Summary
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
- 核心: 把 diffusion 动作去噪嵌入到 LLM 的 next-token prediction 过程里, 让同一个 LLM backbone 同时输出 diffusion-based 连续动作 和 autoregressive 离散动作 token, 两者互相强化。
- 方法: 设计 token 序列
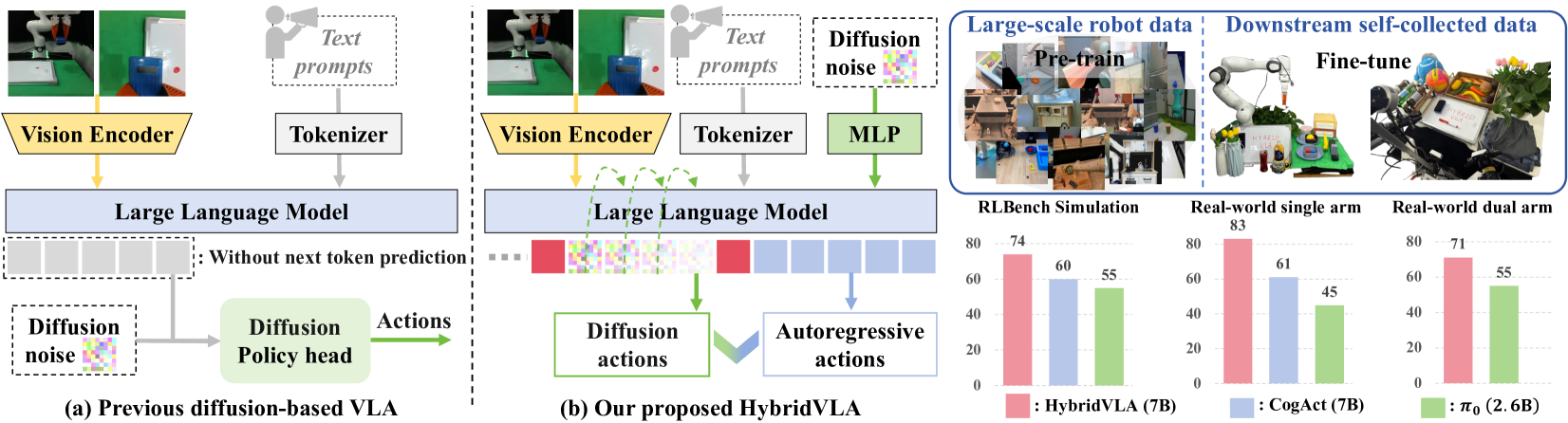
[多模态条件 | <BOD> diffusion tokens <EOD> | AR action tokens], 用L_hybrid = L_dif + L_ce联合训练; 推理时 DDIM 4 步出 diffusion action, 随后 AR 出离散 action, 用 AR token confidence (阈值 0.96) 做 adaptive ensemble。- 结果: RLBench 10 任务 74% 成功率, 超 OpenVLA 33%、CogACT 14%; 真实单臂 / 双臂任务超 π0 / CogACT 19%; 纯 diffusion 推理变体 HybridVLA-dif 达 9.4 Hz。
- Sources: paper | website | github
- Rating: 2 - Frontier. Hybrid AR+Diffusion 在单 LLM 内部耦合是 VLA 设计空间的有代表性的点, 但方法细节偏 engineering, influential citation 低、repo 已 stale。
Key Takeaways:
- 真正”单 LLM 内融合”, 不是 head 拼接: 和 / CogACT / DiVLA 的 “VLM + 独立 diffusion head” 范式不同, HybridVLA 把 diffusion noise 和 denoising timestep 直接投影成 LLM embedding, 让 LLM backbone 同时承载两种生成, 两个 loss 对同一套 LLM 参数回传梯度。
- Token 顺序有 inductive bias: Diffusion tokens 必须放在 AR tokens 之前 —— AR 训练时 label 会泄漏到 context, 若 AR 在前会让 diffusion 在 context 里看到 GT (Type 4 失败模式); 同时用
<BOD>/<EOD>隔离, 避免 diffusion token 直接预测下一个离散 action token (Type 2 失败模式)。 - AR confidence 作为 ensemble gating: AR 和 diffusion 在不同任务上各有所长 (diffusion 擅长精细运动如 Phone-on-base, AR 擅长语义任务如 Water plants), 用 AR mean token confidence > 0.96 作 gate, 超过则两种动作平均, 否则只用 diffusion。
- HybridVLA-dif 证明互相强化: 训练时两种 loss 联合, 但推理只跑 diffusion 分支, 也能比 CogACT 高 6%、比 高 11% —— 说明 AR loss 对 LLM backbone 的正则作用被 diffusion 分支吸收了, 这是本文最有价值的 claim。
Teaser. HybridVLA vs 传统 diffusion-head VLA 的架构对比。
Method
架构总览
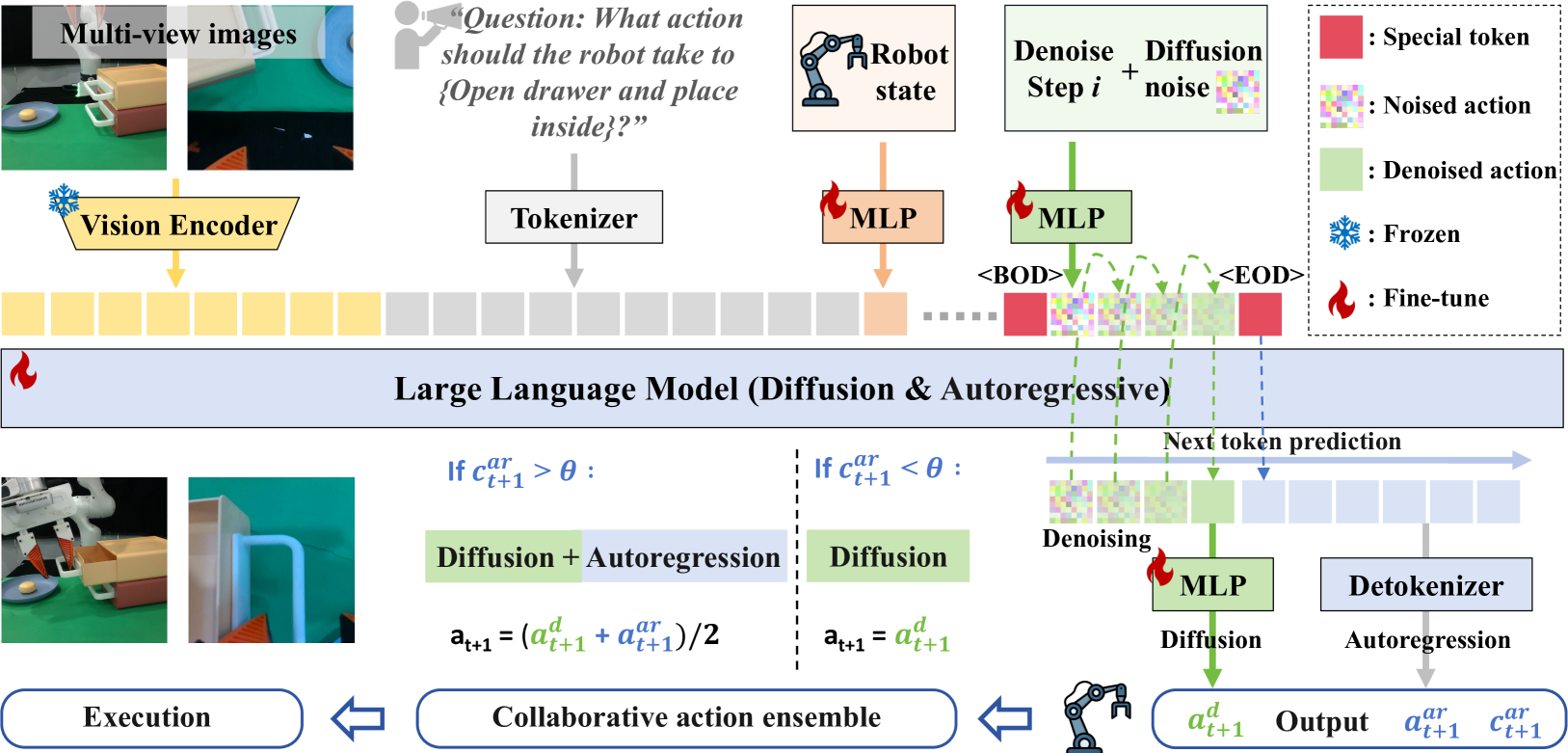
Figure 2. HybridVLA Framework: 多模态输入 (vision、language、robot state) 经编码后按固定 token 序列组织进 LLM embedding; diffusion 分支把 noise + denoising timestep 映射为连续 token 喂入 LLM, LLM 通过 DDIM 迭代 4 步得到 diffusion action; 紧接着 LLM 继续 next-token predict 出离散 AR action tokens; 最后根据 AR confidence 做 ensemble。
Backbone:
- HybridVLA (7B): DINOv2 + SigLIP 双 vision encoder → concat 为 , LLM 用 LLaMA-2 7B, 初始化自 Prismatic VLM
- HybridVLA (2.7B): CLIP + Phi-2 2.7B
- Action: 7-DOF end-effector pose (Δx, Δy, Δz, roll, pitch, yaw, gripper), 双臂 14-DOF
Token Sequence Formulation — 核心设计
序列结构(作者探索了 4 种 Type, 下表中 Type 1 为最优):
[visual tokens | language tokens | robot state | <BOD> diffusion tokens <EOD> | AR action tokens]
关键设计决定:
| 决定 | 动机 |
|---|---|
| Robot state 用可学 MLP 投成连续向量 (), 不离散化 | 避免离散 state 干扰下游 diffusion 对连续 action 的预测 |
<BOD> / <EOD> 包围 diffusion tokens | 防止 diffusion token 直接接替预测离散 action token (Type 2 错误) |
| Diffusion 在前、AR 在后 | 若 AR 在前, 训练时 AR 的 GT 会出现在 context, 被 diffusion 当 condition → 信息泄漏 (Type 4 错误); 反之 diffusion 本身基于 noise, 不会泄漏 |
❓ 这个顺序约束让 AR 分支实际上条件于 “带噪的 diffusion latent”, 而不是干净的 diffusion 结果 —— 论文说这能让 AR 条件于”连续潜在表征”, 我觉得更准确的解释是 AR 被迫学会从 noisy continuous context 中恢复语义, 这种训练压力反过来规整了 LLM 的 representation。
Hybrid Objective
Equation 1. 联合损失
符号说明: 为 GT noise, 为第 步加噪 action, 为条件 (所有 preceding tokens); 是对 AR 离散 token 的 cross-entropy。 含义: 两个 loss 共享同一套 LLM 参数, 梯度联合回传 —— 这是”mutual reinforcement”的机械来源。未用 classifier-free guidance (稳定性考虑, follow RDT-1B)。
训练与推理
训练 (两阶段):
- Pretrain: 5 epoch, 35 个机器人数据集 (Open X-Embodiment + DROID + RoboMind), 共 760K trajectories / 33M frames, 10K+ A800 GPU hours
- Finetune: 自采仿真 / 真实数据, 8× A800, 300 epoch, AdamW lr=2e-5
推理:
- DDIM 4 步 (实验证明不掉点)
- KV cache: 只有首 DDIM 步完整 forward, 后续只更新 noise 和 timestep token, 复用前缀 KV
- Ensemble: AR mean confidence > 0.96 → 两种 action 平均; 否则只用 diffusion
Collaborative Action Ensemble
经验观察:
- Diffusion 擅长: Phone-on-base、Close-laptop 等精度任务
- AR 擅长: Water-plants、Frame-off-hanger 等语义推理任务
- 成功样本中, 80%+ 的 AR token 平均 confidence 超过 0.96 → 作 gating 合理
Experiments
仿真: RLBench 10 任务 (multi-task)
Table 2. RLBench 成功率 (20 rollouts × 3 seed, 每任务 100 条训练轨迹)
| Method | Mean S.R. | Infer Hz |
|---|---|---|
| ManipLLM (7B) | 0.38 | 2.2 |
| OpenVLA (7B) | 0.41 | 6.3 |
| π0 (2.6B) | 0.55 | 13.8 |
| CogACT (7B) | 0.60 | 9.8 |
| HybridVLA-dif (7B) | 0.66 | 9.4 |
| HybridVLA (2.7B) | 0.58 | 12.3 |
| HybridVLA (7B) | 0.74 | 6.1 |
- 对 OpenVLA +33%、对 CogACT +14%
- HybridVLA-dif (只用 diffusion 推理) 对 CogACT +6%、对 π0 +11% → 说明联合训练让 diffusion 分支本身变强
Ablation (Table 3, RLBench)
- CTR (Collaborative Training Recipe): Ex1 vs Ex2 (只 diffusion), Ex3 vs Ex4 (只 AR), 两对比都显示联合训练提升单分支性能 → 验证 mutual reinforcement
- LSP (Large-Scale Pretraining): 去掉机器人数据集 pretrain → 大幅掉点, 说明 VLM pretrain 不能替代机器人数据 pretrain
- RSE (Robot State Embedding): 注入 robot state 提升时间一致性
- CAE (Collaborative Action Ensemble): 证明 ensemble 比任一单分支好
真实世界
- 单臂 (Franka Research 3): 5 任务, Pick-and-place 90%, Unplug-charger 95%, Pour-water 对 SOTA +35%
- 双臂 (AgileX): 5 任务, 均超 π0 (CogACT 不支持多视角, 未比)
- Mean 对 SOTA +19%
泛化 (四维)
Unseen objects / background / spatial height / lighting 上, HybridVLA 降幅最小, 尤其在 object 泛化上 —— 作者归因于 AR 分支保留了 VLM 的 object-level semantic reasoning。
关联工作
基于
- OpenVLA: 离散化 7-DoF pose 为 vocab token, HybridVLA 直接继承这一 AR 路径; backbone (Prismatic VLM, DINOv2+SigLIP) 也来自 OpenVLA 的脉络
- Prismatic VLM (Karamcheti et al. 2024): 视觉编码器 + LLM 的基座
- Diffusion Policy (Chi et al. 2023): diffusion loss formulation 的来源
- DDIM (Song et al. 2020): 推理加速采样
对比 (必较 baseline)
- π0: diffusion expert + flow matching 的代表; HybridVLA 论点是 π0 把 diffusion head 独立出 LLM, 没充分用 LLM 的 reasoning
- CogACT: DiT-base action head + VLM, 同样是 head 拼接范式
- DiVLA (Wen et al. 2024): 也叫 “Diffusion-VLA”, 题目上最像 HybridVLA, 但 DiVLA 仍是 decouple reasoning 和 action 的两模块设计
- RT-2 / ManipLLM: 纯 AR 路径对照组
方法相关
- Transfusion / MonoFormer / Show-o: 通用视觉生成里把 diffusion 融入 AR transformer 的尝试; HybridVLA 是这类思想在 robotics 的移植, 但做了 robot-specific 的 token 序列设计
- GR00T N1: 也是 VLM + diffusion head, 双系统设计, 仍属 HybridVLA 反对的”拼接”范式
- Octo / RDT-1B: 纯 diffusion transformer 动作模型, 无 LLM-AR 分支
论文点评
Strengths
- 问题定位清晰: AR 和 diffusion 在 VLA 里各自的短板 (AR 的离散化 vs diffusion head 的 VLM-underutilize) 被点破, “为什么不融合在单 LLM 里”是个自然而没被做透的问题。
- Token 序列设计有工程洞察: Diffusion-before-AR 的信息泄漏分析 (Type 4) 和
<BOD>/<EOD>的隔离都是做过才能发现的坑, 表格 3.2 的 4 种 Type 对比是 paper 最扎实的贡献之一。 - HybridVLA-dif 的存在是最强论据: 如果只报 ensemble 结果, 会怀疑 gain 来自 test-time 两个分支平均; 但只用 diffusion 推理也超 CogACT 6% 证明了训练阶段的 mutual reinforcement 是真实的。
- Pretrain 规模到位: 760K trajectories / 10K+ A800 hours, 和同期 foundation VLA (π0、OpenVLA) 量级相当, 对比实验有可比性。
Weaknesses
- “mutual reinforcement” 的 mechanism 解释偏口号: 论文反复说两个分支”互相强化”, 但除了共享 backbone + gradient 联合回传, 没给出 representation-level 的分析 (如 attention pattern、token embedding 结构是否真不同于 pure-AR 或 pure-diffusion)。这是可以做 probing 的, 作者没做。
- Inference Hz 实际劣势: HybridVLA (7B) 6.1 Hz, 比 π0 (13.8 Hz) 慢一倍多; 必须退化到 HybridVLA-dif 才追平 CogACT, 但那就放弃了 AR ensemble —— 合起来的”完整版”在部署里不划算。
- 动作表示保守: 单步 7-DOF absolute pose, 没有 action chunking (π0、OpenVLA-OFT 都用), 长时程任务可能受限。
- Confidence 阈值 0.96 的鲁棒性未充分验证: Ensemble 依赖这个硬阈值; 跨任务、跨 embodiment 是否一致没 ablation。
- Benchmark 选择偏窄: 只用 RLBench 10 task (multi-task) + 自采真实, 没上 LIBERO / SimplerEnv / CALVIN 等社区 benchmark, 和 π0、CogACT 的横向可比性打折。
- Repo 已 stale: 最新 push 距今 201 天, 90 天 0 commits, 后续工程维护看起来停滞。
可信评估
Artifact 可获取性
- 代码: inference + training (GitHub 有 training script 和 RLBench env)
- 模型权重: 发布了 pretrain checkpoint (见 README)
- 训练细节: 仅高层描述 + 超参 (lr=2e-5, 300 epoch, 8× A800, AdamW), 数据配比细节在附录
- 数据集: Pretrain 用公开数据 (Open X-Embodiment + DROID + RoboMind); 真实自采数据未开源
Claim 可验证性
- ✅ RLBench 74% 成功率: 有代码 + 公开 benchmark, 可复现
- ✅ HybridVLA-dif 也超 baseline: 最硬的 claim, ablation 直接支持
- ⚠️ “Mutual reinforcement” 的机制解释: 现象 (单分支 gain) 可验证, 但因果归因到”两种 representation 融合”更像叙事而非证据
- ⚠️ 真实世界 +19%: 自采数据, 20 rollouts, 样本量偏小; 且只对比 π0 / CogACT, 没覆盖更多 diffusion-VLA 变体
- ⚠️ 泛化实验: 四个维度各只报 1 任务 (单臂 Pick-place / 双臂 Lift-ball), 难说是 generalization 还是 task-specific
Notes
- 和 π0 的根本分歧: π0 选 flow matching + independent expert, HybridVLA 选 diffusion + share backbone。两条路哪个更 scale, 要看后续 ablation 能不能在 10x 数据规模下维持 gap。
- Token-sequence 设计 (diffusion-before-AR + BOD/EOD) 这一套在 general multimodal generation (Transfusion / Show-o) 里其实已有类似思想, HybridVLA 的增量是把它移到 robot action 并发现了具体的失败模式。
- HybridVLA-dif 作为”只保留 diffusion 推理分支”的设计, 其实是把 AR loss 当成训练时的 auxiliary signal —— 这和用 language modeling loss 做 VLA 辅助训练的若干工作 (如 ECoT) 思路相通。
Rating
Metrics (as of 2026-04-22): citation=142, influential=5 (3.5%), velocity=10.9/mo; HF upvotes=0; github 346⭐ / forks=13 / 90d commits=0 / pushed 201d ago · stale
分数: 2 - Frontier 理由: Citation velocity 10.9/mo 不低, 说明 AR+Diffusion hybrid 这条路确实被社区关注; 但 influential/total 只有 3.5% (远低于 π0 的 19%), 加上 repo stale、HF 0 upvotes, 说明被当作一个”值得引用的设计点”但没有被大量后续工作实质继承。方法本身有巧思但不算范式重塑 —— Foundation (3) 留给真正定义方向的 π0 / OpenVLA 级工作; 而 HybridVLA 在 VLA 方法论地图里是一个明确的、必须知道的 hybrid 节点, 不至于降到 Archived (1)。