Summary
The Unreasonable Effectiveness of Scaling Agents for Computer Use
- 核心: 通过对 CUA 做 wide test-time scaling(多 rollout 选优)、用 behavior narrative 而非原始 trajectory 比较,达到 OSWorld 72.6% 超人类水平
- 方法: Behavior Judge (BJudge) = Behavior Narrative Generator(VLM 把 (s_i, a_i, s_{i+1}) 三元组转成 fact)+ Comparative Behavior Evaluator(MCQ 一次性比较 N 条 narrative 选最佳);底座是改良后的 Agent S3(去掉 manager-worker 层级、加入可调用 coding agent 的 flat policy)
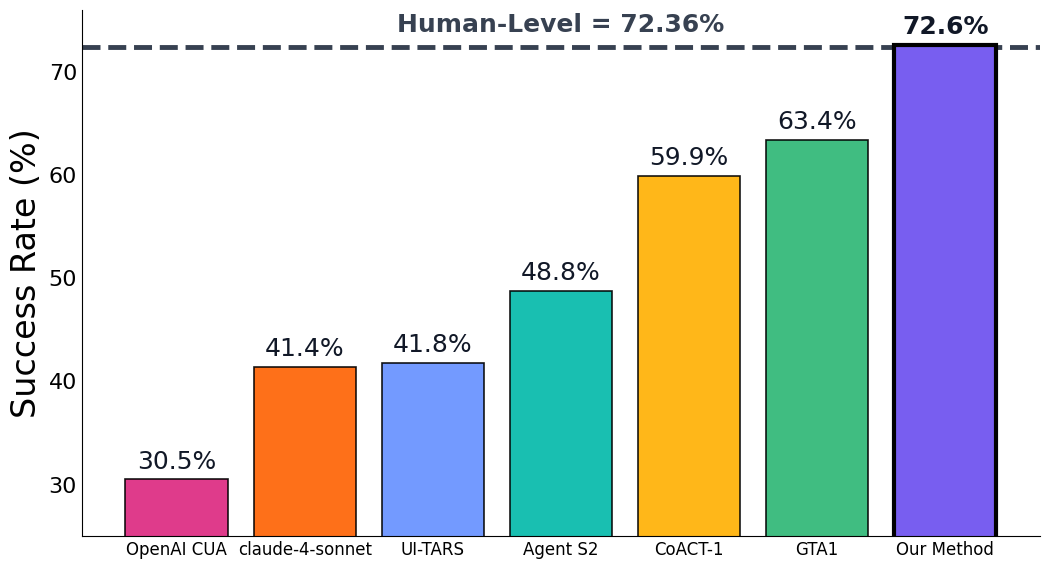
- 结果: OSWorld 100-step SR 72.6%(GPT-5 + Opus 4.5 各 5 rollouts),相对前 SoTA +9.2%,超过 human 72.36%;WindowsAgentArena +6.4%,AndroidWorld +3.5%
- Sources: paper | github
- Rating: 2 - Frontier(CUA test-time scaling 当前最强 baseline,OSWorld 72.6% 超人类的工程化范式;但本质是 BoN + selector 的已知组合,非开创性方法)
Key Takeaways:
- Wide scaling > step-wise scaling:在长程 CUA 任务上,并行多 rollout 选优的收益显著高于单 rollout 内的 step-wise BoN(GTA1 风格)。原因是 step-wise BoN 已 commit 到当前 plan,难以跳出”难解路径”。
- Behavior narrative 是关键 representation:把 trajectory 压成”action–effect facts”再喂给 judge,比直接看 screenshot / trajectory summary / naive caption 都好(60.2 vs 56.0/55.0/56.8);对 transition 而非单 state 生成 fact 是 insight。
- Comparative > independent ranking:BJudge 用 MCQ 一次性看所有候选,比 WebJudge 风格的独立打分稳定且 scaling 更好——后者在 N=10 反而下降。
- Mixture-of-models 提升 coverage 与 SR 的上界:GPT-5 + Opus 4.5 ensemble 既提 SR (71.6%) 又提 Pass@N (79.1%),“All” mixture Pass@N 达 80.5%——多样性是 diversity-driven 选优的前提。
- Agent S3 baseline 本身是大头:去掉 hierarchical planning、加 coding agent 后,相对 Agent S2 单点 SR +13.8%,LLM call -52%,时间 -62%——多数性能来自更好的底座,BJudge 在此基础上再 +10%。
Teaser. OSWorld leaderboard:BJudge 以 72.6% 超过人类 72.36% 与之前 SoTA(GTA1 GPT-5 63.4%)9.2 个绝对点。
1. Motivation:CUA 的高方差与 wide scaling
CUA 在长程任务上的核心痛点是 single-rollout 不可靠:小错误累积、UI 噪声、解空间多分支,使得同一 agent 在同一 task 上”有时成功有时灾难性失败”。
Disjoint task success 是 wide scaling 的基础观察:不同 rollout / 不同 base model 经常解决互补的子集任务,所以 Pass@N 远高于单跑 SR。
Figure 2. 三个 agent instance 在 OSWorld 上的成功任务集合互不重合,说明 wide scaling 有理论上界。

但 wide scaling 的瓶颈在于评估:长程 trajectory 信息密度高、多模态、且很多任务有多解,让”挑出最好的那一个”成为难题。OSWorld / WindowsAgentArena / AndroidWorld 的 evaluation 都依赖人写脚本,无法 scale;web-agent 领域的 VLM-as-judge(如 WebJudge)又过度依赖 web 域 rubric,不通用,且只能评单条 trajectory 而非比较多条。
❓ 论文把”判断正确性”和”在多条中选最好”耦合给同一个 judge——但前者实际上是在 reward model 的范畴,后者更接近 ranker。BJudge 用 MCQ 一次性做选择,确实回避了”绝对正确性”的判断,但当所有 rollout 都失败时它没有 abstain 机制。
2. Method:Behavior Judge
Figure 3. BJudge 架构。Behavior Narrative Generator 把每个 transition 转成 fact;Comparative Behavior Evaluator 用 MCQ 一次性比较所有 narrative。
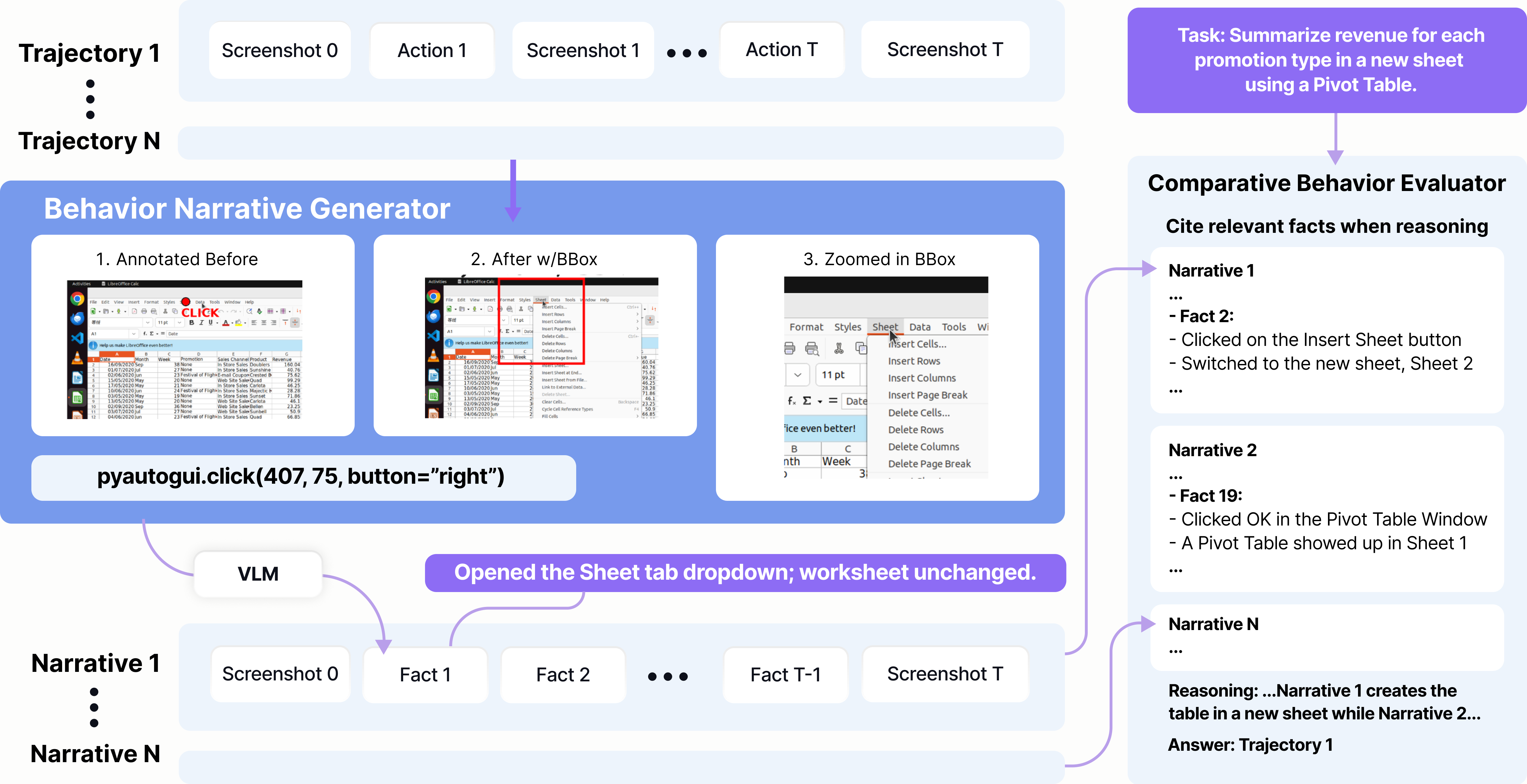
2.1 Behavior Narrative Generator
给一个 rollout ( 为 screenshot, 为 action),对每个 transition 用 VLM 生成 fact:
把整个 rollout 折叠成 narrative ,只保留首尾 screenshot 用于 grounding。
两个工程细节对成功率关键:
- Pointer 增强:对 click/tap/move/drag,在 上叠加 marker 标出指针坐标 ;在 上抽取以 为中心的方块 zoomed crop ,让 VLM 能看清像素级变化(避免”以为点中了 Save 实际没有”这类 step-level hallucination)。
- 延迟采样: 在 action 后 3 秒才截取,避免 hyperlink 跳转、加载等延迟带来的”看不到效果”。
2.2 Comparative Behavior Evaluator
给 个 base policy 各采 个 rollout,得到候选集 。把 转成 narrative 集 ,用单轮 MCQ 让 VLM evaluator 一次性挑出最好的那一个对应的 trajectory 。
MCQ 而非 pairwise tournament 的理由(Appendix E):
| Method | Time (judge calls) | Token cost |
|---|---|---|
| MCQ (one-shot) | ||
| Iterative (pairwise) |
且 N=25 上 MCQ 和 iterative 的 SR 接近(6668 vs 62~66),MCQ 一致更好或持平。
2.3 Agent S3:改良后的底座
BJudge 的输入质量取决于 base agent。作者在 Agent S2 上做两项改动:
- Flat policy:去掉 manager-worker 层级,单一 worker 在每步基于 直接 replan。理由:现代 foundation model 短程 plan 能力够强,hierarchical planning 反而会让 subgoal 变 stale。
- Coding agent:GUI policy 在每步可选择”输出 GUI action”或”调用 coding agent”。后者启动一个 budget B 的内部循环,迭代生成 Python/Bash 在 sandboxed VM 中执行,拿到 stdout/stderr/return_code 反馈,最终返回 DONE/FAIL + summary + 验证 checklist。GUI agent 接到 summary 后必须在屏幕上手动验证才能 done()。
- 与 CoAct-1 的区别:不用 AutoGen,没有独立 orchestrator——coding agent 是 GUI agent action space 的一部分,由 GUI agent 自己决定何时调用。
单点效率对比(Table 2,OSWorld GPT-5):
| Method | 100-step SR (%) | LLM calls/task | Time/task (s) |
|---|---|---|---|
| Agent S2 | 48.8 | 73.62 | 2366.80 |
| Agent S2 (no hier.) | 57.9 (+9.1) | 41.39 (-43.8%) | 1132.91 (-52.1%) |
| Agent S3 | 62.6 (+13.8) | 35.12 (-52.3%) | 891.21 (-62.4%) |
❓ 去掉 hierarchical planning 单独就 +9.1%——这等价于说 Agent S2 的 manager-worker 设计在新 foundation model 上是负收益。是不是 Agent S2 的 hierarchical 在 GPT-4 时代有用、到 GPT-5 已成累赘?这与”模型变强后框架要变简”的趋势一致。
3. Main Results
Table 1. OSWorld 100-step SR (361 tasks)。
| Method | Model | 100-step |
|---|---|---|
| Agent S2 | GPT-5 | 48.8 |
| Jedi-7B | o3 | 51.0 |
| CoAct-1 | OAI CUA + o3 + o4-mini | 59.9 |
| Agent S3 | o3 | 61.1 |
| Agent S3 | GPT-5 Mini | 49.8 |
| Agent S3 | GPT-5 | 62.6 |
| GTA1 (step-wise) | o3 | 53.1 |
| GTA1 (step-wise) | GPT-5 | 63.4 |
| Agent S3 + WebJudge (N=10) | GPT-5 Mini | 50.4 |
| Agent S3 + BJudge (N=10) | GPT-5 Mini | 60.2 |
| Agent S3 + BJudge (N=10) | GPT-5 | 69.9 |
| Agent S3 + BJudge (N=10) | GPT-5 + Opus 4.5 | 72.6 |
主结论:
- Agent S3 单跑就已超过 GTA1 step-wise scaling(62.6 vs 63.4 接近,但 GTA1 已经是 BoN);
- BJudge 在 GPT-5 Mini 上 +10.4%,在 GPT-5 上 +7.3%;
- 弱模型受益更大——这是 Pass@N 上限决定的,弱模型 pass@1 低但 pass@10 还可观。
3.1 BJudge vs WebJudge under equal budget
Figure 4. 等 rollout budget 下,BJudge 比 WebJudge 在所有 N 上都更高,且 N=10 时 WebJudge 反而掉点。
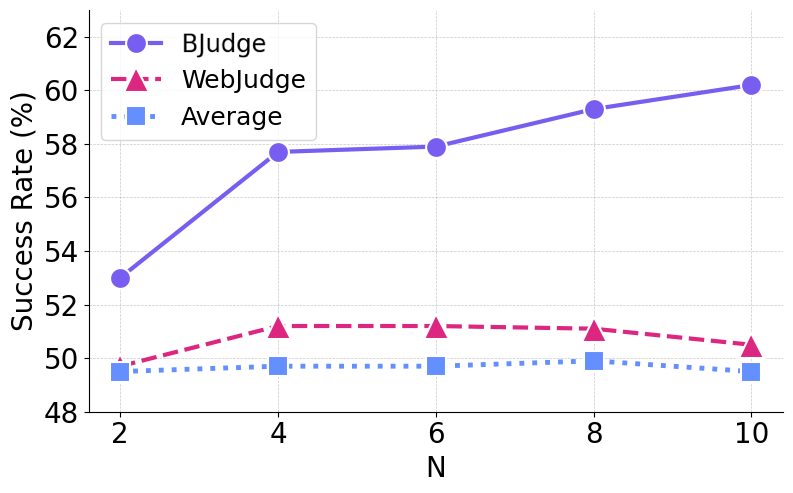
WebJudge 风格(独立打 1-5 分取最高)在 N=4 附近就 plateau 并下降——独立打分无法跨 trajectory 校准,N 越大越容易被某条”看着合理但其实失败”的 rollout 骗到。
3.2 Representation ablation
Table 3. 10 个 GPT-5 Mini rollout 下,behavior narrative 比其他 representation 高 3.4%。
| Representation | SR (%) |
|---|---|
| Screenshot Only | 56.0 |
| Trajectory Summary | 55.0 |
| Naive Captioning | 56.8 |
| Behavior Narratives | 60.2 |
启示:fact 必须从 transition 而非单 state 生成——trajectory summary 损失太多步级细节,naive captioning 没有 action 上下文。
3.3 Judge accuracy 与 failure modes
Table 4. BJudge 的判断准确率(10 个 GPT-5 rollout,OSWorld)。
| Category | Judge Subset Acc | Full Set Acc |
|---|---|---|
| Benchmark Alignment | 78.4% | 69.9% |
| Human Alignment | 92.8% | 76.3% |
Judge Subset = 159 个”至少一对一错”的可改进任务。其中 35 个 BJudge 选了”benchmark 判错但人类判对”的 trajectory——OSWorld eval script 太严,只接受 pre-defined 解。所以人对齐准确率 92.8% 才是 BJudge 的真实上界。
剩 12 个 failure:8 个是 narrative generator hallucination(VLM 看不清细节,比如负号 -17.0),4 个是 code-GUI handoff 失败(GUI agent 没识别 coding agent 的改动,覆盖掉了;BJudge 偏好”narrative 看着丰富”的 GUI 路径,反而漏掉了 coding agent 一步搞定但 narrative 稀疏的 rollout)。
❓ 第二类 failure 暴露 BJudge 的一个 bias:narrative 越丰富越容易被选中。如果 coding agent 一步完成任务,narrative 只有 1 个 fact,反而劣于充满 GUI clicks 但失败的 rollout。这是 representation 的副作用——压缩本身偏向”动作多的”。
3.4 Resource scaling
Figure 5. 总 budget = workers × per-worker steps;不同 worker 数 N 在不同总 budget 下的 SR。
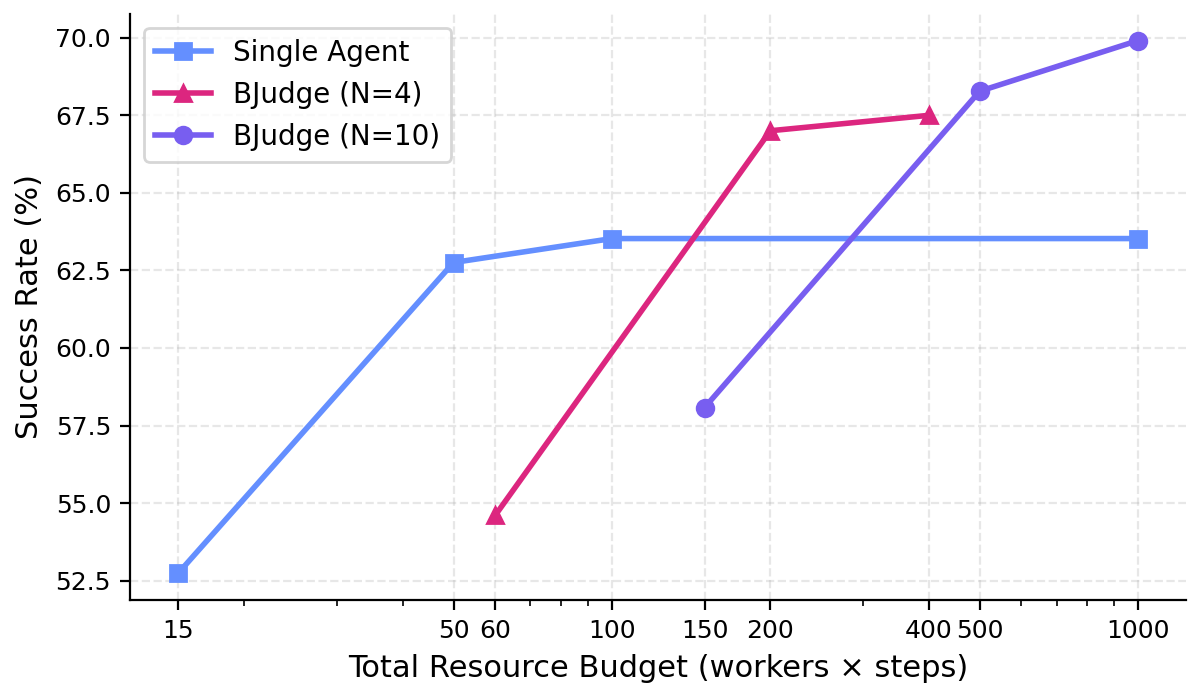
- 小 budget:单 worker 最好(每个 worker 步数太少,分散反而每个都做不完任务)。
- 大 budget:N 越大越好。BJudge (N=10) 在 budget=1000 时比单 worker 高 6.38%。
3.5 Mixture-of-models
Table 5. 不同 mixture 在 N=4 下的 SR 与 Pass@N。
| Mixture | SR (%) | Pass@N (%) |
|---|---|---|
| GPT-5 | 66.5 | 74.7 |
| Claude Opus 4.5 | 69.9 | 74.5 |
| Gemini 3 | 67.7 | 74.3 |
| GPT-5 Mini | 57.0 | 68.2 |
| GPT-5 + Mini | 64.9 | 74.1 |
| GPT-5 + Opus | 71.6 | 79.1 |
| GPT-5 + Gemini | 67.3 | 78.5 |
| Opus + Gemini | 70.6 | 78.2 |
| Opus + Mini | 66.0 | 75.6 |
| Gemini + Mini | 65.1 | 75.3 |
| All | 68.4 | 80.5 |
- “All” mixture Pass@N 最高,但 SR 不是最高——judge 的 selection 准确率限制了多样性的兑现。
- GPT-5 + Opus 4.5 是 SR 最优组合,因此最终 SoTA 配置就是这两个各 5 rollouts。
3.6 Generalization
Table 6 (WindowsAgentArena) + Table 7 (AndroidWorld):
| Benchmark | Method | SR |
|---|---|---|
| WindowsAgentArena 100-step | Agent S3 (GPT-5) | 50.2 |
| WindowsAgentArena 100-step | BJudge N=3 (GPT-5) | 56.6 |
| AndroidWorld | Agent S3 (GPT-5) | 68.1 |
| AndroidWorld | BJudge N=3 (GPT-5) | 71.6 |
零样本迁移到 Windows / Android,N=3 就能 +6.4% / +3.5%。AndroidWorld 上 coding agent 因 emulator 限制未启用——说明 BJudge 框架本身(不依赖 coding agent)也能跨 OS 用。
4. Cost & 实用性
Table 8 (Appendix B):
| Per task | Single Rollout | BN Gen | Judging (N=10) |
|---|---|---|---|
| Avg cost ($) | 0.72 | 0.11 | 0.03 |
| Avg time (sec) | 891 | 433 | 226 |
- BJudge 模块的 cost 只占 single rollout 的 1/5 左右——judge 不是瓶颈。
- 全 BJudge (N=10) 跑完 361 task 需要 17h33m(4 台 c4.8xlarge 并行)。
Cheap rollouts + expensive BJudge (Table 10):用开源 Qwen3-VL-30B-A3B-Thinking 跑 rollout(avg SR 33.3%),再用 GPT-5 做 BN gen + judging,能拉到 51.5%——开源底座 + 闭源 judge 是性价比方案。
关联工作
基于
- Agent S2: Agent S3 的直接前身,去掉 hierarchical manager-worker 后变 flat policy。
- CoAct-1: 同样把 coding agent 与 GUI agent 结合,但用 AutoGen + 独立 orchestrator;Agent S3 把两者合并到单一 GUI policy 的 action space。
对比
- GTA1 (step-wise BoN): 同样做 test-time scaling,但只在单 rollout 内 BoN——commits 到当前 plan,长程任务收益有限。
- WebJudge: web-agent 领域的 VLM judge,用独立打分。本文证明 comparative > independent,且在 N=10 处 WebJudge 反而掉点。
- Jedi-7B / Navi / UI-TARS-1.5 / MobileUse / UI-Venus: 各 benchmark 的开源对比基线。
方法相关
- Test-time scaling for LLM reasoning (Wang et al., Snell et al.): wide BoN + reward model 的思路在 LLM reasoning 已用,本文把它适配到 long-horizon CUA trajectory。
- OSWorld / WindowsAgentArena / AndroidWorld: 主要 benchmark。
- Mind2Web 2: web 领域 code-generated rubric judge,99% human agreement 但成本极高——BJudge 走了相反路线(不依赖 task-specific rubric)。
论文点评
Strengths
- Wide scaling 这条路被走通了:之前 CUA 的 test-time scaling 主要是 step-wise(GTA1 风格),证明 wide scaling 有效且更可 scale,是范式贡献。
- Representation 选择 principled:behavior narrative 不是拍脑袋,ablation 干净地隔离了”transition vs state”和”comparative vs independent”两个变量,结论可信。
- 超人类是真超:72.6% > 72.36% 不是 marketing——人类 baseline 来自 OSWorld 原文,且作者还诚实地指出 benchmark eval script 严苛,human-aligned acc 还能更高。
- Agent S3 的简化趋势对:去掉 hierarchical planning + 加可选 coding agent 的 flat policy,效率与性能双赢,与”foundation model 变强后 scaffold 应变薄”的趋势一致。
- failure analysis 不藏着:明确指出 narrative generator 会幻觉、judge 偏好”narrative 丰富”的 rollout,没掩盖 BJudge 的 representation bias。
Weaknesses
- 本质是 ensemble + selector,不是新算法:贡献是工程化的 representation + ranking 设计。可推广性强,但不是新 insight 范式——Best-of-N 的思路在 LLM reasoning 已用了两年。
- Cost 高且对闭源模型依赖:72.6% 配置需要 GPT-5 + Opus 4.5 各 5 rollouts + GPT-5 做 judge——单任务保守估计 $4-5 美元、20+ 分钟,远超实用部署阈值。
- Judge 没有 abstain:当所有 N 个 rollout 都失败时,BJudge 仍会硬选一个——这在生产环境可能是”自信地交付错误结果”。
- Independence 假设强:要求 N 个 rollout 独立从同一 initial state 出发。在用户真实桌面(非 VM snapshot)上不成立——shared online state(邮箱、cart)会引入 cross-run interference,作者自己也承认这是 deployment 障碍。
- 没和 RL-based selector 对比:BJudge 全是 prompted VLM judge,未对比 trained reward model / preference model。后者在 LLM reasoning 领域已被证明更稳定,CUA 上是否同样如此是开放问题。
- Benchmark eval 局限被混入 BJudge accuracy:Table 4 里 78.4% 提到 92.8% 主要靠”benchmark 判错”——这削弱了 78.4% 数字的对外可比性,但作者没在 main result 中区分。
- “unreasonable effectiveness” 标题略 overclaim:+9.2% 在多 rollout + ensemble + 选优框架下并不”unreasonable”——把 5 个 rollout 各自 60% 上浮到 72% 在 selector 准确率 78% 下是数学预期。
可信评估
Artifact 可获取性
- 代码: Agent-S 仓库(github.com/simular-ai/Agent-S)公开。Agent S3 与 BJudge 的具体集成代码需以仓库 README 为准。
- 模型权重: 不适用——方法纯 prompting,所有底座是闭源 API(GPT-5 / Opus 4.5 / Gemini 3)+ 开源 Qwen3-VL-30B-A3B-Thinking。
- 训练细节: 不适用,无训练。
- 数据集: OSWorld(361-task subset,去掉 8 个 Google Drive 任务)+ WindowsAgentArena (154) + AndroidWorld (116) 都是公开 benchmark。
- System prompts: Appendix H 完整公开 Behavior Comparative Evaluator 与 GUI policy 的 system prompt。
Claim 可验证性
- ✅ OSWorld 72.6% SoTA:在公开 benchmark 上,模型与配置完整披露(GPT-5 + Opus 4.5 各 5 rollouts),第三方可复现(前提是有相应 API 预算)。
- ✅ Behavior narrative > 其他 representation:Table 3 ablation 在同 N、同 base model 下做的,控制变量清晰。
- ✅ Comparative > independent:Figure 4 在等 budget 下对比,结论可信。
- ⚠️ “超人类水平”:超的是 OSWorld 论文给出的 72.36%,但人类 baseline 的具体设置(受试者背景、时间限制、是否允许 Google)未在本文复述;72.36% vs 72.6% 在小数据集(361 task)上落在统计噪声内(差 0.24% ≈ 1 个任务)。
- ⚠️ “unreasonable effectiveness”:+9.2% 来自 wide scaling + 更好的 base + ensemble 三者叠加,归因没在 main result 中分离(Agent S3 已经 +13.8%,BJudge 在此基础上才 +10%)。
- ⚠️ Judge accuracy 78.4% / 92.8%:92.8% 依赖人类判定,且只在 159 个 disjoint 任务上算的,全集 76.3% 才是更公允的数字。
- ❌ 无明显营销话术。
Notes
On taste: 这是”在已有 paradigm 下做扎实工程”的典型——wide BoN 是已知技术,behavior narrative + MCQ judging 是新组合。+9.2% 在 OSWorld 上是大数字,但 mental model 上的更新有限(已经预期 wide scaling > step-wise scaling,已经预期 comparative > independent)。给 rating=2:是 indexed reference,但不会改变方向判断。
Open questions:
- Selection ceiling:当 all-mixture Pass@N 80.5% 但 BJudge SR 71.6%,gap 8.9% 是 judge 的可改进空间。能不能把 judge 训成 reward model(用 OSWorld 的 oracle 做监督)来逼近 Pass@N?
- Online learning:每个 task 的 N rollout + selection 可以变成 (state, trajectory, reward) 数据。这天然适合 agentic-RL——为什么作者不做?是不是因为 OSWorld 太小?
- 可推广到非 GUI 任务? Behavior narrative 的”action–effect fact”抽象在 deep research、code agent 等场景是否同样有效?还是 GUI 的”screenshot before/after” 是这套表征的关键 affordance?
联想: 与 OS Agents Survey 中”reliability is the dominant bottleneck”的判断一致;与 GUI Agent Survey 中提到的”verification 和 selection 是 open problem”对应。
Rating
Metrics (as of 2026-04-24): citation=12, influential=3 (25.0%), velocity=1.79/mo; HF upvotes=25; github 10905⭐ / forks=1270 / 90d commits=3 / pushed 62d ago
分数:2 - Frontier 理由:这是 CUA test-time scaling 当前最强的 baseline——OSWorld 72.6% 超人类 + 跨 WindowsAgentArena/AndroidWorld 零样本迁移,Agent S3 + BJudge 会被 2025-2026 年的 CUA 工作作为必比对象(Strengths 1-3)。但本质是 BoN + comparative selector 的工程化组合,behavior narrative 虽 principled 但非新范式(Weaknesses 1),mental-model 更新有限。够不上 Foundation(无方法论突破、未产出新 benchmark),也远高于 Archived(短期内会是主流对比基线而非被取代)。2026-04 复核:cite=12 但 inf=3(25%)高于 rubric 典型 10%、Agent-S 仓库 10.9k⭐/1.27k forks 反映 Agent S 系列整体影响力(并非仅 S3),vel=1.79/mo 处于 Frontier 区间;保留 2 与原判断一致。