Summary
Move to Understand a 3D Scene (MTU3D)
- 核心: 把”主动探索”和”3D-VL grounding”融在同一个 query-based 决策框架里——object queries 与 frontier queries 共同竞争一个 unified score,让 agent 一边构建在线 spatial memory 一边决定 grounding 还是继续探索
- 方法: 在线 query representation(DINO + FastSAM + sparse 3D U-Net → segment-pooled queries,IoU-based merge 到 global memory bank)+ 统一 grounding/exploration objective(frontier 也作为 query 参与 spatial reasoning transformer 打分)+ 三阶段 VLE 预训练(百万级仿真+真实 RGB-D 轨迹)
- 结果: HM3D-OVON / GOAT-Bench / SG3D / A-EQA 上 SR 分别 +14% / +23% / +9% / +2%;GOAT Val Unseen 47.2 SR / 27.7 SPL;同时部署到真实 Stretch 机器人 zero-shot 工作
- Sources: paper | website | github
- Rating: 2 - Frontier(BIGAI 3D embodied navigation 的最新 SOTA,frontier-as-query 抽象值得记住,但尚未成为 de facto 必读奠基)
Key Takeaways:
- Frontier-as-query 是关键 abstraction: 把”未探索区域”和”已识别物体”放进同一个 query 池,让 transformer 用同一个分数比较”过去那个椅子”和”前面那扇没看过的门”。这把 modular pipeline 里的 explore/exploit 启发式合并成一个端到端可学的决策。
- 在线 query memory 取代显式 3D 重建: 不预建 mesh / point cloud,而是通过 box-IoU 匹配把当前帧 local query 滚动 merge 到 global query bank,EMA 融合 box / feature / vocab embedding。Sim-to-real 主要靠这种紧凑表示 + 真实 ScanNet RGB-D 训练混入,而不是大量的真实策略 fine-tune。
- VLE 预训练规模 > 1M 轨迹:HM3D-OVON 290k + GOAT 680k + SG3D-Nav 2k 探索轨迹 + 多个 grounding 数据集(ScanRefer / ScanQA / Multi3DRefer / SceneVerse / Nr3D / SG3D-VG),用 random + optimal frontier 混合策略避免对 oracle 的过拟合。
- 效率与速度 tradeoff 明确:266M params,3.4 FPS(query proposal 192ms 是瓶颈),与 video VLM (Uni-NaVid) 比 SR 高但 SPL 在短轨迹场景输——因为它要先 explore 再 ground,video 模型可以一眼直冲。
Teaser. MTU3D 同一个模型用 category / image / language description / task plan / question 五种输入做导航,统一通过迭代 explore + ground 完成任务。
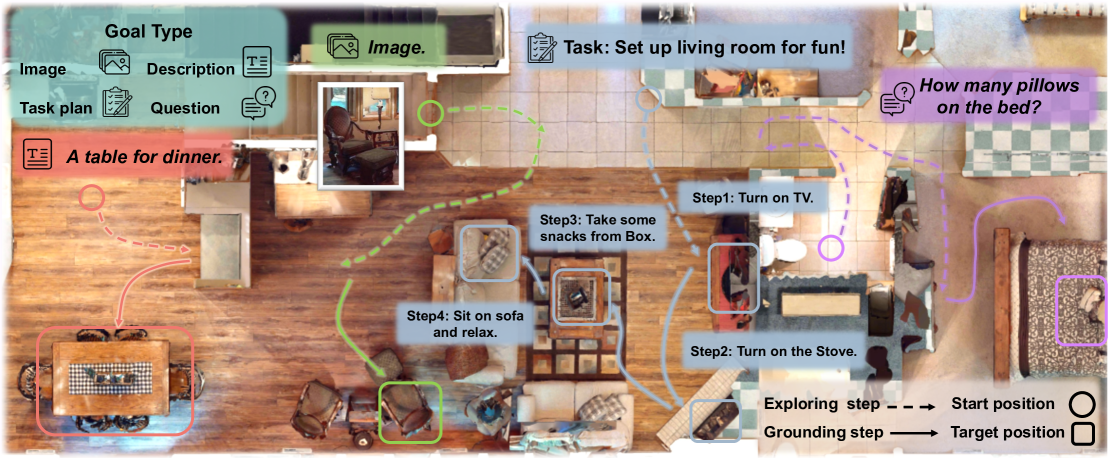
1. Motivation:3D-VL 与 RL Embodied 的鸿沟
两条主线各有短板:
- 3D-VL grounding(PQ3D, LEO, 3DVLP 等)依赖预先重建好的 mesh / point cloud,无法在 partially observable 的真实场景里工作;没有 active perception。
- RL embodied navigation(PIRLNav, VER, DAgRL)能探索但 sample inefficient、generalization 差、缺显式 spatial 表示。
作者把这件事 frame 成一个 unified problem:agent 既要维护一个会增长的 spatial memory 来支持 lifelong grounding,又要在每一步决定继续 grounding 已知物体还是去探索未知区域——而这两个动作应该用同一套表示和同一个目标函数学。
Table 1 — Paradigm 对比
| Method | Online | Exploration | Grounding | Lifelong |
|---|---|---|---|---|
| RL | ✓ | ✓ | ✗ | ✗ |
| 3D-VL | ✗ | ✗ | ✓ | ✓ |
| MTU3D | ✓ | ✓ | ✓ | ✓ |
❓ 这张表里 “RL” 把所有 RL 方法折叠成”无 grounding 无 lifelong”略过简——比如 SenseAct-NN Skill Chain 就有显式 skill。但作为 narrative framing 是 ok 的。
2. Method
Figure 3. 模型结构:RGB-D 序列 → 2D/3D encoder → segment-pooled query → 写入 spatial memory bank;spatial reasoning layer 在 object queries + frontier queries 上做 grounding/exploration 决策;选中的 query 位置交给 trajectory planner(Habitat shortest path),形成 perception-action 闭环。
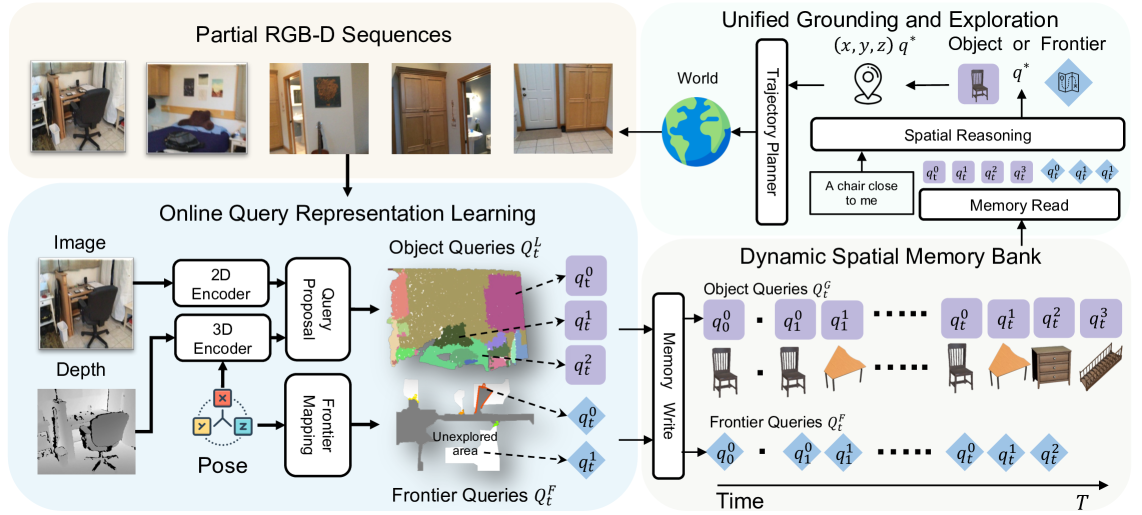
2.1 Online Query Representation Learning
输入 :RGB、depth、camera pose。
特征抽取:
- 2D 路径: FastSAM 切 segment 得到 region map ;DINO 做 pixel feature ;按 pool 到 segment-level
- 3D 路径: depth + pose 反投影到点云,sparse conv U-Net 出 ;同样按 pool 到 segment-level
- Local Query: ,再过 PQ3D-style decoder layer 得到
每个 local query 的 payload:
符号说明: 全局坐标系下的 3D bbox; segment mask; open-vocab embedding; decoder 输出 feature; confidence。
Dynamic Spatial Memory Bank:当前 与历史 通过 bbox IoU 匹配,匹配上的对 用 EMA 融合,mask 取并集;没匹配上的作为新 entry 加入。同时维护一个 occupancy map (occupied / unoccupied / unknown),从已知-未知边界提取 frontier queries ,每个 frontier 是 中的一个候选探索点。
❓ 用 box-IoU 做 query merge 是 ESAM 的做法;好处是几何稳健,缺点是同类物体近距离堆叠(货架上的杯子)会 spurious merge。论文 appendix 用 cosine 阈值 + IoU 做硬截断,没有给出此场景的失败率分析。
2.2 Unified Grounding and Exploration
把 和 拼成一个统一候选池,配合 language goal (CLIP text encoder)或 image goal(CLIP image encoder),喂入 Spatial Reasoning Transformer:
加 type embedding 区分 object 和 frontier。决策:
- → grounding(任务结束)
- → 走到那个 frontier 继续 explore
这一设计的精髓:grounding 和 exploration 不再是两套头/两个网络/两个 reward,而是同一个分类问题——所有候选放在同一 softmax 下竞争。Frontier 通过两层 MLP 编码 3D 坐标后参与 cross-attention,与已经过 decoder refine 的 object query 平起平坐。
2.3 Trajectory Data Collection
两类轨迹:
- Visual Grounding Trajectory :直接用 ScanNet RGB-D + grounding 标注(ScanRefer / ScanQA / Multi3DRefer / Nr3D / SceneVerse-HM3D / SG3D-VG)。
- Exploration Trajectory :在 HM3D 仿真里跑 Habitat-Sim 收集,用混合策略——纯 optimal frontier(最近 target 的)会 overfit,所以混入 random frontier 选择。维护 visited frontier 列表防止反复 explore;只有当存在显著更优 frontier 才继续,否则抛 exception 终止收集。
Table 2 — VLE 预训练数据规模
| Source | Scan | Sim/Real | VG | Exp | Trajectories | Decisions | Goals |
|---|---|---|---|---|---|---|---|
| ScanRefer | ScanNet | Real | ✓ | 1,202 | 37k | 37k | |
| ScanQA | ScanNet | Real | ✓ | 1,202 | 26k | 30k | |
| Multi3DRefer | ScanNet | Real | ✓ | 1,202 | 44k | 44k | |
| SG3D-VG-HM3D | HM3D | Sim | ✓ | 145 | 30k | 30k | |
| SG3D-VG-ScanNet | ScanNet | Real | ✓ | 1,202 | 13k | 13k | |
| Nr3D | ScanNet | Real | ✓ | 1,202 | 30k | 30k | |
| SceneVerse-HM3D | HM3D | Sim | ✓ | 145 | 48k | 48k | |
| HM3D-OVON | HM3D | Sim | ✓ | 290k | 1.94M | 290k | |
| GOAT-Bench | HM3D | Sim | ✓ | 680k | 14.12M | 5.10M | |
| SG3D-Nav | HM3D | Sim | ✓ | 2k | 34k | 11k |
总量 ≈ 1M+ trajectory,16M+ decision——比一般 RL navigation 训练大 1-2 个数量级,这是性能优势的物质基础。
2.4 三阶段训练
- Stage 1: Low-level Perception —— ScanNet + HM3D 上 instance segmentation 训 query proposal:,权重 。50 epoch。
- Stage 2: VLE Pre-training —— 用 stage 1 输出的 frozen queries,在 1M+ 轨迹上训 spatial reasoning transformer,BCE on 。10 epoch。
- Stage 3: Task-Specific Fine-tuning —— 在目标 benchmark 数据上继续 BCE。10 epoch。
总训练 ~164 GPU·h on 4×A100。
❓ Stage 1 query proposal 训完就 freeze,意味着 grounding/exploration 任务的梯度无法反传到 segmentation backbone。从效率角度合理,但也限制了 perception 对下游任务的 task-aware 适应。是否做过 end-to-end fine-tune 的对照?正文未给。
3. Experiments
3.1 Open-Vocabulary Navigation (HM3D-OVON)
Table 3. SR / SPL 三档 split。
| Method | Val Seen SR | SPL | Val Seen Syn SR | SPL | Val Unseen SR | SPL |
|---|---|---|---|---|---|---|
| RL | 39.2 | 18.7 | 27.8 | 11.7 | 18.6 | 7.5 |
| DAgRL | 41.3 | 21.2 | 29.4 | 14.4 | 18.3 | 7.9 |
| VLFM | 35.2 | 18.6 | 32.4 | 17.3 | 35.2 | 19.6 |
| Uni-NaVid | 41.3 | 21.1 | 43.9 | 21.8 | 39.5 | 19.8 |
| TANGO | – | – | – | – | 35.5 | 19.5 |
| DAgRL+OD | 38.5 | 21.1 | 39.0 | 21.4 | 37.1 | 19.9 |
| MTU3D | 55.0 | 23.6 | 45.0 | 14.7 | 40.8 | 12.1 |
SR 全面领先,但 SPL 在 Synonyms / Unseen 输给 Uni-NaVid / DAgRL+OD。作者承认:HM3D-OVON 轨迹短,video model 一眼看到目标可以直冲;MTU3D 必须先 explore 才能在 spatial memory 里 ground,所以路径长度被拖累。这是该 paradigm 的固有 trade-off,不是 bug。
3.2 Multi-modal Lifelong Navigation (GOAT-Bench)
Table 5. 这是 MTU3D 优势最显著的场景——lifelong 设定下需要持续 spatial memory。
| Method | Val Seen SR | SPL | Val Seen Syn SR | SPL | Val Unseen SR | SPL |
|---|---|---|---|---|---|---|
| Modular GOAT | 26.3 | 17.5 | 33.8 | 24.4 | 24.9 | 17.2 |
| Modular CoW | 14.8 | 8.7 | 18.5 | 11.5 | 16.1 | 10.4 |
| SenseAct-NN Skill Chain | 29.2 | 12.8 | 38.2 | 15.2 | 29.5 | 11.3 |
| SenseAct-NN Monolithic | 16.8 | 9.4 | 18.5 | 10.1 | 12.3 | 6.8 |
| TANGO | – | – | – | – | 32.1 | 16.5 |
| MTU3D | 52.2 | 30.5 | 48.4 | 30.3 | 47.2 | 27.7 |
Val Unseen 上 SR +17.7 / SPL +10.5 —— lifelong 长场景里 SR 和 SPL 同时大幅领先,spatial memory 的价值在这里得到最充分体现。
3.3 Sequential Task Navigation (SG3D-Nav)
Table 4.
| s-SR↑ | t-SR↑ | SPL↑ | |
|---|---|---|---|
| Embodied Video Agent | 14.7 | 3.8 | 10.2 |
| SenseAct-NN Monolithic | 12.1 | 7.7 | 10.1 |
| MTU3D | 23.8 | 8.0 | 16.5 |
t-SR(task SR,跨步骤一致性)是真正难的指标,所有方法都很低(<10%),MTU3D 仅 +0.3。这反映 sequential task 仍然是 open problem。
3.4 Active Embodied QA (A-EQA)
Table 6. 用 MTU3D 生成 exploration trajectory,喂给 GPT-4V/4o 回答。
| Method | LLM-SR↑ | LLM-SPL↑ |
|---|---|---|
| GPT-4 (blind) | 35.5 | N/A |
| GPT-4V | 41.8 | 7.5 |
| GPT-4V + MTU3D | 44.2 | 37.0 |
| GPT-4o + MTU3D | 51.1 | 42.6 |
最有意思的数字是 LLM-SPL 从 7.5 飙到 37.0——baseline 是 brute-force 看遍所有位置,MTU3D 提供短得多的目标导向轨迹。这暗示 MTU3D 可以作为 VLM-as-brain 系统的”探索模块”。
3.5 Discussions
Figure 4. 三个消融问题:
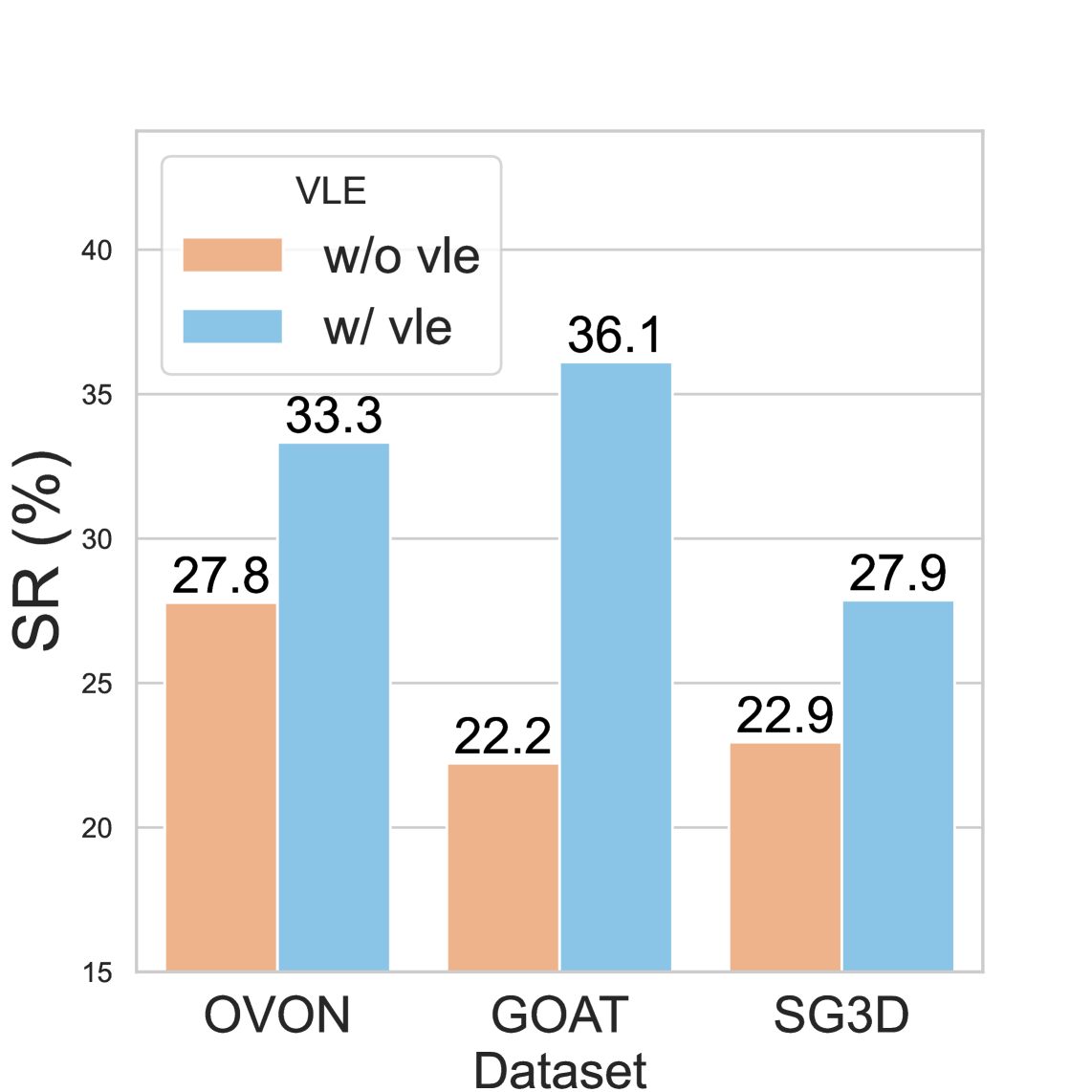
(a) VLE 预训练有效:OVON SR 27.8→33.3, GOAT 22.2→36.1(+13.9,最大),SG3D 22.9→27.9。 (b) Spatial memory 对 lifelong 决定性:GOAT-Bench 上重置 memory 后 Object goal SR 从 52.6 跌到 10.5,Description goal 71.4→28.6,Image goal 60.0→26.7。这是论文最强的因果证据之一。 (c) Grounded exploration > frontier-only exploration:第 6 步时 MTU3D SR 50.0 vs frontier 33.3,SPL 35.3 vs 30.3。语义引导 > 几何启发式。
Table 7. 实时性能
| Query Proposal | Spatial Reasoning | FPS | Params |
|---|---|---|---|
| 192 ms | 31 ms | 3.4 | 266M |
3090 Ti 上 3.4 FPS。Query proposal 是瓶颈(DINO + sparse conv U-Net),spatial reasoning 仅 31ms。
3.6 Real-World Deployment
NVIDIA Jetson Orin + Kinect RGB-D + 带 Lidar 的移动底盘,zero-shot(无 real-world fine-tune)测三个场景:home / corridor / meeting room。论文声称成功导航。
Figure 6. Real World Testing.
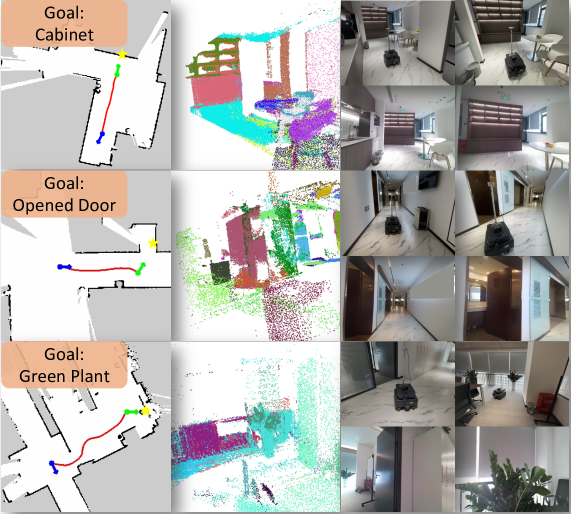
❓ 没给真实环境的成功率数字、试验次数、失败模式分析;仅作为 demonstration 展示。这是 sim-to-real 论文常见的 reporting 短板。
关联工作
基于
- PQ3D: 提供 query-based 多任务 3D 表示和 decoder layer 架构,MTU3D 的 query refinement 直接 inherit
- EmbodiedSAM (ESAM): streaming RGB-D 输入做在线 instance segmentation;MTU3D 的 query merging via box-IoU 与 EMA 融合策略来自 ESAM
- FastSAM + DINO: 2D segmentation prior + 视觉 backbone
- Mask3D / OpenScene: 3D segmentation 的 prior work(Acknowledgement 致谢)
- 3D-VisTA: 3D-VL pretraining 的方法 lineage
- LEO: 3D embodied generalist agent;同作者团队(BIGAI)的前置工作,但 LEO 依赖 reconstructed scene 而 MTU3D 是 online
对比
- VLFM: modular CLIP-on-Wheels 风格,依赖 vision-language model 作 frontier scoring;MTU3D 是 end-to-end 学的 scoring
- Uni-NaVid: video LLM-based navigator;在短轨迹 SPL 上更强但缺乏显式 spatial memory
- PIRLNav / VER / RL baselines: end-to-end RL,MTU3D 论文的主要 outperform 对象
- GOAT (modular): GOAT-Bench 的官方 modular baseline
- SenseAct-NN: 任务分解为 skill chain 的 modular 路线
方法相关
- Frontier-based exploration: 经典几何启发式,MTU3D 把 frontier 升级为可学的 query 候选
- CLIP: text/image goal 编码
- Habitat-Sim / HM3D: 仿真平台与 scene dataset
- ScanRefer / ScanQA / Multi3DRefer / Nr3D / SceneVerse / SG3D: VG 训练数据来源
- GOAT-Bench / HM3D-OVON / SG3D-Nav / A-EQA (OpenEQA): 评测 benchmark
论文点评
Strengths
- Frontier-as-query 的 abstraction 简洁有力:把 modular pipeline 里 hand-crafted 的 explore/exploit gating 替换为 transformer 上的 unified scoring,这是 first-principles 上正确的”让网络自己学决策”方向。值得在其他 active perception 任务上复用。
- 数据规模带动方法:1M+ 轨迹 + 16M+ decision 的 VLE 预训练在 3D embodied 领域是少见的规模——把”大模型预训练 + 小数据 fine-tune”的 recipe 迁移到 navigation 是核心贡献的工程层面。
- Spatial memory 的因果证据扎实:Fig 4(b) 的 reset-memory 消融在 GOAT-Bench 上 SR 跌一半以上,是干净的”一个 component 拿掉,性能直接变烂”对照——比很多 incremental ablation 有说服力。
- 多 modality 输入统一:CLIP text + image encoder 让同一模型支持 category / language description / image / task plan / question 五类 goal——versatility 是 GOAT-Bench 设计的核心需求,MTU3D 是少数能 single-model handle 全部 modality 的工作。
- Sim-to-real 自然过渡:因为表示是 query+memory 而不是 dense feature map,加上 ScanNet 真实数据混入预训练,zero-shot 部署到 Stretch 机器人不需要专门 fine-tune。
Weaknesses
- SPL 在短轨迹场景输给 video VLM:HM3D-OVON Val Unseen SPL 12.1 vs Uni-NaVid 19.8——MTU3D 的 explore-then-ground 范式天然走更长的路。在轨迹短或目标显眼的场景里,端到端 video model 反而更有效率。这是 paradigm-level limitation,论文没有提出缓解方案。
- SG3D t-SR 只有 8.0%:sequential task 是真正考验 long-horizon planning 的设定,所有方法都很低,MTU3D 只比 baseline 高 0.3 个点,spatial memory 在跨任务步骤连续性上没有展现优势——可能是 memory 的容量/长度,也可能是 spatial reasoning transformer 缺少 task-level reasoning。
- Stage 1 query proposal 被 freeze:perception 不会针对下游 grounding/exploration 任务调整。论文未给 end-to-end fine-tune 的对照实验,无法判断 freeze 损失多少性能。
- Frontier 的几何探测过于朴素:从 occupancy map 边界 traverse 出 frontier,没有任何”哪个 frontier 看起来更有信息量”的先验;全靠 spatial reasoning transformer 事后打分。如果 frontier proposal 本身能注入 semantic prior(例如”门内的 frontier 优于墙边的”),效率可能更高。
- Real-world 评测只有 demonstration:3 个场景、无成功率、无 trial 数、无失败分析。zero-shot transfer 的 claim 强度不够。
- 训练成本对再验证不友好:1M+ 轨迹的 VLE 预训练即便只有 164 GPU·h(4×A100 ~ 41h),数据准备和 collection pipeline 复杂度高,独立复现门槛偏高。
可信评估
Artifact 可获取性
- 代码: inference + training(Stage 1/2/3 全部 config),data collection 脚本 2025.08 release —— GitHub
MTU3D/MTU3D完整 - 模型权重:
huggingface.co/bigai/MTU3D提供 stage1 / stage2 checkpoint - 训练细节: 完整 —— optimizer (AdamW lr=1e-4, β1=0.9, β2=0.98)、loss weights、4 stage epoch、4×A100 配置都在正文
- 数据集: 开源 —— stage1 data / stage1 features / vle_stage2 / embodied-bench 全部在
huggingface.co/datasets/bigai/MTU3D;底层 ScanNet / HM3D / GOAT-Bench / SG3D / OVON 都是公开 benchmark
Claim 可验证性
- ✅ HM3D-OVON Val Unseen SR 40.8 / GOAT-Bench Val Unseen SR 47.2 / SG3D s-SR 23.8:表 3-5 完整数据 + checkpoint 公开 + benchmark 公开 → 可独立复现
- ✅ Spatial memory 对 lifelong navigation 的因果作用:Fig 4(b) reset-memory 消融实验设计干净,3 类 goal 一致性强
- ✅ VLE 预训练带来普适提升:Fig 4(a) 三个 benchmark 一致性提升
- ⚠️ “outperforms RL/modular by 14%/23%/9%/2% in SR”:与 abstract 数字一致,但论文中也出现 “13.7%/23.0%/9.1%” 和 GitHub README 的 “14%/27%/11%/3%” 三套互不一致的版本 —— 哪个是权威值不清楚;建议直接看 Tab 3-6 的具体数。
- ⚠️ A-EQA 上 LLM-SPL 7.5→37.0 的 5x 提升:metric 是 score / exploration length,MTU3D 的轨迹本来就更短,分母小自然分大;这个 +29.5 的 gap 一部分来自轨迹长度归一而非 QA 质量本身——论文措辞稍有营销感
- ⚠️ Real-world zero-shot 部署成功:仅定性 demonstration,无量化指标
- ❌ 无明显纯营销 claim
Notes
- 核心 idea 的可迁移性:frontier-as-query 这个 abstraction 不只适用于 navigation——任何 active perception / partial observation 任务(active 3D scanning、search-and-rescue、infovis)都可以套用”已知候选 + 待探索候选 → unified scoring”的范式。值得作为一个 building block 记住。
- 与 video VLM 的范式对比:Uni-NaVid 走的是”video tokens 进 LLM 出 action”,MTU3D 走的是”显式 query memory + 决策头”。前者 SPL 更高(短任务一眼到底),后者 SR 和 lifelong 能力更强。这暗示显式 spatial memory 在长任务上有结构性优势——video LLM 没有 explicit object identity persistence,依赖隐式 attention,长 horizon 上自然劣化。
- Ablation 启发:Fig 4(b) 的 memory-reset 消融是一个非常干净的”必要性证明”模板——
with-X和without-X在多个 sub-condition 上一致拉开差距,是比 +0.3% 数字强得多的 evidence。值得在自己的 ablation 设计上参考。 - 数据规模是真护城河:1M trajectory + 16M decision 不是个人能轻易复现的——这种 scale 决定了短期内难有学术 group 能从头训出 competitive baseline,会强化 BIGAI 在 3D embodied 方向的优势。复现工作更可能是 fine-tune their checkpoint 而非 from scratch。
- 真实部署的 sim-to-real:靠 spatial query 的紧凑表示 + ScanNet 真实数据混入解决,而不是 randomization 或 adapter——这条路径对 manipulation 的 VLA 也有启发:显式中间表示 + 多源真实数据预训练可能比 dense pixel 表示更容易 sim-to-real。
Rating
Metrics (as of 2026-04-24): citation=46, influential=8 (17.4%), velocity=4.79/mo; HF upvotes=0; github 252⭐ / forks=13 / 90d commits=0 / pushed 261d ago · stale
分数:2 - Frontier 理由:ICCV 2025 中稿,是 BIGAI 在 3D embodied navigation 方向当前最新 SOTA——在 GOAT-Bench Val Unseen 上 SR/SPL 同时对 modular / RL baselines 大幅领先(+17.7 SR / +10.5 SPL),且方法论有清晰 abstraction(frontier-as-query)和扎实的因果证据(Fig 4(b) memory reset 消融)。之所以不是 3 - Foundation:frontier-as-query 虽然 elegant 但尚未被后续工作广泛采纳为 de facto 范式,HM3D-OVON SPL 输给 Uni-NaVid 也表明该 paradigm 并非全面压制;之所以不是 1 - Archived:1M+ 轨迹 VLE 预训练 + 开源 checkpoint/data 构成了 3D embodied navigation 当下 must-compare baseline,短期内仍是 frontier 参考。