Summary
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
- 核心: 把 Qwen2-VL-2B 改造成端到端的 GUI VLA:用 UI-Graph 在 RGB 空间挑出冗余 patch 跳过 self-attn,加上 interleaved vision-language-action streaming 统一 grounding 与 navigation,用 256K 精挑数据训出 75.1% 的 zero-shot ScreenSpot grounding。
- 方法: (1) UI-Guided Visual Token Selection——用 Union-Find 在 patch RGB 图上找连通分量,在 self-attn 内随机跳过同分量内冗余 token;(2) interleaved VLA streaming——action JSON 化、用 README 系统提示描述 action space,分 action-visual 和 action-query 两种流支持 navigation 与 grounding;(3) 数据分析驱动的 256K instruction-tuning corpus + 平衡采样。
- 结果: 2B 模型,零样本 ScreenSpot 75.1% avg;UI-Graph 减 33% 视觉 token + 1.4× 训练加速;Mind2Web/AITW/MiniWob 微调后超过 Qwen2-VL-2B baseline。
- Sources: paper | github
- Rating: 2 - Frontier(2B+256K 击败 7B-18B baseline 的 GUI grounder 代表工作,CVPR 2025,已是 GUI agent 方向的 de facto baseline 和 checkpoint 来源)
Key Takeaways:
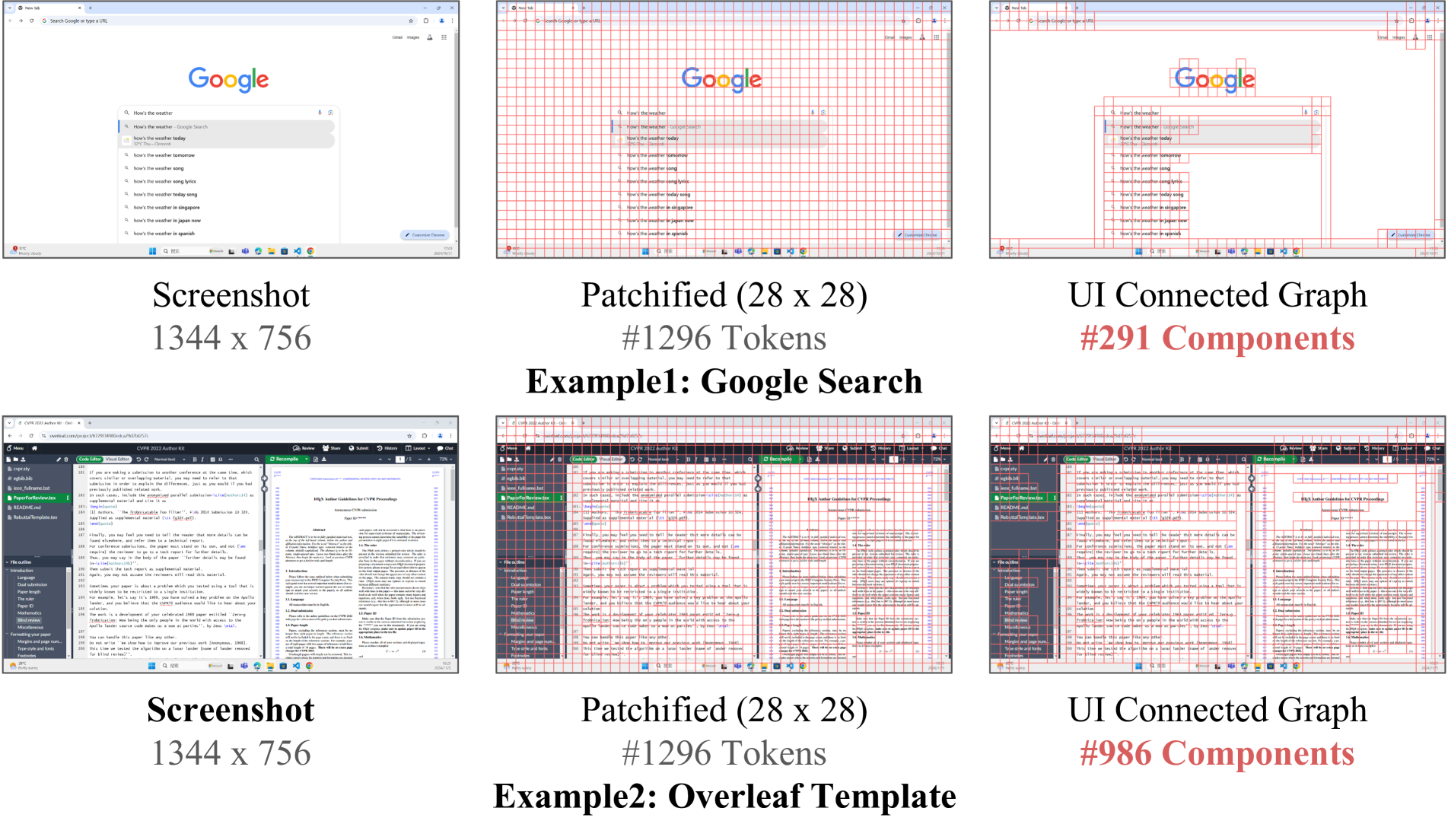
- UI 截图的视觉冗余可以用极简的 RGB Union-Find 量化:作者把 patch 当节点、邻居 RGB 差小于阈值就连边,得到的连通分量数随页面信息量自适应(Google 搜索页 1296→291 token 等价分量,Overleaf 1296→986),不需要任何额外可学参数。
- Token Merging 在 GUI 上不如 Token Selection:合并会破坏位置信息从而毁掉 grounding,作者在 cross-layer(每隔一层插入一次,14 层)+ 0.5 mask ratio 上找到 1.5× 加速且几乎无精度损失的甜点。
- Interleaved streaming 把 history 压成多轮对话:action-visual 流处理 navigation 历史;action-query 流让一张高分屏(~1.3K token)配多个文本 query,避开 one-image-per-action 的 token 浪费。
- 数据质量 >> 数据规模:自采的 22K visual-only web data 击败 SeeClick 270K 全量数据;过滤掉 40% 的 static text 后性能反而上升,因为现代 VLM 自带 OCR;rebalanced sampling 再加 +3.7% avg。
- Mobile 强于 Desktop/Web 在 icon 项:揭示了一个数据缺口——非 mobile 平台缺 visual icon grounding 数据;MiniWob zero-shot (27.1%) 远落后 fine-tuned (71.5%),提示 offline IT 不能解决 OOD navigation,需要 online RL。
Teaser. ShowUI overview——给定 screenshot,UI-graph 路由 token,interleaved VLA streaming 输出 action。

Body
Motivation: GUI Visual Agent 的三个 bottleneck
作者把 GUI agent 分为两条路线:(i) language agent,依赖 HTML / a11y tree + 闭源 LLM,但用户实际只能看到屏幕;(ii) GUI visual agent,输入 screenshot,输出 action。本文走第二条,并明确三个未充分解决的问题:
- Expensive Visual Modeling:2K 高分屏经标准 patch 后产生 5K+ token,self-attn 开销爆炸。
- Managing Interleaved Vision-Language-Action:action 跨 device 不一致(web 的 SCROLL 两向 vs mobile 四向,PRESS HOME 只有 mobile 有),还要和历史 screenshot/action 一起建模。
- Diverse Training Data:跨 device、跨任务(grounding vs navigation)数据混在一起,怎么挑、怎么 balance?
2.1 UI-Guided Visual Token Selection
关键观察:UI 截图与自然图像不同,结构化、大量同色冗余 patch(空白、纯色背景),但小图标/文字又承载关键信息。RGB 值能直接做冗余信号。
Algorithm 1(UI Connected Graph):把 H×W screenshot 切成 G_h × G_w patch 网格,每 patch 作为节点,对相邻 patch 计算 RGB L2 距离 < δ 就用 Union-Find 合并。最终得到 K 个连通分量,K << G_h·G_w。
Figure (UI Connected Graph 自适应性). 同样 1272 token 输入,sparse 的 Google 页面坍缩到 291 个分量,text-rich 的 Overleaf 保留 986 个分量——验证了”按信息量自适应分配”。
Token Merging vs Token Selection——为什么选后者:
- Merging(把同 component 内 patch 平均成一个 token):破坏位置信息,grounding 精度大跌(baseline 70.8 → merging 42.3)。
- Selection(同 component 内随机跳过一部分,保留剩余 token 的原 position embedding):受 Mixture-of-Depths 启发,无新参数;UI-Graph 路由的 selection 在训练 1.5× 加速的同时保持 70.4 score。
Table 9. Token compression 方法对比
| Strategy | Vis.Ctx. | Train.Speedup | Test-time? | ScreenSpot |
|---|---|---|---|---|
| Baseline | 1344.0 | 1× | N/A | 70.8 |
| Token Merge (UI-Graph) | 852.8 | 1.6× | 否 | 42.3 / 34.7 |
| Token Selection Random | 941.5 | 1.5× | 否 | 65.3 / 56.2 |
| Token Selection UI-Graph | 947.4 | 1.5× | 否 | 70.4 / 64.9 |
❓ Token Merging 暴跌到 42.3 让我有点意外——既然位置信息丢失这么致命,是否存在保位置版本的 merging(如保留 anchor patch)能够拉回来?作者没做这个对照。
消融:cross-layer 插入(每隔一层)显著优于 all/early/late;selection ratio 0.5 是最佳 trade-off(0.75 后掉点,1.0 直接掉到 64.5)。
2.2 Interleaved Vision-Language-Action Streaming
Action 形式化:每个 action 表达为 JSON {'action': type, 'value': str, 'position': [x,y]},坐标归一化到 0-1。系统 prompt 里塞一份”action README”,把每种动作的参数语义文档化,使模型按 function-calling 风格在测试时能解释新 action(参考 xLAM)。
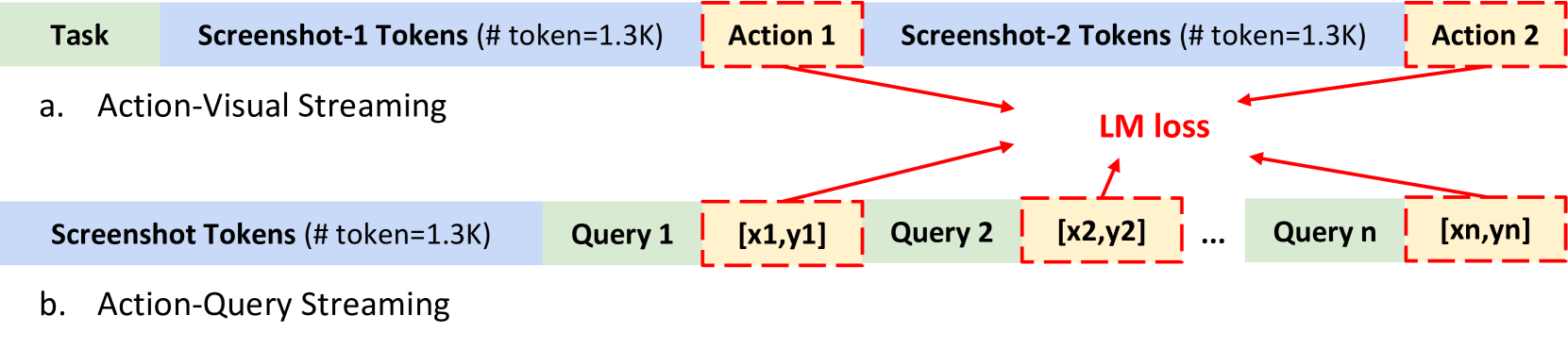
两种 streaming 模式:
- Action-Visual Streaming(navigation 用):把第 i 步执行后的 (i+1)-th screenshot 接到 i-th action 之后,形成 ⟨img_1, act_1, img_2, act_2, …⟩ 的交错序列。Mobile 跨软件切屏要保留 screenshot;Web 同一页面静态时可 mask 视觉 history 节省 token。
- Action-Query Streaming(grounding 用):同一张 1.3K-token 高分屏配多个 (query, action) 对,多轮对话内一次 forward 输出多个 grounding 标注,把视觉 token 摊薄。
Figure 6. Interleaved Vision-Text-Action Streaming 的两种模式。
2.3 GUI Instruction-Tuning Data 配方
Table 1. 256K 训练数据组成
| Usage | Device | Source | Sample | Ele. | Highlights |
|---|---|---|---|---|---|
| Grounding | Web | 自采 | 22K | 576K | Visual-based(去 static text) |
| Grounding | Mobile | AMEX | 97K | 926K | Functionality |
| Grounding | Desktop | OmniAct | 100 | 8K | GPT-4o 三种 query 重描述 |
| Navigation | Web | GUIAct | 72K | 569K | One/Multi-step |
| Navigation | Mobile | GUIAct | 65K | 585K | Multi-step |
| Total | 256K | 2.7M |
三个数据 insight:
- Web—去 static text:作者用 PyAutoGUI 自采 22 个场景(Airbnb/Booking/AMD/Apple 等)22K 屏 926K 元素,然后过滤掉占 40% 的 static text 标签(VLM 已自带 OCR),保留 576K visual element。
- Desktop—GPT-4o 重描述:OmniAct 只有 100 张图 2K 元素,原始标注是
message_ash这种孤词。用 GPT-4o 加 visual prompt(红框框元素),生成 appearance / spatial / situational 三类 query,扩展到 8K 元素。 - Mobile—Functionality:选 AMEX 因为它有超越 atomic 元素名的功能描述。
Balanced sampling:各 dataset 等概率采样,避免 Desktop(100 样本)被 AMEX(97K)淹没。Tab.6 显示这一步带来 +3.7% avg。
3.2 Main Results
Grounding:ScreenSpot
Table 2. Zero-shot grounding on ScreenSpot
| Method | Size | Train | Mobile-T | Mobile-I | Desktop-T | Desktop-I | Web-T | Web-I | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Qwen2-VL-2B | 2B | – | 24.2 | 10.0 | 1.4 | 9.3 | 8.7 | 2.4 | 9.3 |
| CogAgent | 18B | 400K | 67.0 | 24.0 | 74.2 | 20.0 | 70.4 | 28.6 | 47.4 |
| SeeClick | 9.6B | 364K | 78.0 | 52.0 | 72.2 | 30.0 | 55.7 | 32.5 | 53.4 |
| OmniParser (GPT-4V) | * | – | 93.9 | 57.0 | 91.3 | 63.6 | 81.3 | 51.0 | 73.0 |
| UGround | 7B | 1.3M | 82.8 | 60.3 | 82.5 | 63.6 | 80.4 | 70.4 | 73.3 |
| ShowUI-G (only ground) | 2B | 119K | 91.6 | 69.0 | 81.8 | 59.0 | 83.0 | 65.5 | 74.9 |
| ShowUI | 2B | 256K | 92.3 | 75.5 | 76.3 | 61.1 | 81.7 | 63.6 | 75.1 |
亮点:2B 模型 + 256K 数据干掉 18B/9.6B/7B 同类。混入 navigation data 不损害 grounding(balanced sampling 的功劳)。Icon 仍然普遍弱于 text,desktop/web 的 icon 数据是缺口。
Navigation
AITW (Mobile, 11 actions)
| Method | Overall |
|---|---|
| OmniParser (GPT-4V) | 57.7 |
| SeeClick | 59.3 |
| Qwen2-VL-2B (FT) | 67.2 |
| ShowUI† (无 visual history) | 68.3 |
| ShowUI | 70.0 |
| ShowUI-ZS | 35.9 |
Visual history 在 mobile 上额外贡献 1.7%——跨 app 的 UI 切换需要视觉上下文跟踪。
Mind2Web (Web, 3 actions):ShowUI 在 cross-task/website/domain 三档全面提升,但 visual history 在这里收益小(页面相对静态)。Cross-website / cross-domain 比 cross-task 难,瓶颈在视觉感知而非任务语义。
MiniWob (Online, 2 actions):fine-tuned 71.5% vs zero-shot 27.1% 差距巨大——offline IT 没覆盖 OOD error case,作者明确指向”需要 online RL”作为 future work。
关键消融:数据配方
Table 6. 数据配比对 ScreenSpot 的影响(Avg)
| Training Data | Sample | Avg |
|---|---|---|
| AMEX only | 97K | 70.0 |
| Web (SeeClick 270K) | 270K | 65.5 |
| Web (text+vis, 自采) | 22K | 66.6 |
| Web (vis only, 自采) | 22K | 69.0 |
| OmniAct | 100 | 68.7 |
| OmniAct (diverse, GPT-4o) | 100 | 70.9 |
| Joint-Training | 119K | 71.2 |
| + Balanced Sampling | 119K | 74.9 |
最强信号是”22K vis-only > 270K SeeClick”和”100 张 desktop + GPT-4o 重描述就能涨 2 个点”——数据 curation 比堆量更有效。
训练设置
32× V100 instruction-tuning,下游 8× V100;LoRA rank=64 alpha=128(4% 参数);FP16 + DeepSpeed Zero-2 + SDPA;lr=1e-4,max patch=1280;UI-Graph mask ratio 0.75 在 layer 14 cross-layer 插入;history length=2;data ratio Web:Mobile:Desktop:GUIAct-Web:GUIAct-Mobile = 1:1:1:1:1。IT 大约两天完成。
关联工作
基于
- Qwen2-VL-2B:base VLM。
- Mixture-of-Depths:token selection 路由机制的灵感来源。
- Token Merging (ToMe):作为对比基线被验证不适合 UI grounding。
对比
- SeeClick:前一代 GUI grounder(9.6B, 364K data),ShowUI 用更小模型更少数据超过它。
- CogAgent:18B GUI VLM,ShowUI 在 ScreenSpot 上明显更好。
- OmniParser:GPT-4V + parser 路线,ShowUI 想用单一开源模型替代之。
- UGround(7B, 1.3M):universal visual grounding 同期工作,ShowUI 用 1/5 数据 + 2B 模型 avg 略胜。
- Ferret-UI 2 / Fuyu:另两类训练 GUI VLM 的尝试。
方法相关
- OpenVLA / RT-2:robotics 侧的 VLA,ShowUI 把 VLA 范式拓展到 digital GUI 域。
- AMEX [Chai et al. 2024]:mobile functionality grounding 数据来源。
- OmniAct [Kapoor et al. 2024]:desktop grounding 数据来源,被 GPT-4o 重描述扩 4×。
- GUIAct [Chen et al. 2024]:navigation 训练数据来源。
- Mind2Web / AITW / MiniWob:navigation 评测 benchmark。
后续 / 相关方向
- GUI Agent Survey:同期 GUI agent 综述,可作为更广分类参考。
- 作者明确指向”online RL on GUI agent”作为 future work,这条线后续被相关 GUI agentic-RL 工作推进。
论文点评
Strengths
- UI-Graph 是一个漂亮的”利用 domain 结构换计算”的例子:不需要新参数、纯粹基于 RGB 距离的 Union-Find,自适应地按页面信息量分配 component 数。Token Merge vs Selection 的对比(42.3 vs 70.4)清晰说明 grounding 任务对 positional information 的依赖远超语义压缩任务。
- 数据 curation 的反直觉发现有 transferable insight:22K vis-only > 270K 全量、过滤 40% static text 反而涨点——这两条结论对所有要训 GUI grounder 的人都有用,说明现代 VLM 的 OCR 能力让 text-heavy 的 web 数据不再稀缺。
- Action 的 README 化值得借鉴:把 action space 当 function-calling schema 写进 system prompt,理论上能在 test-time 处理新 action,比 hard-code action vocab 更通用。
- 2B size + 256K data 的工程友好性:在一片 7B-18B 模型里做出 SOTA grounding,对学术 lab 复现友好。
- 诚实的 negative results:MiniWob zero-shot 27.1% vs FT 71.5% 的 gap 没有藏着,并明确指向 online RL 的下一步。
Weaknesses
- Mind2Web / AITW 的提升幅度有限:ShowUI 比 fine-tuned Qwen2-VL-2B baseline 在 AITW 仅 +2.8% (67.2→70.0),Mind2Web cross-task Step.SR 仅 +4.0% (33.2→37.2)。考虑到 interleaved streaming + 数据配方两个模块叠加,单独的贡献度并不突出;其中 visual history 在 web 上贡献几乎为零。
- UI-Graph 的 inference-time 表现弱化:Tab.9 中所有 selection 方法在 test time 应用都掉 5-9 分(70.4→64.9),这意味着 1.4× 的加速主要是训练侧收益,部署时若想要这个 speedup 要付精度代价。论文标题强调的 “33% 减少 + 1.4× 加速” 没有显式说明是 train-only。
- RGB 阈值 δ 没有 ablation:Algorithm 1 的核心超参 δ 决定 component 粒度,论文里没看到对 δ 的扫描或自适应策略,对不同分辨率/不同 DPI 屏的鲁棒性存疑。
- 与 UGround 的对比偏向自己:UGround (7B, 1.3M data) avg 73.3 vs ShowUI (2B, 256K) 75.1——但 UGround 的训练目标和数据更偏 universal grounder,把”小模型小数据更好”当 main claim 时应控制变量更严。
- UI-Graph 对带很多渐变/动画/视频缩略图的现代 web/桌面 UI 的鲁棒性?:RGB 相邻相等是个强假设,alpha-blended 半透明 UI 或 dark-mode 带阴影的 element 上未必成立。论文样例多是 PC 截图,缺少对 visually rich UI(如视频网站、富媒体 app)的 stress test。
- 256K 数据里 navigation 137K vs grounding 119K 的 1:1 sampling 假设跨任务等价:但实际下游评测 grounding 的 +ve 信号比 navigation 的强很多,没有按任务难度调整 sampling 的 ablation。
可信评估
Artifact 可获取性
- 代码: inference + training 全开(GitHub README 显示支持 Mind2Web/AITW/MiniWob 训练 + 评估,DeepSpeed/QLoRA/FlashAttention2,多 GPU/多节点)。
- 模型权重:
showlab/ShowUI-2B在 HF 公开;后续还放了ShowUI-Aloha、ShowUI-π(2025 年底)等扩展 checkpoint;亦支持 vllm / int8 推理。 - 训练细节: 完整披露超参(lr/LoRA/batch/精度/插入层/mask ratio/sampling weight),未明说 random seed 和 grad-clip。
- 数据集:
showlab/ShowUI-desktop-8K和ShowUI-web数据集已发布在 HF;自采 22K Web data 已公开;其余 AMEX/OmniAct/GUIAct 都是公开 source。
Claim 可验证性
- ✅ “75.1% zero-shot ScreenSpot grounding”:Tab.2 完整数字 + 同 benchmark 多 baseline 对比,权重已开源可复现。
- ✅ “256K 数据训出”:Tab.1 给出每个数据 source 的样本数,可逐项核对。
- ✅ “UI-Graph 减 33% token + 1.4× 加速”:Tab.9 给出 1344→947 token(≈30% 减少)和 1.5× speedup,与正文 1.4× 略不一致但量级吻合。
- ⚠️ “Interleaved streaming 提升 navigation”:AITW 上 ShowUI vs ShowUI† 仅 +1.7%,统计意义和 seed variance 没报,单 seed 的 1.7% 难说显著。
- ⚠️ “Action README 让模型在测试时处理新 action”:这是个吸引人的 claim,但没有专门的 held-out novel action benchmark 验证泛化,只在已见 action space 内评测。
- ⚠️ “lightweight 2B”:与 SeeClick (9.6B)/CogAgent (18B) 比是真小,但与同尺寸 Qwen2-VL-2B baseline 对比,grounding 提升的相当一部分应归功于 instruction-tuning 而非架构创新——Tab.2 baseline Qwen2-VL-2B 仅 9.3% 是几乎裸跑,对比可能过于宽松。
Notes
- UI-Graph 的”用结构信号路由计算”思想可推广到其他高分辨率结构化输入:如 PDF 解析、code rendering、design canvas——只要存在 RGB 冗余 + 关键小元素的双重 pattern,都可能受益。
- “Action README in system prompt” 模式与 tool-use / function-calling 完全同构,意味着 GUI agent 与 LLM tool agent 的边界在模型设计层面正在融合;测试时新 action 的真实泛化需要专门 benchmark(held-out action 类)来验证,是个值得做的小研究。
- 数据 curation insight(“VLM 自带 OCR ⇒ 不要堆 static text”)反过来说明 GUI grounder 应该专注 visual element 数据收集,而不是从 HTML 自动 dump。这条 insight 应该写进所有 GUI agent project 的 data SOP。
- MiniWob ZS 27% vs FT 71% 的 gap 是 offline IT 范式的根本局限——OOD error 只能在 online interaction 中暴露。这进一步强化”GUI agent 必须做 online RL/self-improvement”的判断(与 agentic-RL 方向的趋势一致)。
- 作为 2B 端到端 grounder,ShowUI 的实际部署可定位为”更轻、更通用的 SoM/OmniParser 替代”——但若要做 long-horizon multi-app navigation,2B 容量与 history length=2 的设计可能成为 hard constraint。
Rating
Metrics (as of 2026-04-24): citation=173, influential=24 (13.9%), velocity=10.24/mo; HF upvotes=90; github 1808⭐ / forks=135 / 90d commits=2 / pushed 0d ago
分数:2 - Frontier
理由:站在 GUI visual agent 方向的前沿——2B+256K 击败 CogAgent(18B)/SeeClick(9.6B)/UGround(7B) 的 ScreenSpot 结果让它成为”轻量 GUI grounder”范式的代表;CVPR 2025 + 公开 showlab/ShowUI-2B / ShowUI-Aloha 等后续 checkpoint 表明社区在持续把它作为 baseline 和起点使用。尚不到 3 - Foundation,因为核心组件(UI-Graph train-time-only 增益、README action 未做 held-out 验证、Mind2Web/AITW 相对 FT baseline 提升有限,见 Weaknesses 1-2)并非开创性 primitive;也明显高于 1 - Archived,因为它未被后续工作取代,反而作为 ShowUI-Aloha / ShowUI-π 系列的底座继续演进。