Summary
MoManipVLA: Transferring VLA Models for General Mobile Manipulation
- 核心: 把 fixed-base VLA 输出的 end-effector waypoint 当成约束,再用 bi-level 轨迹优化把 base 动起来配合 arm,从而 zero-shot 把 fixed-base VLA 升级成 mobile manipulation policy
- 方法: VLA 预测 EE waypoint → 设计 reachability/smoothness/collision 三项 cost → 上层搜 base pose、下层搜 arm pose 的 bi-level Dual Annealing
- 结果: OVMM benchmark 上 overall SR 比 SOTA 高 4.2pp(15.8% vs. 11.6%);real-world 仅 50 episodes 微调即可,Put-in-Bowl 40% / Stack 30% / Drawer 10%
- Sources: paper | website
- Rating: 2 - Frontier(CVPR 2025,OVMM 上当前 SOTA 且提供了 “VLA + motion planning” 的典型 hybrid 方案,但依赖 GT mask、real-world SR 低、articulation 任务几近失败,作为 frontier baseline 而非 foundation)
Key Takeaways:
- VLA-as-waypoint-generator:把 VLA 当成 zero-shot waypoint predictor 而非端到端 policy,把”动 base”的责任扔给传统 motion planning,这是绕开 mobile manipulation 数据稀缺的实用工程 trick
- Bi-level decomposition:10-DoF 联合搜索 (7 arm + 3 base) → 上层搜 base、下层搜 arm,可降 latency 又比直接 Dual Annealing 略高 SR——但本质是 greedy,论文承认非凸
- Reachability cost 是性能瓶颈:ablation 中去掉 reachability 掉得最多;它直接编码”base 站位决定 arm 能否够到”这一物理直觉
- Real-world 收益主要来自 VLA 的 prior,非新方法:50 episodes LoRA fine-tune OpenVLA-7B 即可上线,但 SR 只有 10–40%,距离实用还很远
Teaser. MoManipVLA 通过将预训练 VLA 模型迁移到 mobile manipulation,可在大空间内完成 picking、delivery、drawer opening 等多样化家庭任务,base 与 arm 的运动在物理可行性约束下联合生成。

背景与动机
Mobile manipulation 要求机器人在大空间内完成复杂操作,需要 base 与 arm 的 whole-body 协同控制。现有方法两类都有硬伤:
- End-to-end 模仿学习(Mobile ALOHA, Skill Transformer 等):直接预测 mobile manipulation 动作,但 demo 收集成本极高,dataset scale 小、generalization 弱
- Modular 方法(HomeRobot, OK-Robot, SPIN):foundation-model planner + RL controller 分模块,长程任务下编译误差累计
与此同时,VLA 模型(OpenVLA、π0、RDT-1B 等)在 fixed-base manipulation 上展现了强 generalization,但它们没有 base action 的训练信号,无法直接生成 base+arm 协同动作。
本文 framing:把 VLA 当 fixed-base policy 用,用 motion planning 桥接 base movement,零额外训练就能把 VLA 升级到 mobile manipulation。
方法
整体框架
Figure 2. MoManipVLA pipeline. 预训练 VLA 模型基于观察预测高泛化的 end-effector waypoints;motion planning 在 reachability、smoothness、collision 三类物理可行性约束下,通过 bi-level 优化联合生成 base 和 arm 的轨迹。
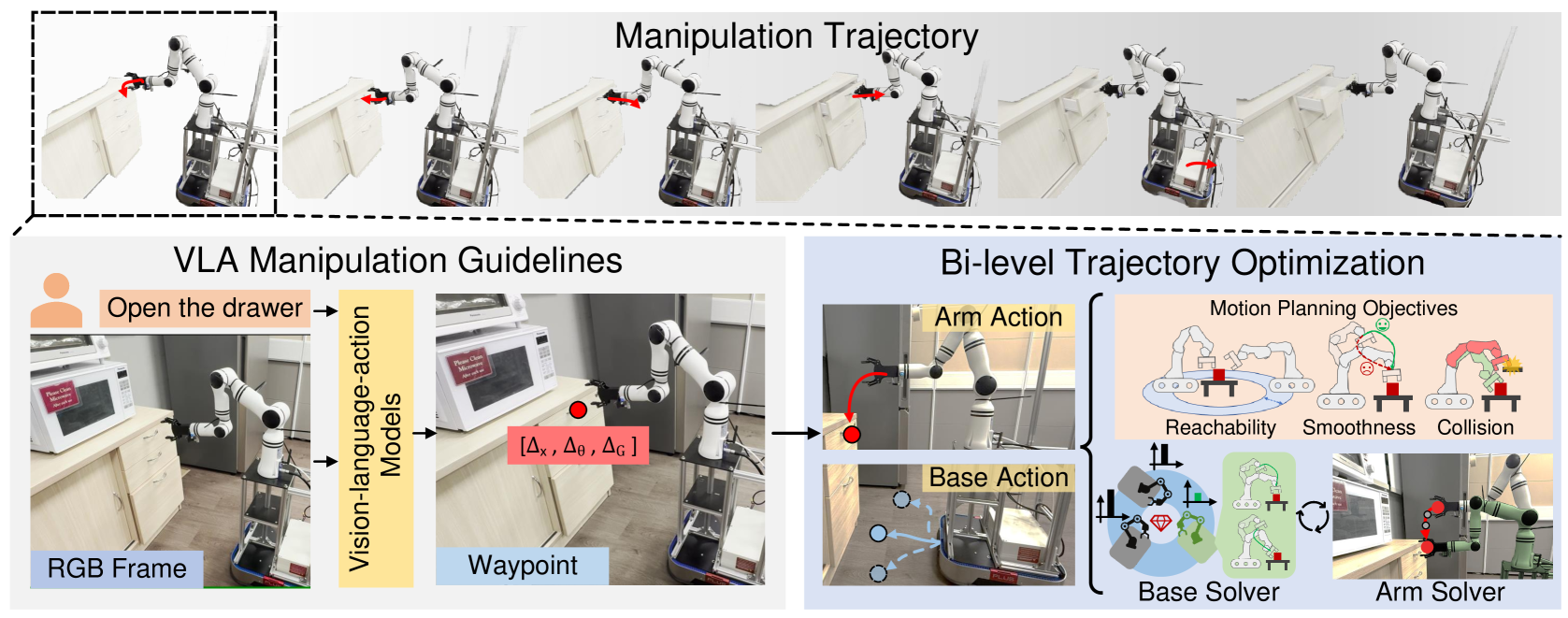
观察 = RGB-D + 相机位姿 + base 位姿/旋转 + EE 位姿/旋转/夹爪状态。VLA 输出第 个 EE waypoint (base frame),通过变换 映射到 world frame:
其中 是 VLA 推理时的 base 位姿。然后在两个连续 waypoint 之间做轨迹优化:
边界约束要求轨迹首尾的 EE pose 与 VLA waypoint 一致。Arm 关节角通过 Pinocchio IK 求解。
Motion Planning 三项 Cost
Reachability cost —— 评估 IK 求解可行性:
IK 收敛慢说明关节接近极限、对噪声敏感;超过预算则视为不可达,赋极大常数。
Smoothness cost —— 关节角与 base 状态的连续性:
❓ 注意 smoothness 用的是 IK 解出的关节角而非 EE proprioception——因为 EE 位姿小变化不能保证关节角小变化(IK 的多解性)。这是个细节但很关键,避免突变损坏电机。
Collision cost —— 用 nvblox 从 RGB-D 构建 ESDF,在机器人表面采 个 query point:
是安全 margin(实验取 0.1),距离大于 margin 则不贡献 cost。总目标:,权重 (10.0, 1.0, 0.6)。
Bi-Level Trajectory Optimization
直接在 10-DoF 空间搜(7 arm + 3 base)非凸且大,易陷局部最优。论文做 greedy 分解:
- Upper-level 只搜 base pose,对每个候选 base pose 采样多组 arm pose,用期望目标 + top-k 目标评估搜索空间质量:
是采样集合, 是 top-k 最优集合。这把 base pose 选择转化为”哪个 base 位置给 arm 留下更大可行空间”的判定。
- Lower-level 在最优 base pose 下搜 arm pose,目标即式 (6)。
求解器:Dual Annealing + SLSQP(梯度局部细化)。
❓ 论文承认 bi-level 是 greedy、不保最优,借类比 humanoid control 的 27+12 DoF 分解为其辩护。但 mobile manipulation 中 base 动得不好直接卡死 arm 可达性——这种 coupling 比 humanoid 上下身更强,greedy 是否合理还需要更多 evidence。
实验
OVMM Benchmark
OVMM = Open Vocabulary Mobile Manipulation,60 个房屋场景 + 18k 物体,任务”把目标物体从容器 A 搬到容器 B”,由 5 个 stage(Nav→Gaze→Pick→Nav→Place)组成。机器人是 Hello Robot Stretch。 他们沿用 OVMM 的 baseline Nav 和 Gaze 模块,只替换 Pick + Place policy,用 OpenVLA-7B + 200 episodes + LoRA 微调(4×3090, 10K epochs)。
Table 1. OVMM benchmark 主结果。 MoManipVLA 在 overall SR 上比此前 SOTA (KUZHUM) 高 4.2pp,partial SR 高 11.2pp,Pick stage 高 12.4pp。
| Method | FindObj | Pick | FindRex | Overall SR | Partial SR | Step |
|---|---|---|---|---|---|---|
| UniTeam | 49.2% | 42.8% | 19.6% | 9.2% | 30.8% | 1006.6 |
| OVMM (RL) | 32.4% | 15.6% | 9.2% | 1.2% | 14.6% | 1132.5 |
| OVMM (Heuristic) | 30.8% | 14.4% | 3.6% | 0.8% | 12.4% | 1009.8 |
| RoboAI | 41.2% | 21.2% | 6.4% | 0.0% | 17.2% | 906.2 |
| KUZHUM | 55.7% | 50.2% | 35.2% | 11.6% | 38.2% | 1153.3 |
| MoManipVLA | 66.1% | 62.6% | 53.1% | 15.8% | 49.4% | 1240.5 |
❓ Step 数(1240)反而高于 KUZHUM (1153)——SR 升但效率降,论文未深入解释。可能是 bi-level 优化引入了更多中间步。
Ablation
Table 2. 消融实验。 三项 cost 全部贡献正向,去掉 reachability 掉最多(overall SR -2.7pp 至 13.1%)。Bi-level vs. 直接 Dual Annealing:SR 略升 (15.8 vs 14.1),latency 显著降 (693 vs 743 ms)。“Base Method w/o GT” 表示用 Detic 生成 mask 而非 GT mask,SR 暴跌至 1.7%——暴露视觉感知是当前方法的脆弱点。
| Method | Search | FindObj | Pick | FindRex | Overall SR | Partial SR | Latency |
|---|---|---|---|---|---|---|---|
| Base | Bi-level | 66.1% | 62.6% | 53.1% | 15.8% | 49.4% | 693.1 |
| Base | Direct | 65.9% | 61.1% | 52.5% | 14.1% | 48.5% | 742.9 |
| Base w/o GT mask | Bi-level | 23.7% | 12.7% | 7.1% | 1.7% | 11.3% | 737.6 |
| w/o Reachability | Bi-level | 65.8% | 61.3% | 52.6% | 13.1% | 48.2% | 682.7 |
| w/o Smoothness | Bi-level | 66.1% | 61.7% | 53.1% | 13.8% | 48.7% | 688.2 |
| w/o Collision | Bi-level | 66.3% | 61.4% | 52.7% | 15.3% | 48.9% | 692.1 |
Table 3. Failure case 分布。 “Orient_to_place”(导航策略未对齐目标)占 72%——印证 base waypoint 的重要性。
| Find_recep | Nav_to_place | Orient_to_place | Other |
|---|---|---|---|
| 14.62% | 0.33% | 72.09% | 12.96% |
真实世界
平台:hexman echo plus base + RM65 arm,Realsense T265 跟踪相机 + ORB-SLAM 估计位姿,Grounded SAM 取 mask,nvblox 重建 ESDF。仅 50 expert episodes fine-tune VLA 即可部署。
Figure 3. 真实世界 Pick-and-Place 序列。 当目标 block 进入 arm 原生 workspace 时直接执行;当需要把红色盒放到工作空间外时,用 heuristic 初始化 base,然后 bi-level 优化精化 base waypoint 让红盒重新进入 workspace。

Table 4. Real-world 任务 SR(每任务 10 次)。
| Task | SR | Step | Latency (ms) |
|---|---|---|---|
| Stack Block | 30.0% | 67.0 | 580.0 |
| Open Drawer | 10.0% | 89.0 | 592.0 |
| Put in Bowl | 40.0% | 102.0 | 585.0 |
❓ Drawer Opening 仅 10% 反映该方法对带 articulation/物理约束的任务能力很弱——hinge object 的运动需要力闭合反馈,单纯 motion planning + ESDF 难以建模。
项目主页 demo 视频
Video 1. Real-world demo 1.
Video 2. Real-world demo 2.
关联工作
基于
- OpenVLA:本文的 VLA backbone,提供 7-DoF EE action 预测
- ReKep:motion planning 用 foundation model 建模 spatial constraint 的灵感来源
- nvblox:用于实时 ESDF 重建的 GPU 加速库
- Pinocchio:IK solver
对比
- HomeRobot / OVMM baselines (UniTeam, KUZHUM, RoboAI, OVMM-RL, OVMM-Heuristic):sim 环境下的 modular 与 RL 方法
- HomeRobot / OK-Robot:modular mobile manipulation 框架,本文 motivation 中作为对比
- Mobile ALOHA / Skill Transformer:end-to-end 模仿学习方法,本文 motivation 中作为对比
- M2Diffuser, Harmonic Mobile Manipulation:未在 table 中对比但属同期工作
方法相关
- VoxPoser:foundation model 推断 scene affordance / constraint 的代表
- π0 / RDT-1B / TinyVLA / ManipLLM:related work 中提到的 VLA 家族
- Diffusion Policy:related work 中作为 imitation learning baseline
- Dual Annealing / SLSQP:本文的优化求解器组合
论文点评
Strengths
- Framing 清晰且实用:把 VLA 当 zero-shot waypoint generator,避开了 mobile manipulation 数据稀缺,是工程上立竿见影的解法
- 三项 cost 设计有物理直觉:reachability/smoothness/collision 各自对应明确失败模式,ablation 也验证了它们的必要性
- Bi-level 分解显著降 latency:693 ms vs. 直接搜 743 ms,且 SR 反而略升,分解策略 work
- Real-world 验证完整:T265 + nvblox + Grounded SAM + ORB-SLAM 的完整 pipeline,50 episodes 起步成本低
Weaknesses
- 本质是把 mobile manipulation 重新降回 modular pipeline,与论文 motivation 中批判的 “modular 方法编译误差累计” 自相矛盾——他们用 OVMM 的 Nav + Gaze baseline,自己只解决了”已经导航到附近后”的局部 motion planning 问题
- Bi-level greedy 的合理性证据不足:base 与 arm 的 coupling 远强于 humanoid 上下身,类比缺乏定量分析;该不该上更紧的联合优化值得验证
- 强依赖 ESDF 与 GT mask:去掉 GT mask 后 SR 从 15.8% 暴跌至 1.7%,real-world 用 Grounded SAM 但论文未给对应数字,可疑
- Real-world SR 较低:Drawer 10%、Stack 30%、Put-in-Bowl 40%,且 articulation 任务(drawer)几乎不 work
- Generalization claim 未充分验证:方法依赖 OpenVLA 的泛化,但实验全在 OVMM + 自建 real-world,未跨 embodiment / 跨任务集 ablation;“4.2% 高 SR” 中有多少来自 VLA prior、多少来自 motion planning,没有清晰拆分
- Website 与 paper 数据不一致:website 写 “50% training cost”,paper 写 “50 expert episodes”——后者更具体,前者像 marketing 简化
- Latency 仍 ~600–700 ms/step:不算实时,对动态环境受限
- 未与最近的 mobile manipulation VLA 对比:例如 Mobile ALOHA、Harmonic Mobile Manipulation、M2Diffuser 都未在表中
可信评估
Artifact 可获取性
- 代码: 未开源(项目主页标 “Code Coming Soon”)
- 模型权重: 未发布
- 训练细节: 部分披露(VLA backbone OpenVLA-7B;200 episodes;10K epochs LoRA on 4×3090;cost 权重 (10, 1, 0.6);safety margin 0.1;step size 0.05;但 LoRA rank、学习率、Dual Annealing 超参未说明)
- 数据集: OVMM benchmark 公开;real-world demo 数据私有
Claim 可验证性
- ✅ OVMM 上 4.2pp Overall SR 提升:Table 1 给了对比方法明细,但需要原作者代码才能完全复现
- ✅ Bi-level 比直接搜更快更高 SR:Table 2 ablation 直接对比
- ⚠️ “50 episodes 即可 real-world 部署”:episodes 数量明确,但未告知 episodes 时长 / 任务复杂度,10–40% SR 不算”成功部署”
- ⚠️ “高 generalization across tasks and environments”:实验只测了 OVMM 内的 60 场景 + 自建 3 任务,未做严格 OOD 评估
- ⚠️ Real-world Drawer 10%:样本仅 10 次,统计意义弱
- ❌ Website 的 “50% training cost”:与 paper 的 “50 episodes” 是不同 claim,更像营销简化,建议以 paper 为准
Notes
- 这篇是典型的 “用 motion planning 桥接 VLA 的 capability gap” 的工作。Insight 不在 VLA 本身,而在认清”mobile manipulation 数据贵 & VLA 已经够泛化”这一前提下,把问题降维到一个传统机器人问题
- 与 π0 / RDT-1B 这类直接训练 mobile / bimanual VLA 的路线形成对比:那条路线 scale data;这条路线 reuse 已有 prior。两者都合理,trade-off 在数据成本 vs. 系统复杂度
- ❓ 一个开放问题:随着 VLA 直接覆盖 mobile manipulation(如 Mobile ALOHA 风格的 demo + π0 的 fine-tune),这种 motion planning hybrid 路线的窗口还能开多久?我倾向认为短期(1–2 年)有用,中期会被纯端到端取代——除非端到端在 safety / explainability 上始终输给显式约束
- 真正能 generalize 的 cost function 设计可能是这条路线的长期价值所在(cf. ReKep 思路)
- 项目主页的 “Last update: June 17, 2024” 比 paper 的 2025-03 提交还早,疑似主页早于论文发布——也可能是页面模板未更新
Rating
Metrics (as of 2026-04-24): citation=32, influential=3 (9.4%), velocity=2.42/mo; HF upvotes=N/A; github=N/A (无代码仓库)
分数:2 - Frontier 理由:CVPR 2025 中选、OVMM 上 overall SR 超 KUZHUM 4.2pp 属当前 sim benchmark SOTA,且提供了 “fixed-base VLA + bi-level motion planning” 的代表性 hybrid 范式,符合 Frontier 的 “当前 SOTA / 必比 baseline / 方法范式代表” 语义。未达 Foundation:代码未开源、real-world SR 仅 10–40%、articulation 任务基本失败、且正如 Notes 所言该 hybrid 路线的窗口可能随 mobile VLA 数据规模化而关闭,缺乏 ImageNet/DROID 级的方向奠基性。高于 Archived:它仍是 OpenVLA 生态下把 VLA 迁入 mobile manipulation 的代表尝试,被同方向工作作为 baseline 引用的概率不低。2026-04 复核:citation=32 / velocity=2.42/mo、influential 比例 9.4%(接近典型 10%)属 CVPR paper 中等水位,无 github 加速了 adoption 迟缓,若 6 个月后 velocity 继续低迷 + 代码仍不 release 应考虑降 1,当前暂维持 Frontier。