Summary
Diffusion Models Are Real-Time Game Engines
- 核心: 用 fine-tune 后的 Stable Diffusion v1.4 在单 TPU 上以 20 FPS 实时模拟 DOOM,整套游戏循环(状态更新 + 渲染)由神经网络代替手写引擎
- 方法: 两阶段——(1) PPO agent 自动玩 DOOM 收集 trajectory;(2) action-conditioned diffusion 做 next-frame prediction,noise augmentation 抑制 auto-regressive drift,decoder fine-tune 修复 HUD 细节
- 结果: 4 步 DDIM 即可达到 PSNR 29.4(接近 JPEG q20-30);人类区分真假游戏的准确率仅 58%-60%(接近 50% 随机),即便 5 分钟自回归后仍如此
- Sources: paper | website | github
- Rating: 3 - Foundation(首次工程化跑通 real-time + long-horizon + action-conditioned diffusion 作为可玩 game engine,noise augmentation trick 已成为后续 auto-regressive diffusion / video world model 工作的必引基线)
Key Takeaways:
- Real-time, long-horizon, action-conditioned diffusion 第一次被工程化跑通:不是更好的 video generation,而是闭环可玩的 game engine。20 FPS、多分钟稳定运行是新的 capability frontier。
- Noise augmentation 是 auto-regressive drift 的必要条件:训练时给 context frame 注入 Gaussian noise(最大 0.7),让 U-Net 学会”修正历史”。无此机制 LPIPS 在 10-20 帧后崩塌。
- 少步数推理在受限分布下成立:4 步 DDIM 与 64 步质量持平(PSNR 32.58 vs 32.19),原因是图像空间受限 + previous frames 强 conditioning。这是个值得 generalize 到 robotics world model 的观察。
- Agent-collected data >> random data,但只在中等难度区域显著:easy/hard 上差距小,medium 区域 agent 数据带来 +3.7 PSNR。data coverage 才是 bottleneck。
- 3 秒上下文跑出多分钟一致性:模型只看最近 64 帧(≈3.2s),但游戏 state(弹药、血量、地图位置)能通过像素 + 学到的启发式持续 minutes。模型实际上是在”重新推断状态”而非”记住状态”——这是个有趣但脆弱的 emergent behavior。
Teaser. Full DOOM gameplay simulated entirely by GameNGen at 20 FPS:
1. Problem Setup: Interactive World Simulation
作者把 game engine 抽象成 Interactive Environment :latent state、observation、rendering 函数 、action set、transition 。对 DOOM 来说, 是程序内存, 是渲染像素, 是渲染逻辑, 是按键。
Interactive World Simulation 的目标是学一个分布
最小化与真实环境之间的 observation distance 。两种 conditioning 模式区分得很清楚:
- Teacher forcing:context observation 来自真实 —— 训练用
- Auto-regressive:context observation 来自 自己上一步的输出 —— 推理用
这个 formulation 很 clean,把”游戏引擎能不能学”reduce 成一个 sequence modeling 问题。training-inference 分布偏移正是 §3.2.1 noise augmentation 要解决的核心。
2. GameNGen Method
整套方法两阶段串联:RL agent 收数据 → diffusion model 学 next-frame。
Figure 3. Method overview: agent 收 trajectory 喂给 diffusion model,diffusion model 用 noise-augmented past frames + action embedding 做 next-frame prediction。
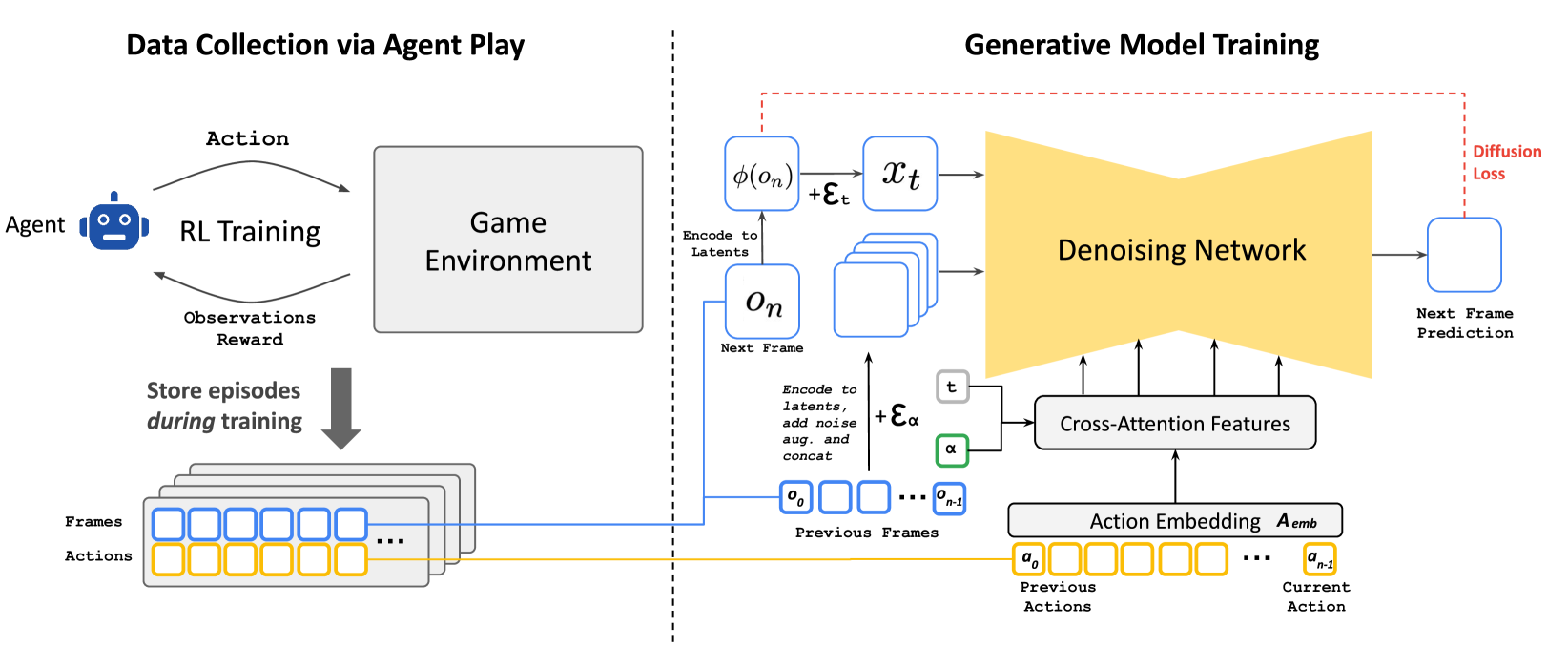
2.1 Data Collection via Agent Play
不直接用人类玩 —— 收集成本太高。而是训一个 PPO agent 自动玩 DOOM,记下整个训练过程的所有 trajectory(包括早期 random policy 阶段)。这样数据集天然覆盖从随机到熟练的多样行为。
- Reward 设计是唯一 game-specific 的部分(命中 -100、捡弹药 +5、捡武器 +5、kill +300,详见 Appendix A.5)
- Agent 训练 50M env steps,feature net 是简单 CNN(160×120 frame + 32 个 past actions)
- 不追求最高分,而是追求多样化的 state coverage
❓ 这个 reward 函数还是要人为设计的。论文标榜 “extracts gameplay” 但 agent 训练这一步本身需要可访问 game state(用 ViZDoom)来计算 reward。要真正做到”看视频学游戏”还差一层抽象。
2.2 Diffusion Model: SD v1.4 Re-purposed
Architecture
- Backbone: Stable Diffusion v1.4,所有 U-Net 参数解冻 fine-tune
- Action conditioning: 每个 action 学一个 embedding,替换掉原来的 text cross-attention
- Frame conditioning: 把 64 个 past frames 经 SD VAE 编码后,沿 latent channel 维度 concat 到 noised latent 上
- 所有 text conditioning 移除
- 训练用 v-prediction loss:
注:cross-attention 还是 channel-concat 喂 frame,作者尝试过两种,没看到显著差别——选了更简单的 concat。这是个值得记住的工程结论:在 SD-style 架构里,past frame 作为 dense 视觉条件更适合 channel concat 而非 cross-attention。
2.2.1 Noise Augmentation —— 解决 Auto-Regressive Drift
核心 trick,也是 paper 最重要的方法贡献。
问题:训练用 teacher forcing(context = ground truth),推理用 auto-regressive(context = 自己的 prediction)。这种分布偏移让误差累积,20-30 步后画面崩。
解法:训练时给 context frame 在 latent 空间加 Gaussian noise,noise level ,离散化成 10 个 bucket,把 noise level 也作为输入 embedding 喂给 U-Net。这样模型就学会”我看到的 history 可能是脏的,要从中恢复”。
Figure 4. 顶图:无 noise augmentation 时,50 帧的 stationary trajectory 在 20-30 帧后视觉质量崩塌;底图:加了 noise augmentation 后稳定。

这个 trick 跟 diffusion forcing 类的 “per-token variable noise” 思路是同源的,但实现极其简单——只在 context 上加均匀采样的 noise level,不需要改架构。属于”小 trick 撬动大 capability”的典型。
2.2.2 Latent Decoder Fine-tuning
SD v1.4 的 VAE 把 8×8 patch 压成 4 channel,对游戏 HUD(弹药数字、血条)这种小细节有可见 artifact。解法:只 fine-tune decoder(不动 encoder),用 MSE loss 对齐目标像素。
关键设计:encoder 不动,所以 auto-regressive 路径(latent → latent)完全不变;decoder fine-tune 只影响最后渲染。这个 separation 让 latent space 保持稳定。
2.3 Inference
- DDIM sampling,只用 4 步
- CFG only on past observations,weight 1.5(更大的 weight 在 auto-regressive 下放大 artifact)
- Action 不做 CFG(试过没用)
- 单 TPU-v5:每个 denoiser step 10ms,VAE decoder 10ms → 4 步 + decoder = 50ms/帧 = 20 FPS
- 1 步 distilled 版本可达 50 FPS,但质量略降
Table 1. Sampling step ablation。4 步已是 sweet spot,再加步数无收益。
| Steps | PSNR ↑ | LPIPS ↓ |
|---|---|---|
| D (distilled) | 31.10 | 0.208 |
| 1 | 25.47 | 0.255 |
| 2 | 31.91 | 0.205 |
| 4 | 32.58 | 0.198 |
| 8 | 32.55 | 0.196 |
| 16 | 32.44 | 0.196 |
| 32 | 32.32 | 0.196 |
| 64 | 32.19 | 0.197 |
“4 步够用” 这个结论作者归因于 (1) 受限的图像空间 + (2) 强的 frame conditioning。这是个对 robotics world model 很重要的观察:当 past observation 已经把分布约束得很窄时,diffusion 不需要很多 step。值得在 manipulation 视频生成场景验证。
3. Experimental Setup
- Agent: PPO,50M env steps,8 个 parallel ViZDoom,replay 512,γ=0.99
- Generative model: SD 1.4 fine-tune,batch 128,lr 2e-5,Adafactor,700k steps,128 个 TPU-v5e
- Data: 70M frames(agent training trajectories 的随机子集)
- Resolution: 320×240(pad 到 320×256)
- Context length: 64 frames + 64 actions(约 3.2 秒)
- Noise augmentation: max noise 0.7,10 个 bucket
- Decoder fine-tune: batch 2048
4. Results
4.1 Simulation Quality
Image quality (teacher-forced, single frame):
- PSNR 29.43, LPIPS 0.249 (holdout 2048 trajectories × 5 levels)
- PSNR 等价于 JPEG quality 20-30
Video quality (auto-regressive):
- 16 帧 (0.8s) FVD 114.02
- 32 帧 (1.6s) FVD 186.23
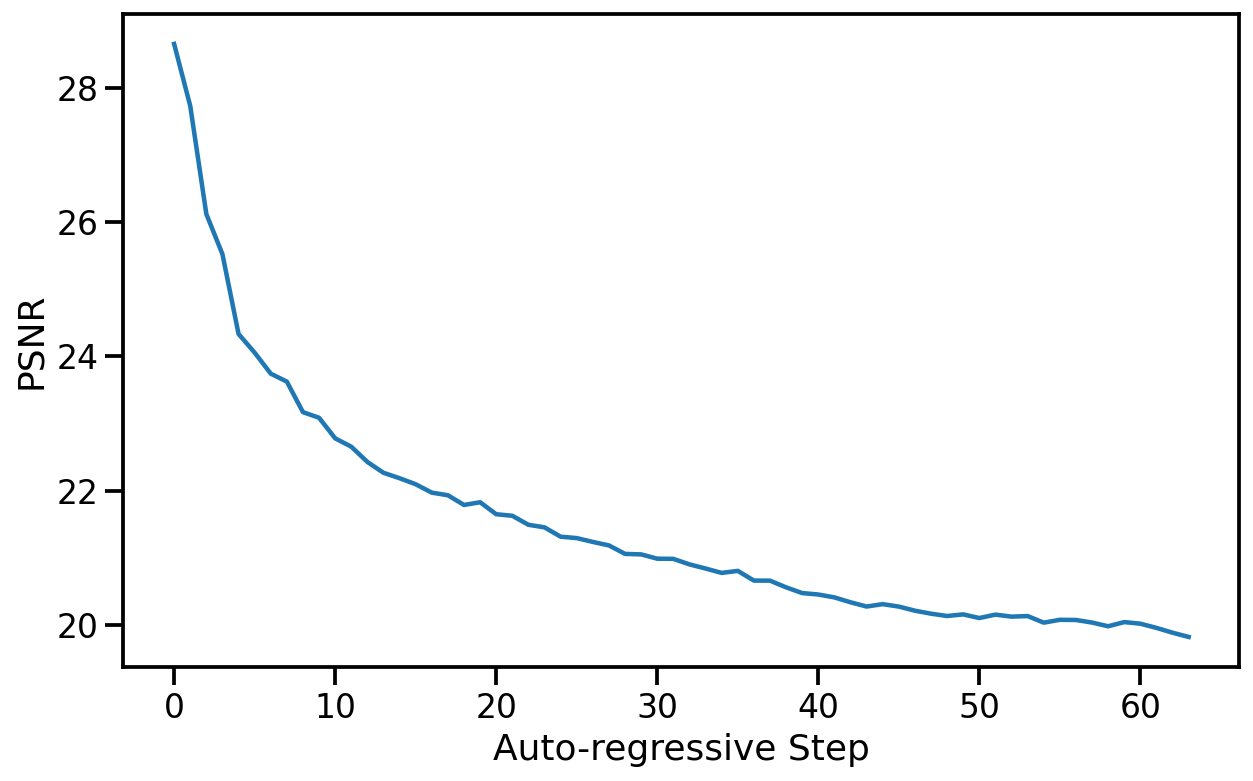
Figure 6. PSNR/LPIPS 随自回归 step 单调劣化但仍维持可用水平:
Human evaluation:
- 130 段 1.6/3.2 秒 clip,10 个 rater 区分真假游戏:accuracy 58% / 60%(50% = chance)
- 5-10 分钟 auto-regressive 后再做:accuracy 50%(仍随机水平)
- 但作者自己(熟悉 limitations)能在几秒内识别
❓ Human eval 的 setup 是 1.6-3.2 秒短 clip,而 5-10 分钟 evaluation 也只用 3 秒 clip。没有让 rater 实际 play——只是看视频判断真假。“Human raters fail to distinguish” 是个偏 generous 的 framing,因为短 clip + passive viewing 本来就掩盖了交互层面的不一致(比如开门后回头门是不是还在)。
4.2 Ablations
Context Length (Table 2)
| History | PSNR ↑ | LPIPS ↓ |
|---|---|---|
| 64 | 22.36 | 0.295 |
| 32 | 22.31 | 0.296 |
| 16 | 22.28 | 0.296 |
| 8 | 22.26 | 0.296 |
| 4 | 22.26 | 0.298 |
| 2 | 22.03 | 0.304 |
| 1 | 20.94 | 0.358 |
重要发现:1→2 帧跳跃最大,4 帧后基本饱和。论文坦承”3 秒 history 太短,需要换架构才能 scale memory”。这是 GameNGen 最尖锐的局限。模型实际上不是”记住了游戏状态”,而是”从最近 3 秒像素 + 学到的启发式重新推断”。
Noise Augmentation (Figure 7)
无 noise aug:LPIPS 在 10-20 帧后急剧上升,PSNR 暴跌。
有 noise aug:曲线平稳。这是 Section 3.2.1 的 ablation 实锤。
Agent vs Random Policy (Table 3)
| Difficulty | Policy | PSNR ↑ | LPIPS ↓ |
|---|---|---|---|
| Easy | Agent | 20.94 | 0.48 |
| Random | 20.20 | 0.48 | |
| Medium | Agent | 20.21 | 0.50 |
| Random | 16.50 | 0.59 | |
| Hard | Agent | 17.51 | 0.60 |
| Random | 15.39 | 0.61 |
Random policy 训出来的模型已经 surprisingly 好——在 easy 区域跟 agent 几乎打平。差距主要在 medium 区(agent 能进入但 random 探索不到的地方)。
Insight:data coverage > data quality。如果有更强的 exploration policy(比如 RND-style intrinsic reward),可能能更进一步。
5. Out-of-Distribution Editing (Appendix A.4)
把游戏中的 frame 用图像编辑器手动改一下(塞个怪物、加堵墙),然后用作 history buffer 启动生成。模型能:
- 把陌生位置的角色”接住”,让它移动、攻击、造成伤害
- 把陌生 layout 渲染成 navigable 场景
这是迈向 “用神经网络生成新游戏” 的一个 hint,但作者自己也说这只是 preliminary。
关联工作
基于
- Stable Diffusion v1.4 / Latent Diffusion (Rombach et al., 2022): backbone,channel-concat past frames + replace text cross-attn with action embedding
- PPO (Schulman et al., 2017): RL agent for data collection
- DDIM (Song et al., 2021): 4-step inference sampler
- v-prediction (Salimans & Ho, 2022): diffusion loss parameterization
对比 / 此前 game simulation 工作
- World Models (Ha & Schmidhuber, 2018): VAE + RNN 模拟 ViZDoom,分辨率/质量低,主要用于 RL imagined rollout
- GameGAN (Kim et al., 2020): LSTM + adversarial loss 模拟 PacMan/VizDoom,无 long-horizon 一致性
- GAIA-1 (Hu et al., 2023): driving 场景的 transformer + diffusion world model,420M images 训练
- DIAMOND (concurrent, Alonso et al., 2024): 同期 diffusion world model,用于 Atari 训 RL agent
方法相关 (auto-regressive diffusion)
- Diffusion Forcing (Chen et al., 2024): independent per-token noise level,理论框架更通用
- Per-token / sliding-window 变 noise level 方法: 与 GameNGen 的 noise augmentation 同源思想,但实现更复杂
后续 / 可联系
- Genie: 从无标注视频学 latent action,方向上是 GameNGen 的 “data collection 不依赖 game-specific reward” 答案
- World Model Survey: GameNGen 是 video-game-as-world-model 范式的代表
- Gen World Renderer / HYWorld2: 更近期的 large-scale interactive world simulator,可对比看 memory/context 问题如何被解决
论文点评
Strengths
- 新 capability frontier,不是 +0.3% SOTA:第一次让 diffusion model 实时驱动一个 complex game engine。20 FPS + 多分钟稳定 + visual quality ≈ original,三个维度同时达成在此前的 world model 工作里没人做到(GameGAN、World Models 都是 toy 视觉 + 短序列)。
- Noise augmentation trick 简洁普适:3 行代码级别的改动解决 auto-regressive drift。机制清晰(让模型学会从 noisy history 恢复),跟 diffusion forcing / sliding-window denoising 等更复杂的方案是同一类思想的极简实例。可直接 transfer 到任何 auto-regressive diffusion 应用。
- “4 步够用”的工程证据:在受限 + 强 conditioning 的场景下,diffusion 的 inference cost 不是瓶颈。这对 robotics world model(VLA 内部 imagined rollout)有直接启示。
- 诚实的 ablation:context length ablation 直接暴露了最大局限(3 秒不够),没有藏起来。
- Reproducibility 友好:所有 backbone(SD 1.4)+ environment(ViZDoom)+ training detail 都开源/详细。
Weaknesses
- 不是 “neural game engine”,是 “neural game player”:模型只能模拟训练数据里见过的游戏(DOOM)。无法用 textual/image input 创建新游戏,也无法在新规则下泛化。论文标题 “Real-Time Game Engines” 略 overclaim——更准确的描述是 “real-time learned simulator of a specific game”。
- 3 秒上下文是结构性瓶颈:当前架构 scale context 收益快速饱和(Table 2)。要做更复杂的游戏(RPG、策略游戏,甚至 DOOM 的复杂关卡)需要换架构(recurrent state?compressed memory?),这是 paper 之后所有跟进工作的核心难题。
- Reward function 仍 game-specific:data collection 这一步不是 self-supervised 的——必须能访问 game 内部状态来设计 reward。从”看 YouTube 视频学游戏”还差很远。
- Human eval setup 偏 generous:只让 rater 看短 clip 而不让其交互。交互层的不一致(state inconsistency over actions)没被测到。authors 自己承认”几秒就能识破”,说明 50% accuracy 数字有 framing bias。
- Action space 简单:DOOM 是 discrete keypress,每个 action 学一个 embedding 即可。换成 continuous control(鼠标位置、joystick)需要重新设计 action conditioning,未必能 plug-and-play。
- 70M frames + 128 TPU 训练成本:复现门槛高,社区 unofficial impl 至今很难达到原文质量。
可信评估
Artifact 可获取性
- 代码: 未开源(github 仓库只放 project page,没有 training/inference code)
- 模型权重: 未发布
- 训练细节: 完整披露——超参(lr 2e-5, batch 128, max noise 0.7, 10 buckets, 64 context, 700k steps)、数据规模(70M frames)、硬件(128 TPU-v5e)、agent 配置(PPO + reward function in Appendix A.5)都齐全
- 数据集: ViZDoom 环境开源,但作者收集的 70M trajectory 数据集未公开
Claim 可验证性
- ✅ 20 FPS 实时性 + 多分钟稳定: 项目页面 supplementary video 直接展示多分钟连续 gameplay,可肉眼验证
- ✅ Noise augmentation 是 drift 抑制必要条件: Figure 4 + Figure 7 ablation 严格对照,结论硬
- ✅ 4 步 DDIM ≈ 64 步质量: Table 1 数字明确
- ⚠️ Human raters at chance level: passive 短 clip evaluation,不覆盖交互一致性。作者自己承认能识破,说明 setup 对 model 友好。“接近随机”的 framing 应该打折读
- ⚠️ PSNR 29.4 ≈ JPEG q20-30: 数字本身没问题,但 JPEG 等价 framing 容易让人忽视——这只是 single-frame teacher-forced 的指标,auto-regressive 下持续下降(Figure 6)
- ❌ “First game engine powered entirely by a neural model”: marketing 修辞,World Models (Ha & Schmidhuber 2018)、GameGAN (Kim et al. 2020) 早就做过 game simulation。“first” 仅在 “real-time + complex + long-horizon” 三个修饰词同时满足下成立——但论文 abstract 直接 strip 了修饰,容易误读
Notes
- 方法学启示:noise augmentation 是个值得放进自己工具箱的 trick。任何需要 auto-regressive rollout 的 diffusion 应用(diffusion policy 在 manipulation 中的 multi-step rollout、video diffusion 长视频生成、VLA 的 imagined trajectory)都可以试。
- 对 robotics world model 的启示:(1) 4-step DDIM 在受限 + 强条件下够用——manipulation video prediction 可能不需要那么多 step。(2) data coverage 决定 simulation 边界——agent-collected > random,但需要更强的 exploration 才能进一步突破。
- 3 秒上下文限制 = open problem:这是后续工作的金矿。compressed memory(learned latent state)、retrieval-based context、explicit world state encoder 都是可能方向。
- 范式判断:GameNGen 是 “rendering as generation” 范式的概念证明,不是 “game design as generation”。要让神经网络真正 “create” 游戏,需要 (a) 从无标注视频学 action(Genie 方向),(b) text/image-to-game 的高层 control,(c) 跨游戏的 generalization。GameNGen 证明了下游 — neural rendering 部分 — 可行。
Rating
Metrics (as of 2026-04-24): citation=200, influential=17 (8.5%), velocity=10.05/mo; HF upvotes=126; github 91⭐ / forks=9 / 90d commits=0 / pushed 603d ago · stale
分数:3 - Foundation 理由:按 field-centric rubric,GameNGen 是 video-game-as-world-model / auto-regressive diffusion 方向的奠基工作。Strengths (1) 指出它首次在 real-time + long-horizon + visual-quality 三维同时跑通 neural game engine,是此前 GameGAN/World Models 都未达到的 capability frontier;Strengths (2) 的 noise augmentation trick 已被后续 auto-regressive diffusion / video world model 工作普遍采纳为标准组件,ICLR 2025 oral 发表后 citation 持续攀升、被 DIAMOND 等并列视为 diffusion world model 的代表性 baseline。相比 2 - Frontier 档(“当前 SOTA / 重要 baseline 但未奠基”),GameNGen 的影响已外溢到 robotics world model 的 inference-cost 讨论和 long-horizon diffusion rollout 设计,属于方向主脉络的必读必引工作。