Summary
RoboInter: A Holistic Intermediate Representation Suite Towards Robotic Manipulation
- 核心: 构建大规模中间表示标注数据集(230k episodes, 10+ 类标注),并提出 plan-then-execute VLA 框架
- 方法: RoboInter-Tool 半自动标注 → RoboInter-Data(密集逐帧标注)→ RoboInter-VQA(2.3M VQA 样本训练 VLM)→ RoboInter-VLA(三种 plan-then-execute 变体)
- 结果: VLM Planner 在 RoboRefIt 上比 RoboBrain2.0 提升 76.8%;EC-E2E 实现 8.3% 最小 ID→OOD drop
- Sources: paper | website | github
- Rating: 2 - Frontier(系统性的中间表示数据+方法贡献,VLA 权重尚未释放、benchmark 尚未成为 de facto 标准,属重要参考但未到奠基档)
Key Takeaways:
- 数据规模与质量: 230k episodes、571 scenes、10+ 类中间表示的密集逐帧标注,是目前最大规模的操作中间表示数据集,且通过 human-in-the-loop 保证质量
- 中间表示的 granularity matters: Ablation 显示 trace(密集时序信息)带来最大性能提升,spatially grounded 表示(object box, affordance)远优于 coarse-grained 表示(subtask, skill)
- Explicit reasoning 提升 OOD 泛化: EC-E2E 的 ID→OOD drop 仅 8.3%(vs IC-E2E 的 19%),显式中间表示推理增强了分布外鲁棒性
Teaser. RoboInter 套件总览:数据、VQA、VLA 全流程

Introduction
现有操作数据集通常只提供视觉输入-指令-动作对,缺少 plan-then-execute 范式所需的细粒度中间表示。已有标注尝试要么规模有限(ShareRobot 仅 51k),要么全靠自动标注质量不可控(ECoT, LLARVA),要么覆盖的中间表示类型有限。
RoboInter 的核心贡献:
- RoboInter-Tool: 基于 PyQt5 的轻量级 GUI,支持半自动逐帧标注,集成 SAM2 分割追踪和 ChatGPT 辅助语言标注
- RoboInter-Data: 230k+ episodes,571 scenes,6 种机械臂,10+ 类中间表示的密集逐帧标注
- RoboInter-VQA: 9 spatial + 20 temporal VQA 类别,共约 2.3M 训练样本
- RoboInter-VLA: 统一的 plan-then-execute 框架,支持 IC-E2E / EC-E2E / Modular 三种变体
Dataset
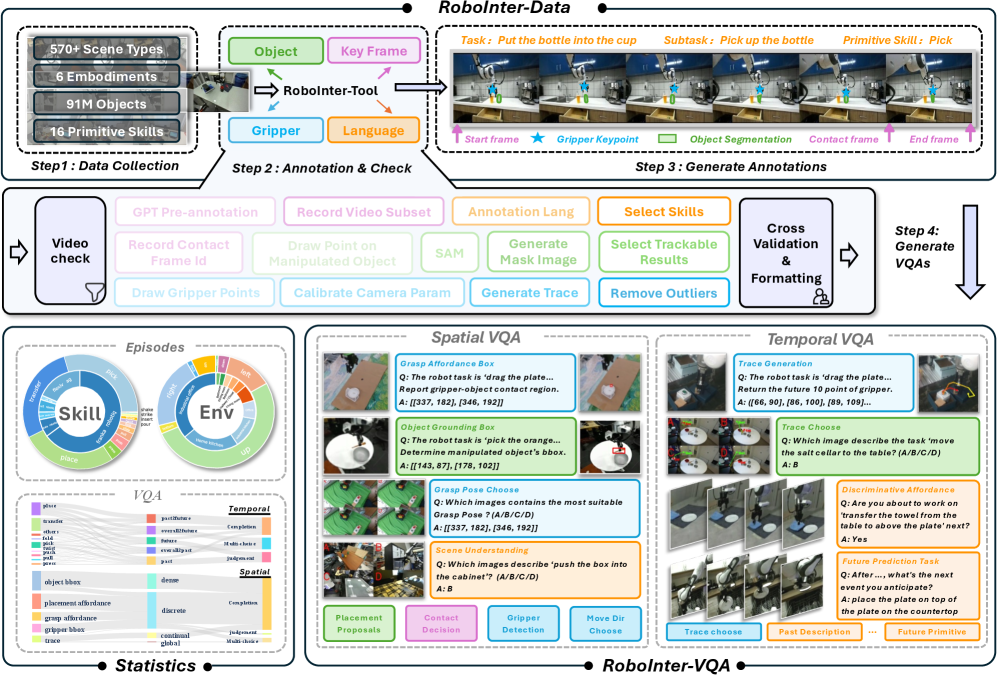
Figure 2. RoboInter-Data 和 RoboInter-VQA 总览
Video. RoboInter-Data 标注可视化 demo
RoboInter-Data
数据来源分两类场景:
- In-the-Wild(多样室内场景):主要来自 DROID 和 OXE,强调场景和指令多样性
- Table-Top(桌面交互):来自 RH20T,强调高质量和技能多样性
标注流程(通过 RoboInter-Tool):
- 任务分解与关键帧标注:视频按 15 种 primitive skills 分段,ChatGPT 生成初步语言标注参考,人工标注员审核修正
- 操作对象识别:标注交互对象后自动传给 SAM2 进行分割追踪,异步返回人工审核
- 末端执行器定位:通过标定矩阵估计 + gripper 检测 + point tracking 重建 2D trace
后处理衍生标注包括:grasp affordance box、contact points、grasp pose(6D EE pose)、placement 位置、gripper bounding box。
RoboInter-VQA
VQA 任务按两个维度组织:中间表示类型(spatial vs temporal)和目标能力(understanding vs generation)。
- Spatial Understanding: 选择题(object box / grasp pose / scene-instruction matching)+ 判断题(contact)
- Spatial Generation: 预测 object box、grasp pose、placement proposal、contact points、gripper box
- Temporal Understanding: gripper 运动方向、trace-description 匹配、subtask/primitive 判别、执行阶段识别、任务成功判断
- Temporal Generation: trace 生成(easy/hard)、多步规划、next-step 预测
Data Statistics
- 总量:230k episodes,6 种机械臂,571 种场景,15 种 primitive skills
- 标注量:约 61M 帧对象 grounding、约 70M 帧 gripper trace、190k affordance box & placement proposal、约 760k 语言 clip 标注
- VQA 数据量:约 1M spatial generation + 172k spatial understanding + 131k temporal generation + 935k temporal understanding
RoboInter-VLA
Figure 3. RoboInter-VLA 框架:Planner + Executor 的 plan-then-execute 范式

Model Architecture
Planner:采用 VLM 架构(Qwen-VL 系列 / LLaVA-OneVision),通过 VQA co-training 获取具身能力。支持单图和多图输入以捕获空间和时序信息,自回归生成输出,cross-entropy loss 优化。
Executor:基于 Qwen2.5-VL backbone + Diffusion Transformer (DiT) action head。使用 information aggregator 收集所有输入/输出 token 的 hidden states 及中间表示,压缩为可控长度的 conditioning features。消费多视角观测 + 语言指令 + 中间表示,通过 diffusion loss 生成多步 action chunks。
Plan-Then-Execute Paradigms
三种范式:
- RoboInter-IC-E2E(Implicitly-Conditioned):直接注入预训练 Planner 的 VLM 作为更强的 vision-language feature extractor,提供更鲁棒的具身感知
- RoboInter-EC-E2E(Explicitly-Conditioned):用 Planner 的 VLM 初始化 Executor,联合优化中间表示推理和动作生成
- RoboInter-Modular:非端到端层级设计,Planner 和 Executor 作为独立模块。训练时用 GT 中间表示,推理时用 Planner 预测的中间表示
Flexible Chain-of-Thought (F-CoT):由多种中间表示组合而成的 CoT,灵活组合 subtask, skill, object box, affordance box, trace 等,支持文本形式(Te-Modular)和视觉 prompt 形式(Im-Modular)。
Benchmarking and Experiments
Benchmarking the Planner
在第三方 benchmark 上,RoboInter-VLM 表现突出:
- RoboRefIt:RoboInter-Qwen-7B 达 85.6%,比 RoboBrain2.0-7B(8.8%)提升 76.8%
- RoboVQA:RoboInter-Qwen-7B 达 74.4,比 RoboBrain2.0-7B(31.6)提升 42.8%
- Where2Place:RoboInter-LLaVAOV-7B 达 66.3%
在 RoboInter-VQA 自有 benchmark 上,通用 VLM(含 GPT-4o-mini、Gemini-2.5-flash)在 spatial generation 类任务上普遍低于 40%,而 RoboInter-VLM 在各项上大幅领先。
Open-Loop Evaluation of the Executor
Table 5. 中间表示消融实验
| Variant | OLS@0.1 | OLS@0.05 | OLS@0.03 | OLS@0.01 | mOLS |
|---|---|---|---|---|---|
| Vanilla | 0.6793 | 0.3608 | 0.1753 | 0.0189 | 0.3086 |
| + Subtask | 0.6965 | 0.3676 | 0.1770 | 0.0171 | 0.3146 |
| + S. + Primitive Skill | 0.6983 | 0.3681 | 0.1779 | 0.0194 | 0.3159 |
| + S. + P. + Object Box | 0.7025 | 0.3849 | 0.1988 | 0.0294 | 0.3289 |
| + S. + P. + O.B. + Gripper Box | 0.7212 | 0.4032 | 0.2048 | 0.0272 | 0.3391 |
| + S. + P. + O.B. + G.B. + Affordance | 0.7245 | 0.4083 | 0.2114 | 0.0297 | 0.3435 |
| + S. + P. + O.B. + G.B. + Aff. + Trace | 0.7511 | 0.4640 | 0.2705 | 0.0587 | 0.3861 |
Insights: Coarse-grained 表示(Subtask, Primitive Skill)仅带来 marginal 提升(stage-level guidance,缺乏 actionable constraints)。Spatially grounded 表示(Object Box, Gripper Box, Affordance)带来更大提升。Trace 贡献最大,因为它提供了密集的 temporally grounded 信息。mOLS 从 0.3086(Vanilla)到 0.3861(全部表示),提升 25%。
关键对比结论:
- Pretrained Planner 持续提升 Executor:IC-E2E(0.3218)> Vanilla(0.3086)
- 显式中间表示优于隐式:EC-E2E(0.3340)> IC-E2E(0.3218)
- 解耦 planning 和 execution 进一步提升:Te-Modular(0.3543)> EC-E2E(0.3340)
Closed-Loop Real-World Evaluation of the Executor
Figure 5. 真实世界实验结果

在 Franka Research 3 上的四个长 horizon、contact-rich 任务上评估:
Table 6. 真实世界闭环性能
| Model | Objects Collect. (ID/OOD) | Cups Stack. (ID/OOD) | Towels Fold. (ID/OOD) | Clutters Clean. (ID/OOD) | ID→OOD Drop |
|---|---|---|---|---|---|
| OpenVLA | 53.3/20.0 | 66.7/33.3 | 26.7/6.7 | 33.3/33.3 | 21.7 |
| π₀ | 73.3/46.7 | 80.0/53.3 | 53.3/40.0 | 46.7/40.0 | 18.3 |
| Vanilla | 66.7/33.3 | 80.0/46.7 | 46.7/20.0 | 66.7/53.3 | 26.7 |
| IC-E2E | 86.7/53.3 | 86.7/60.0 | 60.0/46.7 | 73.3/73.3 | 18.4 |
| EC-E2E | 73.3/60.0 | 80.0/73.3 | 46.7/40.0 | 73.3/66.7 | 8.3 |
| Modular | 66.7/53.3 | 86.7/73.3 | 53.3/40.0 | 80.0/73.3 | 11.7 |
Insights: IC-E2E ID 平均 77.3%,Vanilla 65.0%,IC-E2E 的 pretrained VLM 提供更强感知先验。EC-E2E 虽然 ID 略低(68.3%),但 OOD 泛化更好,ID→OOD drop 仅 8.3%(IC-E2E 为 19%)。EC-E2E 的显式推理以 ID 精度换取 OOD 鲁棒性,这是有意义的 trade-off——OOD 的 ID-to-OOD drop 与 open-loop 结论一致。
关联工作
基于
- DROID: 主要原始数据来源之一(In-the-Wild 场景)
- RH20T: 主要原始数据来源之一(Table-Top 场景)
- SAM2: RoboInter-Tool 的核心分割追踪后端
- Qwen2.5-VL: VLM Planner 的主力 backbone
- LLaVA-OneVision: VLM Planner 的备选 backbone
- CogACT / InternVLA-M1: VLA 设计参考
对比
- ECoT: 自动标注 pseudo-intermediate,但仅文本 + object grounding,标注类型有限
- LLARVA: 用 pretrained gripper detector 生成 trace,对 distribution shift 敏感
- ShareRobot: 自动标注 + 人工审核,但规模小(51k)、标签与 step-wise actions 不对齐
- RoboBrain2.0: 具身 VLM,在 RoboRefIt 和 RoboVQA 上被大幅超越
- OpenVLA: 在闭环评估中被全面超越
- π₀: 在闭环评估中表现中等,IC-E2E 整体优于它
方法相关
- Diffusion Transformer (DiT): Executor 的 action head 架构
- Flexible Chain-of-Thought (F-CoT): 本文提出的多中间表示组合 CoT 机制
论文点评
Strengths
- 数据工程扎实:230k episodes 的多类别密集标注是重大的 infrastructure 贡献,human-in-the-loop 质量控制和多轮抽检保证了标注质量
- 系统性消融:对中间表示 granularity 的消融非常有信息量——从 coarse(subtask)到 fine(trace)的逐级叠加清晰展示了每类信息的边际贡献
- 三种 VLA 范式的统一对比:IC-E2E / EC-E2E / Modular 在相同数据和架构上的对比揭示了 implicit vs explicit reasoning 的核心 trade-off
- 开源完整:数据 + 标注工具 + VLM + benchmark 全部开源,可复现性高
Weaknesses
- 标注依赖已有数据集:RoboInter-Data 主要标注 DROID 和 RH20T 的已有数据,未收集新的 manipulation 数据,因此受限于原始数据集的场景和技能分布
- 闭环评估规模偏小:每个任务仅 15 次 ID + 15 次 OOD 试验,统计显著性有限
- VLA 未释放:截至目前 RoboInterVLA 模型尚未开源(TODO 列表中标为未完成),仅开源了 VLM Planner
- EC-E2E 的推理速度代价:EC-E2E 推理频率仅 2.56 Hz(即使带 caching),对实时性要求高的任务可能不够
可信评估
Artifact 可获取性
- 代码: inference+training 全流程开源(VLM 训练 + VLA 训练 + 标注工具 + dataloader)
- 模型权重: 已发布 RoboInter-VLM(Qwen-7B / Qwen-3B / LLaVA-OV-7B),safetensors + bf16;VLA 权重尚未发布
- 训练细节: 超参完整(Planner: lr=3e-6, batch=128, 1 epoch; Executor: lr=5e-5, batch=128, action chunk=15 steps)
- 数据集: 开源(RoboInter-Data 和 RoboInter-VQA 均在 HuggingFace)
Claim 可验证性
- ✅ “230k episodes with 10+ types of dense annotations”:数据集已公开可验证
- ✅ “RoboRefIt 上比 RoboBrain2.0 提升 76.8%“:第三方 benchmark,有具体数字和对比
- ✅ “EC-E2E 的 ID→OOD drop 仅 8.3%“:Table 6 有完整数据,但样本量偏小(15 trials)
- ⚠️ “Trace 是最有价值的中间表示”:ablation 是在 Oracle+Executor(GT 标注)设定下做的,实际推理时 Planner 预测的 trace 质量会影响最终效果,这个 gap 未被充分讨论
Notes
Rating
Metrics (as of 2026-04-24): citation=3, influential=0 (0.0%), velocity=1.25/mo; HF upvotes=0; github 125⭐ / forks=6 / 90d commits=26 / pushed 68d ago
分数:2 - Frontier 理由:RoboInter 以 230k episodes 的密集中间表示标注 + 三种 plan-then-execute 范式的统一对比构成系统性的 frontier 贡献,在 RoboRefIt / RoboVQA 等第三方 benchmark 上对 RoboBrain2.0 大幅领先(Strengths #2、#3)。未到 Foundation 档的原因是:VLA 权重尚未释放(Weaknesses #3),RoboInter-VQA 作为 benchmark 尚未被社区广泛采纳为 de facto 标准;未降到 Archived 则是因为数据集+工具+VLM 的开源组合对方向研究者而言是重要参考(Strengths #4)。