Summary
One Agent to Guide Them All: Empowering MLLMs for VLN via Explicit World Representation
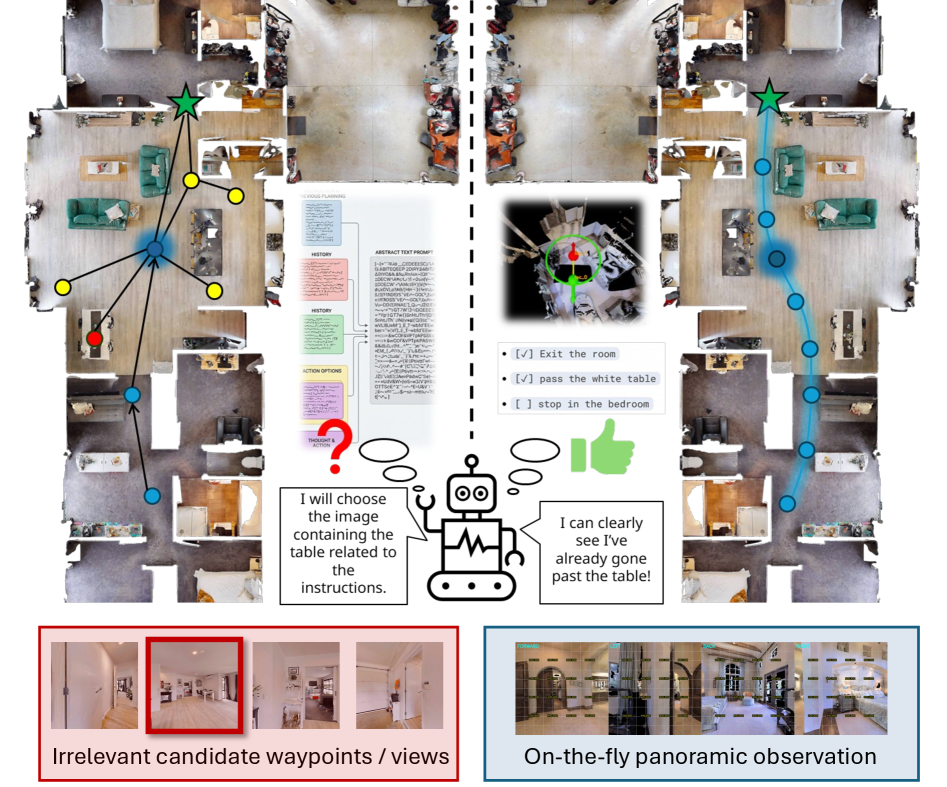
- 核心: 在 zero-shot VLN-CE 中,把 MLLM 的”空间状态估计”和”语义规划”解耦——前者用一张可交互的 metric world map 显式承载,后者让冻结的 MLLM 在地图上做反事实推理选 waypoint。
- 方法: 异步 TSDF 体素地图 + 拓扑图作为 World Representation;BEV + 4 张正交 RGB-D + 归一化坐标网格作为视觉 prompt;用 procedural blueprints(动态 TODO list、loop alert、5-step history)驱动 MLLM 输出 (view_id, u, v) 后由 ray-cast 还原 3D waypoint。
- 结果: R2R-CE val-unseen SR 48.8%、RxR-CE 42.2%(zero-shot SOTA,比前最佳 BZS-VLN 高约 7 个点);TurtleBot 4 真机 SR 40%、自制无人机 42%,远超监督式 VLN-BERT(16%)/RDP(20%)。
- Sources: paper
- Rating: 2 - Frontier(zero-shot VLN-CE SOTA + EWR plug-in 的 framing 有 insight,但无开源、counterfactual 术语名不副实、与监督 SOTA 仍有 15+ 点 gap)
Key Takeaways:
- Decoupling > stronger backbone:把空间状态从 MLLM 的隐式推理里剥出来,比直接用更大的 MLLM 更能涨分。Spatial 推理交给 TSDF 这种确定性管线,MLLM 只负责”在已知地图上选哪走”。
- Explicit metric map 是 sim-to-real 的关键:MLLM 不直接看 raw real-world 像素,而是看渲染好的 BEV + 拓扑图——representation 在 sim 和 real 长得一样,所以 zero-shot 真机迁移没有显著掉点。
- EWR 是 plug-in:把 metric world representation 接到 NavGPT / OpenNav / SmartWay 这些 baseline 上,几乎所有 metric 都涨——说明 explicit spatial substrate 是 zero-shot VLN agent 的通用缺口。
- Backbone 越强越好但天花板未触:Qwen3-VL-235B → Gemini-2.5 Pro → GPT 5.1 单调升 SR (37.2 → 42.3 → 47.2),框架的 reasoning 上限随 MLLM 升级直接受益。
Teaser. GTA 框架的核心对照——左侧是已有 MLLM-based VLN 用线性化文本 memory,右侧是 GTA 用 interactive metric world representation + counterfactual reasoning。
Body
问题与动机
VLN-CE:给一句自然语言指令,让 agent 在 Habitat 这类连续 3D 场景里 follow 指令到达目标。当前两种主流路线:
- Fine-tune MLLM:贵,且会损伤 MLLM 的 generative knowledge
- MLLM-centric zero-shot(NavGPT / OpenNav / SmartWay 等):通常采用 tightly coupled 设计——把 spatial 和 semantic 推理塞在一次 forward 里,让 MLLM 看 egocentric RGB 序列直接出 action
作者诊断 tightly coupled 的两个 failure mode:
- Implicit spatial inference 不可靠:MLLM 从 ego RGB 序列里自己脑补 global layout,经常 hallucinate 不存在的房间连接
- Error propagation:错误的空间认知传到语义层,导致”自信地走错”
Method: GTA 框架
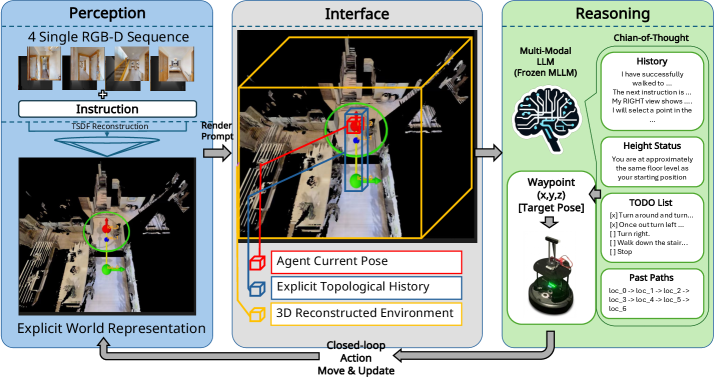
整体由三块组成(Fig. 3):
- Metric Mapping Module(左):异步融合 RGB-D 流,TSDF 重建出一张实时 metric map
- Interactive Reasoning Interface(中):把 metric map + procedural blueprints 渲染成 MLLM 能吃的多模态 prompt
- Counterfactual Reasoning Brain(右):冻结的 MLLM 在 prompt 上推理,输出下一个 waypoint
Figure 3. GTA 框架总览。左:Metric Mapping Module 用 TSDF 融合稀疏 RGB-D 出 metric map;中:把几何重建 + procedural reasoning blueprints(TODO list + 拓扑历史)融成一个 spatial-logic state 渲染成 prompt;右:MLLM 直接输出下一个 metric waypoint (x, y, z)。
Interactive Metric World Representation
世界表示 由两部分组成:
Volumetric mapping ():用 TSDF 维护稠密 3D 几何。每个 RGB-D 观测 经相机内参 和 pose 反投影到世界坐标,TSDF 体素 的 signed distance 用加权平均更新:
Topological graph ():长程记忆。每个 node 存 metric 位置和 visit count。新到的 pose 与最近 node 距离 < 就合并,否则新建。Visit count 超过 就触发 loop alert。
Interactive Reasoning Interface
这是把 转成 MLLM-friendly prompt 的转换层 ,model-agnostic。
- Orthogonal view selection:从异步 RGB-D 流里挑 4 张近似正交(0°/90°/180°/270°)且空间临近当前 pose 的观测
- Visual prompting with coordinate grids:把 TSDF 正交投影成 BEV ,并在 BEV 和 ego view 上叠加归一化坐标网格 。MLLM 不用回归 head 也能输出精确 spatial action——直接输出 grid 上的 (u, v)
❓ Coordinate grid 这种 in-image visual prompting 让 frozen MLLM 输出离散坐标的做法和 SoM (Set-of-Mark) / GPT-4V grounding 一脉相承,但作者没引相关工作。trick 在 GUI agent / spatial QA 都验证过有效,说明 GTA 的成功部分依赖 MLLM 在做 grid-based grounding 时的预训练 prior。
Figure 2. R2R-CE 上一个 episode 的可视化。上行是 metric world representation(top-down 视角),下行是对应步的 ego panorama。黄色是规划轨迹,蓝点是 waypoint,红箭头是当前 pose。

Counterfactual Reasoning Brain
每步给 MLLM 喂的 text prompt:
- Dynamic Task Plan ():把指令分解成动态 checklist(“[x] Navigate to door”、”[ ] Turn left”),MLLM 每步更新
- Topological & Physical State:图上当前位置 + Vertical Awareness( 触发”Upstairs/Downstairs”)+ Safety Alerts(前一动作失败 / loop 检测)
- Execution History:sliding window w=5 的 thoughts/views/actions log
- Global Instruction:原始指令,作为 immutable global ref
MLLM 输出 JSON:reasoning chain + (view_id, u, v)。3D waypoint 通过 ray-cast 在 TSDF mesh 上还原:
确定性低层 planner 接管执行。
❓ 名字叫 “counterfactual reasoning” 但实际只是让 MLLM 在 prompt 里枚举候选 (view, u, v) 然后选一个;并没有显式做”if I take action a, what is the resulting world state”的 rollout。这里的 counterfactual 是修辞性的——并没有看到与传统 model-based planning 的 counterfactual rollout(如 MuZero/Dreamer 类)有任何技术对应。
Experiments
主表 (Table I):R2R-CE val-unseen 全集 1839 episodes、RxR-CE val-unseen 采样 260 episodes。
| Method | R2R-CE SR↑ | R2R-CE SPL↑ | RxR-CE SR↑ | RxR-CE SPL↑ |
|---|---|---|---|---|
| Supervised SOTA Efficient-VLN | 64.2 | 55.9 | 67.0 | 54.3 |
| Supervised NavFoM | 61.7 | 55.3 | 64.4 | 56.2 |
| Supervised ETPNav | 57.0 | 49.0 | 54.8 | 44.9 |
| Zero-shot SmartWay | 29.0 | 22.5 | – | – |
| Zero-shot BZS-VLN(前 SOTA) | 41.0 | 25.4 | 35.7 | 21.7 |
| GTA (Ours) | 48.8 | 41.8 | 42.2 | 39.3 |
GTA 在 zero-shot 上把 SR 从 41.0 → 48.8(+7.8),SPL 从 25.4 → 41.8(+16.4);甚至超过经典监督式 VLN-BERT 之类,逼近近期监督 SOTA Efficient-VLN。SPL 涨幅显著大于 SR——意味着不是”瞎逛凑成功率”而是真在按地图高效推进。
EWR plug-in 实验 (Table II):把 EWR 装到 NavGPT、OpenNav、SmartWay 上,所有方法在 R2R-Sampled / REVERIE-Sampled / 对应 CE 版本上一致提升。在 REVERIE(高层目标如 “find the pillow”)上提升尤其明显——验证 explicit map 让 agent 能做 frontier-based exploration 而不是被指令”牵着走”。
Procedural Blueprints 消融 (Table III) on R2R-CE 180-episode hard subset:
| NE↓ | OSR↑ | SR↑ | SPL↑ | nDTW↑ | |
|---|---|---|---|---|---|
| GTA (w/o PB) | 5.38 | 48.3 | 45.0 | 38.1 | 52.7 |
| GTA (w/ PB) | 5.27 | 56.7 | 47.2 | 39.6 | 55.8 |
OSR 涨 8.4 个点最显著——blueprint 像个”long-horizon compass”,让 agent 在复杂场景里不掉队(OSR 衡量”是否到过目标附近”)。SR / SPL 涨幅相对小(约 1.5–2 点),说明 blueprint 主要解决”找路”,不太解决”知道何时停”。
Backbone scaling (Table IV) on 同一 180-episode subset:
| Backbone | NE↓ | OSR↑ | SR↑ | SPL↑ |
|---|---|---|---|---|
| Qwen3-VL-235B | 5.98 | 46.1 | 37.2 | 29.5 |
| Gemini-2.5 Pro | 5.35 | 48.7 | 42.3 | 34.4 |
| GPT 5.1 | 5.27 | 56.7 | 47.2 | 39.6 |
GPT 5.1 > Gemini-2.5 Pro > Qwen3-VL-235B,单调相关于 backbone 通用 reasoning 强度。框架是 “future-proof” 的,但同时也意味着 GTA 的核心红利来自最强闭源模型——开源 Qwen3-VL-235B 拿到的 SR 比 GTA(GPT 5.1) 低 10 个点。
Real-World Deployment
50 trials × 2 平台:TurtleBot 4(RealSense D455 + ROS2 Nav2)和自制 quadrotor(RealSense D435 + Betaflight + 外部动捕定位)。MLLM inference 通过 HTTP 跑在远端 server。
Figure 4. Sim-to-Real 跨形态零样本迁移。上:TurtleBot 4 在 unseen 环境里完成 obstacle 避让 + 大物体语义 grounding;下:自制无人机用同一框架定位细粒度目标。

| Method | SR↑ (%) | NE↓ (m) |
|---|---|---|
| Supervised VLN-BERT | 16.0 | 5.36 |
| Supervised RDP | 20.0 | 5.45 |
| Zero-shot SmartWay | 32.0 | 4.85 |
| GTA - TurtleBot 4 | 40.0 | 3.66 |
| GTA - Drone | 42.0 | 3.50 |
监督方法暴跌(VLN-BERT 16%)暴露 sim-to-real visual gap;GTA 几乎没有 gap——因为 MLLM 看的是 BEV + topo graph 这种 domain-invariant representation,不是 raw pixel。这是论文最强的卖点。
❓ 但 50 trials 是个小样本量,且没说 wheeled / drone 各占多少 trials。drone 用外部动捕定位 = 在 controlled 实验室——不是 in-the-wild deployment。这两点弱化了 real-world claim 的强度。
关联工作
基于
- TSDF 体素融合:经典 3D reconstruction 技术(KinectFusion 等),不是新的,只是被作为 mapping module 使用
- Habitat simulator:所有 sim 实验的基础
对比(Zero-shot baseline)
- Open-Nav: 把 EWR 装上后 R2R-CE-Sampled SR 30.6 → 38.3,是 EWR plug-in 的主要消融对象
- SmartWay: zero-shot waypoint predictor + backtracking,是 GTA 直接对比的 MLLM-based zero-shot 系统
- BZS-VLN: 当前 zero-shot SOTA,被 GTA 在两个 benchmark 上超越
- NavGPT: 早期 LLM-based VLN,作为 EWR plug-in 的 discrete 环境对比
- MapGPT: language-descriptive map 思路的代表,是 GTA 反对的 “implicit / linearized memory” 范式
对比(Supervised baseline)
- ETPNav: 监督式 topological planner,作为上界 reference
- NavFoM: 监督 VLN foundation model
- Efficient-VLN: 当前 supervised SOTA
- NaVid: video-based VLM VLN,被引为 task-specific adaptation 的代表
- MapNav: annotated semantic map 作为 memory,被批为 “human-designed prior”
方法相关
- Procedural blueprint / dynamic checklist:与 LLM agent 里的 ReAct / plan-execute 范式一脉相承
- Coordinate grid visual prompting:与 Set-of-Mark / GPT-4V visual grounding 相关(论文未引)
论文点评
Strengths
- Decoupling 的 framing 干净:把”spatial state estimation 是确定性问题,semantic planning 是 LLM 问题”这件事讲清楚,并且 EWR plug-in 实验(Table II)是个很有说服力的消融——不是只能在自己框架里 work。
- Sim-to-real 是真亮点:监督方法 SR 从 sim 60+ 掉到 real 16-20% 的 collapse 与 GTA 维持 40%+ 的对比,证明 representation 选对了 domain shift 就不那么致命。这是作者反复强调的 take-away,且证据是直接的。
- 方法 model-agnostic:换 backbone 直接涨分(Table IV),意味着不绑定特定 MLLM;换 baseline planner 也直接涨分(Table II),意味着 EWR 是个 reusable component。这两个性质让方法的”半衰期”较长。
- Real-time TSDF + ray-cast pipeline 没有偷懒:用了实际的 SLAM-style 工程组件而不是 oracle map,落到真机后立刻可用。
Weaknesses
- “Counterfactual reasoning” 名不副实:实质就是让 MLLM 在 grid 上选 (view, u, v),没有显式 rollout / state imagination。该术语在 model-based planning 里有明确含义,作者借用但没做对应工作,是 framing 上的 inflation。
- SR 仍远低于监督 SOTA:Efficient-VLN 64.2 vs GTA 48.8,gap 15+ 个点。论文论调是”接近监督 SOTA”——更准确说法是”接近第一代监督 baseline”。
- Real-world 实验设计偏弱:50 trials 小样本、wheeled/drone 没拆分、drone 用动捕(in-lab 设定),不能称为”in-the-wild zero-shot deployment”。
- No code, no project page:截至撰写时无开源仓库或项目页,artifact 可获取性几乎为零。复现需要从头实现 TSDF mapping、orthogonal view selection、prompt template、coordinate grid renderer,工作量很大。
- Coordinate grid prompting 没引相关工作:Set-of-Mark / GPT-4V visual grounding 相关 literature 缺失。这部分技术不是新的,作者表述像是自己的发明。
- Top backbone 是 GPT 5.1:47.2 → 37.2(GPT 5.1 → Qwen3-VL-235B)的 10 个点 gap 说明很大一部分性能依赖闭源 frontier MLLM 的 reasoning 能力,开源能复现到的上限被拉低。
可信评估
Artifact 可获取性
- 代码: 未开源(论文未提供 GitHub 链接,Web 搜索也未找到)
- 模型权重: 不适用(zero-shot,frozen MLLM)
- 训练细节: 不适用;推理细节有:、history window 、height threshold 、4 个正交 view、grid
- 数据集: R2R-CE / RxR-CE / REVERIE-CE 都是公开 benchmark;RxR-CE 用了 260 episodes 子集,180-episode 难样本子集是作者 curated 但没说怎么放出
Claim 可验证性
- ✅ Zero-shot SOTA on R2R-CE/RxR-CE:Table I 数字与现有 zero-shot baseline 直接对比,metric 标准(SR/SPL/nDTW)有共识
- ✅ EWR 作为 plug-in 提升 NavGPT/OpenNav/SmartWay:Table II 在多个 baseline 上的一致提升,是较强的因果证据
- ✅ Backbone scaling 单调:Table IV 三档 backbone 单调上升,可重复验证
- ⚠️ “Competitive with supervised experts”:实际 SR 比 Efficient-VLN 低 15 点,仅与早期监督 baseline (CMA/VLN-BERT) 相当;“competitive” 措辞偏 marketing
- ⚠️ Sim-to-real 40-42% SR:50 trials 小样本,drone 是动捕环境,wheeled/drone 拆分未公开;数字方向正确但置信区间宽
- ⚠️ Counterfactual reasoning 是 strategy 而非术语对应:技术上没有 explicit rollout,与 model-based RL 的 counterfactual 不能等同
- ❌ 无明显纯营销话术
Notes
- 该读吗:是 zero-shot VLN-CE 当前 zero-shot SOTA,在我的方向(VLA / spatial intelligence)有 indexed 价值——核心 take-away 是 “explicit metric representation 比 implicit linguistic memory 更适合 MLLM-based embodied agent”,这个 thesis 和 spatial intelligence 的趋势一致。但方法本身不算复杂的 contribution——是工程整合 + 一个清晰的 framing。
- 可借鉴点:
- EWR plug-in 的实验设计(Table II)是个 transferable pattern——证明某个 representation 是 reusable component 时,跨 baseline 的一致提升比”我自己框架最强”有说服力
- Sim-to-real 用 domain-invariant intermediate representation(这里是 BEV + topo graph)来 bypass visual gap 的思路——在 manipulation 里也成立(depth / point cloud / object centric representation)
- 追问:
- 如果换成 raw point cloud 而不是 TSDF + BEV 渲染,性能会更好吗?(绕开 BEV 投影损失的 height 信息)
- PB(procedural blueprint)的 OSR 涨幅显著大于 SR,说明能找到目标但不会停——是否说明 stop policy 才是 bottleneck?
- GPT 5.1 → Qwen3-VL-235B 的 10 点 gap 究竟是 spatial reasoning 弱还是 instruction following 弱?拆开 ablate 会更有意义。
Rating
Metrics (as of 2026-04-24): citation=2, influential=0 (0.0%), velocity=0.91/mo; HF upvotes=N/A; github=N/A (无代码仓库)
分数:2 - Frontier 理由:是 zero-shot VLN-CE 当前 SOTA(Table I:R2R-CE SR 41.0→48.8)且 EWR plug-in 在 NavGPT/OpenNav/SmartWay 上一致涨分(Table II),说明 “explicit metric representation > linearized linguistic memory” 这个 framing 是可迁移的 insight——符合 Frontier 档”方法范式的代表工作、必须比较的 baseline”。但不够 Foundation:与监督 SOTA Efficient-VLN 仍有 15+ 点 gap、无开源代码 / 项目页、“counterfactual reasoning” 术语名不副实、关键性能严重依赖闭源 GPT 5.1(Qwen3-VL-235B 掉 10 点),未成为方向的 de facto 范式。不降 Archived 因为 EWR 的 decoupling insight 与 domain-invariant representation 的 sim-to-real 思路对 VLA/spatial intelligence 方向仍有 indexed 价值。2026-04 复核:发表 2.2 月(<3mo 豁免窗口内)2 citation / 影响力 0 / 无代码仓库,按早期信号口径维持 Frontier;下轮若仍无代码开源或采纳信号则需重新评估。