Summary
AnywhereVLA: Language-Conditioned Exploration and Mobile Manipulation
- 核心: 把经典 SLAM + frontier exploration + 一个 fine-tuned SmolVLA manipulation head 拼成一个模块化 mobile manipulation pipeline,跑在 Jetson Orin NX + Intel NUC 这种 consumer-grade edge hardware 上,单条自然语言指令即可在未知室内场景做 pick-and-place
- 方法: 语言指令 → 任务图 → 三大模块(带 confidence 的 3D 语义建图 + frontier-based active exploration + Approach 规划) + SmolVLA 450M 在自采 50 episode SO-101 数据集上微调
- 结果: 50 个 end-to-end episode 中 46% overall SR;其中 VLA manipulation 80%,SLAM 100%,AEE 75%;5 m 半径平均 < 133 s 完成
- Sources: paper | website | github
- Rating: 1 - Archived(完整 open-source 的 edge mobile manipulation system paper,但发布近 7 个月仅 3 cites / 0 influential / 23⭐,加上方法 novelty 接近零,更适合作为一次性 system reference 而非前沿 baseline)
Key Takeaways:
- Classical stack + small VLA 是 edge 部署的现实路径:作者明确放弃 end-to-end VLA / VLN 路线,把长程导航交给 SLAM + Nav2 + frontier exploration,让 SmolVLA 只负责局部 grasp/place,这样在 Jetson Orin NX + NUC 上保 ≥10 Hz。
- 语言指令的”用法”很轻:prompt 只用来抽取 target object class 来 condition exploration,不做组合性空间约束(“on the table” / “blue box”)——作者也在 limitation 里承认这点。
- Fine-tuning ablation 是最有信息量的数字:用同 SmolVLA 不微调时 overall SR 只有 10%,微调后 46%——也就是说 platform-specific 的 50-episode 数据集是 unlock 这个系统的关键,而不是架构本身。
- HermesBot 是个完整的 hardware artifact:Velodyne VLP-16 + 3 个 D435 + SO-101,三视角相机 + LiDAR densification 的工程细节比方法新颖度更值得参考。
Teaser. AnywhereVLA 的整体形态与 use case:teaser 图 + 5× 加速的 demo 视频。

I. Motivation:为什么不直接 end-to-end?
作者把 prior work 分成三类,并指出各自的”墙”:
- VLA(π0、π0.5、MoManipVLA):instruction grounding 强,但 spatial awareness 局限在 room-scale,无法跨房间探索。
- VLN(BUMBLE):building-wide navigation 可以,但要求已知地图 + pre-provided landmarks,dynamic / unexplored 场景不工作。
- Classical nav stack(Nav2 / FAST-LIVO2):mapping 和 exploration 鲁棒,但不懂语义和指令。
AnywhereVLA 的定位:把 classical stack 的 traversability 和 VLA 的 task generalization 拼起来,在 unseen indoor 场景里只靠一条 language 指令完成 pick-and-place。
❓ 这个 framing 比较 conservative——它本质是工程拼装,不是新范式。论文的卖点应该是”在 edge hardware 上 end-to-end 跑通”,而不是方法 novelty。
II. 系统架构
Figure 2. AnywhereVLA 的模块化架构:3D Semantic Mapping (SM) + Active Environment Exploration (AEE) + Approach + VLA Manipulation 四个模块。

工作流:
- 语言 prompt 解析出 target object class
- SM 模块用 LiDAR-Inertial-Visual SLAM + YOLO v12m detection 构建带 confidence 的 3D 语义点云图
- AEE 模块以 target class 为条件做 frontier-based exploration,直到检测到目标
- Approach 模块根据 2D occupancy grid 规划”可见 + 可达”的预抓取 base pose
- SmolVLA 输出末端动作完成 pick-and-place
II.A 3D Semantic Mapping with Confidence
把 RGB image、undistorted LiDAR cloud 和 2D detection box 同步起来,把 LiDAR 点投到相机帧、与检测框关联,再反投到 3D。两个工程要点:
LiDAR densification:Velodyne VLP-16 16 线 spinning LiDAR 在 2D box 内常常没有有效 return,作者在每个 azimuth bin 内对相邻 ring 做线性插值:
符号说明:、 是同一 azimuth bin 内相邻 ring 的两个有效采样点; 是插值数量。
Figure 3 / 4. 稀疏 vs 密化后的 LiDAR 点云对比。


II.B Object Aggregation 和 Confidence
按 class 累积点 → DBSCAN 聚类 → 鲁棒外点滤除 → 每个 cluster 用质心和协方差表征。Confidence 是一个 logistic 融合:
符号说明: point density、 multi-view 角度覆盖率、 inlier 数、 detector 平均得分; 和 是手调参数。
❓ 五个权重 + bias 都是 hand-tuned,在不同环境怎么 transfer 没说。这种打分基本是工程经验。
II.C Active Environment Exploration
以 SLAM 后端的 occupancy grid 为输入,frontier 用 8-connected 形态学膨胀提取,clustering 后给每个 cluster 算 centroid + 优化 yaw 提升 FoV。后续用 Nav2(Macenski et al.)验证可行性。一系列经验阈值:
- cluster filtering px
- chunking px
- NMS m
- exploration radius
- FoV yaw 优化 , m
- 保守 frontier filter kernel + gain threshold = 50
- planner 每 s 重新评估
II.D Approach Module
从 labeled object pose 出发,隔离支持面(如桌面)、提边界、用 PCA 估表面法线,然后在用户给定的 offset 处放置 base,使 base 朝向垂直于支持面。Nav2 验证可达性,不可达就在边缘上迭代候选。
III. VLA Fine-Tuning
- 模型:SmolVLA 450M
- 硬件:单卡 RTX 4090 16 GB
- 数据:自采 50 个 SO-101 pick-and-place episode,by teleoperation with leader manipulator
- 优化:AdamW,lr 1e-4 + cosine decay + 100 steps warmup,batch 16,weight decay 0.01,grad clip 10.0
❓ 50 个 episode 就够 SmolVLA 把 SR 从 10% 拉到 80%——这个数字本身值得记。但只在自家 platform 评估,并没说能否 transfer。
IV. HermesBot 平台
Figure 5. HermesBot:双轮差分驱动 + SO-101 manipulator 的 mobile platform。

- 导航子系统:Velodyne VLP-16 LiDAR + Intel RealSense D435i RGB-D,跑 FAST-LIVO2 做 Visual-LiDAR-Inertial SLAM
- VLA 子系统:3 个 Intel RealSense D435——third-person、wrist-mounted、base-mounted forward 三视角
- 算力:Jetson Orin NX 16 GB(perception + VLA)+ Intel NUC i7 32 GB(SLAM + nav + control)
模块吞吐:
| Module | Computer | Frequency (Hz) ↑ | Process time (ms) ↓ |
|---|---|---|---|
| SLAM | Intel NUC | 10 | 25 |
| Semantic Map | Jetson Orin | 15 | 45 |
| VLA | Jetson Orin | 15 | 20 |
V. 实验结果
50 个 end-to-end episode,目标物体在 exploration radius 内随机放置。统一 prompt 模板:“Pick up the <object> and place it in the <area>. And bring the <object> to <location>.” <location> 全部固定为 HermesBot 上的蓝盒子。
Overall SR = 46%。关键 ablation:fine-tune SmolVLA → 46%;不 fine-tune → 仅 10%。
各模块独立 SR:
| Module | SR (%) ↑ |
|---|---|
| SLAM | 100 |
| Active Environment Exploration | 75 |
| Navigation | 90 |
| Object Detection | 85 |
| VLA Manipulation | 80 |
按链式概率粗算:,与 overall 46% 自洽——意味着模块失败近似独立。AEE 失败 25% 主要因为狭窄走廊里在 半径内找不到目标;VLA 失败主要是瓶子滑出夹爪。
Figure 7. 不同 exploration radius 下的总 episode 完成时间。
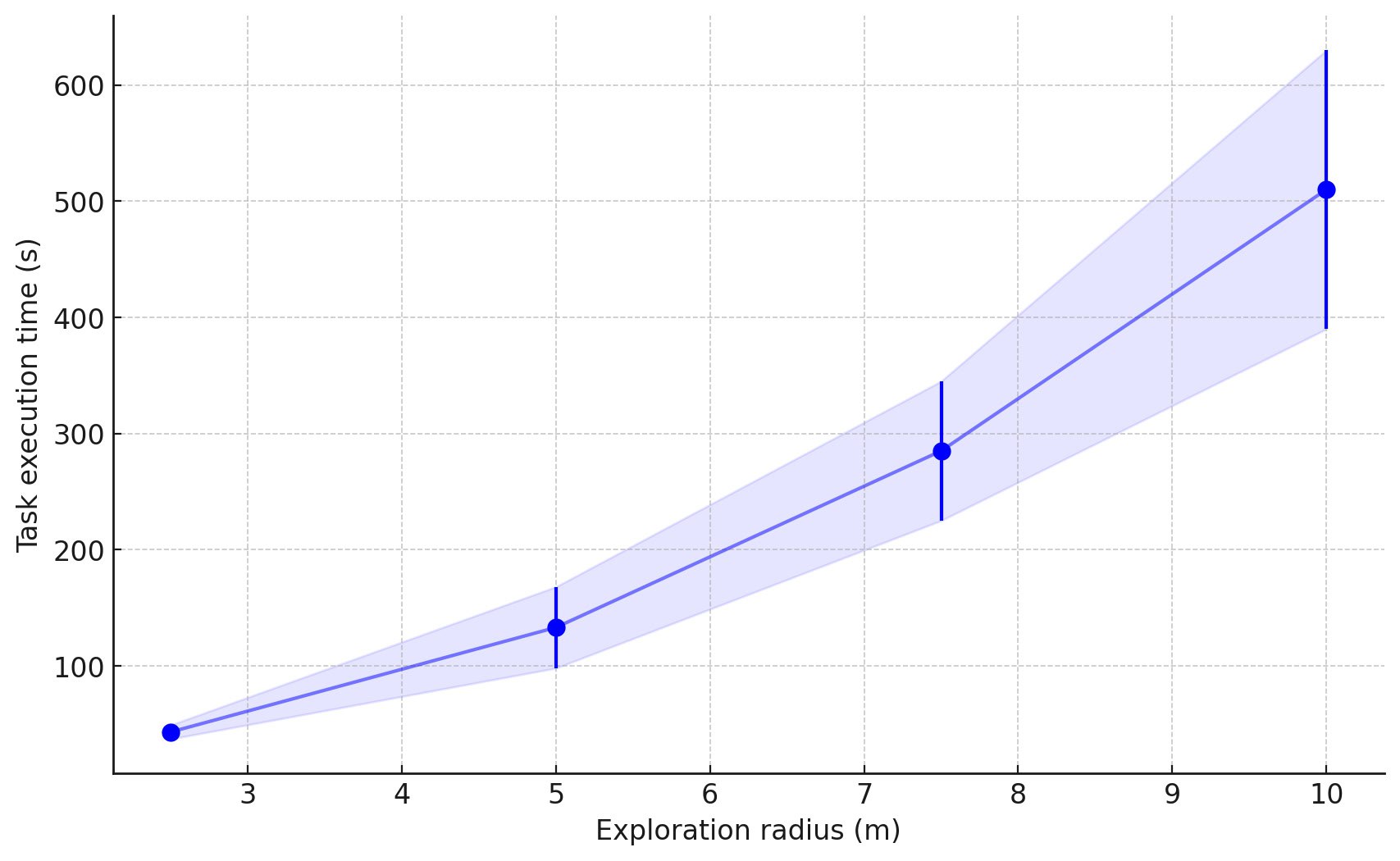
5 m 半径(≈ 普通公寓尺寸)平均 < 133 s;10 m 半径下也能在 10 min 内完成。
VI. Limitations & Future Work(作者自陈)
最关键的 limitation:无法处理 spatial-semantic 复合约束。例:“Pick up the bottle from the table and place it in the blue box.” — pipeline 看到第一个 bottle 就去抓,不管它在不在桌上。本质是因为只用 prompt 抽 object class,没有任何关系推理。
作者提出的方向:(a)动态构建 scene graph + graph-based reward;(b)接一个轻量 VLM 做 zero-shot relational query(如 “is the bottle supported by the table?“)做 pre-success check。
❓ 这两个方向都是 patch 而不是 fix——根因是 instruction parser 把语言压缩成了 class token。要真解决得让 exploration / approach / manipulation 全栈接受 structured task graph,而不是 single class。
关联工作
基于
- SmolVLA:manipulation head 直接 fine-tune 它的 450M checkpoint
- FAST-LIVO2:LiDAR-Inertial-Visual SLAM 直接用
- Nav2 (Macenski et al.):navigation stack 直接用
- YOLO v12m:object detection(per website)
对比
- BUMBLE:building-wide mobile manipulation 但要预先地图 + landmarks
- MoManipVLA:把 VLA 适配到 mobile manipulator,base + arm 联合规划
- π0 / π0.5:generalist VLA,作者主要用来对比 spatial awareness 的局限
- ASC (Yokoyama 2023):apartment-sized mobile manipulation,但完成时间 10–15 min
方法相关
- 轻量 VLA 路线:SmolVLA / EdgeVLA / TinyVLA
- Diffusion policy 路线:RDT-1B / AC-DiT
- Frontier exploration:Yamauchi 1997(这篇 30 年前的 paper 还在被直接引用本身就说明 exploration 这一块没大革新)
论文点评
Strengths
- 完整的 system paper:硬件、SLAM、exploration、manipulation、edge deployment 五件套全做了,并且 open source 代码 + 数据集,做 mobile manipulation 工程的 reference 价值高。
- Edge 部署 latency 数字诚实:明确给出 SLAM 25 ms / SemMap 45 ms / VLA 20 ms 的 process time 和频率,没有用 RTX A6000 的”dev 数字”糊弄。
- Fine-tuning ablation 给出了最有信息量的对照(10% vs 46%),告诉读者真正的 lift 来自 platform-specific 数据,不是新方法。
- 模块 SR 拆分让 system 的瓶颈一目了然(VLA 80% + AEE 75% 是主要 cap),这种工程透明度在 system paper 里少见。
Weaknesses
- 方法 novelty 几乎为零:SLAM、frontier exploration、PCA 表面法线、DBSCAN、Nav2、SmolVLA 全是 off-the-shelf 组件,论文贡献是”组装 + 调参 + 工程化”。
- 语言理解非常浅:把 prompt 压缩成单个 object class,spatial-semantic 复合约束直接放弃,实质上和”YOLO 关键词检测”差别不大。
- 评估场景单一:50 episode 全在同一个 university lab、统一蓝盒子作为目的地、统一 prompt 模板——overall SR 46% 的 generalization 边界不清楚。
- Confidence formula 全是手调权重: 五个 hyperparameter 在不同 LiDAR / 不同环境下怎么 transfer 没说。
- 数据集”50 episode”太薄:目前没法判断这是 SmolVLA 本身样本效率高,还是因为评估里物体类别和数据集严格重叠。
可信评估
Artifact 可获取性
- 代码: inference + training pipeline 都在 GitHub(SelfAI-research/AnywhereVLA),三个子目录 hardware / gpu / cpu 分开
- 模型权重: README 提到 fine-tuned SmolVLA,但没看到明确的 checkpoint 下载链接(只有 “models, datasets are open source” 的笼统声明)
- 训练细节: 关键超参全披露(lr、optimizer、batch、warmup、grad clip);数据规模(50 episode)有;但 prompt template 多样性、object 种类未详
- 数据集: 部分公开——README 里只看到一个 96.2 s 的 ROS2 bag(office corridor,bottles + bananas),并没明确说是否包含完整的 50-episode SO-101 manipulation 数据
Claim 可验证性
- ✅ 46% overall SR:50 episode 实验,模块独立 SR 链式相乘自洽
- ✅ Edge real-time ≥ 10 Hz:表 I 给出每个模块的频率和 process time
- ⚠️ “robust generalization”:claim 在 abstract 和 website 反复出现,但实验只在单一 lab、单一 prompt 模板、单一目的地(蓝盒子)下做,generalization 边界没测
- ⚠️ “unseen environments”:lab 对模型可能 unseen,但 object class 几乎一定在 50-episode fine-tune 集合里——这是 in-distribution object + out-of-distribution layout 的混合,而不是 truly unseen
- ❌ “agility and task generalization of language-conditioned manipulation”:作者自己承认连”on the table”这种简单 spatial 约束都解析不了,这个 claim 是营销性修辞
Notes
- 这篇本质是一篇 system / hardware integration paper,方法层 novelty 接近零,但 edge 部署的 number、模块 SR 拆分、SmolVLA 微调收益的数字是有用的 datapoint。
- 对我自己 mental model 的更新:在 Jetson Orin NX 这类 consumer edge hardware 上跑通 perception + VLA 的吞吐数字(45 ms semantic map + 20 ms VLA @ 15 Hz)值得记下,作为未来评估其他 edge VLA 部署 claim 的 baseline。
- 真正有意思的 open question:“50 episode 让 SmolVLA 从 10% → 80%” 这个数字到底是 SmolVLA 的 sample efficiency 高,还是因为评估 in-distribution?需要看 SmolVLA 原 paper 的样本效率曲线对照。
- 提交到 ICRA 2026——属于 RAS 系 system paper 的典型 fit。
Rating
Metrics (as of 2026-04-24): citation=3, influential=0 (0.0%), velocity=0.43/mo; HF upvotes=0; github 23⭐ / forks=1 / 90d commits=0 / pushed 180d ago
分数:1 - Archived 理由:在 edge mobile manipulation 方向,这是少见的完整 open-source system paper——硬件、SLAM、exploration、VLA 微调、部署 latency 全栈 disclosure(见 Strengths 1–3),fine-tune 10% → 46% 的 ablation 和模块 SR 拆分是后续工作可直接引用的 datapoint。但方法 novelty 接近零(Weaknesses 1)、评估场景单一(Weaknesses 3)、语言理解退化成 class token(Weaknesses 2)。2026-04 复核:发布 6.9 个月仅 3 cites / 0 influential / velocity 0.43/mo / 23⭐ / 0 HF upvotes / 90d commits=0,与 Frontier 档 “有一定使用量 / 必须比较的 baseline” 的定性不符,更符合 Archived 档的 “niche / 为某个具体问题查的一次性参考”,故从 2 - Frontier 下调至 1 - Archived;相对 2,差别在于社区未兑现 adoption,edge mobile manipulation 方向当前更活跃的参考是 SmolVLA 等单点 VLA 路线,本文保留作为 system-integration reference 即可,不再预期主动翻。