Summary
UniPlan: Vision-Language Task Planning for Mobile Manipulation with Unified PDDL Formulation
- 核心: 把 large-scale 室内 mobile manipulation 的 task planning 统一为一个 PDDL 形式——视觉拓扑地图 + VLM 局部 grounding + 程序化领域扩展,用现成 PDDL solver 求解
- 方法: (1) 在 visual-topological map 上用 LLM 检索任务相关 asset 节点并压缩拓扑图;(2) 通过 AST rewrite 将学到的 tabletop PDDL 域 (UniDomain) 程序化扩展出导航/开门/双臂算子;(3) 用 factored 方式构造 PDDL problem——robot state 程序注入、object state 由 VLM grounding、topology 从压缩图直接编码;(4) Fast Downward 求解
- 结果: 50 个真实场景任务 (4 settings) 平均 SR 83.75%,相对 SayPlan/DELTA/LLM-as-Planner 大幅领先;LLM calls=2、planner time <0.7s;w/o Injection 时 SR 在 with-door 设置下崩到 31%
- Sources: paper
- Rating: 2 - Frontier(neuro-symbolic task planning 的代表前沿工作,factored PDDL construction 的设计原则有 transferability,但完全跳过低层执行 + 单一环境评测限制其 foundational 地位)
Key Takeaways:
- Factored PDDL Construction is the load-bearing trick:把 robot / object / environment 三类 fact 分别用合适的 channel 注入(程序、VLM、deterministic 算法),而不是让 VLM 一把生成整个 problem 文件——w/o Injection 在 Single-Arm With Door 下 SR 直接崩到 31%(vs. 84%),证明 VLM 写大规模 graph 结构是不可靠的
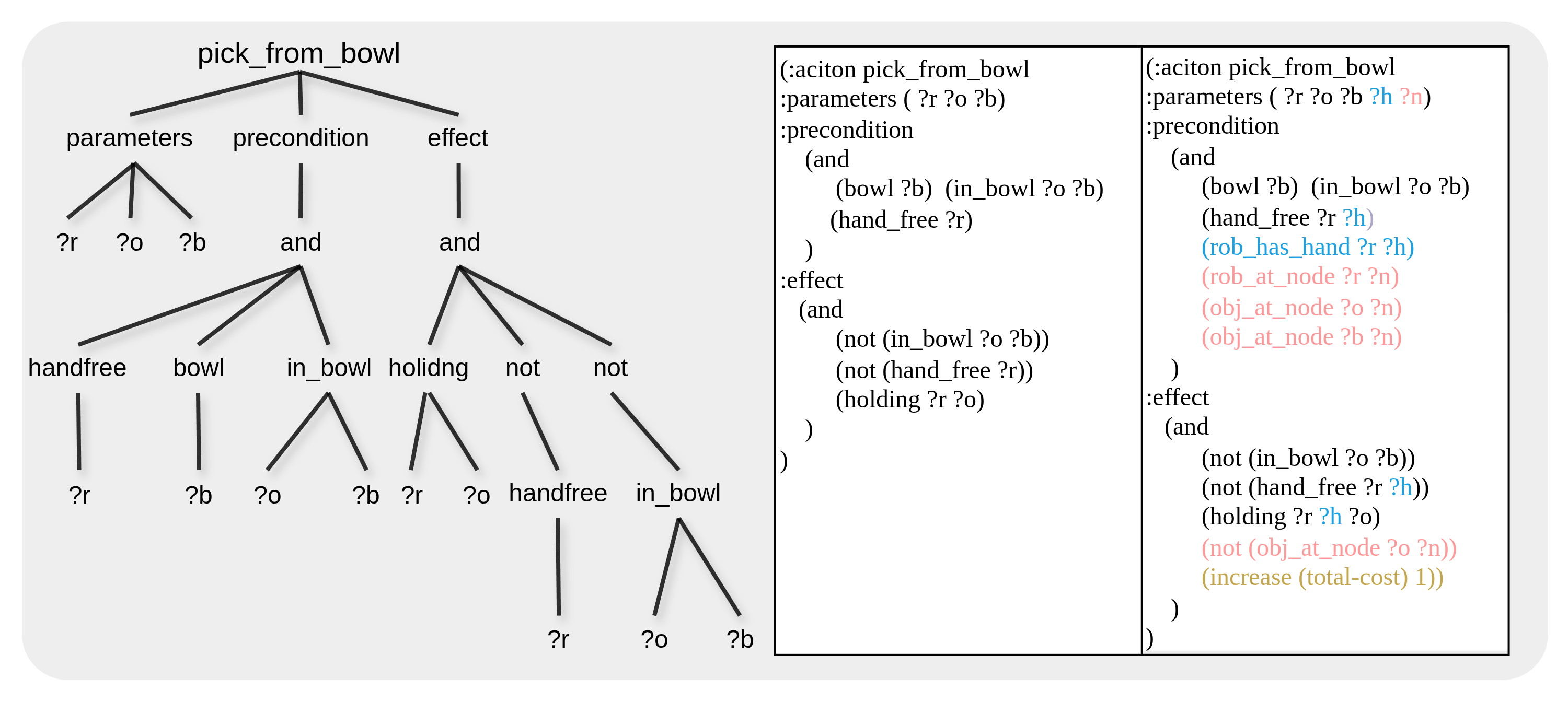
- Programmatic Domain Expansion via AST Rewrite:把 PDDL 当 CFG 解析成 AST,定义一套基于 semantic anchor (
hand_free,holding) 的 syntax-preserving rewrite 规则,把 tabletop 域自动扩展出 navigation / door / bimanual 能力——避免重新 collect mobile 演示数据 - Task-Oriented Map Compression:用 LLM 按 caption 检索相关 asset 节点 + Dijkstra 算最短路压缩成稠密拓扑图,把 PDDL 搜索空间从 hundreds of nodes 压到几个,planner time 从 48s 降到 0.4s
- VLM 只做局部 grounding:避免 cross-image 推理这一已知 VLM 弱点;同时 caption 用作离线 lightweight 索引,每任务只调 2 次 LLM
- Building on UniDomain:UniPlan 的强度建立在前作 UniDomain 学到的 large-scale tabletop PDDL 域之上——本文的贡献是”如何把它扩展到 mobile”,而不是”如何获得 manipulation 域”
Teaser. UniPlan 系统总览:visual-topological map → 任务相关节点检索与拓扑压缩 → factored PDDL problem 构造 → 统一规划。

Motivation 与 Problem Setup
Mobile manipulation 在 large-scale 室内环境的核心矛盾:
- Pure LLM + scene graph 路线 (ConceptGraphs、SayPlan 等):把视觉先压成文本 scene graph 再交给 LLM 推理。但作者论证——哪些视觉属性 task-relevant 是 task-dependent 的(“取苹果吃” vs. “取苹果摆放” 关心的属性完全不同),任何 fixed scene graph 都会有 information loss。
- Pure VLM 路线(直接拿当前 + 历史图给 VLM 推理高层动作):mapless,只能处理少量在线图片,无法形成对大场景的 holistic understanding;且 long-horizon 下 VLM 推理脆弱。
- PDDL + LLM 混合路线 (DELTA, SayPlan 等):依赖手工域(环境特定)或 LLM 生成域(脆弱)。
UniPlan 的设计原则:
- 维护保留完整图像信息的 visual-topological map
- 用 VLM 做局部 visual grounding,长程推理交给符号 PDDL planner
- 不做 task/env-specific training,依靠 pretrained VLM + pretrained 符号域
- 只对 task-relevant 视觉上下文做推理(scalability)
❓ 这套设计的正确性高度依赖 “tabletop PDDL 域已经被预训练好”——也就是 UniDomain 的存在。如果换一个域不够 mature 的 manipulation skill set,整个 pipeline 是否仍 work?作者只在 Generality 段说”原则上适用于其它 tabletop 域”,没实验。
方法
Programmatic Domain Expansion (Section IV)
把 PDDL 当 CFG,用 Unified Planning framework 解析成 AST 后做确定性 rewrite——保证 (i) syntactically valid by construction、(ii) operator 间一致、(iii) 跨环境复用。
Semantic Anchors:统一两个 canonical predicate (hand_free ?r) 和 (holding ?r ?o)(与 UniDomain 一致),作为后续 rewrite 的稳定锚点——不依赖具体源域的命名约定。
Navigation & Door Expansion:引入 (rob_at_node ?r ?n)、(obj_at_node ?o ?n)、(connected ?n1 ?n2)、(has_door ?n1 ?n2),加 move_robot 和 open_door 算子。每个原 operator 自动注入:
- precondition 加
(rob_at_node ?r ?n),对每个非 robot 参数?o若不在(holding ?r ?o)precond 中则加(obj_at_node ?o ?n) - effect 根据
(holding)状态变化推断(obj_at_node)的增删
Bimanual Expansion:把 anchor 升为 hand-specific:(hand_free ?r ?h)、(holding ?r ?h ?o),每个 operator 加 hand 参数 ?h 并传播到所有 anchor occurrence。
Cost Modeling:引入 (travel_cost ?n1 ?n2),move_robot 累加 travel cost,其它 manipulation operator 加常数 cost;problem 文件设 metric 让 solver 联合优化。
Figure 2. AST-based operator rewriting on pick_from_bowl:左为原始 AST、中为原始 schema、右为扩展后 schema(蓝=arm-utility,红=topological,橙=cost)。
Visual-Topological Map (Section V)
节点三类:
- Pose Nodes:导航 waypoint
- Room Nodes:空间过渡(doorway、走廊入口)作为 topological bottleneck
- Asset Nodes:大型静态家具(桌台、橱柜),每个 anchor 一组 high-resolution 多视角图像
地图假设离线预构建——拓扑结构借鉴 Hydra 等,anchor image 的选择借鉴 KeySG 等。
Task-Oriented Map Compression 是 UniPlan 实现 scalability 的关键:
- Offline Indexing:VLM 给每个 Asset node 的图生成简单 caption(只列 visible objects/furniture),作为轻量文本索引
- Online Selection:LLM 根据 instruction 在 caption 上检索相关 asset 节点
- Topology Compression:在原图上跑 Dijkstra 算选中节点 + robot 当前位置之间的两两最短路;同 zone 内创建 weighted shortcut;关闭的门视为物理边界——shortcut 不能穿越关门,必须保留具体的 door traversal edge
输出:稠密、最小但物理一致的状态空间。
Factored PDDL Problem Formation (Section VI)
三个 factor 分别注入:
| Factor | 来源 | 注入方式 |
|---|---|---|
| Robot state(hand 占用、arm 配置、初始位置) | onboard perception | 程序化写入 (:objects) / (:init) |
| Object & object state | VLM grounding(每个 task-relevant node 的图像) | VLM 生成 entity / init / goal predicate;后处理注入空间 anchor (obj_at_node ...) |
| Topology & cost | 压缩后的 map | 直接映射为 (connected ...) / (= (cost ...) ...) / (has_door ...) |
关键设计:明确禁止 VLM 生成 robot-specific predicate(这些由 robot config 模块独占),且禁止 cross-image VLM 推理——全局空间关系由 deterministic 算法负责。
最终用 Fast Downward 跑 seq-opt-lmcut 求 cost-optimal plan,然后把抽象的 move_robot 边展开回低层 waypoint 序列。
实验
Setup
- 真实大场景地图:43 pose / 18 room / 18 doors / 31 asset / 100+ objects
- 50 个人类提出的真实任务,覆盖 17 种 primitive action(pick/place/open/close/pour/cut/stir/scoop/fold/wipe/turn_on/turn_off/hang_on/open_door/move 等)
- 三档复杂度:Simple (1-10, 2-4 actions) / Moderate (11-40, 5-10 actions, 全 17 类 action) / Compositional (41-50, 10-20 actions)
- 4 setting:{Single-Arm, Dual-Arm} × {No Door, With Door}
- LLM 统一用 GPT-5.2 (T=0, none reasoning effort),每 setting 跑 N=4
- Planner: Fast Downward seq-opt-lmcut
- 评估方式:python emulator 严格编码 precondition/effect/transition/goal——避免 human/LLM judge 的 inconsistency
主结果 (Table I)
| Setting | Method | SR (%) | LLM Calls | T_think / T_plan (s) | RPQG (%) |
|---|---|---|---|---|---|
| S-A No Door | LLM as Planner | 40.00 ± 4.62 | 2.00 | 19.07 / — | 2.90 |
| SayPlan | 41.00 ± 5.29 | 9.13 | 64.18 / — | 5.42 | |
| DELTA | 26.00 ± 5.89 | 4.04 | 71.50 / 0.31 | 7.77 | |
| UniPlan | 83.50 ± 4.43 | 2.00 | 21.23 / 0.43 | — | |
| S-A With Door | LLM as Planner | 17.50 | 2.00 | 22.63 / — | 5.49 |
| SayPlan | 33.00 | 9.75 | 71.30 / — | 10.26 | |
| DELTA | 18.50 | 4.09 | 75.12 / 0.35 | 16.17 | |
| UniPlan | 84.00 ± 2.83 | 2.00 | 21.55 / 0.42 | — | |
| D-A No Door | LLM as Planner | 40.50 | 2.00 | 18.38 / — | 2.49 |
| SayPlan | 49.50 | 8.77 | 60.55 / — | 6.12 | |
| DELTA | 26.50 | 4.05 | 71.46 / 0.35 | 12.19 | |
| UniPlan | 82.00 ± 2.31 | 2.00 | 21.73 / 0.66 | — | |
| D-A With Door | LLM as Planner | 39.50 | 2.00 | 22.50 / — | 2.74 |
| SayPlan | 42.50 | 9.09 | 59.64 / — | 4.65 | |
| DELTA | 21.50 | 4.02 | 72.60 / 0.33 | 7.25 | |
| UniPlan | 85.50 ± 2.52 | 2.00 | 21.89 / 0.11 | — |
观察:
- UniPlan 在所有 4 个 setting 上 SR ≥ 82%,比 baseline 拉开 ~30-60 pt
- LLM calls 只有 2(baseline 4-10 次),thinking time 也是最低(~21s vs. 60-75s)
- Planner time <0.7s——压缩拓扑图让符号搜索基本免费
- RPQG 全为正,UniPlan 的 plan 比 baseline 短 ~2-16%
❓ baseline 都被砍到 ~20-50% SR,部分原因是任务覆盖了 17 种 action 且包含 long-horizon——这是 LLM 直接规划的传统弱项。但 SayPlan 在 With-Door / Single-Arm 下只有 33%,DELTA 只有 18.5%,比作者自己复述 SayPlan 原文的数字差得多。这暗示作者的 task pool 比 SayPlan 原 setting 难得多,可信但需要注意 baseline 数字不是直接可比的。
消融 (Table II)
| Setting | Variant | SR (%) | T_think | T_plan | RPQG vs. Full |
|---|---|---|---|---|---|
| S-A No Door | Full | 83.50 | 21.23 | 0.43 | — |
| w/o Vision | 70.00 | 13.55 | 0.13 | 0.14 | |
| w/o Expansion | 86.50 | 21.53 | 0.09 | 8.76 | |
| w/o Injection | 66.00 | 38.79 | 0.12 | 0.88 | |
| w/o Compression | 82.00 | 21.64 | 4.92 | 0.43 | |
| S-A With Door | Full | 84.00 | 21.55 | 0.42 | — |
| w/o Vision | 75.00 | 13.41 | 0.15 | -0.01 | |
| w/o Expansion | 84.50 | 22.07 | 0.09 | 13.37 | |
| w/o Injection | 31.00 | 44.05 | 0.10 | 0.64 | |
| w/o Compression | 72.00 | 22.36 | 48.17 | 0.34 | |
| D-A With Door | Full | 85.50 | 21.89 | 0.11 | — |
| w/o Vision | 73.50 | 13.24 | 0.11 | -0.30 | |
| w/o Expansion | 80.50 | 26.98 | 0.08 | 23.60 | |
| w/o Injection | 31.00 | 54.89 | 0.09 | -0.20 | |
| w/o Compression | 76.50 | 26.34 | 22.45 | -0.13 |
四类消融的 take-away:
- w/o Vision(用 VLM 生成的纯文字 scene graph 替代图):SR 平均掉 ~10pt——证实预压缩成文字会丢 task-relevant cue
- w/o Expansion(手动 post-hoc 加导航,符号域只管 manipulation):SR 几乎不变,但 plan quality 大幅下降(With-Door / Dual-Arm 下 RPQG 高达 23.6%)——unified domain 的价值在于联合优化导航与操作(如把开门和导航协同)
- w/o Injection(让 VLM 一把生成整个 PDDL problem 包括 topology):With-Door setting 下灾难性(SR 从 84-85% 掉到 31%),thinking time 翻倍——VLM 编码大规模 graph 结构能力极差,这是整个 paper 最 load-bearing 的 ablation
- w/o Compression(喂全图给 planner):planner time 从 0.42s 爆到 48s(With-Door / Single-Arm),触发 300s timeout——拓扑压缩对 tractability 是必需的
❓ “w/o Expansion” 的 SR 居然在 S-A No Door 比 Full 还高(86.5 vs 83.5),但 RPQG 8.76%——说明拆开做时容易找到 feasible 但 suboptimal 的解。这个 trade-off 值得思考:在简单场景,unified planning 反而引入了 optimal-but-fragile 的失败模式?
Failure Analysis
UniPlan 失败 ~16% 的分布:
- PDDL Grounding Errors (7.49%):VLM 识别物体正确但 misinterpret 状态(漏 init predicate),导致 unsolvable
- Perception Errors (3.69%):VLM 漏检物体或错认关系
- Retrieval Errors (3.06%):检索没召回所有相关节点
- Instruction Misunderstanding (2.03%):意图理解错
主要 bottleneck 是 visual state estimation——neuro-symbolic 架构成功隔离了 planning consistency 问题,把失败模式收敛到感知。
关联工作
基于
- UniDomain (NeurIPS 2025, Ye et al.):本文同一团队的前作,预训练了 large-scale tabletop PDDL 域。UniPlan 的 81 operators / 79 predicates 的 base 域来自它,可以视为其 mobile 扩展
- Fast Downward:用作 PDDL solver(seq-opt-lmcut engine)
- Unified Planning framework (SoftwareX 2025):用作 PDDL AST 操作工具
对比
- SayPlan (CoRL 2023, Rana et al.):collapsed scene graph + LLM 迭代规划,UniPlan 的主要 baseline——证明纯 LLM-on-graph 的 implicit reasoning 不如 symbolic planner
- DELTA (Liu et al. 2024):5-stage pipeline 用 LLM 生成 PDDL,UniPlan 论证其 LLM-generated domain 脆弱
- LLM as Planner:朴素 baseline,配上 UniPlan 的检索和压缩图作为 fair-share
方法相关
- 3D Scene Graph (ConceptGraphs、Hydra、Hydra-multi、KeySG 等):UniPlan 的 visual-topological map 是另一种环境表示——保留图像而非压成符号 graph
- Embodied-Reasoner (Zhang et al. 2025):纯 VLM 直接预测高层动作的 mapless 路线,UniPlan 的对立面
- VeriGraph / LookPlanGraph:用 SG 验证 LLM-generated plan,但仍以 LLM 为核心 reasoner——UniPlan 把核心 reasoning 完全交给符号 planner
论文点评
Strengths
- Factored construction 的设计非常 clean:把”什么放给 LLM/VLM、什么交给 deterministic 算法、什么程序化注入”切得很清楚,且 ablation 数据强力支撑(w/o Injection 崩到 31% 是这一架构最有说服力的论据)。这种 neuro-symbolic 的 division of labor 是有 transferability 的设计原则
- AST-based domain expansion 是真正”once and reusable”的工程:基于 semantic anchor 的 rewrite 不依赖具体源域命名,原则上能套用到任何 tabletop PDDL 域,比每来一个新场景手写域要 scalable
- Map compression 把 PDDL 求解搬到了实用 latency 区间:planner_time < 0.7s 让”PDDL solver 慢”这一传统反对意见不再成立,至少在 task-oriented compressed graph 上
- RPQG metric 设计合理:作者主动论证 SPL 在 SR gap 大时被 SR 主导、平均 step count 有 selection bias——只在双方都成功的任务上比 plan 长度,metric design 是过关的
Weaknesses
- 完全跳过低层执行:所有评估都假设”perfect low-level policy”,整套系统从未跑在真实机器人上。“task planning 解决了” 的 claim 在缺少 closed-loop 演示的情况下偏强。Failure analysis 也只覆盖 planning-side
- 单一环境 + 单一 base domain:43 pose / 18 room / 31 asset 是一个真实地图,但只有一个。Generality 段说原则上可换 base 域,但没有跨域、跨 building 的实验——“general programmatic extension” 的泛化性是 claim 而非 evidence
- Baseline 实现细节模糊:SayPlan 和 DELTA 都做了 adaptation(比如 DELTA 的 Domain Generation 被替换为 Domain Selection——这相当于给 DELTA 借用了 UniPlan 自己扩展好的域),是否完全 fair 难判断。SayPlan 在 With-Door / Single-Arm 只有 33% 与原文 setting 差距很大
- Bimanual 是 logically independent 的:双臂在 PDDL 里只是各自占用 hand,没有真正同步操作(如双手抬重物)的建模——作者 limitation 承认了
- 静态、完全可观环境假设:地图离线构建后假设不变,对动态/遮挡/object uncertainty 都不 robust——典型的 PDDL planning 老问题,作者承认但未解决
- GPT-5.2、N=4 的 reproducibility:依赖闭源模型 + 小样本统计,对独立复现是阻碍
可信评估
Artifact 可获取性
- 代码: 未说明
- 模型权重: 不适用(系统级方法,依赖闭源 GPT-5.2 + Fast Downward + Unified Planning framework)
- 训练细节: 不适用(无训练)
- 数据集: 50 个人类任务和地图——supplementary materials 提到完整 task list,但未说明是否公开
Claim 可验证性
- ✅ “UniPlan 在 4 settings 上平均 SR 83.75%“:emulator 自动评测、N=4 重复,标准差报告完整
- ✅ “Factored injection 是 critical”:w/o Injection 在 With-Door 下 SR 从 84% 掉到 31%,证据强
- ✅ “Compression 对 planner tractability 必需”:w/o Compression 下 T_plan 从 0.42s 爆到 48s
- ⚠️ “AST rewrite 可推广到任何 tabletop PDDL 域”:仅基于 UniDomain 测试,跨域泛化是推测
- ⚠️ “比 baseline 显著优”:baseline adaptation 后的复现细节有限,绝对数值难直接对照原 paper
- ⚠️ “通过解决 perception 可以进一步提升”:合理猜想但未实验
- ❌ 暂无明显 marketing 话术
Notes
- “VLM 局部 grounding + 符号 planner 全局 reasoning” 的分工是这篇 paper 最有 transferability 的 idea。值得问的下一步:能否把这套 factored injection 的设计原则套到 computer-use agent / GUI agent 上——把 UI 状态 grounding 给 VLM、长程任务规划交给某种符号 planner,避免 VLM 长链推理的 brittleness?
- Programmatic AST rewrite 让 manipulation 域 → mobile manipulation 域是 syntax-level 操作,对 learned domain 几乎免费——这暴露了一个 underexploited 的方向:学到的符号域可以被程序化扩展/组合,而不必每个新场景都重学。这与 VLA 那条强调”端到端 scaling”的路线形成对比
- 全文最弱的 claim:在没真机演示的情况下声称 “tackles long-horizon mobile manipulation”。Symbolic planning 的 sim-to-real gap 与端到端 policy 不同,但仍存在——感知误差、低层控制失败的累积都不在评估里。如果真机上 plan 执行成功率掉到 50%,“83% SR” 就是误导
- 一个开放问题:当 base domain 不是 UniDomain 这种”覆盖广、操作干净”的域时,AST rewrite 还能那么干净吗?如果原域里 anchor predicate 命名混乱、或 effect 不是简单的 add/delete,rewrite 规则的 robustness 会怎样?这是 generality claim 的真正考验
Rating
Metrics (as of 2026-04-24): citation=1, influential=0 (0.0%), velocity=0.42/mo; HF upvotes=N/A; github=N/A (无代码仓库)
分数:2 - Frontier 理由:这篇是 2026 年 2 月的新 arXiv,neuro-symbolic task planning 方向的代表前沿工作——factored PDDL construction (w/o Injection 崩到 31% 的 ablation) 和 AST-based programmatic domain expansion 是有 transferability 的设计原则,且明确与 SayPlan / DELTA / ConceptGraphs 这条主线对话。不够 Foundation 的原因:(1) 完全跳过低层执行,在真机上未验证,SR 数字的语义比 end-to-end VLA 工作窄;(2) 单一环境 + 单一 base domain (UniDomain),“general programmatic extension” 的 claim 还缺跨域证据;(3) 论文太新尚无社区采纳信号。不是 Archived 的原因:factored injection 的分工原则和 compressed topological map 对 PDDL latency 的改进是过硬的贡献,不是 incremental 也非 niche。