Summary
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
- 核心: 用 LLM 写 Python 代码去调用 VLM / open-vocab detector,在机器人的 3D 观察空间中直接 compose 出 affordance + constraint 的 voxel value map,作为 motion planner 的 cost,从而 zero-shot 合成 6-DoF 操纵轨迹——无需任何机器人数据训练
- 方法: LLM (GPT-4) 生成 Python 代码 → 调用 OWL-ViT + SAM + XMem 做感知,用 NumPy 操作写出 (100,100,100) 的 affordance / avoidance / rotation / velocity / gripper 五类 3D 值图 → greedy 运动规划器在 affordance+avoidance 加权和上求 collision-free 路径 → 5 Hz MPC 闭环重规划
- 结果: 真实世界 5 任务 zero-shot 平均 88% 成功率(有扰动下 70%),显著强于 LLM+primitives baseline;仿真 13 任务 2766 指令的 open-set 泛化也显著领先;加 <3 分钟在线探索即可学到用于 contact-rich 任务的 dynamics model
- Sources: paper | website | github
- Rating: 3 - Foundation(LLM-as-reward / LLM-生成空间 cost 这条路线的奠基工作,873 citations + 64 influential 印证其被大量继承)
Key Takeaways:
- LLM 的最佳用法不是直接输出 action,而是输出 3D 空间中的 reward/cost:LLM 擅长推理”哪里该去/哪里该避”,但高频控制信号它写不了;code-writing + NumPy + perception API 把这个推理落地成 voxel 上的数值场。
- “Entity of interest”抽象:value map 不止驱动 end-effector,也可以驱动”被操纵物体”——配上 dynamics model 后直接优化”robot 怎么推才能让物体到达高 value 区域”,把 manipulation 统一成一个 value-driven 框架。
- Spatial composition 比 sequential composition 更强:Code as Policies 把 LLM 限制在”调用预定义原语序列”,VoxPoser 展示出 LLM 可以在空间层面组合多种约束(吸引+排斥+旋转+速度)于同一个优化问题内,这是对 LLM+robotics 设计空间的关键扩展。
- MPC + LLM-caching 让闭环可行:生成代码在一个 sub-task 内不变,所以可以 cache LLM 输出、每步重新执行代码获得新 value map——规避了 LLM 推理延迟,同时保留对动态扰动的鲁棒性。
- Zero-shot 之外:synthesized trajectory 可作为探索先验,加少量在线交互学 dynamics model,解决接触丰富的任务(如开门)——“LLM 提供 prior,RL 细化 skill”的一个干净范式。
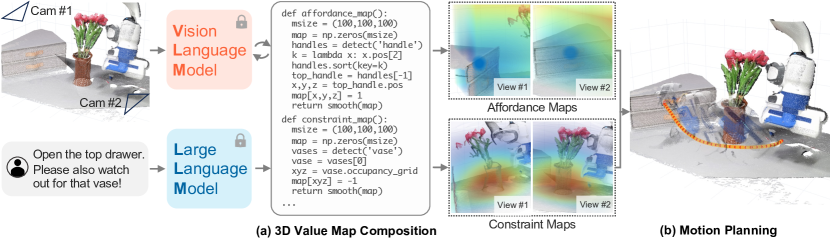
Teaser. VoxPoser 整体 pipeline:给定 RGB-D 观察和语言指令,LLM 写代码、调用 VLM 得到语义信息,再用 NumPy 组合成 3D 值图,作为运动规划的目标函数。
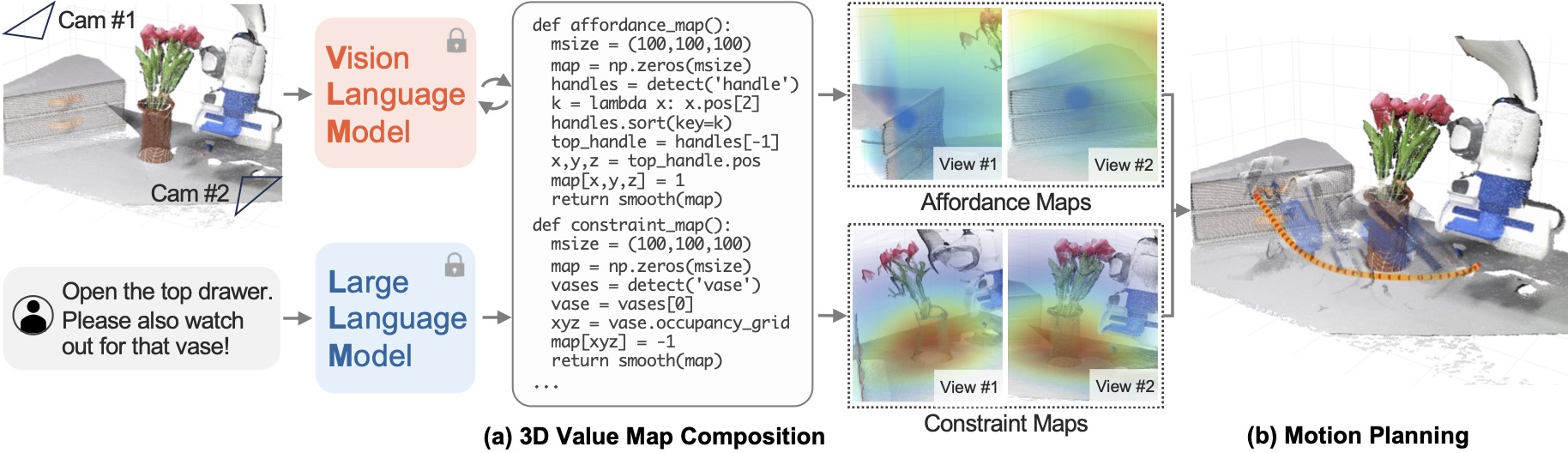
Problem Formulation
把长指令 分解为 sub-tasks (分解本身也交给 LLM,但不是本文重点)。对每个 sub-task,优化问题是:
符号说明: 环境状态轨迹; 机器人轨迹(6-DoF end-effector waypoints); 指令完成度; 控制成本; 动力学与运动学约束。
核心挑战: 对 free-form language 几乎没法写——语义空间太大、没有 labeled trajectory-instruction 数据。VoxPoser 的 insight 是把它近似为 voxel value map 上的路径积分。
Grounding Language via Voxel Value Maps
关键观察
大量 manipulation 任务可以用一个 voxel value map 指导”entity of interest” 的运动( 可以是 end-effector、物体、或物体部件)。于是:
例:“open top drawer”的第一个 sub-task “grasp top drawer handle”: 是 end-effector,value map 在 handle 位置高值;加上”watch out for the vase”后,vase 周围低值。
LLM 怎么生成 value map
LLM 被 prompt 以 code 的形式写出值图构造逻辑:
- 调用 perception API(触发 OWL-ViT + SAM + XMem)获取对象点云 / 部位
- NumPy operations 在 100×100×100 的 voxel 格子上做距离变换、Gaussian 模糊等
- prescribe 数值 在相关位置
得到 。稀疏的 map 会用 Euclidean distance transform(affordance)或 Gaussian filter(avoidance)做平滑——鼓励规划器出平滑轨迹。
五类值图
除位置 cost map 外,还 compose:
- rotation map(如”end-effector 对齐 handle 法向”)
- gripper map
- velocity map
这些不是 cost,但参与轨迹参数化。
LMP 架构
沿用 Code as Policies 的 LMP (Language Model Program) 递归调用结构:
plannerLMP:把 切成 sub-taskscomposerLMP:接到 后调用五类 value-map LMP- 每个 value-map LMP 有 5-20 个 in-context examples
Figure 2. VoxPoser overview:LLM 写代码 → 调 VLM → 产 3D affordance / constraint map → 作为运动规划的 objective → 合成轨迹。全程无需训练。
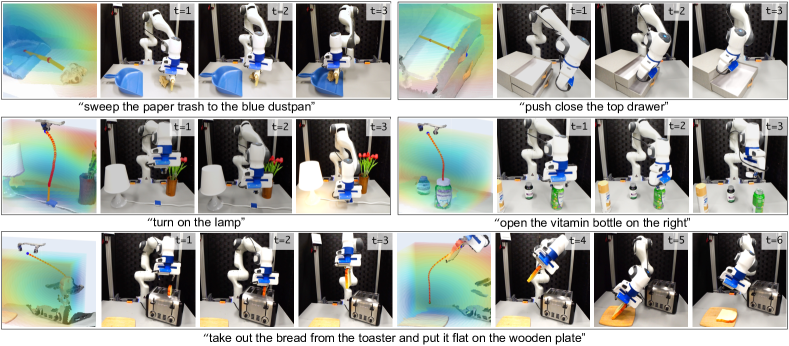
Zero-Shot Trajectory Synthesis
- 运动规划器:只把 affordance 和 avoidance map 加权(权重 2 和 1)作为 cost,用 greedy search 找 collision-free 的 ;然后把 rotation / velocity / gripper map 在每个 waypoint 上 enforce。
- MPC 闭环:合成 6-DoF 轨迹后只执行第一步,5 Hz 重新规划。因为同一 sub-task 内 LLM 生成的 code 保持不变,可以 cache LLM 输出,每次重规划只是重新执行 code → 这样既有 LLM-level 推理,又能闭环响应动态扰动。
- Dynamics model:多数任务 entity 是 robot 本体,用已知机器人模型即可;对”entity 是物体”(如平面推物),用启发式模型(沿 push direction 平移点云),random shooting MPC 优化 contact point / direction / distance。
Figure 3. 真实世界 value map 可视化:上行 entity 是物体/部件;中下行 entity 是 end-effector;最下是双阶段任务。
Online Dynamics Learning
zero-shot pipeline 对 contact-rich 任务(开门、开冰箱、开窗)不够——需要学 dynamics model。传统 MPC 从完整 action space 随机采样效率低。VoxPoser 的 zero-shot 轨迹 虽不完全正确,但提供了有用的 exploration prior:只在 ()的邻域采样,快速收集有意义的交互数据,然后训练 MLP 动力学模型。
Experiments
真实世界 5 任务
Table 1. VoxPoser vs. LLM+Primitives [Code as Policies]:真实环境成功率(static / with disturbances)。
| Task | LLM+Prim. Static | LLM+Prim. Dist. | VoxPoser Static | VoxPoser Dist. |
|---|---|---|---|---|
| Move & Avoid | 0/10 | 0/10 | 9/10 | 8/10 |
| Set Up Table | 7/10 | 0/10 | 9/10 | 7/10 |
| Close Drawer | 0/10 | 0/10 | 10/10 | 7/10 |
| Open Bottle | 5/10 | 0/10 | 7/10 | 5/10 |
| Sweep Trash | 0/10 | 0/10 | 9/10 | 8/10 |
| Total | 24.0% | 0.0% | 88.0% | 70.0% |
LLM+Primitives 对扰动的 0% 成功率印证了:预定义原语一旦被外部干扰打断就无法恢复;VoxPoser 的闭环重规划是结构性优势。
仿真 13 任务泛化
Table 2. 仿真 block-world 成功率(SI/UI = seen/unseen instruction,SA/UA = seen/unseen attributes)。
| Train/Test | Category | U-Net+MP | LLM+Prim. | VoxPoser (MP) |
|---|---|---|---|---|
| SI SA | Object Int. | 21.0% | 41.0% | 64.0% |
| SI SA | Composition | 53.8% | 43.8% | 77.5% |
| SI UA | Object Int. | 3.0% | 46.0% | 60.0% |
| SI UA | Composition | 3.8% | 25.0% | 58.8% |
| UI UA | Object Int. | 0.0% | 17.5% | 65.0% |
| UI UA | Composition | 0.0% | 25.0% | 76.7% |
关键观察:U-Net 在 unseen instruction 上崩到 0%(监督学习外推失败),LLM-based 方法保持稳定——LLM 显式 reasoning 比 learned cost 更 generalize;value map composition 比 primitive parameter 灵活——后者的表达受限于原语集。
Online Dynamics Learning
Table 3. 开门 / 开冰箱 / 开窗三类接触任务:VoxPoser zero-shot 先验 + <3 分钟在线交互学到的 dynamics model 达到高成功率;无先验探索全部 TLE(>12 小时)。
涌现行为(网站展示)
- Behavioral commonsense:“I am left-handed” → 把叉子换到 bowl 左侧
- Fine-grained correction:“you’re off by 1cm” → 精细调整
- Multi-step visual program:“open drawer precisely by half” → 先开到底记录位移,再回到一半
关联工作
基于
- SayCan: LLM + 预定义 primitive 的代表;VoxPoser 把”LLM 只能选原语”打破
- Code as Policies (Liang et al. 2023): LLM 写代码调用 perception + primitives 的起点;VoxPoser 在其 LMP 架构基础上,把 code 生成的对象从 primitive sequence 换成空间值图
- PaLM-E: 多模态 LLM 直接 ground vision 的路线——作者在 future work 中指出可以替代 VoxPoser 的外部 perception 模块
- OWL-ViT / SAM / XMem: open-vocab 感知堆栈,VoxPoser 作为可调用的 API
对比
- LLM + Primitives(Code as Policies 变体):主 baseline,sequential 组合 vs. spatial 组合;在扰动下 primitive 无法重规划
- U-Net + MP (Sharma et al.): 监督学语言→2D costmap,不会 reasoning 所以 unseen instruction 崩;VoxPoser 走纯 zero-shot reasoning
方法相关
- Potential field / constraint-based manipulation:VoxPoser 的 voxel field + motion planning 在形式上是经典 potential field 的升级版——场由 LLM 写出来而非人工设计
- LLM-based reward generation(Yu et al. 于 MuJoCo 等):VoxPoser 的区别是把 reward grounded 在 3D observation space 而非 physics model
论文点评
Strengths
- 问题抽象优雅:把”LLM 怎么控制机器人”的难题转化为”LLM 写代码生成 3D 值图”,既利用了 LLM 的强项(写代码、spatial reasoning、open-world knowledge),又规避了弱项(高频控制、连续动作)。这是 first-principles 思考的漂亮结果。
- 泛化能力结构性强:因为 value map composition 发生在推理时、而且是空间层面组合(不是序列层面),open-set instruction/object 泛化是内生的而非学出来的。真实世界 88% 成功率 + 仿真 unseen instruction 不掉点就是证据。
- 闭环 MPC 设计聪明:LLM cache + code 重执行解决了”LLM 推理延迟 vs. 闭环响应”的 tension,扰动下成功率 70% 验证了闭环确实 work。
- 把 zero-shot 和 online learning 接起来:zero-shot 作为 exploration prior 让 RL 样本效率从 >12 小时降到 <3 分钟——“LLM 提供先验,少量交互 refine”是非常干净的 hybrid 范式。
- 方法 simple + scalable:没有新模型、没有新训练,就是 LLM prompting + NumPy + greedy search + OWL-ViT/SAM;这种简洁是真正 generalize 的信号。
Weaknesses
- 依赖外部 perception 堆栈:OWL-ViT + SAM + XMem 这一套对初始姿态敏感,error breakdown 显示真实世界 perception 是主要瓶颈。这个决定可能是时代限制(2023 Q3 还没有 SAM 2 或 GroundingDINO);现在可以用多模态 LLM 直接 ground,VoxPoser 的 pipeline 会更干净。
- Prompt engineering 负担重:5 类值图 + planner + composer + parse-query 共 7 个 LMP,每个 5-20 个 in-context examples,手写 prompt 的工作量不小——这部分是 manual labor,论文坦诚列在 limitation。
- Motion planner 简陋:只考虑 end-effector trajectory,whole-arm planning 没做;greedy search + random shooting 对非常 dense 的 clutter 可能不够。
- Dynamics model 的通用性:contact-rich 任务的 dynamics 是 MLP + 在线数据,每个任务单独学——没有 general-purpose dynamics prior 这件事在论文 limitation 里也明确了。这也是后续 world model + VoxPoser 结合的空间。
- 评测任务偏 table-top:5 个真实任务都是桌面操作,没有 mobile manipulation / 高动态 / deformable object。“88% 成功率”的外推性要谨慎。
- “Zero-shot”边界:虽然不需要机器人数据,但 GPT-4 本身是大规模训练的产物,而且 prompt 里有 5-20 个 example——这是严格意义上的 “few-shot prompted”,“zero-shot” 的措辞略 marketing。
可信评估
Artifact 可获取性
- 代码: 已开源(RLBench 仿真版 demo,不含真实感知 pipeline),MIT license
- 模型权重: 无——VoxPoser 无需训练,依赖 GPT-4 API + 公开 VLM 权重(OWL-ViT / SAM / XMem)
- 训练细节: N/A(zero-shot,无训练);prompt 细节在 paper appendix + 网站的 prompt 链接完整公开
- 数据集: 13 个仿真任务来自 block-world 环境(build on OpenAI gym-style 代码),公开;真实世界 5 任务是自建,任务描述在论文但无数据集发布
Claim 可验证性
- ✅ Zero-shot 合成轨迹 + 真实 88% 成功率:Table 1 提供 5 任务 × 10 trials 的明确成功率,网站有对应视频
- ✅ 扰动鲁棒性:网站有 disturbance 条件下的 closed-loop recovery 视频
- ✅ 泛化到 unseen instruction:Table 2 的 UI UA 条件下 VoxPoser 65%/77% vs. U-Net 0%,对比干净
- ⚠️ “Open-set”:定义偏宽松——实际测试任务还是相对结构化的 tabletop task,真实开集泛化(如户外、novel object morphology)未验证
- ⚠️ Error breakdown 的归因:perception / dynamics / specification 三类 error 的定义 operational 但未报告 inter-rater reliability,数字的绝对值要谨慎看
- ⚠️ LLM-as-reward 的 failure mode:LLM 写错代码怎么办?论文没系统分析 value map 本身出错的比例(“specification error”包含这一项但没拆细)
Notes
- 对 VLA 路线的意义:VoxPoser 代表了和 VLA(RT-2、OpenVLA、π0)互补的一条路——VLA 直接学 action,VoxPoser 学 cost landscape 让 planner 生成 action。长期看这两条会收敛(end-to-end 学 value map + planner),但在”怎么用 pretrained foundation model 做机器人”这个设计空间里,VoxPoser 是不能跳过的 reference point。
- 和 world model 的连接:论文 4.3 节的”zero-shot prior + online dynamics learning”其实就是”LLM 提供 action prior,world model 细化 transition”。现在的 world model 论文可以重新审视这个框架——VoxPoser 把 action prior 具象化成3D 空间中的 attractor field,这比抽象的 action distribution 更可视化、可调试。
- 一个疑问:
> ❓ value map 的 spatial resolution 是 100³ = 1M voxels,对很大场景或很精细操作是否够?paper 没系统 ablate——这其实是方法 scale-up 时的关键参数。
Rating
Metrics (as of 2026-04-22): citation=873, influential=64 (7.3%), velocity=26.2/mo; HF upvotes=4; github 801⭐ / forks=109 / 90d commits=0 / pushed 426d ago · stale
分数:3 - Foundation
理由:VoxPoser 是”用 LLM 写代码生成 3D 空间 reward / affordance”这一路线的奠基工作——发布近 33 个月累计 873 citations、26/mo 的 velocity 持续强劲,64 influential citations(7.3%,接近 LLM-robotics 领域典型水平)说明被大量后续工作实质继承而非仅 landmark reference。github 虽然 stale(pushed 426 天、90d 无 commit、仅 demo 实现),但论文贡献在方法论层面而非代码资产,不影响方向上的奠基性。相对于 Frontier (2):VoxPoser 不是 incremental SOTA,而是定义了 LLM + VLM + motion planning 的一个新的组合范式,CoRL 2023 Best Paper 也是社区共识;相对于同档的 SayCan 这类 LLM+primitives 工作,VoxPoser 展示了”spatial composition”的更强表达力,是后续 LLM-as-reward / language-to-costmap 路线(Eureka、Text2Reward 等)的共同源头之一。