Summary
TongUI: Internet-Scale Trajectories from Multimodal Web Tutorials for Generalized GUI Agents
- 核心: 把 YouTube/Bilibili/WikiHow/百度经验上现成的 GUI 教程(视频+图文)通过 ASR + key-frame 提取 + zero-shot agent 标注 转成 1M GUI 操作 trajectory,构造 GUI-Net-1M 数据集。
- 方法: 四步 pipeline——tutorial crawling → tutorial processing(Whisper ASR / 文章解析 + LLM 抽取任务、MOG2 提关键帧 + GPT-4o-mini 过滤非 screenshot)→ trajectory generation(用 UI-TARS 把 (image, rough description) 翻译成 thought+action)→ 多阶段过滤;在 Qwen2.5-VL-3B/7B/32B 上 SFT。
- 结果: TongUI-32B 在 ScreenSpot-V2 92.1,ScreenSpot-Pro 33.1;TongUI-7B 在 MiniWob/AndroidControl 等多 benchmark 比 ShowUI/OS-Atlas 高 5-20%,与 UI-TARS-7B 接近但完全开源数据。
- Sources: paper | website | github
- Rating: 1 - Archived(2026-04 复核降档:12.2mo 后 citation 仅 25、influential=1(4%,远低于典型 10%)、velocity 2.05/mo、github 仅 94⭐,GUI-Net-1M 未被主流 GUI agent 工作采纳为数据基座)
Key Takeaways:
- Web tutorial 是被低估的 GUI trajectory 来源:相比人工标注(贵)和 simulator 合成(diversity 差、有 sim-to-real gap),现成的 WikiHow / YouTube 教程同时提供任务 query、step-by-step 描述和真实截图,三要素齐全。
- Zero-shot agent 当 thought/action labeler:不直接拿教程的自然语言当监督,而是用 UI-TARS 在 (screenshot, rough_description) 对上 inference 出 ReAct 格式的 thought + 标准 action,把异构教程统一到固定 action space。
- Data scaling 在多源叠加上单调:Refined→+WikiHow→+Baidu→+Video→+All 在 ScreenSpot 从 68.0 涨到 83.6,每加一类源都涨,说明源多样性比单源量更重要。
- 泛化主要靠 OS/应用覆盖:5 OS + 280 应用的横扫让 TongUI 在 cross-domain(Mind2Web Cross-Domain、UI-Vision Spatial)上甚至超越规模更大的 UI-TARS,但在 in-distribution、高分辨率专业软件(ScreenSpot-Pro CAD)上仍输 UI-TARS-7B。
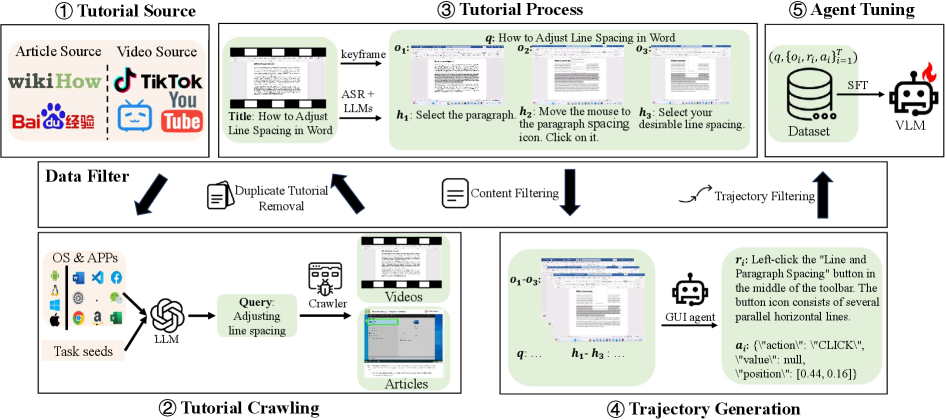
Teaser. TongUI 框架总览。 把 Internet 上的多模态 GUI 教程经四步流水线转成 trajectory 数据,覆盖 5 个操作系统、280+ 应用。
Motivation
GUI agent 的瓶颈不是模型,是数据。两条主流路线各有问题:
- 人工标注(如 UI-TARS、VisualAgentBench):质量高但贵;并且 UI-TARS 本身没开数据,社区无法复用。
- Synthetic / simulator(合成 trajectory):可以 scale 但缺乏真实场景的 diversity,常常 exploit simulator 的 bias。
作者的 key insight:Internet 上已经有人为人写好的”教程”——WikiHow 的图文步骤、YouTube 的录屏配旁白——这些天然是 (task, screenshot, step description) 三元组,只缺一个把它们变成 (thought, action) 的转换器。把现成内容利用起来,既便宜又自带分布多样性。
❓ 这个观察其实 AgentTrek 和 Synatra 已经做过(TongUI 自己也承认)。差异是 TongUI 强调”多模态”——直接用图像而不是把 HTML 当 ground truth,因此能覆盖 desktop/mobile 而非只有 web。这个差异是否 essential 取决于 desktop/mobile 的提升能否归因到模态本身而非数据量。论文没拆这个 ablation。
Method
Formulation
GUI 任务建模为 ReAct 范式的序列决策。给定历史观察 、历史 thought/action 和 query ,VLM 输出新的 thought 和 action :
训练数据格式为 ,目标是 SFT 损失:
Pipeline 四步
Step 1: Tutorial Crawling. Seed task 由人写,再用 LLM 扩展成 “app/web + task” 形式的 keyword(如 “Word + change font size”),分别在 YouTube(Google API)、Bilibili/TikTok(unofficial API)、WikiHow、Baidu Experience(按 tag 爬)抓取。
Step 2: Tutorial Processing.
- Textual: 视频用 Whisper 做 ASR 拿 transcript;图文文章按 DOM 结构解析。LLM 抽出 task 和 步 rough descriptions ;同时分类为 mobile/desktop/others,丢弃 others。
- Visual: 文章直接拿图序列;视频先按 ASR 时间戳切段,每段用 MOG2 背景减除算法找显著变化帧作为 keyframe。然后 GPT-4o-mini 二分类过滤掉非 screenshot 的帧(图解、漫画等)。
Step 3: Trajectory Generation. 这一步是关键——把 翻译成 。用 zero-shot UI-TARS 当 labeler:把 (不是 )作为 query 喂给 agent,因为 是抽象目标而 是当前步具体描述,empirically 效果更好。生成失败的步骤被丢弃,并把 trajectory 在该处切断成两段。
❓ 用 UI-TARS 当 labeler 意味着 GUI-Net-1M 的 thought/action 质量上限被 UI-TARS 卡死。在 UI-TARS 表现差的 OS(如 CAD 软件、iOS)上,标签噪声会很大。这能解释为什么 TongUI 在 ScreenSpot-Pro CAD 上明显落后 UI-TARS-7B。
Step 4: Data Filtering. 三阶段:(1) 按 video ID/URL 去重;(2) LLM 基于内容判断是否 GUI 相关;(3) 把 (screenshot, trajectory) 喂 Qwen2.5-VL-7B 打质量分;UI-TARS 输出 wait / call_user 的步骤直接当低质信号丢掉。最终保留 33% 原始数据。
Action Space
Table 8. 动作空间。 Desktop 9 个动作(Click, Input, Scroll, LeftClickDouble, RightClickSingle, Drag, HotKey, Hover, Finish),Mobile 7 个(Tap, Input, Swipe, LongPress, PressHome, PressBack, Finish)。这套空间和 UI-TARS 兼容——这是 labeling 用 UI-TARS 的必然约束。
Tuning
base = Qwen2.5-VL-3B/7B/32B;context window 8192;max prev observations = 2;每图限 1350 vision tokens;LoRA rank 16, alpha 32(仅 0.5% 参数);lr 1e-4,AdamW;batch 4 × grad accum 8;3B 在 8×A100-80G 跑 ~4 天,7B ~7 天。
❓ 只 LoRA 0.5% 参数就拿到 SOTA-comparable,这暗示要么数据质量是 dominant factor、要么基模 Qwen2.5-VL 本身的 GUI grounding 已经接近 ceiling。如果是后者,“GUI-Net-1M 让 agent 更通用”的 claim 应该被打个折——可能更多是”激活”而非”教会”。
Dataset Statistics
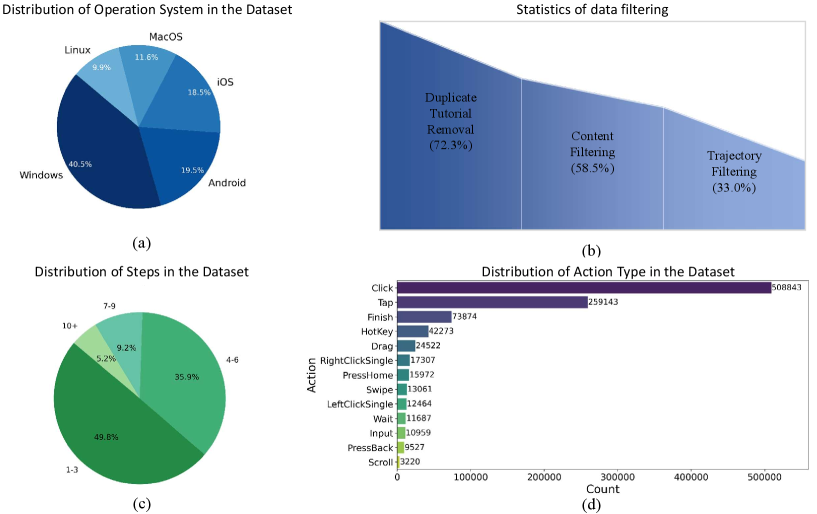
GUI-Net-1M 关键统计:5 OS(Windows / Android / iOS / MacOS / Linux)、280+ 应用、1M trajectories;步长分布以 1-3 步为主(部分因为切段策略);动作分布以 Click / Tap 为主导。
Table 1. GUI-Net-1M 与已有数据集对比。
| Datasets | Size | Platform | OS |
|---|---|---|---|
| GUI Odyssey | 7K | W+M | A |
| AgentTrek | 10.4K | W | A+W+L+M+I |
| AndroidControl | 15.3K | W+M | A |
| AGUVIS | 35K | W+M | A+W+L |
| LBI | 42.6K | D+W | L |
| E-ANT | 49K | M | A |
| ShowUI | 137K | W+M | W+L+I |
| AITW | 715K | W+M | A |
| GUI-Net-1M | 1M | D+W+M | A+W+L+M+I |
(D=Desktop, W=Web, M=Mobile; A=Android, W=Windows, L=Linux, M=MacOS, I=iOS)
GUI-Net-1M 是已知最大的开源 GUI trajectory 数据集,且唯一同时覆盖三类 platform 和五种 OS 的。规模上是 ShowUI 数据 7×、AITW 1.4×。
Figure 2. GUI-Net-1M 数据统计。 OS 分布、过滤前后数据量、步长分布、动作分布。
Experiments
Setting
- Base: Qwen2.5-VL-3B/7B/32B
- Offline benchmarks: ScreenSpot, ScreenSpot-V2, ScreenSpot-Pro, AITW, AndroidControl, Mind2Web, UI-Vision
- Online benchmark: MiniWob(按 SeeClick 设置)
Grounding (ScreenSpot 系列)
Table 2. Grounding 结果。 TongUI-32B 在 ScreenSpot-V2 上 92.1 (best),在 ScreenSpot 88.5(仅次于 UI-TARS-7B 89.5),ScreenSpot-Pro 33.1(落后 UI-TARS-7B 35.7、UI-TARS-72B 38.1)。
| Model | ScreenSpot Avg | ScreenSpot-V2 Avg | ScreenSpot-Pro Avg |
|---|---|---|---|
| Qwen2.5-VL-7B† | 78.6 | 84.0 | 12.5 |
| ShowUI-2B | 75.1 | – | 7.7 |
| OS-Atlas-7B | 85.1 | 84.1 | 18.9 |
| UI-TARS-7B | 89.5 | 91.6 | 35.7 |
| UI-TARS-72B | 88.4 | 90.3 | 38.1 |
| TongUI-3B | 83.6 | 85.5 | 18.0 |
| TongUI-7B | 86.0 | 88.7 | 24.7 |
| TongUI-32B | 88.5 | 92.1 | 33.1 |
观察:
- 比 base Qwen2.5-VL 提升 ~10-25 个点,说明 GUI-Net-1M 数据对 grounding 显著有效。
- 32B 在 ScreenSpot-V2 反超 UI-TARS-72B,但 ScreenSpot-Pro(专业 CAD/Office 软件)仍输——因为教程数据多是大众软件,专业垂直应用覆盖差。
Offline Navigation
Table 6. Mind2Web 结果(Step SR)。
| Method | Cross-Task | Cross-Website | Cross-Domain |
|---|---|---|---|
| ShowUI-2B | 37.2 | 35.1 | 35.2 |
| AgentTrek | 40.9 | 35.1 | 42.1 |
| UI-TARS-7B | 67.1 | 61.7 | 60.5 |
| TongUI-3B | 48.8 | 48.1 | 49.5 |
| TongUI-7B | 53.4 | 49.0 | 52.9 |
| TongUI-32B | 52.4 | 50.6 | 54.1 |
❓ 32B 在 Cross-Task 上反而比 7B 差(52.4 vs 53.4),AITW Average 上 32B (71.0) 也输 7B (73.3)。作者没解释。可能是 large model 在 GUI-Net-1M 这种带 labeler 噪声的数据上更容易过拟合标签噪声而不是学习真实分布。
AndroidControl TongUI-7B 76.0/91.9 (High/Low),超过 UI-TARS-7B (72.5/90.8),说明在 Android 单 OS 也有提升空间。
UI-Vision (Spatial) TongUI-32B 11.3,超过 UI-TARS-7B (8.4);这个更难的空间推理 benchmark 上 TongUI 优势明显。
Online Navigation (MiniWob)
Table 7. MiniWob. TongUI-3B/7B/32B 分别 72.7/73.9/74.3,均超过 ShowUI-2B (71.5)、SeeClick-9.6B (67.0)。Online 设置(动态环境)的提升也是单调 monotonic 的,说明从离线教程学到的策略能 transfer 到 online。
Data Scaling
Table 12. 数据源叠加 ablation。 关键的 ablation——回答 “多源是否真的有用”:
| Data | ScreenSpot | M2W Task | M2W Website | M2W Domain |
|---|---|---|---|---|
| No SFT | 56.5 | 0.4 | 1.0 | 1.7 |
| Refined data | 68.0 | 39.7 | 35.5 | 40.7 |
| + WikiHow 50K | 75.8 | 42.1 | 39.6 | 44.4 |
| + Baidu 50K | 78.7 | 43.4 | 41.6 | 45.5 |
| + Video 50K | 79.6 | 44.2 | 42.6 | 46.0 |
| + All data | 83.6 | 48.8 | 48.1 | 49.5 |
每加一个源都涨——这是支持”多源教程 diversity 重要”主张的 strongest evidence。但单源 50K 的边际增益递减明显(WikiHow +7.8 → Baidu +2.9 → Video +0.9 ScreenSpot),说明源之间存在 redundancy;最后 “All data”(不止 50K)的大跳暗示量也很重要。
Data Quality User Study
5 个独立 GUI agent researcher 打分(0-5):
- Trajectory Filtering 前 3.22 → 后 4.12(filtering 有效)
- ShowUI 数据基线 4.26(GUI-Net-1M 与之 comparable)
Figure 3. User study 平均分。
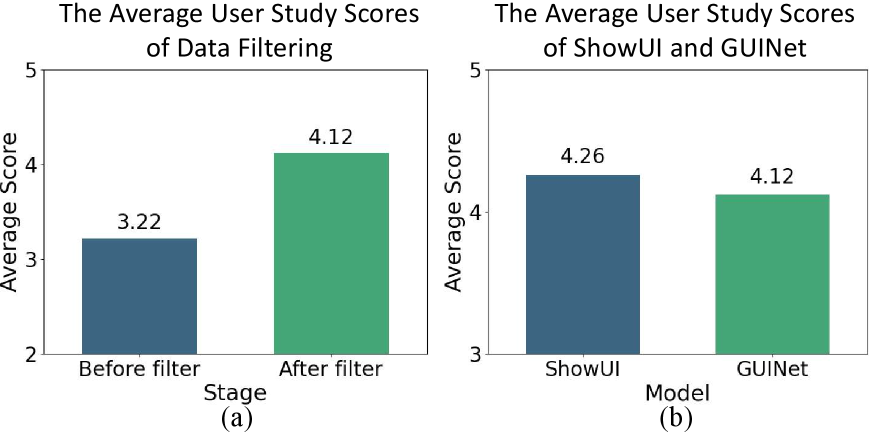
❓ 4.12 vs 4.26 说明 GUI-Net-1M 单点质量略低于人工/脚本生成的 ShowUI——但论文用 “comparable” 一笔带过。考虑到用 LLM-based labeler 自动化生成 1M 数据,这个差距其实可以接受;但 marketing-wise 措辞偏向于隐藏差距。
关联工作
基于
- Qwen2.5-VL: base VLM (3B/7B/32B)
- UI-TARS: 用作 zero-shot trajectory labeler;其 action space 也被 TongUI 沿用
- Whisper: video 转 transcript
- ReAct: thought-action 交错的决策框架
对比
- AgentTrek: 同样从 web tutorial 收集 trajectory,但只用文本教程 + simulator 验证;TongUI 的差异是直接处理多模态教程,不需 simulator
- ShowUI: 137K 数据,是 TongUI 比较的主要 small-scale baseline;TongUI 的 user study 用 ShowUI 作数据质量参照
- UI-TARS: 同代 SOTA 但闭源数据;TongUI 性能 comparable 但数据完全开源
- OS-Atlas: GUI grounding baseline
- SeeClick: 早期 GUI agent,MiniWob 实验设置参考它
方法相关
- ASR (Whisper): 视频转录
- MOG2 背景减除算法: video keyframe 提取
- LoRA: 高效 fine-tuning(rank 16, alpha 32, 仅 0.5% 参数)
评测
- ScreenSpot / ScreenSpot-V2: GUI grounding
- ScreenSpot-Pro: 高分辨率专业软件 grounding
- AITW, AndroidControl: Android navigation
- Mind2Web: web navigation
- UI-Vision: 空间推理 GUI
- MiniWob: online web navigation
论文点评
Strengths
- 数据工程做得彻底:四源(YouTube/Bilibili/WikiHow/百度经验)+ 三阶段过滤 + LLM-as-labeler,每一步都 reasonable,没有 hand-wave。
- 完全开源:与 UI-TARS 形成对照——UI-TARS 只放模型不放数据;TongUI 把 1M 数据、模型、训练管线全部 release,社区可直接复用。这是真正的 community contribution。
- 多源 ablation 证据扎实:Table 12 的 incremental scaling 是支撑”diversity 重要”主张的关键证据,且符合直觉。
- OS / Platform 覆盖最广:5 OS × 3 platform 是目前开源数据集里唯一全覆盖的。
Weaknesses
- 方法 novelty 有限:核心思路(爬 web 教程转 trajectory)AgentTrek、Synatra 已做过;TongUI 的差异是”多模态 + 用 UI-TARS 当 labeler”,但这是工程改进而非概念突破。
- Labeler 是 ceiling:用 UI-TARS 标注,TongUI 的 thought/action 质量 fundamentally 受 UI-TARS 限制;ScreenSpot-Pro 上输 UI-TARS-7B 大概率源自这点——学生不会超过老师。这种 distillation 范式的根本约束没被讨论。
- 32B 反常表现没解释:AITW、Mind2Web Cross-Task 上 32B 比 7B 差,可能是过拟合数据噪声,但论文回避了这个 negative result。
- 缺同等规模对照实验:如果换用同等规模(1M)的合成 trajectory 或人工 trajectory 训 Qwen2.5-VL,性能差距是多少?没有这个对照,“web tutorial 性价比高”的 claim 缺关键 baseline。
- 数据质量略低于 ShowUI:4.12 vs 4.26 user study;论文用 “comparable” 软化,但其实是承认了 LLM-labeling 引入的噪声。
- 缺连续学习 / 时间漂移分析:声称”含不同时期教程帮助适应 evolving GUI”,但没量化——比如旧 Windows XP 教程是否反而 hurt 新 Windows 11 任务?
可信评估
Artifact 可获取性
- 代码: inference + training(GitHub README 显示 release 了完整训练 pipeline)
- 模型权重: TongUI-7B / TongUI-32B 已发布在 HuggingFace(Bofeee5675 collection)
- 训练细节: 仅高层描述(lr、batch、LoRA rank 给了;数据配比、各源具体数量、训练步数、loss 曲线均未披露)
- 数据集: 开源(GUI-Net-1M @ huggingface.co/datasets/Bofeee5675/GUI-Net-1M)
Claim 可验证性
- ✅ GUI-Net-1M 是最大开源 GUI trajectory 数据集:Table 1 横向对比清晰,且数据集已实际公开可下载验证
- ✅ 多源叠加单调提升:Table 12 数据 ablation 明确,可在公开数据上复现
- ✅ TongUI 在多 benchmark 超过 ShowUI / Qwen2.5-VL baseline:表格数字详尽,模型已发布可独立 benchmark
- ⚠️ “outperforming baseline agents by 10% on multiple benchmarks”(abstract):选择性描述——成立但仅对特定 baseline(ShowUI、Qwen2.5-VL base);与同代 SOTA UI-TARS 比是输的(特别是 ScreenSpot-Pro),abstract 没明确这点
- ⚠️ “含不同时期教程帮助 generalize 到 evolving GUI”:论文反复 claim 但无任何针对性实验(如分时间段评测)
- ⚠️ User study n=5 数据质量评估:样本太小,且每人打 200 个数据点的疲劳偏差 / participant 间一致性 (IAA) 未报告
- ⚠️ “GUI-Net-1M data quality comparable to ShowUI”:4.12 vs 4.26 严格说不是 comparable(差距约 3.3%);措辞偏向 marketing
Notes
- Pivot 启发:TongUI 的 “用 SOTA agent 当 labeler 把无标注 web 内容变成训练数据” 是个通用 recipe,可推广到 robotics(用 SOTA VLA 给 YouTube 操作视频打 action 标签)、visual reasoning(用 SOTA VLM 给图书章节配 reasoning trace)等。但要警惕 labeler ceiling 问题——学生天花板被老师卡死。
- 对 ClawGUI / 我自己工作的启示:如果想做 generalist GUI agent,GUI-Net-1M 已经把”广度”这条路走通了;下一步差异化方向是 (a) “深度”——单 OS / 单领域专精;(b) “online”——RL on dynamic environment(TongUI 全是 SFT);(c) 突破 labeler ceiling 的方法——self-improvement / RLVR。
- 数据集本身比方法更有价值:rating 选 2 而非 3,因为方法论(爬+标)已被 AgentTrek 提出过;但数据集是 building block 级别,未来如果做 GUI agent 实验,GUI-Net-1M 是必备 ingredient。
- ❓ 待跟进:GUI-Net-1M 在 mobile vs desktop 的细分性能?论文没拆。如果 mobile 远不如 desktop(直觉上 mobile 教程更碎片化),可能要做按 platform 分桶的训练。
Rating
Metrics (as of 2026-04-24): citation=25, influential=1 (4.0%), velocity=2.05/mo; HF upvotes=1; github 94⭐ / forks=8 / 90d commits=0 / pushed 144d ago
分数:1 - Archived 理由:初评 2 - Frontier 基于 “GUI-Net-1M 是目前最大的开源 GUI trajectory 数据集,数据/模型/管线全开源” 与 AAAI 2026 的录用。2026-04 复核降档:12.2 个月后 citation=25 / velocity=2.05/mo、influential 1/25 = 4.0%(远低于典型 ~10%,按 rubric 属”被当 landmark reference 提及但继承性弱”)、github 仅 94⭐ / 90d 0 commits / pushed 144d,“最大开源 GUI trajectory 数据集” 的 claim 并未转化为社区采纳——同期 GUI agent 主力工作(UI-TARS / Qwen2.5-VL-GUI / OS-Atlas 后续)仍各自用自采或合成数据而非 GUI-Net-1M,labeler ceiling 问题(学生性能被 UI-TARS 卡死)进一步限制其作为数据基座的吸引力。方法论层面 AgentTrek / Synatra 已先行,独立 insight 不足以支撑 Frontier 档,降 1。