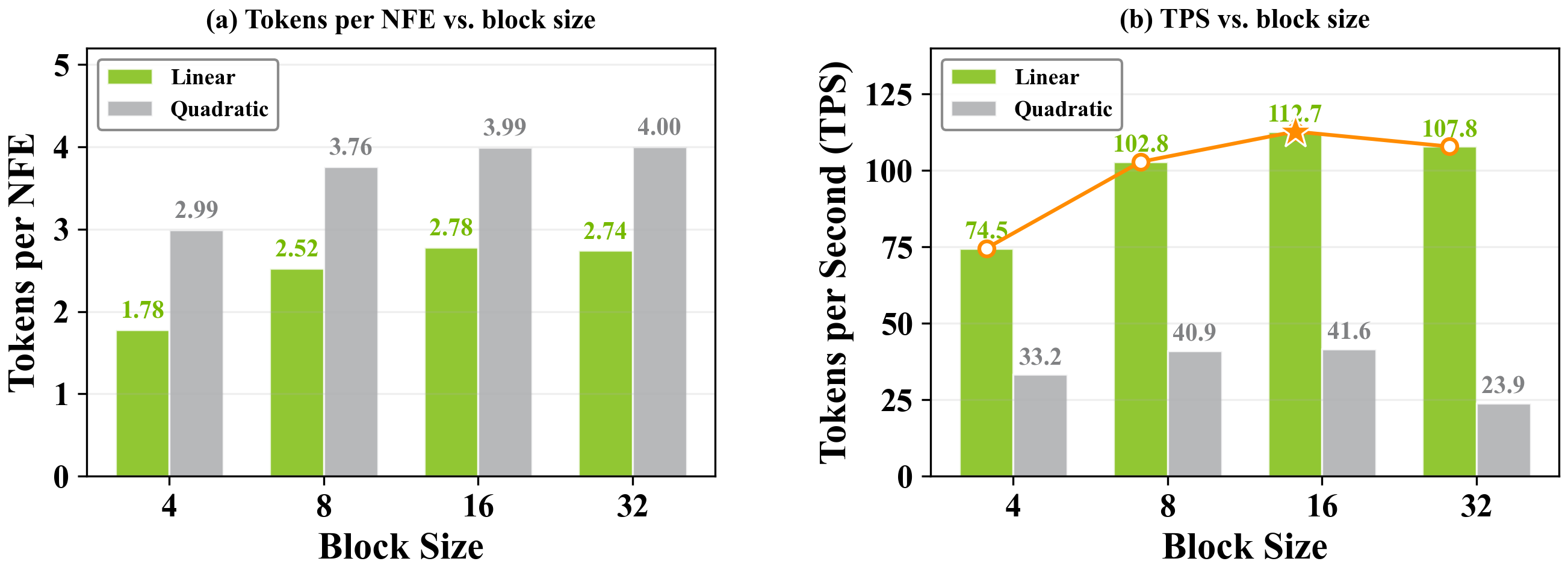
Linear 在 block size 16 达到 TPS 峰值 (112.7),32 时下降;quadratic 始终 TPS 较低,因 attention pattern 没有 kernel 支持。
Physical AI Case Studies
项目页展示了 autonomous driving 和 robotic manipulation 的定性 case:driving 场景 149-token 响应 73.3 tok/s,manipulation 488-token 8 步 guide 73.0 tok/s,两者 Tokens/step > 1.68——支持论文 “physical AI deployment” 的卖点。

❓ Case study 是 cherrypick 的,而且这两个场景的 VLM 输出在真实 robot 系统里通常不是端到端 latency 瓶颈(perception + control loop 还有别的开销)。论文用 “physical AI” 作为 motivation 很自然,但要把这种加速的实际价值兑现,需要进一步验证。
关联工作
基于
- Fast-dLLM v2 (Wu et al. 2025, arxiv 2509.26328): 直接前作,提供 block-diffusion + complementary masking + dual-stream block attention 框架;Fast-dVLM 在其上把 block-level context 改为 token-level causal context,加上 VLM-specific 适配
- Qwen2.5-VL-3B (Bai et al. 2025): backbone,所有实验都从这里 fine-tune
- SGLang (Zheng et al. 2024): 推理服务框架,扩展其 scheduler 支持 alternating bidirectional-draft / causal-verify attention
- SmoothQuant (Xiao et al. 2023): W8A8 (FP8) 量化方案
对比
- LaViDa, Dimple, LLaDA-V: 之前的 diffusion VLM,但都用 full-sequence diffusion,没有 block 结构因此无法增量 KV cache
- DiffusionVL, AR2D, SDAR-VL: 引入 block diffusion + KV cache 的近期工作,但没有系统比较 two-stage vs direct conversion
方法相关
- Masked diffusion models (Sahoo et al. 2024 simple-diffusion; Nie et al. 2025 LLaDA): 文本 masked diffusion 的基础方法
- Block-wise discrete diffusion (Arriola et al. 2025): block diffusion 的核心思想来源
- Dream (Ye et al. 2025): full-attention diffusion LLM 的 580B token 训练量,被 Fast-dLLM v2/dVLM 用作”500× data reduction”对比基准
- Self-speculative decoding (Samragh et al. 2025; Chen et al. 2026 dflash; Liu et al. 2025 tidar): self-speculative 的算法思路;quadratic 变体 fuse verify+propose 来自 tidar
论文点评
Strengths
- Direct vs two-stage 的 controlled comparison 很有说服力:同 backbone 同 budget 同 epoch,10/10 benchmark 一致结论,是一个清晰的 actionable finding——后续做 diffusion VLM 的 default 应该是 direct path。
- Causal context attention 的 ablation 实验本身有价值:22.5% 平均下降证明 block-level context 不能直接搬,是对前作 (Fast-dLLM v2 / DiffusionVL / AR2D) 的一个重要修正。
- Vision-efficient concatenation 是漂亮的”无损”工程优化:基于 vision token 永远不被 corrupt 这个简单观察,省 15% 内存 + 14% 训练时间。这种”看清楚问题就拿到 free lunch”的优化是 first-principle 思考的好例子。
- 完整的 system stack:SGLang + FP8 集成是少见的”算法到 production-grade serving”的全栈论文。
Weaknesses
- “Same ceiling, different efficiency” 是未验证的 hypothesis:作者只跑了 same-budget 对比就声称两条路径 ceiling 相近,没有 budget scaling 曲线。如果 two-stage 在更大 budget 下能追平,论文 main thesis 就站不稳。
- Long-form reasoning 落后没有解决:MMMU-Pro-V 上 spec 仍落后 AR 1.7 点,论文用”future work: longer annealing + larger data”带过。这是 block-diffusion paradigm 的结构性问题(sequential coherence vs parallel denoising 的内在张力),不是简单 scale 能解决的。
- “6.18× speedup” 有点 misleading:算法贡献只 1.98×,剩下 3× 来自 SGLang + FP8——这两个加速都可以独立应用到 AR baseline。如果给 AR baseline 加同样的 SGLang + FP8 stack,剩下的 diffusion 优势可能只剩 1.5-2×。论文没做这个 fair comparison。
- 只在 Qwen2.5-VL-3B 一个 backbone 上验证:3B 规模、单 backbone,结论的 generalizability 不明。larger model 上 AR 的内存瓶颈相对更轻(compute 占比更大),diffusion 的优势会不会缩水?
- Quadratic spec decoding 的 negative result 处理过于轻描淡写:理论 NFE 更优却 wall-clock 更差,这本身是个有信息量的 finding,应该展开讨论 attention kernel 的限制和未来 fix 路径,而不是一句”current kernels not optimized”。
可信评估
Artifact 可获取性
- 代码: inference + 部分 training(fast_dvlm/ 目录有 chatbot 和 inference;training code 见 v2/,因为 fast_dvlm 共用 LMFlow 框架)
- 模型权重: Fast_dVLM_3B 已发布
- 训练细节: 完整披露——64×H100 (8 nodes × 8 GPU)、DeepSpeed ZeRO-2、BF16、cosine LR peak 5e-6、warmup 0.03、per-device bs=1、grad accum=4、global bs=256、1 epoch、、
- 数据集: 开源(ShareGPT4V、LLaVA-Instruct、DVQA、ChartQA、AI2D、GeoQA、DocVQA、SynthDoG),按 NVILA 配方混合,~2M samples
Claim 可验证性
- ✅ “6.18× end-to-end speedup”:Table 4 完整分解,每层都有 TPS 数据,可在 H100 上独立复现
- ✅ “Direct path 73.3 vs Two-stage 60.2”:Figure 4 / Section 4.3 controlled comparison,trained model 已开源
- ✅ “11 benchmarks, AR-equivalent quality on short-answer”:用 VLMEvalKit 评测,可复现
- ⚠️ “Both strategies share similar performance ceiling”:仅 hypothesis,无 budget scaling 实验支撑
- ⚠️ “Particularly impactful for physical AI deployments”:仅 cherrypicked qualitative cases,无端到端 robot/AV 系统 latency 测量
- ⚠️ “AR baseline 56.7 TPS”:作为 6.18× 的分母,没说明 AR baseline 是否也用了 SGLang + FP8 同等优化(应该没有,那就是不公平比较)
Notes
- 这篇论文的真正 insight 在于 direct conversion 的 budget efficiency 优势——这个发现对所有想做 modality extension of diffusion LM 的工作都适用(不只 vision,extending to audio/video 同理可推)
- “block-diffusion VLM” 这个 paradigm 本身的天花板还不清楚:long-form CoT 上 1.7 点的 gap 是 small but persistent。如果未来 reasoning model 主导,这个 paradigm 可能会被边缘化
- 论文反复强调 “physical AI” / “robotics / autonomous driving” motivation,但实际 benchmark 都是传统 VLM benchmark。真正的 batch-1 edge inference 上的端到端价值没有被实验验证——这是一个值得后续做 spatial-reasoning / VLA 工作的人留意的 gap:可以做一个 “Fast-dVLM on real robot/driving stack” 的 follow-up
- Direct-path 的 finding 反过来对 AR LLM → diffusion LLM 转化也有启示:是不是应该等模型在某 modality / domain 上完成 alignment 之后再 convert,而不是在 base model 上 convert?这个角度论文没明说但隐含
- 一个开放问题:causal context attention 的”必要性”是否会随模型规模缩水?如果 7B/13B model 表示更鲁棒,bidirectional context 的破坏可能没那么严重
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.00/mo; HF upvotes=0; github 940⭐ / forks=116 / 90d commits=2 / pushed 10d ago
分数:2 - Frontier 理由:field-centric 看,这是 diffusion VLM 方向一篇值得参考的 frontier 工作——direct vs two-stage 的 controlled comparison 和 causal context ablation (-22.5%) 是清晰的 actionable findings,system stack (SGLang + FP8) 完整。但不到 Foundation:main thesis “same ceiling, different efficiency” 是未验证 hypothesis,long-form 差距 (-1.7) 未解决,“6.18×” 归因混淆算法与工程栈(算法只贡献 1.98×),且只在单 backbone 3B 规模验证。相邻档对比:比 Archived 多了明确的社区价值(已开源权重 + 可复现评测 + 对前作 block-level context 的重要修正),但距离 Foundation 的”方向必读必引”还差持久性验证。