Summary
Vlaser: Vision-Language-Action Model with Synergistic Embodied Reasoning
- 核心: 基于 InternVL3 构建 embodied VLM,系统研究 VLM 预训练数据对下游 VLA 微调的影响
- 方法: Vlaser-6M 多任务 embodied 数据集 + flow matching action expert;分离 VLM embodied reasoning 预训练和 VLA 微调两阶段
- 结果: 12 个 embodied reasoning benchmark SOTA(avg 51.3@8B);WidowX SOTA(65.1%);关键发现:in-domain 数据远比 OOD embodied reasoning 数据对 VLA 性能更关键
- Sources: paper | website | github
- Rating: 2 - Frontier(提出 OOD reasoning vs in-domain 的重要 negative result + 完整开源 Vlaser-6M,当前在 embodied reasoning-VLA 协同方向是重要参考;但方法上沿用 π0 flow matching + InternVL3 SFT,且未跨越 sim-to-real,尚未到奠基 level)
Key Takeaways:
- In-domain 数据 >> OOD embodied reasoning 数据: OOD embodied reasoning 数据虽然大幅提升 reasoning benchmark 分数(15.2→45.3@2B),但对下游 VLA closed-loop 性能几乎无提升(41.8→43.2);而 in-domain 数据(来自同一仿真平台的 QA/grounding/spatial 数据)则显著提升 VLA 成功率(41.8→65.1)
- Domain shift 是核心瓶颈: 当前 embodied reasoning benchmark 与实际机器人操控任务之间存在严重 domain gap,主要来自视角差异(互联网图片 vs 机器人视角)
- 多类型 in-domain 数据的叠加效应: 单独使用 QA/spatial/grounding 中任一类 in-domain 数据都有显著提升,三者组合进一步提升(Vlaser-All 优于单类型)
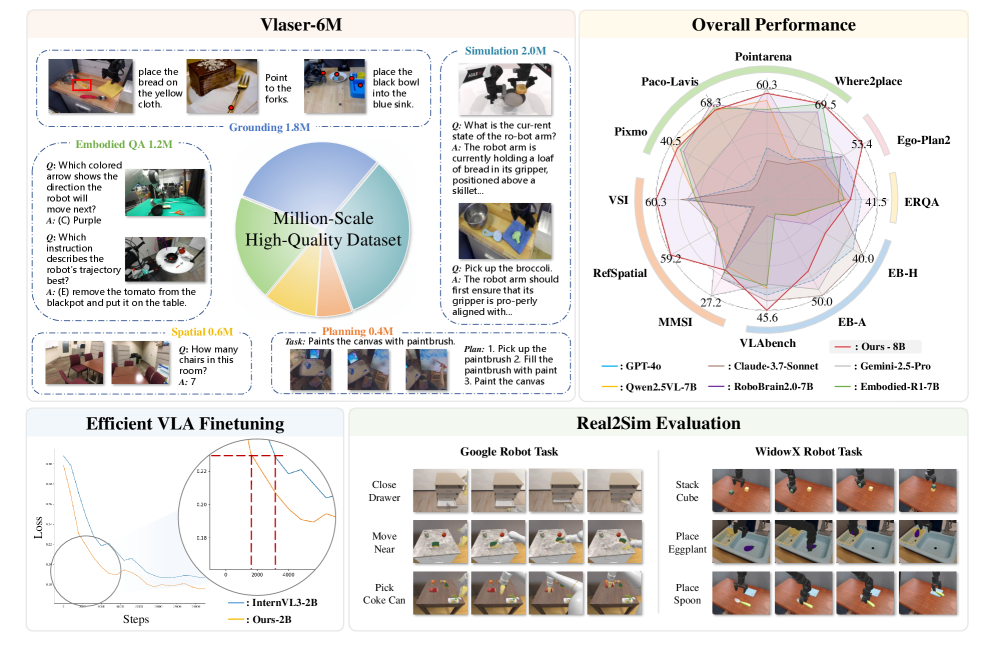
Teaser. Vlaser 整体框架:数据集组成、embodied reasoning 能力、VLA 收敛加速、closed-loop 评估
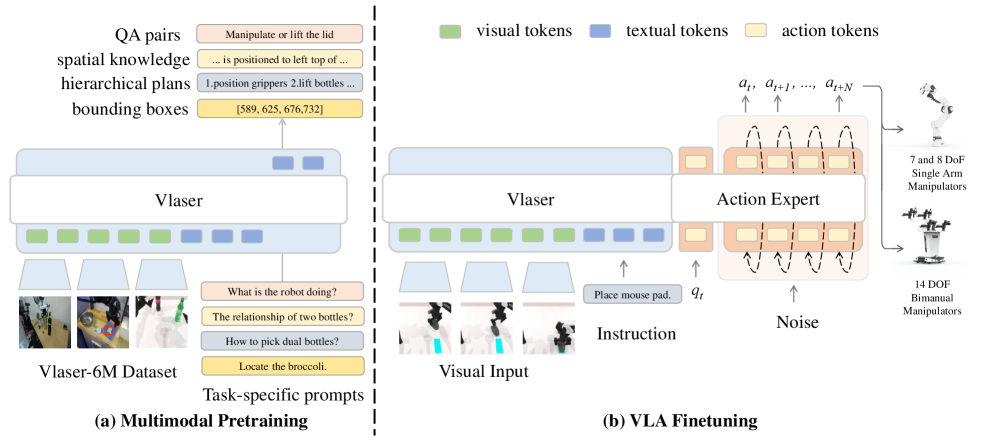
Model Structure
Vlaser 由两个主要组件构成:VLM backbone 和 action expert。
VLM Backbone: 基于 InternVL3(2B 和 8B 两个规模),使用 InternViT 作为 vision encoder,分别搭配 Qwen2.5-1.5B 和 Qwen2.5-7B 作为 LLM。通过 Vlaser-6M 数据集 SFT 增强 embodied common-sense reasoning 能力。
Action Expert: 参照 π0 的设计,在 VLM 基础上加入 flow matching action expert。Action expert 类似 MoE 架构——原始参数处理图像和文本,独立的一组权重处理 action 和 state token。State 编码为 state token,noised actions 编码为 action tokens,输入 action expert,使用 non-causal attention。推理时从随机噪声开始去噪生成动作序列。
Figure 2. Vlaser 架构示意图
Vlaser Data Engine
Vlaser-6M 数据集包含四大类 embodied reasoning 数据:
- Embodied Grounding (1.5M+300K): 2D grounding(bounding box 和 center point,归一化到 [0, 1000]),数据来自 RoboPoint、ShareRobot、Pixmo-Points、Paco-LaVIS、RefSpatial,另从 SA-1B 生成 300K 额外标注
- General & Spatial Reasoning (1.2M+500K): 包括 RoboVQA 和 spatial intelligence 数据,来自 RoboVQA、Robo2VLM、SPAR、SpaceR-151k、VILASR 等,另有 100K 从 ScanNet/ScanNet++/ARKitScenes 手动标注的 3D spatial 样本
- Planning (400K): 语言规划和多模态任务分解,来自 Alpaca-15k-Instruction、MuEP、WAP、LLaRP + Habitat、EgoPlan-IT、EgoCOT
- In-Domain Data (2M): 针对下游 VLA 平台生成的 in-domain QA,覆盖 SimplerEnv(Google Robot + WidowX)和 RoboTwin(Aloha-AgileX),包含 general QA、grounding QA、spatial reasoning QA 三类,使用 Qwen2.5VL-7B 生成,Qwen2.5VL-32B 做 LLM-as-a-judge 过滤
Training Recipe
两阶段训练:VLM 预训练 + VLA 微调。
Stage 1: Vision-Language Pretraining — 在 InternVL3 基础上全参数 SFT(包括 ViT、MLP projector 和 LLM),使用标准 auto-regressive language modeling loss:
Equation 1. Language modeling loss
符号说明: 为 ViT + MLP, 为 text tokenizer, 为 LLM 参数。 训练设置: 5000 steps,global batch size 128,learning rate 2e-5 cosine decay。
Stage 2: Vision-Language-Action Finetuning — 在 VLM 基础上加入 flow matching action expert,训练 action chunk 预测。Action chunk ,noisy action ,优化目标为:
Equation 2. VLA flow matching loss
推理时通过 Euler 积分从 到 生成动作:
Equation 3. Action denoising (Euler integration)
训练设置: H=4(action chunk),=10(推理步数),10 epochs,global batch size 1024,learning rate 5e-5。
Performance on Embodied Reasoning Capability
在 12 个 embodied reasoning benchmark 上评估(QA、Planning、Grounding、Spatial Intelligence、Simulation),对比 closed-source 模型和 open-source embodied VLM。
Table 1. 12 个 Embodied Reasoning Benchmark 综合对比(部分关键结果)
| Model | ERQA | Ego-Plan2 | Where2place | Pointarena | Paco-Lavis | VSIBench | RefSpatial | VLABench | EB-ALFRED | EB-Habitat | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | 47.0 | 41.8 | 29.1 | 29.5 | 16.2 | 42.5 | 8.8 | 39.3 | 56.3 | 59.0 | 34.2 |
| Gemini-2.5-Pro | 55.0 | 42.9 | 39.9 | 62.8 | 45.5 | 43.4 | 30.3 | 34.8 | 62.7 | 53.0 | 44.4 |
| InternVL3-2B | 31.5 | 30.9 | 5.2 | 7.1 | 15.4 | 31.5 | 1.8 | 19.4 | 1.3 | 12.0 | 15.2 |
| RoboBrain2.0-3B | 37.3 | 41.8 | 64.2 | 46.0 | 67.6 | 28.8 | 46.5 | 18.1 | 0.0 | 10.0 | 35.3 |
| Vlaser-2B | 35.8 | 38.3 | 74.0 | 57.8 | 72.5 | 57.5 | 43.0 | 23.1 | 42.3 | 30.7 | 45.3 |
| InternVL3-8B | 35.3 | 40.0 | 10.0 | 14.2 | 21.1 | 42.1 | 5.6 | 24.7 | 19.0 | 23.7 | 22.3 |
| Embodied-R1-7B | 38.3 | 37.1 | 69.5 | 51.2 | 69.9 | 38.6 | 31.1 | 35.5 | 10.0 | 19.0 | 38.9 |
| RoboBrain2.0-7B | 42.0 | 33.2 | 63.6 | 49.5 | 73.1 | 36.1 | 32.5 | 6.6 | 14.0 | 29.3 | 37.0 |
| Vlaser-8B | 41.0 | 53.4 | 69.5 | 60.3 | 68.3 | 60.3 | 59.2 | 45.6 | 50.0 | 40.0 | 51.3 |
Insights: Vlaser-6M SFT 带来巨幅提升(InternVL3-2B 15.2→45.3,InternVL3-8B 22.3→51.3),grounding 和 simulation 提升最大。有趣的是 Vlaser-2B 在简单 point grounding 任务上优于 8B,而 8B 在多步规划和 closed-loop 仿真上更强,说明模型规模选择应依据目标应用。
Performance on downstream Close-Loop Robot Tasks
在 SimplerEnv(WidowX + Google Robot)和 RoboTwin(Aloha-AgileX bimanual)上评估 VLA 性能。核心实验设计:对比 InternVL3-2B(base)、Vlaser-OOD(仅 OOD embodied reasoning 数据)、Vlaser-QA/Spatial/Grounding(分别加入单类 in-domain 数据)、Vlaser-All(全部 in-domain 数据)。
Table 2. SimplerEnv WidowX 任务
| Model | Carrot on plate | Eggplant in basket | Spoon on towel | Stack Cube | Avg |
|---|---|---|---|---|---|
| SpatialVLA (4B) | 25.0% | 100.0% | 16.7% | 62.5% | 42.7% |
| π0 (3B) | 55.8% | 79.2% | 63.3% | 21.3% | 54.9% |
| InternVL3-2B | 42.9% | 57.1% | 55.8% | 11.3% | 41.8% |
| Vlaser-OOD (2B) | 60.8% | 35.4% | 56.7% | 20.0% | 43.2% |
| Vlaser-QA (2B) | 55.8% | 83.3% | 77.9% | 33.3% | 62.6% |
| Vlaser-All (2B) | 52.5% | 87.9% | 76.6% | 43.3% | 65.1% |
Table 3. SimplerEnv Google Robot 任务(Visual Matching / Variant Aggregation)
| Model | VM Pick Coke | VM Move Near | VM Drawer | VM Avg | VA Pick Coke | VA Move Near | VA Drawer | VA Avg |
|---|---|---|---|---|---|---|---|---|
| Magma (8B) | 56.0% | 65.4% | 83.7% | 68.4% | 53.4% | 65.7% | 68.8% | 62.6% |
| π0 (3B) | 72.7% | 65.3% | 38.3% | 58.3% | 75.2% | 63.7% | 25.6% | 54.8% |
| InternVL3-2B | 94.3% | 78.8% | 19.0% | 64.0% | 80.4% | 72.7% | 11.1% | 54.7% |
| Vlaser-OOD (2B) | 85.0% | 76.3% | 44.9% | 68.7% | 74.4% | 69.2% | 10.3% | 51.3% |
| Vlaser-All (2B) | 91.0% | 85.4% | 52.1% | 76.2% | 80.5% | 77.7% | 18.8% | 59.0% |
Table 4. RoboTwin 双臂任务(Avg over 12 tasks)
| Model | Avg |
|---|---|
| RDT-1B | 36.8% |
| InternVL3-2B | 55.8% |
| Vlaser-OOD (2B) | 54.5% |
| Vlaser-All (2B) | 67.5% |
Insights: 核心发现——Vlaser-OOD 对 VLA 下游任务几乎无提升(与 InternVL3-2B 基线持平),而 in-domain 数据带来显著提升。这说明当前 embodied reasoning benchmark 与 closed-loop robot control 之间没有正相关,根本原因是互联网数据与机器人视角之间的 domain shift。三类 in-domain 数据任一都有显著增益,全部组合效果最佳。
Ablation Studies
消融实验验证三个关键超参数:predicted action length P、execute action length H、flow matching sampling steps 。
Table 5. WidowX 超参消融
| Model | P | H | Steps | Avg |
|---|---|---|---|---|
| InternVL-2B | 4 | 4 | 10 | 41.8% |
| InternVL-2B | 4 | 2 | 10 | 21.2% |
| InternVL-2B | 2 | 2 | 10 | 28.7% |
| Vlaser-OOD (2B) | 4 | 4 | 10 | 43.2% |
| Vlaser-QA (2B) | 4 | 4 | 10 | 62.6% |
| Vlaser-QA (2B) | 4 | 4 | 20 | 63.3% |
Insights: P=4, H=4 是最优配置。增加 sampling steps 到 20 几乎无额外收益。在所有超参配置下,in-domain 数据的提升都很稳健,验证了结论的 robustness。
Limitations
论文未进行真实机器人实验,所有实验均在仿真环境中完成。
关联工作
基于
- InternVL3: 作为 VLM backbone,Vlaser 在此基础上 SFT 增强 embodied reasoning
- π0: Action expert 的 flow matching MoE 设计直接参考 π0 架构
- open-pi-zero: VLA 训练和推理代码基于此开源实现
对比
- RoboBrain2.0: 同期 embodied reasoning VLM,使用 RFT 方法,Vlaser 在综合分数上 +10%
- Embodied-R1: 同期 embodied reasoning VLM,使用 RL fine-tuning,Vlaser 在多数 benchmark 上领先
- SpatialVLA: VLA baseline,Vlaser-All 在 WidowX 上显著超越(65.1% vs 42.7%)
方法相关
- Flow Matching: 用于 action prediction 的生成方法,替代 diffusion
- SimplerEnv: 标准化仿真评估框架,支持 WidowX 和 Google Robot
- RoboTwin: 双臂操作仿真框架,用于 Aloha-AgileX 评估
论文点评
Strengths
- 系统性的 data ablation 设计:通过 OOD vs in-domain、QA/Spatial/Grounding 分别消融的实验设计,清晰回答了”哪些数据对 VLA 微调最有效”这个重要问题,实验设计比单纯堆 SOTA 有洞察力
- 重要的 negative result: OOD embodied reasoning 数据对 VLA 无显著提升这一发现,直接挑战了”先提升 VLM reasoning 再微调 VLA”的直觉假设,对社区有实际指导价值
- 全面的 benchmark 覆盖: 12 个 embodied reasoning benchmark + 3 个仿真平台(WidowX、Google Robot、RoboTwin),覆盖了 QA、grounding、spatial、planning、closed-loop 多个维度
- 完整开源: 代码、模型(VLM + VLA)、6M 数据集全部开源,可复现性强
Weaknesses
- 无真实机器人实验: 这是最明显的局限。虽然 SimplerEnv 声称 sim-to-real 相关性强,但 domain shift 恰恰是本文的核心论点之一,仅在仿真中验证这个关于 domain shift 的论断有些自我矛盾
- In-domain 数据定义模糊: “in-domain” 数据直接从同一仿真平台生成 QA,这本质上是 data augmentation on the same visual domain,而非真正的”embodied reasoning 增强 VLA”。这使得核心结论(reasoning 不重要,domain 匹配重要)可能 trivially true
- VLA 架构创新有限: Action expert 设计直接沿用 π0 的 flow matching MoE 方案,VLM 侧也是标准 InternVL3 SFT,技术贡献更多在数据工程层面
- 模型规模受限: 只在 2B 和 8B 上实验,未验证更大规模模型(如 72B)是否有不同的数据效率 pattern
可信评估
Artifact 可获取性
- 代码: inference+training 均已开源
- 模型权重: Vlaser-2B、Vlaser-8B(VLM)和 Vlaser-2B-VLA 已在 HuggingFace 发布
- 训练细节: 超参 + 数据配比 + 训练步数完整(Table 6, 7)
- 数据集: Vlaser-6M 已开源于 HuggingFace(包含 Robot_QA_data、grounding_data、planning_data、spatial_data)
Claim 可验证性
- ✅ Embodied reasoning SOTA(avg 51.3@8B):12 个 benchmark 结果完整报告,与多个公开 baseline 对比
- ✅ WidowX SOTA(65.1%):SimplerEnv 为标准化仿真评估框架,结果可复现
- ✅ OOD 数据对 VLA 无显著提升:通过 Vlaser-OOD vs InternVL3-2B 直接对比,在三个平台均观察到一致趋势
- ⚠️ “Urgent to shrink domain gap”:这是基于仿真实验的归因推论,未通过 real robot 实验验证这一 domain gap 假说是否在 real-world 成立
Notes
Rating
Metrics (as of 2026-04-24): citation=10, influential=1 (10.0%), velocity=1.59/mo; HF upvotes=23; github 45⭐ / forks=0 / 90d commits=5 / pushed 37d ago
分数:2 - Frontier 理由:在 embodied reasoning 与 VLA 协同方向上,Vlaser 提供了关键的 negative result(Strengths #2:OOD reasoning 数据对 closed-loop 几乎无增益),且 Vlaser-6M + 完整模型开源(Artifact 可获取性全绿),具备作为当前 “VLM data for VLA” 方向 baseline 的潜力;但方法层面(Weaknesses #3)直接沿用 π0 flow matching + InternVL3 SFT,未形成范式突破;仅发布半年、尚无大规模后续 baseline 采纳,且未验证 sim-to-real,距离 Foundation level 还有距离,不是 1 是因为 ICLR 2026 录用 + in-domain vs OOD 的实验设计在方向内已是重要参考点。2026-04 复核:cite=10/inf=1 (10.0%)/vel=1.59/mo、HF=23、gh=45⭐——influential/total 正好处 rubric “典型 ~10%“,early signal 支撑 Frontier 档;star 数偏低但仓库近期 active(37d)+ ICLR 接收会在接下来半年继续拉 citation,维持 2 是 field-centric 稳妥判断。