Summary
RoboMamba: Efficient Vision-Language-Action Model for Robotic Reasoning and Manipulation
- 核心: 把 Mamba SSM LLM 当作 VLA 的骨干(替代 attention-based LLM),换取 linear 复杂度与更快推理,并声称配合一个只占 0.1% 参数的 MLP policy head 就能学到 SE(3) pose 预测
- 方法: CLIP ViT + MLP projector + Mamba-2.7B,两阶段训练:Stage 1(alignment 预训练 + 与 RoboVQA 的指令 co-training)建立通用与机器人 reasoning;Stage 2 冻结骨干,只微调 3.7M 的 position/direction MLP 头
- 结果: 在 SAPIEN PartNet-Mobility 20 类 articulated object 上的 open-loop 成功率 seen 0.63 / unseen 0.53(超过 ManipLLM),RoboVQA BLEU-4 42.8;推理号称比 LLaMA-AdapterV2 / ManipLLM 快 7×,端到端比 VLA baseline 快 3×
- Sources: paper | website | github
- Rating: 1 - Archived (方法上是”把 VLA 里的 Transformer 换成 Mamba”的一次探索;发表近 2 年只 100 citation / 2 influential citations,repo stale,主流 VLA 路线没跟进 SSM)
Key Takeaways:
- SSM 做 VLA 骨干的可行性验证:证明 Mamba-2.7B + CLIP 在通用 MLLM benchmark(POPE 86.3、GQA 64.2、VQAv2 79.6)上可达 TinyLLaVA / LLaVA-Phi 同档水平,同时保持 linear 复杂度;是”SSM 替换 Transformer”这条死胡同里少数跑到机器人下游的工作。
- “强 reasoning + 轻 policy head” 的解耦假设:作者主张一旦 MLLM 具备足够的 robotic-related reasoning,只加一个 3.7M 的 MLP head(position L1 + direction geodesic loss)、冻结骨干,就能拿到 SOTA 的 open-loop 成功率。这个假设在他们的 SAPIEN setup 上成立,但评测只到 single-step 的接触点+姿态,不是 closed-loop trajectory。
- Co-training 缓解 robotic hallucination:Stage 1.2 把 RoboVQA 300K 与 LLaVA 655K 混训,既提升 RoboVQA BLEU(42.8 vs TinyLLaVA 的 29.6),也反向改善通用 reasoning(GQA 提升);作者把这归因为”机器人数据里嵌入的复杂 reasoning 任务”,但没做对照实验隔离到底是数据规模还是数据质量在起作用。
- 推理速度优势主要来自 2.7B 体量 + linear scan:3× / 7× 的提速和 Mamba 架构本身耦合,但和”同等 2.7B 的 Transformer LLM”的头对头比较缺席(作者只对比了 7B 的 LLaMA-AdapterV2 / ManipLLM),因此”Mamba 相对 Transformer 的胜出”其实是体量差与架构差的混淆。
Teaser. RoboMamba 总览:Mamba LLM 做骨干,policy head 仅 3.7M 参数,推理频率超过其他 VLA baseline。
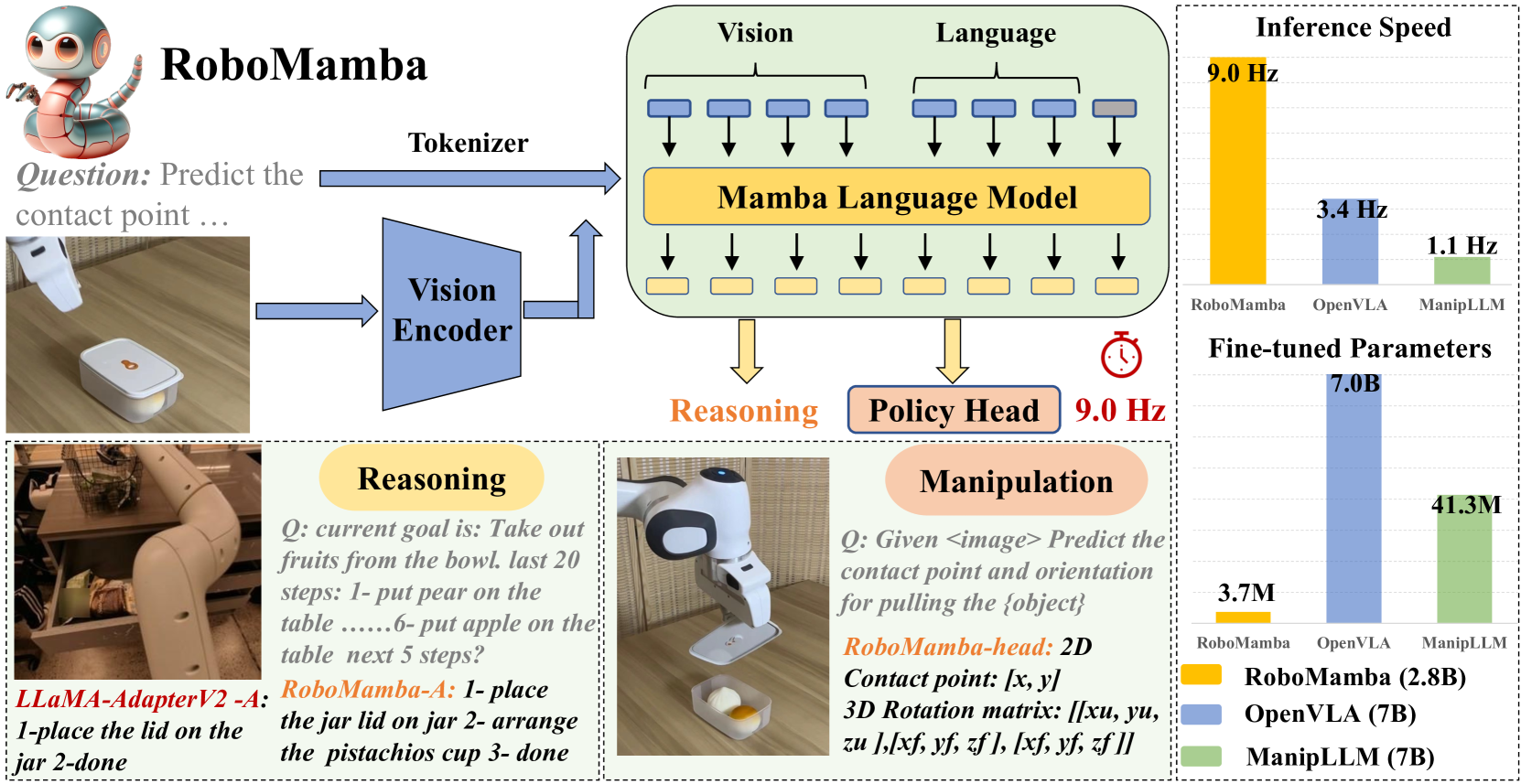
Motivation 与问题设定
作者对 MLLM-based VLA 的两个痛点定位是:
- Reasoning 能力不足:现有 MLLM(LLaMA-AdapterV2、LLaVA)在机器人场景里对 affordance、长程规划、过去/未来预测的 reasoning 深度不够,微调后也只会”formulaic”地输出 “step 1: find the handle”——即便对象没有 handle。
- 计算代价高:Transformer 二次复杂度让 7B/13B VLA 的 fine-tuning 和推理昂贵,限制了在机器人上的实时性。
由此提出的问题:能否用 linear-complexity 的 SSM(Mamba)当 LLM 骨干,同时 (i) 保留 reasoning 能力、(ii) 以极低成本注入 SE(3) pose prediction?
❓ “formulaic hallucination” 的观察(microwave 无 handle)更多是 training-data coverage 问题,不是 LLM 架构问题——用 Mamba 换 Transformer 是否真能治这个症状?论文没有隔离这个假设。
架构
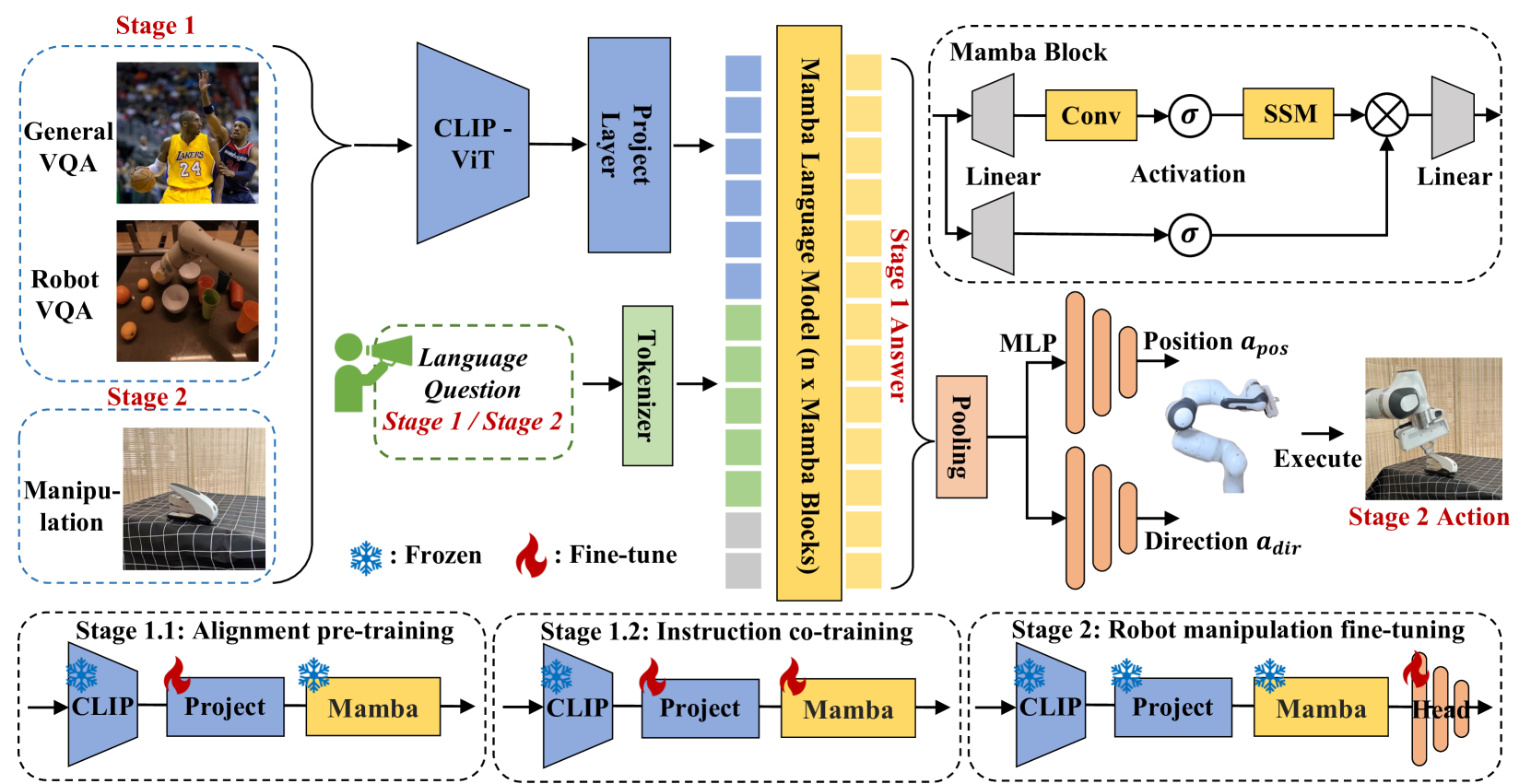 Figure 2. RoboMamba 总体框架:CLIP ViT-L 提取视觉特征 ,经 MLP projector 投影到 Mamba 的 token embedding 空间 ,与文本 token 拼接后输入 Mamba-2.7B。输出语言 token 用于 reasoning,pooled global token 送入两个 MLP policy head 分别预测 position / direction。
Figure 2. RoboMamba 总体框架:CLIP ViT-L 提取视觉特征 ,经 MLP projector 投影到 Mamba 的 token embedding 空间 ,与文本 token 拼接后输入 Mamba-2.7B。输出语言 token 用于 reasoning,pooled global token 送入两个 MLP policy head 分别预测 position / direction。
设计选择:
- 不用 vision encoder ensemble(不同于 SPHINX、Cobra 的 DINOv2 + CLIP-ConvNeXt + ViT 组合):作者论证 ensemble 的计算代价伤害机器人实用性,单纯 CLIP ViT-L + 好数据 + 好策略也够用。
- LLM 选 Mamba:通过 Selective Scan(S6)让 都成为输入的函数,带 content-aware reasoning 能力,inference 是 而非 。
SSM 的核心方程(Mamba 的离散化形式):
符号说明: 状态矩阵, 时间尺度;在 Mamba 里 都随输入变化,形成 selective 机制。
含义:以零阶保持法把连续 SSM 离散成 RNN-like 的循环式,训练时可用并行扫描高效实现。
训练 pipeline
Stage 1.1 — Alignment pre-training:freeze CLIP + Mamba,只训 MLP projector。用 LLaVA-LCS 558K 图文对,1 epoch。
Stage 1.2 — Instruction co-training:freeze CLIP,训 projector + Mamba。数据:LLaVA 1.5 mixed 655K(通用)+ RoboVQA 300K 采样(机器人指令,含 long-horizon planning、success classification、discriminative/generative affordance、past description、future prediction)。2 epoch,AdamW lr=4e-5,fp16。
Stage 2 — Robot manipulation fine-tuning:冻结所有 RoboMamba 参数,只训两个 MLP policy head(共 3.7M ≈ 0.1% 总参数):
- Position head:输出 或 open-loop 里的 2D 接触像素 (后用深度映回 3D)
- Direction head:输出 旋转矩阵
Loss:
即位置 L1 loss + 方向 geodesic loss(旋转矩阵夹角)。训 8 epoch,lr=1e-5,fp32。数据是 SAPIEN 里 10K 成功样本(20 类 articulated object,Franka Panda + 吸盘)。
❓ 完全冻结 Mamba,只让 3.7M 的 head 把 pooled language token 映射到 pose——这等价于把 Mamba 当成固定的”视觉-任务”特征抽取器。为何 reasoning token 里会自然编码出精确的 SE(3) 接触点?作者没给出 probing 分析,只给了黑箱 end-to-end 结果。
实验结果
通用 reasoning(Table 1):RoboMamba-2.7B / 224 在 OKVQA 63.3 / VQAv2 79.6 / GQA 64.2 / VizWiz 57.1 / POPE 86.3 / MMB 60.9 / MM-Vet 29.4 / RoboVQA BLEU-4 42.8。整体与 TinyLLaVA(2.7B,MMB 68.3 / GQA 61.0)、LLaVA1.5(7B,GQA 62.0)同档或略优;POPE 86.3 同 TinyLLaVA 并列,对 hallucination 稳。
Manipulation(Table 2,SAPIEN 20 seen + 10 unseen 类):
| Method | Seen AVG | Unseen AVG |
|---|---|---|
| UMPNet | 0.34 | 0.26 |
| Flowbot3D | 0.35 | 0.30 |
| RoboFlamingo | 0.41 | 0.43 |
| ManipLLM | 0.56 | 0.51 |
| RoboMamba | 0.63 | 0.53 |
Seen +7%、Unseen +2% 超过 ManipLLM;update 参数 3.7M(0.1%)vs ManipLLM 41.3M(0.5%)vs RoboFlamingo 1.8B(35.5%)。
❓ Unseen 只 +2%,且 RoboFlamingo / ManipLLM 已在 0.43–0.51 区间——“强 reasoning 带来更好 generalization” 在数字上很弱,接近 noise。
Ablation(Figure 3):
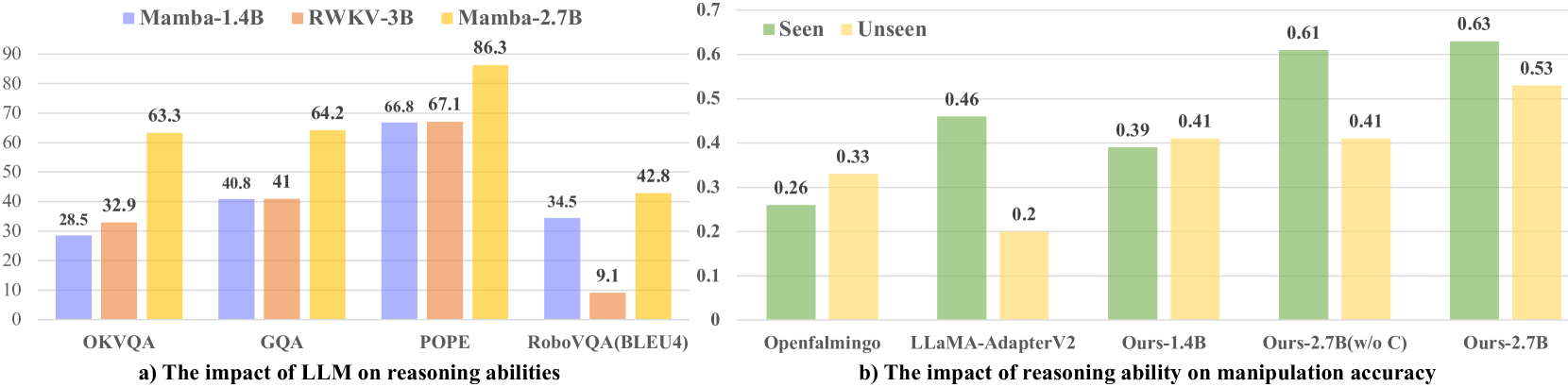 Figure 3. 左:Mamba-2.7B vs RWKV-3B(另一种 linear-complexity LLM)——Mamba 在通用与机器人 reasoning 上都显著更强。右:reasoning 能力更强的 MLLM(Ours-2.7B > Ours-1.4B > LLaMA-AdapterV2 > OpenFlamingo)拿到的 manipulation 成功率更高;同时 Ours-2.7B (w/o C)(去掉 co-training 里的 RoboVQA)明显掉点,尤其 unseen。
Figure 3. 左:Mamba-2.7B vs RWKV-3B(另一种 linear-complexity LLM)——Mamba 在通用与机器人 reasoning 上都显著更强。右:reasoning 能力更强的 MLLM(Ours-2.7B > Ours-1.4B > LLaMA-AdapterV2 > OpenFlamingo)拿到的 manipulation 成功率更高;同时 Ours-2.7B (w/o C)(去掉 co-training 里的 RoboVQA)明显掉点,尤其 unseen。
这个 ablation 的信号是合理的:reasoning 强 → 冻结骨干后的 pooled token 对下游 policy 更 informative;co-training 的 robotic data 对 unseen 泛化关键。
Real-world(Figure 4):Franka Emika 机械臂操作 household articulated objects,展示 task planning、长程规划、affordance、past/future prediction、以及 6-DoF pose 预测。
 Figure 4. 真实场景下的 reasoning + 低层 pose 预测可视化:红点表示接触点、末端执行器姿态投影到 2D 图。只给定性 demo,没给成功率数字。
Figure 4. 真实场景下的 reasoning + 低层 pose 预测可视化:红点表示接触点、末端执行器姿态投影到 2D 图。只给定性 demo,没给成功率数字。
局限(作者自述 + 我的补充)
作者承认:2.7B LLM 在复杂 reasoning 上不如 7B/13B。我的额外观察:
- Open-loop 评测的局限:SAPIEN pull/push articulated object 只要一个接触点 + 一次推拉,不是闭环轨迹——和 RT-2、OpenVLA、π0 的 closed-loop benchmark 不在一个难度级别。
- 与同体量 Transformer LLM 缺对照:对比 baseline 要么是 7B(LLaMA-AdapterV2、ManipLLM、RoboFlamingo),要么是 3B 但 non-Mamba(RWKV)。“Mamba 比同体量 Transformer 更好” 的 claim 其实没被干净地测过。
关联工作
基于
- Mamba (Gu & Dao 2023): Selective SSM 的核心创新(S6 机制),RoboMamba 直接复用其 2.8B pretrained checkpoint 作为 LLM。
- LLaVA: 视觉指令微调范式(MLP projector + LLM),RoboMamba 的 Stage 1 pipeline 直接复刻 LLaVA 的两阶段训练并用其 558K + 655K 数据。
- Cobra: 用 Mamba 替代 LLM 做通用 MLLM 的前置工作——RoboMamba 是首次把这条路线推到机器人下游。
- ManipLLM(同 PKU 组前作,arXiv 2312.16217): RoboMamba 的 manipulation task setup、SAPIEN 数据收集、baseline 策略直接继承。
对比
- RT-2: Transformer-based VLA,把 action 当 text token 直接解码——RoboMamba 走”冻结 LLM + 独立 policy head”的反向路线。
- OpenVLA: 同月发布、同样 open-source 的 7B Transformer VLA,社区影响力远大于 RoboMamba,实际上是这条路线之争的胜者之一。
- RoboFlamingo / ManipLLM: 文中的直接 manipulation baseline,都在 fine-tune LLM 本身;RoboMamba 通过冻结骨干节省参数。
方法相关
- RoboVQA: 机器人 VQA 数据集,RoboMamba 的 Stage 1.2 co-training 关键来源,也是主要的 reasoning evaluation。
- SAPIEN / PartNet-Mobility: 仿真环境与 articulated object 数据集,所有 manipulation 数字都在这里生成。
- π0 / π0.5: 后续 flow-matching + 大规模 cross-embodiment 的 VLA 路线(2024 Q4 起),把 RoboMamba 这种 “冻结 LLM + 小 policy head” 的思路基本绕开了。
论文点评
Strengths
- SSM-as-VLA 的第一次系统 benchmark:在通用 MLLM benchmark 和机器人 pose 预测两头都给了端到端对照,说明 Mamba 在这套 pipeline 下”没崩”,为 SSM 社区在 embodied 方向提供了一个落地参考点。
- 参数效率的观察有价值:冻结 2.7B 骨干 + 只训 3.7M head 就能学 SE(3) pose,且 ablation 显示 reasoning 能力与下游成功率正相关——这与后来 π0.5 / GR00T 等大 VLA 的 “先预训 VLM reasoning、再挂 action head” 的思路方向一致。
- Co-training 策略的信号干净:通用数据 + RoboVQA 的混训在 general benchmark 和 robotic benchmark 上都涨,Ablation(w/o C)明确验证了这是必要的。
Weaknesses
- “Mamba vs Transformer” 的 claim 未受控:关键对照(同体量 Transformer LLM 在同 pipeline 下)缺席,速度优势与性能优势都混淆了体量差。
- Open-loop + single-contact 评测过窄:不像 RT-2 / OpenVLA / π0 的 closed-loop、long-horizon manipulation,外推性受限——“SOTA on SAPIEN open-loop” 不等于 “competitive VLA”。
- Unseen 泛化提升微弱(+2% over ManipLLM):不足以支撑 “reasoning 强 → 泛化强” 的强版 claim。
- Reasoning 与 action 的 bridge 是黑箱:冻结骨干后 pooled global token 为什么能编码精确 3D 接触点?没有 probing 或可视化分析。
- 社区没跟进 SSM 路线:2 年 100 citations / 2 influential citations / repo stale(自 2024-12 无 commit),说明这个方向被后续 Transformer-based VLA(OpenVLA、π0、GR00T)压过去了——这条技术路线即便不错,也没成为主脉。
可信评估
Artifact 可获取性
- 代码: inference+training(repo
lmzpai/roboMamba在 GitHub 可用,MIT license,但 README 空,且 2024-12 后无更新) - 模型权重: 未在正文明确披露 checkpoint 名字(repo 未验证具体 release)
- 训练细节: 仅高层描述(超参、数据配比给了,训练步数只说 epoch 数)
- 数据集: 开源(LLaVA-LCS 558K、LLaVA 1.5 655K、RoboVQA、SAPIEN/PartNet-Mobility 均公开;10K SAPIEN pose 数据作者自采,是否 release 未说明)
Claim 可验证性
- ✅ 通用 MLLM benchmark 成绩:Table 1 的 POPE/GQA/VQAv2 数字与 TinyLLaVA / LLaVA-Phi 同档可对齐,可复现。
- ✅ SAPIEN open-loop 成功率领先 ManipLLM:Table 2 的 baseline 是作者自己复现的,公平性 OK,SAPIEN 评测可复现。
- ⚠️ “3× faster than existing VLA / 7× faster than LLaMA-AdapterV2”:没给 token 数、batch size、硬件细节的完整对照,数字可能把 2.7B vs 7B 的体量差算进去。
- ⚠️ “minimal parameters for manipulation acquisition”:3.7M head 的结论依赖于冻结骨干 + SAPIEN 特定任务,能否迁移到 closed-loop / 真实机器人 long-horizon 未验证。
- ⚠️ “strong robotic-related reasoning”:只在 RoboVQA 上评测,该 benchmark 本身就是训练数据的一部分(300K 采样 train + 18K val),有 train-val 同分布的嫌疑。
Notes
- 这篇的价值更像是 “SSM backbone 可行性 demo”,而不是 “VLA 路线指南”。
- 与 OpenVLA 同月发布,两篇论文的命运对比很有意思:OpenVLA 走 Llama2-7B Transformer + OpenX 大规模训练,成了开源 VLA 基线;RoboMamba 走 Mamba-2.7B + SAPIEN 小数据,2 年后 stale。社区用脚投票:scale + Transformer > architecture-efficiency + 小数据。
-
❓ 如果用 Mamba-2 / Jamba 这种更新的 SSM 架构重做,且放大到 OpenX 数据规模,VLA 的 “Mamba 路线”会不会翻盘?
Rating
Metrics (as of 2026-04-22): citation=100, influential=2 (2.0%), velocity=4.5/mo; HF upvotes=N/A (论文未在 HF Papers 收录); github 150⭐ / forks=12 / 90d commits=0 / pushed 487d ago · stale
分数:1 - Archived 理由:方法的 insight(SSM-as-VLA、冻结骨干 + 小 policy head)清晰,但发表近 2 年 citation 只 100、influential citation 2 篇(2% ratio,远低于典型 10%,说明被 “提一下” 多于被 “继承”),repo 2024-12 起 stale,社区用脚投票没跟进 SSM 路线。相对 OpenVLA(同月,~千级 citation、活跃生态)显然不在 Frontier 档。不给 2-Frontier 是因为它没成为 must-compare baseline;不给 3-Foundation 是因为技术路线未被继承。仍保留为 1 是因为 “VLA 里换 LLM 架构” 的 motivation 与 ablation 对后来理解 “reasoning capacity → manipulation transfer” 有参考价值。