Summary
ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
- 核心: 用 2D foundation models 的输出通过 multi-view association 增量构建 object-centric 的 open-vocabulary 3D scene graph,无需任何 3D 标注数据或微调,directly serve 多样化机器人下游任务
- 方法: SAM 做 class-agnostic segmentation → CLIP/DINO 提 region embedding → depth back-projection + greedy 跨帧 association → LLaVA 多视角 caption + GPT-4 summarize → 在 MST-pruned bbox-IoU 图上让 LLM 生成 spatial relation edges
- 结果: Replica 上 zero-shot 3D semantic segmentation mAcc 40.63(超 ConceptFusion+SAM 的 31.53);node caption 准确率 ~70%、edge 准确率 ~90%;real-world 上 Jackal/Spot 完成 affordance/negation 查询、object search、traversability 估计、open-vocabulary pick-and-place
- Sources: paper | website | github
- Rating: 3 - Foundation(open-vocabulary 3D scene graph 方向的奠基工作,ICRA 2024 后被 DovSG、3DGS+scene graph、embodied QA 等方向广泛作为 baseline 或直接扩展)
Key Takeaways:
- Object 是比 point 更好的语义抽象单元:per-point feature map(CLIP-Fields/OpenScene/ConceptFusion)冗余、无结构、不支持关系推理;object-level 节点天然支持 LLM 文本化、增量更新、relation reasoning,且 memory footprint 小一个量级
- Foundation model stack 替代专用 3D 模型:SAM + CLIP + LLaVA + GPT-4 的组合就能 zero-shot 超过专门训练的 3D 方法(CG 40.63 vs ConceptFusion+SAM 31.53 mAcc),暗示 3D 表示学习的 “标注瓶颈” 可以用 2D 基础模型绕过
- CLIP vs LLM retrieval 在复杂查询上断崖式分化:descriptive query 上两者持平(R@1 ~0.6),但 negation query 上 CLIP R@1=0.26 而 LLM R@1=0.80——CLIP embedding 不理解 “other than”,必须文本化后让 LLM 推理
- Scene graph + LLM 解锁了 traversability、object search 等需要常识的能力:把 graph 的 caption 喂给 LLM 推断 “可推动 / 典型存放位置”,不需要训练专用模型即获得 commonsense reasoning
Teaser. ConceptGraphs 的整体能力 demo——open-vocabulary 查询、affordance/negation、object search、real-robot manipulation/navigation 全在一段视频里展示
Problem & Motivation
机器人需要的 3D scene representation 应同时满足三个要求:(i) scalable & efficient,能随场景体积和操作时长扩展;(ii) open-vocabulary,不被预定义类别限制;(iii) flexible level of detail,既能支撑稠密几何(导航/抓取),也能支撑 abstract 语义和 affordance(任务规划)。
当时的两类方法都不满足:
- Closed-vocabulary semantic mapping(基于 SLAM/SfM + DL 检测分割):只能识别训练集里的类别
- Open-vocabulary per-point feature map(CLIP-Fields、OpenScene、ConceptFusion 等):将 2D foundation model 的 feature 投到每个 3D point 上。两个根本问题——(a) per-point feature 冗余,无法 scale 到大场景;(b) dense representation 无结构,难以 decompose 和动态更新,更没有 entity 间的 spatial/semantic relationship
3D Scene Graph 路线(Hydra 等)解决了第二个问题,但仍是 closed-vocabulary。ConceptGraphs 同时解决两端:用 2D foundation models 喂养一个 object-centric 的 open-vocabulary 3D scene graph。
Method
Figure 2. Pipeline overview——RGB-D 序列 → SAM region → CLIP embed → 3D 投影 → 跨帧 association → LLaVA caption → GPT-4 relation → 最终 scene graph
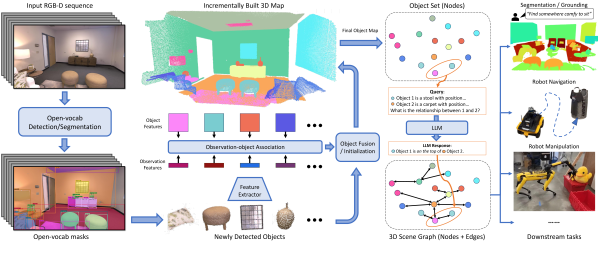
Object-based 3D Mapping
输入是一段 posed RGB-D 序列 ,每帧 。系统增量维护 map ,其中每个 object 由 3D point cloud 和 semantic feature vector 描述。
Class-agnostic 2D Segmentation. 每帧用 SAM(默认)或 RAM + Grounding DINO(CG-Detector 变体)得到一组 mask 。每个 mask 经 CLIP / DINO encoder 得到归一化 embedding 。Mask 内的像素用 depth 反投影到 3D,DBSCAN denoise,转到 map 坐标系,得到 。
Object Association. 对每个新检测,与 map 中有几何 overlap 的现有 object 计算相似度:
Equation 1. Geometric similarity(NN 比例)
含义: 中有多少比例的点在 里能找到 内的近邻(默认 cm)。
Equation 2. Semantic similarity(归一化 cosine)
含义:把 的余弦距离 rescale 到 。
Equation 3. 总相似度 + greedy assignment
新检测 greedy 匹配最高相似度的现有 object。若最大相似度 ,则新建一个 object。
❓ greedy + 简单加和的 score 在 cluttered scene 里大概率会 over/under-segment。论文用 0.55 + 0.55 这样的 cutoff 隐含一个假设:semantic 和 geometric 的 scale 一致。但 CLIP 余弦相似度的实际分布通常很 narrow(0.7-0.95),geometric NN ratio 是 0-1,会让 semantic 项在排序中被压缩。
Object Fusion. 关联成功后:feature 用计数加权平均 ;point cloud 取并集后下采样去冗余。
Node Captioning. 序列处理完后,对每个 object 找出 top-10 most-informative views(按贡献的 noise-free 3D 点数排序),逐张过 LLaVA-7B 生成 caption(prompt: “describe the central object in this image”)。10 个 caption 再由 GPT-4 按特定 system prompt 合成为单一 object_tag,含 summary / possible_tags / object_tag 三字段,能输出 invalid 标签剔除噪声检测。
Scene Graph Generation
给定 object 集合 ,要生成 edge :
- 结构剪枝:两两计算 3D bounding box IoU 得到稠密图,MST 剪枝 得到候选 edge 集合
- Semantic 标注:每条候选 edge,把两端 object 的 caption + 3D location 喂给 LLM,prompt 让其输出 spatial relation(如 “a on b”、“b in a”)+ rationale。LLM 还能产出 nominal 之外的 open-vocab 关系,如 “a backpack may be stored in a closet”
❓ MST 剪枝为什么是合理的?真实场景中一个 object 可以同时与多个 object 有意义关系(书在桌子上、桌子在房间里、书旁边有杯子)。MST 把 edge 数压到 N-1,损失了 multi-relation 表达力,也限制了 graph reasoning 时的多跳路径。
Robotic Task Planning through LLMs
给定文本 query:把每个 object 的 3D bbox + caption 序列化为 JSON description,让 LLM 选出最相关的 object,再把其 3D pose 传给具体的 grasping / navigation pipeline。Scene graph 整体可文本化是这条 pipeline 的关键——也是 graph-structured 表示相对 per-point feature 的根本优势。
Implementation
| 模块 | 默认实现 | 备选 (CG-Detector) |
|---|---|---|
| Segmentation | SAM (class-agnostic) | RAM (image tagging) + Grounding DINO |
| Visual feature | CLIP image encoder | 同 |
| LVLM (caption) | LLaVA-7B | 同 |
| LLM (summary + relation) | GPT-4 (gpt-4-0613) | 同 |
| Voxel size / | 2.5 cm | 同 |
| Association threshold | 1.1 | 同 |
CG-D 还需特殊处理 background object(wall/ceiling/floor),不依赖相似度直接合并。
Experiments
Scene Graph Construction(Replica + AMT)
由于 open-vocabulary 难自动评估,作者用 Amazon Mechanical Turk 让人工评判每个 node caption 是否正确(多数票)、是否是有效 object、edge 是否准确。
Table I. Replica 上的 scene graph 质量(CG = SAM-based default; CG-D = detector-based 变体)
| 变体 | scene | node prec. | valid objects | duplicates | edge prec. |
|---|---|---|---|---|---|
| CG | Avg | 0.71 | - | 0-5 | 0.88 |
| CG-D | Avg | 0.61 | - | 0-4 | 0.91 |
Node 准确率约 70%,主要错误来自 LLaVA 自身的 caption 错误;Edge 准确率 90% 左右——LLM 推断 spatial relation 比想象中可靠。CG-D 的 node precision 稍低,因为 RAM+GroundingDINO 倾向于过度分割(更多 valid objects 但更多噪声)。
3D Semantic Segmentation(Replica,遵循 ConceptFusion 评测)
把每个 object 的 fused CLIP feature 与 "an image of {class}" 的 CLIP text embedding 算相似度,得到 dense class label。
Table II. Open-vocabulary semantic segmentation on Replica
| Setting | Method | mAcc | F-mIoU |
|---|---|---|---|
| Privileged | CLIPSeg | 28.21 | 39.84 |
| Privileged | LSeg | 33.39 | 51.54 |
| Privileged | OpenSeg | 41.19 | 53.74 |
| Zero-shot | MaskCLIP | 4.53 | 0.94 |
| Zero-shot | Mask2Former + Global CLIP | 10.42 | 13.11 |
| Zero-shot | ConceptFusion | 24.16 | 31.31 |
| Zero-shot | ConceptFusion + SAM | 31.53 | 38.70 |
| Zero-shot | ConceptGraphs | 40.63 | 35.95 |
| Zero-shot | ConceptGraphs-Detector | 38.72 | 35.82 |
关键观察:CG 在 mAcc 上甚至追平 privileged 的 OpenSeg(41.19 vs 40.63),且 memory footprint 比 ConceptFusion 小一个量级。F-mIoU 略低于 ConceptFusion+SAM,暗示 object-level 表示在 boundary 精度上有损失(一个 object 一个 label,无法表达 mask 内的细粒度变化)。
Object Retrieval(Descriptive / Affordance / Negation Query)
两种检索策略:CLIP(query embedding 与 object feature 余弦最近邻)vs LLM(GPT-4 读 scene graph 文本选)。
Table III. R@1 / R@2 / R@3 on Replica + REAL Lab scan
| Dataset | Query | Model | R@1 | R@2 | R@3 |
|---|---|---|---|---|---|
| Replica | Descriptive | CLIP | 0.59 | 0.82 | 0.86 |
| Replica | Descriptive | LLM | 0.61 | 0.64 | 0.64 |
| Replica | Affordance | CLIP | 0.43 | 0.57 | 0.63 |
| Replica | Affordance | LLM | 0.57 | 0.63 | 0.66 |
| Replica | Negation | CLIP | 0.26 | 0.60 | 0.71 |
| Replica | Negation | LLM | 0.80 | 0.89 | 0.97 |
| Lab | Descriptive | CLIP | 1.00 | – | – |
| Lab | Descriptive | LLM | 1.00 | – | – |
| Lab | Affordance | CLIP | 0.40 | 0.60 | 0.60 |
| Lab | Affordance | LLM | 1.00 | – | – |
| Lab | Negation | CLIP | 0.00 | – | – |
| Lab | Negation | LLM | 1.00 | – | – |
核心发现:CLIP 适合 descriptive,但完全无法处理 negation(Lab 上 R@1=0),因为 “something to drink other than soda” 的 text embedding 与 soda 高度相关。LLM 路线在 Lab 上 affordance/negation 都是 100%——这是 graph 文本化最大的红利。
❓ Replica 上 LLM descriptive 的 R@2/R@3 都是 0.64,没有提升——说明 LLM 一旦判错就死认,缺乏 ranking 能力。CLIP 自带连续 score 反而 R@K 单调增。实际系统可能需要 hybrid:CLIP top-K 召回 + LLM 重排。
Real-World 任务
Object Search(Jackal). 用户给 abstract query → LLM 在 graph 选最相关 object → LVLM 验证现场是否存在 → 不在则让 LLM 推断典型存放位置(如 “laundry bag” / “shoe rack”)→ 重新导航。
Figure 3. Jackal 的 object search demo:space party query → 找 NASA shirt → 不在原位 → LLM 推断在 laundry bag

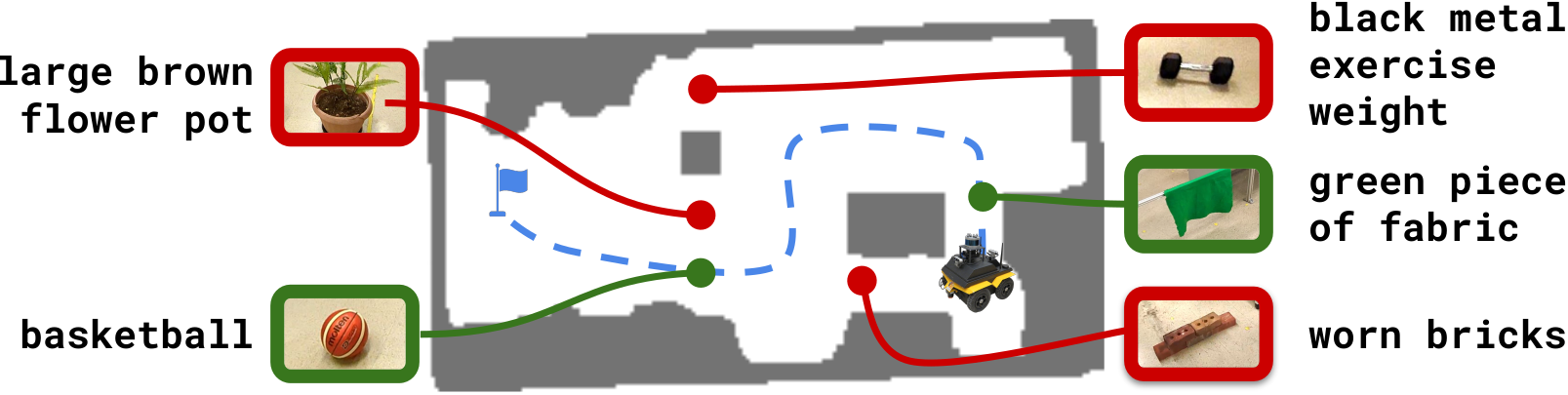
Traversability Estimation. 用户场景:机器人被一圈物体围住,要找通路到达 goal。让 LLM 基于每个 object 的 caption 判断是否可推开/穿越,把不可穿越的加入 costmap。
Figure 4. Jackal 通过 LLM 推理出 “可穿越窗帘 + 可推开篮球”,避开 brick / dumbbell / flower pot
Open-Vocab Pick-and-Place(Spot Arm). Query “cuddly quacker” → 抓鸭子玩偶放盒子;query “something healthy to eat” → 抓芒果。
Localization & Map Updates(AI2Thor). 3-DoF particle filter 用 ConceptGraphs map 做 re-localization,观测更新时把当前 detection 与 map object 按 Sec II-A 同样的 association 流程匹配;过期 object 移除,新 object 加入。
失败模式(来自 Sec III-H)
- Caption 错误:~30% 的 node 标错,直接源于 LLaVA-7B 的能力边界
- 小物体 / 薄物体漏检 + 重复检测:影响关键 object 时直接让规划失败
- API 成本:每帧多次 LLaVA + 一次或多次 GPT-4 inference,real-robot 部署时算力 + 钱都是约束
关联工作
基于
- SAM (Kirillov et al. 2023): class-agnostic mask proposal 是 pipeline 的 entry point
- CLIP (Radford et al. 2021): 提供 region embedding 用于跨帧 association 和 retrieval
- LLaVA (Liu et al. 2023): 多视角 caption 生成
- GPT-4 (OpenAI 2023): caption summarization + spatial relation 推断
- Grounding DINO + RAM: CG-Detector 变体的检测 backbone
对比
- ConceptFusion (Jatavallabhula et al.): 同作者的 per-point feature 工作,是 ConceptGraphs 主要 baseline——用 object node 替代 dense per-point 是核心 framing
- CLIP-Fields / OpenScene / LSeg / OpenSeg: per-point 或 implicit feature field 路线,对比突出 graph 结构的 retrieval 优势
- Mask2Former + Global CLIP / MaskCLIP: zero-shot 2D-to-3D feature lifting baseline
方法相关
- 3D Scene Graph 路线(Hydra, Kimera, SceneGraphFusion 等): closed-vocabulary 的前辈,提供 graph structure 设计灵感;ConceptGraphs 把它们的 vocabulary 限制打开了
- OGSV: 同期 open-vocab 3D scene graph 工作,但用 closed-set GNN 预测 relation;ConceptGraphs 用 LLM 替代了 GNN,避免了 relation 的训练数据需求
- SplaTAM: 同实验室(Krishna Murthy 共同作者)的 dense 3D Gaussian SLAM,可作为 ConceptGraphs 的 pose / geometry 前端,弥补本文对外部 SLAM 的依赖
论文点评
Strengths
- 正确选择了 abstraction level:从 point feature 上升到 object node,是一个简单但 underrated 的设计——它让 LLM 直接成为可调用工具(graph 文本化),让 memory 和 update 都 tractable
- 完全 zero-shot pipeline,但 mAcc 居然超过 privileged 方法:说明 2D foundation model 已经强到不需要专用 3D 训练即可在 indoor scene 达到 SOTA-comparable
- 下游应用展示充分:segmentation / retrieval / search / traversability / pick-place / re-loc 全部跑通,每个都用 graph 的不同侧面(feature / caption / edge / location),有力证明了 representation 的 generality
- CG-Detector 变体提供了 ablation 选择:实践中 SAM 还是 RAM+GDINO 取决于场景,作者直接给出两个版本
Weaknesses
- 依赖 posed RGB-D:需要外部 SLAM 或 ground truth pose,限制了 in-the-wild 部署。作者把这块 outsource 了
- Greedy + 加和相似度的 association 在 cluttered scene 不鲁棒:实测的 duplicate 0-5 是在 Replica 这种相对干净的场景;real-world 的 over/under-segmentation 没有定量评估
- MST 剪枝丢失多跳关系表达力:N 个 object 只有 N-1 条 edge,对需要多 relation 路径的复杂查询(“杯子右边的盘子上的叉子”)会受限
- Caption 准确率 70% 是 hard ceiling:整个系统的语义上限被 LLaVA-7B 压制,30% 的 node 是错的就意味着任何 LLM 推理都在不可靠的输入上做
- 没有 dynamic scene 实验:虽然 architecture 支持 incremental update,但只在 AI2Thor sim 里测了 re-loc + map update。真实动态场景(人走来走去、物体被搬移)的 association rejection 策略没讨论
- API 成本未量化:建图时每个 object 10 次 LVLM + 一次 GPT-4 summary + 每条 edge 一次 GPT-4 relation。一个中等场景(50 objects + 50 edges)就是 500+ LLaVA + 100+ GPT-4 调用
可信评估
Artifact 可获取性
- 代码: 已开源,GitHub 仓库结构完整(concept-graphs/concept-graphs),含 mapping pipeline、object association、captioning、relation generation、retrieval evaluation
- 模型权重: 不需要自己训权重——全部使用 off-the-shelf 模型(SAM、CLIP、LLaVA-7B、GPT-4 API、Grounding DINO、RAM)
- 训练细节: 不适用(zero-shot)。超参完整披露:voxel/ = 2.5 cm, = 1.1,top-10 views per object,GPT-4 system prompt 在 appendix 完整给出
- 数据集: 评测数据集 Replica 公开;real-world REAL Lab scan 未公开发布;AMT 标注 protocol 描述但未发布原始标注
Claim 可验证性
- ✅ Replica 上 zero-shot 3D semantic segmentation mAcc 40.63,超过 ConceptFusion+SAM:Table II 完整对比,code 可复现
- ✅ Node caption ~70% / edge ~90% 准确率:Table I 提供 per-scene 数据 + AMT 评测协议
- ✅ Negation query 上 LLM (R@1=0.80) 显著优于 CLIP (R@1=0.26):Table III 数据明确
- ✅ 可在 Jackal 和 Spot 上 deploy:项目页有完整 real-world demo 视频证据
- ⚠️ “compact and efficient for large scenes”:相对 per-point feature 确实更 compact,但论文未给定量的 memory / latency 对比表,也未在大尺度场景(如建筑级别)验证。Replica 是房间级别
- ⚠️ “dynamic updates to the map”:架构上支持,但只在 AI2Thor sim 里验证。真实动态场景的 association 失败率未知
- ⚠️ “open-vocabulary”:caption 依赖 LLaVA-7B,对于 LLaVA 训练数据外的稀有物体(如特殊工业部件)能力未测
Notes
- ConceptGraphs 的 scene graph 结构天然适合作为 VLN 和 VLA 的桥梁:graph nodes 可以作为 navigation waypoints(VLN),也可以作为 manipulation targets(VLA)。这是 “spatial memory” 这条线和 “language-conditioned policy” 之间的有用接口
- 与 SplaTAM 等 dense SLAM 结合,可以解决其依赖外部 pose 估计的问题。Krishna Murthy 同时是两者作者,暗示这两条路线可能融合(事实上之后确实出现了 ConceptGraphs + Gaussian Splat 的工作线)
- 核心 takeaway 复盘:把 representation 从 per-point 上升到 object-node,本质是 explicit decomposition + 文本化能力,让 LLM 能直接读写 map。这与 agent 领域 “把环境序列化为 LLM 可消化的文本” 的趋势一脉相承——representation 选择应该 align 下游 reasoning engine 的接口
- 2026 视角下需要重看的点:(1) LLaVA-7B 的 caption 上限早已被新一代 VLM 突破(GPT-4o、Claude、Qwen-VL 等),如果重做 Table I node precision 应能升到 90%+;(2) negation/affordance 上 CLIP 的崩溃在 SigLIP-2 / 更强 text encoder 下是否依然存在,值得复测;(3) 整个 pipeline 在新一代 VLM 推理便宜后是否变得可全在线运行
Rating
Metrics (as of 2026-04-24): citation=388, influential=61 (15.7%), velocity=12.56/mo; HF upvotes=10; github 829⭐ / forks=117 / 90d commits=0 / pushed 189d ago · stale
分数:3 - Foundation
理由:ConceptGraphs 是 open-vocabulary 3D scene graph 方向的奠基工作——它把 “per-point feature map → object-centric graph” 的 representation shift 立住(Strengths 1 + Weaknesses 3 中 framing),并完整展示了 segmentation / retrieval / search / traversability / pick-place 全栈可用性。ICRA 2024 发表后被 DovSG、后续 3DGS + scene graph、embodied QA 等方向广泛作为 baseline 或直接扩展(同目录下的 2410-DovSG.md 即明确 build on)。不给 2 是因为它不是”只是一个 SOTA”——它定义了 foundation-model-driven 3D scene graph 这个子方向的 template;不给更高是因为已经出现 LLaVA caption 瓶颈和 MST 剪枝等被后续工作修正的设计缺陷(Weaknesses 3-4)。
2026-04 复核:citation=388 / influential=61 (15.7%) / velocity=12.56/mo——citation 总数不如我原文”破千量级”断言(撤回该说法),但 influential ratio 15.7% 明显高于典型 ~10%,说明方法被后续工作实质继承而非仅作 landmark reference,维持 Foundation 判断;相邻档 2(Frontier)的工作往往是 SOTA 对照而非被继承的 building block,ConceptGraphs 的 pattern 符合前者。