Summary
RynnBrain: Open Embodied Foundation Models
- 核心: 统一 egocentric understanding、spatio-temporal localization、physically grounded reasoning 和 physics-aware planning 的开源 embodied foundation model
- 方法: 基于 Qwen3-VL 做 physics-aware spatio-temporal pretraining(20M 样本),引入 Chain-of-Point (CoP) interleaved reasoning + GRPO RL
- 结果: 在 20 个 embodied benchmarks 上大幅超越同等规模 embodied brain 模型;post-trained 变体在 VLN、manipulation planning、VLA 任务上均取得 SOTA
- Sources: paper | website | github
- Rating: 2 - Frontier(大规模开源 embodied foundation model 系列,在当前 embodied brain model 前沿占据重要位置,但尚未被社区定型为 de facto baseline)
Key Takeaways:
- 统一四大能力: Egocentric understanding + spatio-temporal localization + physically grounded reasoning + physics-aware planning 在同一模型中实现,解决了现有 VLM 缺乏物理 grounding、embodied model 缺乏语义泛化的割裂问题
- Chain-of-Point (CoP) reasoning: 提出 interleaved textual-spatial reasoning 范式,推理过程中交替输出文本和空间坐标(bounding box / point / trajectory),用 GRPO 强化学习进一步对齐物理世界
- 数据飞轮 + 20M 样本: 设计 human-model collaborative data pipeline 覆盖 cognition / localization / planning 三类数据,总量约 20M samples,数据构建本身是重要贡献
- 强 post-training 潜力: RynnBrain 作为 backbone 用于 VLN (RynnBrain-Nav)、manipulation planning (RynnBrain-Plan)、VLA (RynnBrain-VLA) 均显著提升下游性能,证明 embodied pretraining 的迁移价值
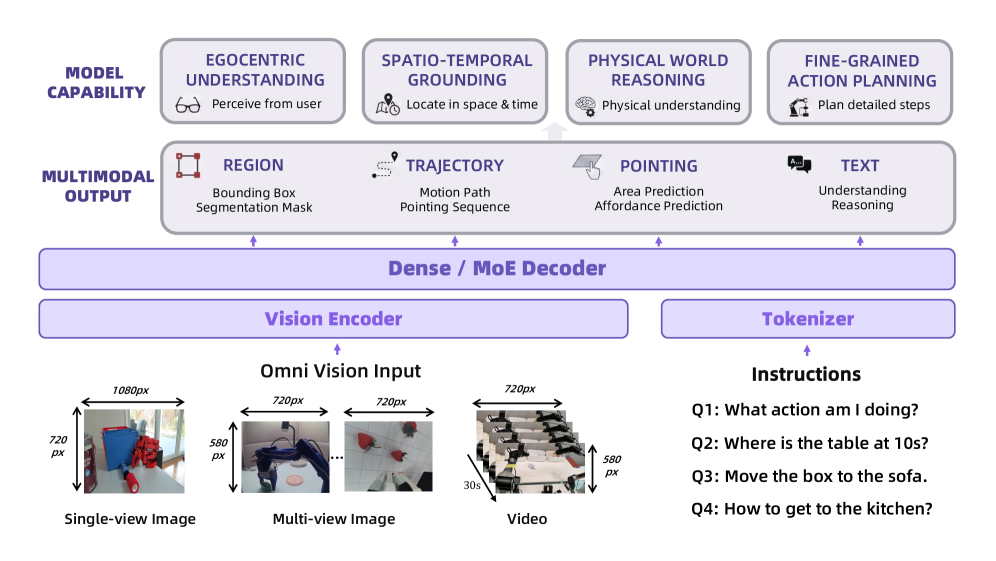
Teaser. RynnBrain 能力全景与系统架构

Introduction
现有 VLM 不具备物理 grounding 能力(spatio-temporal consistency、physical reasoning、actionable planning),而 embodied model 仅在 action-centric 数据上训练,丢失了大规模多模态预训练的语义泛化能力。现有 embodied brain 模型(如 RoboBrain 2.0、Robix)有三个核心局限:(1) egocentric cognitive capability 范围窄;(2) spatial reasoning 仅限 static image;(3) 高层推理在纯文本空间进行,与物理约束脱节。
RynnBrain 的核心定位:统一的 spatio-temporal foundation model,保留 VLM 语义广度同时显式围绕 physical space、temporal dynamics 和 embodiment constraints 构建。作为高层 cognitive “brain” 服务于感知、推理和决策,同时可适配下游控制系统。
Overview
Model Architecture
Figure 2. RynnBrain 架构总览
RynnBrain 采用 decoder-only vision-language 架构,继承 Qwen3-VL 设计:vision encoder + vision-language projector + LLM backbone,初始化自 Qwen3-VL 变体(2B/8B/30B-A3B-Instruct)。额外采用 DeepStack 和 Interleaved MRoPE 改进多模态信息融合。
输出空间统一为 text + spatial grounding primitives(bounding box、point、trajectory),所有空间实体归一化到 [0, 1000] 并编码为 integer token,将连续空间预测转化为 classification 问题。
Infrastructure
训练面临序列长度分布高方差 + 长尾的挑战(多模态数据跨任务差异大)。关键优化:
- Online load-balancing pipeline: 按 sequence length 估计值跨 DP worker 动态重分配样本,贪心近似最小化最大累积长度,消除 straggler effect
- Per-sample loss reduction: 避免 all-gather 计算全局 token count,用每样本均值替代,训练效率翻倍且不影响收敛
- ZeRO-1/2 + Expert Parallel: 2B/8B 用 ZeRO-1 + gradient checkpointing;30B-A3B 用 ZeRO-2 + EP(world_size=2) + DeepEP token dispatching
Physics-Aware Spatio-temporal Pretraining
两个基本能力驱动 pretraining 设计:(1) Spatio-temporal Memory — 从 visual history 建立空间、位置、事件、轨迹的多维表示;(2) Physical World Grounding — 所有认知过程必须根植于物理世界客观现实。
Training Recipe
- Unified spatio-temporal representation: 图像和视频作为统一 visual modality,视频均匀采样保持时间连续性,每帧编码为 visual token + temporal positional embedding
- Physically grounded output space: 引入 discrete coordinate token 表示物理位置,bounding box / point / trajectory waypoint 归一化到 [0, 1000],与 language token 用相同 autoregressive 机制生成
Equation 1. Next-token prediction loss
符号说明: 为 visual input, 为 textual + coordinate token 混合序列, 为模型参数。
Table 1. 预训练超参数
| Parameter | RynnBrain-2B | RynnBrain-8B | RynnBrain-30B-A3B |
|---|---|---|---|
| Base Model | Qwen3-VL-2B-Instruct | Qwen3-VL-8B-Instruct | Qwen3-VL-30B-A3B-Instruct |
| Optimizer | AdamW | AdamW | AdamW |
| Learning Rate | 5e-6 | 2e-6 | 2e-6 |
| Learning Rate Vision | 1e-6 | 2e-6 | 2e-6 |
| Global Batch Size | 512 | 1024 | 1024 |
| Warmup Ratio | 0.03 | 0.03 | 0.03 |
Pretraining Data
总计约 19.89M 样本,覆盖 4 大类 12 个子任务。数据构建采用 human-model collaborative flywheel:用预训练 foundation model 生成初始标注,仅在关键决策点引入人工监督。
Table 2. 预训练数据统计
| Category | Sub-Task | Samples (M) |
|---|---|---|
| General MLLM | General | 4.80 |
| Cognition | Object Understanding | 1.10 |
| Cognition | Spatial Understanding | 2.50 |
| Cognition | Counting | 0.30 |
| Cognition | OCR | 1.00 |
| Cognition | Egocentric Task Understanding | 2.77 |
| Localization | Object Localization | 1.20 |
| Localization | Area Localization | 3.37 |
| Localization | Affordance Localization | 1.13 |
| Localization | Trajectory Prediction | 0.56 |
| Localization | Grasp Pose Prediction | 1.00 |
| Planning | Manipulation | 0.16 |
| Total | 19.89 |
Insights: Localization 类数据占比最大(~7.26M),远超 Planning(0.16M)。Cognition 数据来自大量公开数据集 + 自采 egocentric 视频的自动标注。Spatial understanding 数据通过 MASt3R-SLAM 重建 3D 点云 + RANSAC ground plane 对齐后生成 metric QA,是获取 3D spatial reasoning 能力的关键。OCR 数据来自 Ego4D / Charades-Ego / EPIC-KITCHENS,用 GoMatching 检测场景文字。
关键数据构建 pipeline:
- Object understanding: Qwen2.5-VL 识别 → Grounding DINO 1.5 检测 → SAM2 分割跟踪 → Qwen2.5-VL 生成 QA
- Spatial understanding: MASt3R-SLAM 重建 → RANSAC 对齐 → template-based 几何 QA 生成
- Trajectory: 人工标注 + FSD 数据,轨迹表示为最多 10 个归一化 waypoint
- Grasp pose: Grasp-Anything 数据集,oriented rectangle → 4 corner points
Physically Grounded Chain-of-Point Reasoning
现有多模态推理模型(Video-R1、DeepSeek-VL 等)依赖纯文本 reasoning,推理过程与物理空间结构脱节。RynnBrain 提出 Chain-of-Point (CoP) reasoning:在 egocentric video stream 上交替进行 textual inference 和 explicit spatial grounding,将中间推理步骤锚定到具体空间 reference。
Cold-Start SFT
从预训练 RynnBrain 出发,全参数 SFT。数据构建 pipeline:
- Qwen3-VL-235B 预生成 step-by-step textual reasoning chain,标记候选 entity
- In-house model 将 entity 分类为 “area” 或 “object”
- 人工标注员选择最佳帧并标注 bounding box(object)或 representative points(area)
- Grounding 结果以
<object/area> <frame n>: (coordinates) </object/area>格式插入 reasoning text
最终生成 interleaved textual-spatial reasoning chain,模型学会在 thinking 过程中持续锚定物理空间。
Reinforcement Learning
使用 GRPO 对齐 physically grounded reasoning。相比 PPO 不需要 critic,从 group 内多个输出的得分估计 baseline。
Equation 2. GRPO objective
符号说明: 为 importance sampling ratio, 为 group-normalized advantage, 为 KL 系数。
Reward Design — 三类 task-specific rule-based reward:
- Trajectory: Discrete Frechet Distance (DFD) 的指数衰减
- Affordance: Bidirectional Mean Euclidean Distance(Chamfer distance 变体)的指数衰减
- Area: predicted points 落在 ground truth polygon 内的比例
RL 数据: 30K 高质量样本,通过 difficulty-aware filtering 保留中等难度(SFT model score 40-80)+ failure case 子集。
Post-training for Embodied Tasks
Vision-Language Navigation
RynnBrain-Nav 采用 multi-turn conversational format(借鉴 StreamVLN),训练数据组织为 observation-action pair 序列。数据规模:R2R / R2R-EnvDrop / RxR 的 450K 视频 + ScaleVLN 300K 增强 + multi-turn DAgger 采集。在 R2R 和 RxR benchmark 上取得 SOTA。
Manipulation Planning
RynnBrain-Plan 用 multi-turn dialogue 格式维护 explicit memory buffer。关键发现:仅需几百个样本 fine-tune 即可获得 robust long-horizon planning 和 generalization 能力(data-efficient)。Grounding annotation 仅在每轮对话的最后一帧标注,确保决策基于即时观测 + 累积记忆。
VLA
Figure 3. RynnBrain-VLA 架构
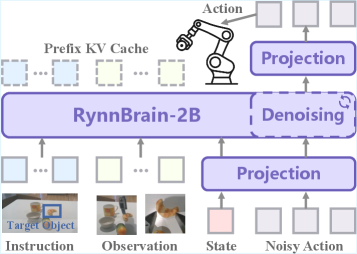
RynnBrain-VLA 基于 RynnBrain-2B 构建,采用 flow matching framework 预测 action chunk(借鉴 π0)。VLM backbone 作为 single-stream DiT,packed sequence 包含 condition + noisy actions。添加三个 linear projection 对齐 noise / timestamp embedding / action 到 VLM hidden size。用 Franka Emika arm 上 6 个 pick-and-place task 的 teleoperation 数据 fine-tune 60K steps。
关键结论:在高复杂度抓取场景中,RynnBrain-VLA 持续优于从 π0.5 fine-tune 的模型,说明 strong scene understanding + embodied grounding 是 generalizable VLA 的关键 foundation。
Evaluation
RynnBrain-Bench
Figure 4. RynnBrain-Bench 评估维度
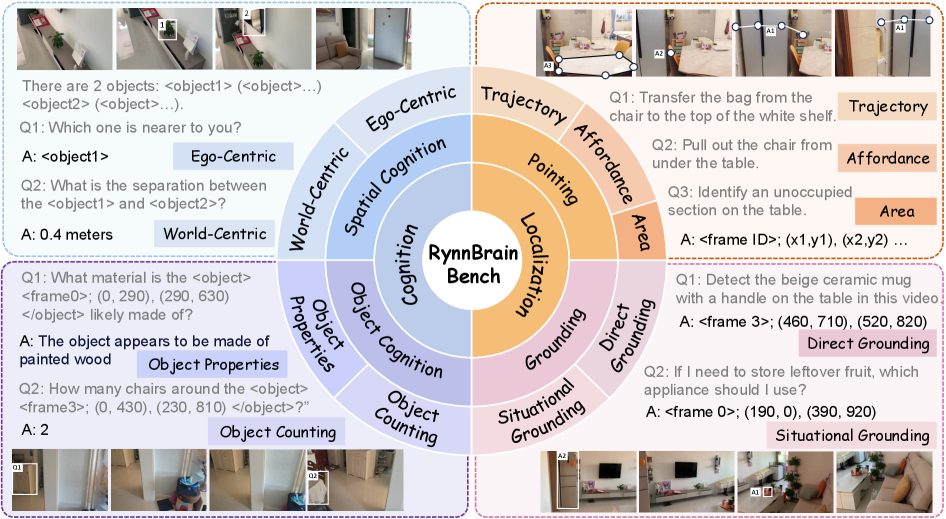
RynnBrain-Bench 包含 3,616 个 video clip(577,998 frames)和 12,000 个人工标注的 open-ended question,覆盖 21 个子能力:
- Object Cognition: 9 个 object attribute + counting,GPT-4o 评分
- Spatial Cognition: Ego-centric vs World-centric,MRA/RoA + GPT-4o
- Grounding: Direct + Situational grounding,Acc@0.5
- Pointing: Area / Trajectory / Affordance,DFD / polygon accuracy / distance decay
主要实验结果
RynnBrain-8B 在几乎所有 embodied cognition 和 location benchmark 上大幅超越同规模模型(MiMo-Embodied 7B、RoboBrain 2.0 7B、Pelican-VL 7B、Cosmos-reason2 8B),同时保持接近 Qwen3-VL 的 general visual understanding 性能。值得注意的对比:
- VSI-Bench: RynnBrain-8B 71.0 vs MiMo-Embodied 48.5 / Qwen3-VL 60.3
- RynnBrain-Grounding: RynnBrain-8B 81.6 vs MiMo-Embodied 49.8 / Qwen3-VL 62.8
- RynnBrain-Object: RynnBrain-8B 71.2 vs MiMo-Embodied 39.0
- General understanding (DocVQA): RynnBrain-8B 96.2,与 Qwen3-VL 96.4 几乎持平
CoP reasoning(SFT + RL)在 trajectory prediction 任务上提升约 7%。RynnBrain-Nav 在 R2R 和 RxR benchmark 上一致超越基于 Qwen3-VL 的对应模型。
关联工作
基于
- Qwen3-VL: RynnBrain 的 base model,继承 vision encoder + LLM 架构
- π0: RynnBrain-VLA 借鉴其 flow matching action chunk 预测框架
- GRPO: CoP reinforcement learning 的优化算法
对比
- RoboBrain 2.0: 同类 embodied brain model,RynnBrain 在几乎所有 benchmark 上大幅超越
- MiMo-Embodied: 7B 规模 embodied model,RynnBrain-2B 即可超越
- Pelican-VL: embodied VLM baseline
- Cosmos-reason2: NVIDIA 的 embodied reasoning model
方法相关
- Chain-of-Thought reasoning: CoP 是 CoT 在物理空间的自然延伸
- StreamVLN: RynnBrain-Nav 借鉴其 multi-turn conversational VLN format
- MASt3R-SLAM: 用于构建 spatial understanding 训练数据
论文点评
Strengths
- 系统性工程: 从数据 pipeline、pretraining recipe、post-training 到 benchmark 一体化设计,工程完整度极高
- 统一的 physically grounded output space: 将 spatial entities 离散化为 coordinate token 与 language token 同质化,是优雅且 scalable 的设计
- Chain-of-Point reasoning 是新颖且务实的 contribution: 将 CoT 的 intermediate steps 锚定到物理空间坐标,比纯文本推理对 embodied task 更有意义;GRPO reward design(DFD、Chamfer distance、polygon accuracy)针对空间任务合理
- 开源力度大: 4 个 scale 的 foundation model + 3 个 post-trained variant + benchmark + 训练框架全部开源
- 数据贡献实质: 20M 样本的构建方法论(MASt3R-SLAM spatial QA、GoMatching OCR、human-model collaborative flywheel)有独立参考价值
Weaknesses
- VLA 实验规模有限: RynnBrain-VLA 仅在 6 个 pick-and-place task 上验证(Franka single arm),远不足以证明 generalizable VLA 的 claim;与 π0.5 的对比也仅限于这个小规模 setting
- Manipulation planning 数据未开源: 声称 “几百个样本” 即可,但这批数据是 in-house 的,可复现性受限
- Pretraining data 大量使用私有数据: RynnBrain-Object / RynnBrain-Spatial / RynnBrain-OCR / RynnBrain-Area 等均为内部构建,虽然公开了构建方法但数据本身不可获取
- RynnBrain-Bench 自建自评: 虽有 human-in-the-loop 标注,但在自家 benchmark 上大幅领先存在 evaluation bias 风险
- 30B-A3B MoE 的消融不足: 没有充分展示 MoE vs Dense 在相同 compute budget 下的对比
可信评估
Artifact 可获取性
- 代码: inference + training(基于 HuggingFace Transformers,training 用 RynnScale)
- 模型权重: RynnBrain-2B/4B/8B/30B-A3B + RynnBrain-CoP-8B + RynnBrain-Plan-8B/30B-A3B + RynnBrain-Nav-8B,全部在 HuggingFace 和 ModelScope 发布
- 训练细节: 超参 + 数据配比 + 训练步数较完整,但部分细节(如 pretraining epoch 数、具体数据 mixing ratio)在 paper 中未完全披露
- 数据集: 混合使用公开数据集和自建数据集;自建数据部分仅公布 pipeline 描述,RynnBrain-Bench 公开发布在 HuggingFace
Claim 可验证性
- ✅ 在 20 个公开 embodied benchmark 上大幅超越同规模模型:有完整实验数据,部分 baseline 为作者复现
- ✅ CoP reasoning 提升 trajectory prediction 约 7%:有 ablation 对比
- ⚠️ “仅需几百个样本即可获得 robust long-horizon planning”:data-efficiency claim 缺少 scaling curve 或控制实验
- ⚠️ RynnBrain-VLA 优于 π0.5 fine-tuned models:仅在 6 个自定义 task 上验证,规模太小
- ⚠️ RynnBrain-Bench 的评估公正性:自建 benchmark 的 data distribution 可能有利于自家模型
Notes
Rating
Metrics (as of 2026-04-24): citation=4, influential=0 (0.0%), velocity=1.74/mo; HF upvotes=45; github 734⭐ / forks=70 / 90d commits=45 / pushed 9d ago
分数:2 - Frontier 理由:RynnBrain 是当前 embodied brain model 前沿的大规模系统工程,在 20 个 benchmark 上大幅超越 RoboBrain 2.0、MiMo-Embodied、Pelican-VL、Cosmos-reason2 等同规模对手(参见 Strengths 1/4 和主要实验结果),具备必须比较的 baseline 价值;CoP reasoning 与 physically grounded output space 的设计代表方法范式的前沿尝试。但尚未达到 Foundation 档——方法范式(coordinate token 化、embodied 多任务 pretraining)并非开创性,VLA 验证规模过小(Weaknesses 1),作为新开源工作社区采纳度尚在形成中,不像 Qwen3-VL / π0 那样已成为 de facto backbone。