Summary
Skill0: In-Context Agentic Reinforcement Learning for Skill Internalization
- 核心: 把 agent skill 从 inference-time prompt 注入挪到 training-time scaffold——通过课程化退火让 RL 把技能逐步”内化”进参数,inference 时彻底丢掉 skill 上下文
- 方法: In-Context RL (ICRL) + Dynamic Curriculum——按 helpfulness filter & rank skill 文件,配合线性衰减预算 三阶段退火至 0;context 走 OCR 视觉压缩
- 结果: Qwen2.5-VL-3B 在 ALFWorld 87.9 / Search-QA 40.8,比 AgentOCR 分别 +9.7 / +6.6;inference token <0.5k/step(SkillRL 2.21k/0.87k)
- Sources: paper | github
- Rating: 2 - Frontier(把 skill internalization 做成可优化训练目标,helpfulness-driven curriculum 是 elegant 机制创新;但依赖高质量初始 SkillBank、7B 上增益收窄,尚未到 de facto 奠基)
Key Takeaways:
- Skill internalization 作为显式训练目标:第一次把”训练时给 skill / 推理时不给”做成一个完整的 RL 框架,把 prompt 里的程序化知识强制压回参数
- Helpfulness 驱动的自适应退火:不是按固定 schedule 衰减 skill,而是用 with/without skill 的 validation accuracy 差 决定每个 skill 还该不该留——已内化的自动 被淘汰
- OCR 视觉上下文压缩 + skill 内化叠加:单步 token <0.5k 同时维持 SOTA 性能,验证两个 orthogonal 的 context 压缩思路可叠
- w/o Rank 消融崩盘 (-13.7%):证明”留对 skill”比”留几个 skill”更关键,随机选会污染策略学习
Teaser. Skill Augmentation vs Skill Internalization 范式对比。 左侧传统 skill augmentation 在每个推理 step 都从 skill bank 检索注入;右侧 Skill0 在训练时给 skill scaffold,推理时模型独立行动。
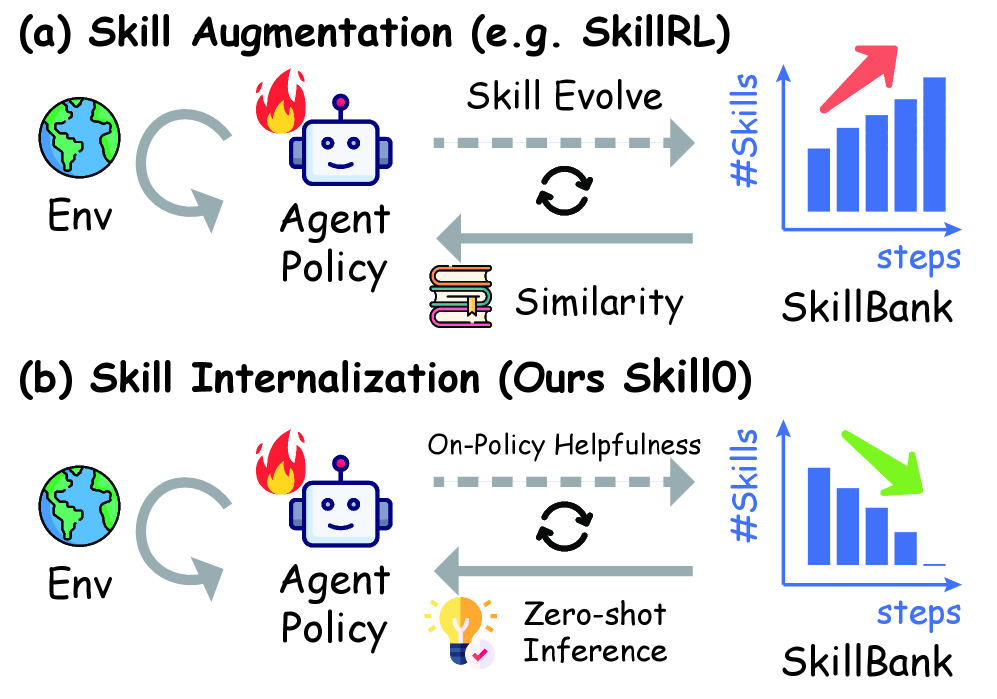
1. Motivation:为什么不”读”skill 而是”学”skill
Inference-time skill augmentation(retrieve skill → 拼到 prompt)是当下 LLM agent 的主流范式,作者指出三个根本性问题:
- Retrieval noise:检索到无关 skill 反而污染 context
- Token overhead:skill 文本随 multi-turn 累积,scaling 困难
- 能力寄存在 context 而非参数:模型在”执行”skill 而非”掌握”skill——一旦 retrieval 失效,策略瞬间退化
类比人类技能习得:从 explicit instruction phase → internalized phase。Augmentation 把 agent 永久锁在第一阶段。RL 是通往第二阶段的自然路径,但 naive RL 两边都不讨好:
- 不给 skill:缺乏结构化指引,复杂多步行为学不会
- 全程给 skill:模型从来没被逼着去内化
❓ 这里的论证有点跳——“naive RL 不给 skill 学不会复杂行为”的证据其实就是后面 GRPO baseline 的曲线。但 GRPO 在 ALFWorld 也能到 79.9%,说明 naive RL 并非完全不 work,只是 plateau 较早
需要的是一种”先给后撤”的训练 regime——这就是 Skill0。
2. Method:Skill0 框架
2.1 Agent Loop 与 Skill Bank
任务定义为标准 sequential decision-making:策略 ,环境返回观察 。
Skill 组织成两级结构:
- General skills:跨任务策略原则(如 exploration、goal-tracking)
- Task-specific skills:按
skills/{task_name}/{skill_category}.md组织,例如skills/search/entity_attribute_lookup.md
完整 SkillBank 共 个文件。训练时不按 semantic similarity 检索,而是按 on-policy helpfulness 选 个 skill 文件。
2.2 Context Rendering:OCR 视觉压缩
继承 AgentOCR 的思路,把文本 context( + 选中的 )渲染成压缩 RGB 图:
关键是 compression ratio 由策略自己生成——和 action 一起 sample:。这给了策略主动权衡 token 成本和信息保留的能力。
Figure 2. Skill0 总览。 (a) Relevance-Driven Skill Grouping 离线把验证子集 partition 成 ;(b) ICRL 训练 loop,skill scaffold 进入 visual context;(c) Dynamic curriculum 三阶段退火预算。
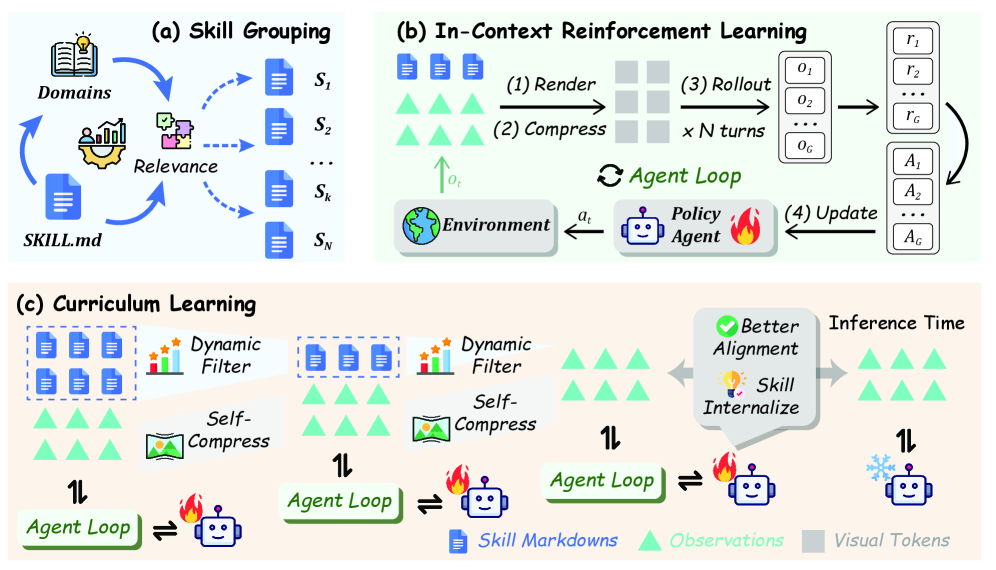
2.3 In-Context Reinforcement Learning (ICRL)
核心训练 loss 是 GRPO 风格的 group-normalized PPO + KL:
复合奖励兼顾任务成功和压缩效率:
只有任务成功才给压缩奖励——避免策略为了省 token 牺牲 success rate。 形式反映 diminishing return。
2.4 Dynamic Curriculum:核心创新
线性预算衰减
个阶段,每阶段最大 skill 数:
step-wise 衰减约 ,最终 。线性而非陡降是为了避免 visual context 分布的 abrupt shift(Appendix A 给了 Lipschitz 风格的 KL bound 论证)。
Helpfulness 评估
每 训练步,对每个 skill 在配对子任务 上做对照评估:
然后三步:
- Filter:丢掉 (已内化或无用)
- Rank:按 降序
- Select:取 top-
ALFWorld 实际预算为 ,Search-QA 为 。
❓ Helpfulness 评估的成本不小——每 步要在所有 个子任务上跑两次 validation。论文说 是最优 trade-off,但没给完整的 wall-clock 训练成本对比
3. Experiments
3.1 Setup
- Backbone:Qwen2.5-VL-3B / 7B-Instruct
- Benchmarks:ALFWorld(6 类家务任务,文本游戏对齐 ALFRED)+ Search-QA(NQ/TriviaQA/PopQA 单跳 + HotpotQA/2Wiki/MuSiQue/Bamboogle 多跳)
- 训练:4× H800,最多 180 steps;ALFWorld batch 16 tasks × 8 rollouts,Search-QA batch 128 tasks
- 课程:,validation subset = 1000,SkillBank 来自 SkillRL
- Baselines:Zero/Few-Shot、GRPO、AgentOCR、EvolveR、SkillRL;外加 GPT-4o、Gemini-2.5-Pro、Mem0、ExpeL、Search-R1、ZeroSearch 等
3.2 主结果
Table 1. ALFWorld 与 Search-QA 主结果(节选 3B/7B 代表性 baseline)。 表示推理时仍用 skill; 表示 OCR 压缩。
| Method | ALFWorld Avg | ALFWorld Cost | Search-QA Avg | Search-QA Cost |
|---|---|---|---|---|
| Qwen2.5-VL-3B Few-Shot | 29.3 | 2.30k | 17.9 | 0.86k |
| GRPO (3B) | 79.9 | 1.02k | 36.4 | 0.61k |
| AgentOCR (3B) | 78.2 | 0.38k | 34.2 | 0.26k |
| SkillRL (3B) | 82.4 | 2.21k | 38.9 | 0.87k |
| Skill0 (3B) | 87.9 | 0.38k | 40.8 | 0.18k |
| GRPO (7B) | 81.8 | 0.95k | 41.9 | 0.73k |
| AgentOCR (7B) | 81.2 | 0.43k | 40.1 | 0.36k |
| SkillRL (7B) | 89.9 | – | 47.1 | – |
| Skill0 (7B) | 89.8 | 0.41k | 44.4 | 0.34k |
3B 上:相对 AgentOCR (同 OCR 范式) +9.7 / +6.6;相对 SkillRL(推理时仍依赖 skill)+5.5 / +1.9,且 token cost 是后者的 ~1/5。7B 上相对 SkillRL 略低 (-1.4 在 ALFWorld, -2.7 在 Search-QA) 但 SkillRL 推理时还在用 skill,Skill0 不用——属于不同推理预算下的可比。
❓ 7B Skill0 在 Search-QA 上不及 SkillRL 和 EvolveR——会不会规模上去后内化的边际收益就被 retrieval 的 specificity 反超?需要 13B/30B 才能确认 trend
3.3 Training Dynamics
Figure 5. 训练动态对比。 (a) Skill0 用 vs 不用 skill 验证:用 skill 早期更快,不用 skill 后期追平——典型的内化曲线。(b) 在 skill-free inference 设定下,Skill0 全程超 AgentOCR。(c) 同设定下 Skill0 持续上升,而 GRPO/SkillRL 早早 plateau。
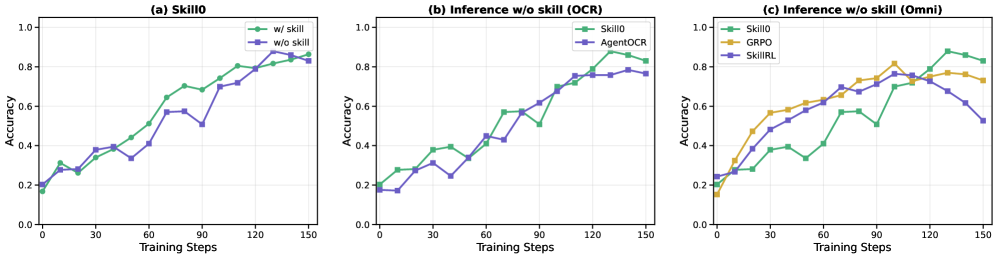
(c) 这条很关键:标准文本 RL(GRPO/SkillRL)在 skill-free inference 下早期就 plateau,而 Skill0 持续提升至最高 upper bound——说明 ICRL 的训练-内化机制确实在抽取额外信号。
Figure 6. Helpfulness 训练动态。 呈现 rise-then-fall pattern:早期策略不会用 skill () → 中期学会用 ( 上升) → 后期内化完成 ( 回落至 0)。Curriculum 自然把这些 skill 自动淘汰。
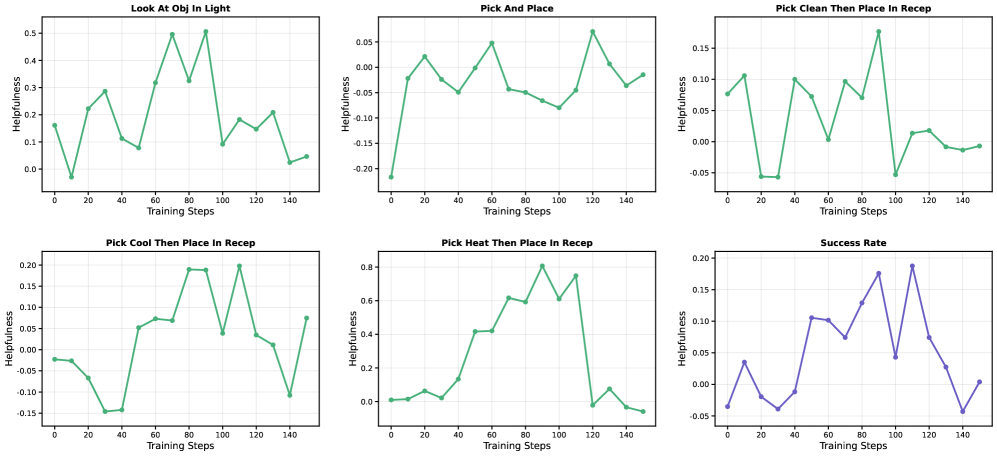
这是文章最优雅的实证——skill 不是被人工 schedule 移除的,而是因为”已经学会了所以 helpfulness 归零”被自动 filter 掉。从机制角度证伪了”skill 一直留着也无害”的直觉。
3.4 Ablations
Figure 7. Skill Budget M 消融(OCR 设定,ALFWorld)。比较 vs 、、、Fixed Full。
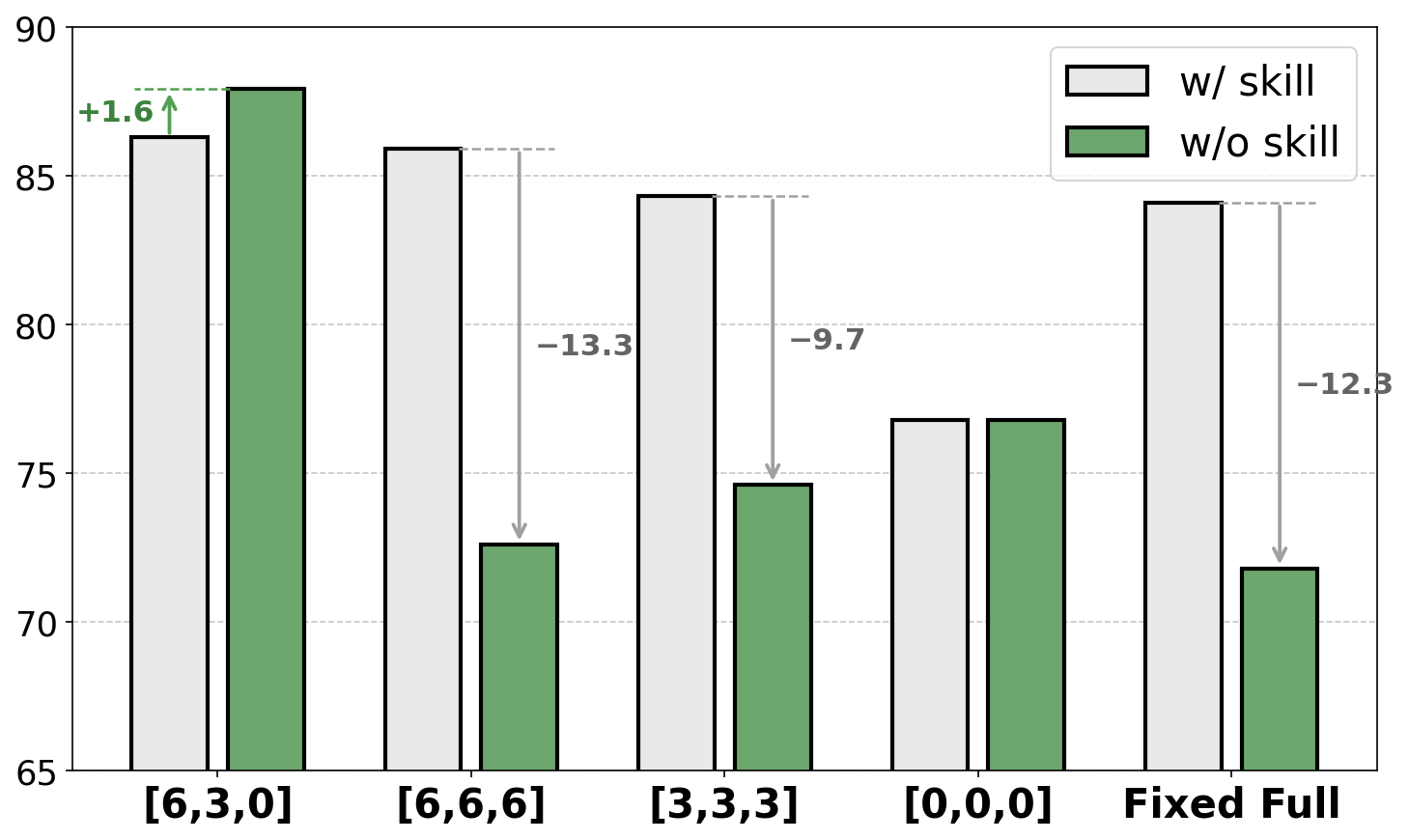
Table 2. Dynamic Curriculum 三步策略消融(ALFWorld)。
| Method | w/ | w/o | |
|---|---|---|---|
| Filter & Rank & Select | 86.3 | 87.9 | 1.6 |
| w/o Filter | 81.6 | 78.9 | 2.7 |
| w/o Rank | 76.6 | 62.9 | 13.7 |
只有完整三步策略在 inference 时撤掉 skill 后性能反升 (+1.6)——这是”成功内化”的硬指标。w/o Rank(随机选 skill)后塌 13.7 分,证明保留正向 skill 而非任意 skill 才能稳定策略学习。
固定预算 的 inference 性能塌 13.3 分,验证”全程给 skill”会 induce skill over-reliance——完全符合 motivation 中的批判。
Table 3. Validation Interval 消融。
| ALFWorld | Search-QA | |
|---|---|---|
| 5 | 87.5 | 49.6 |
| 10 | 87.9 | 48.9 |
| 20 | 78.1 | 42.3 |
性能急剧下降——课程更新太慢,策略在过时 skill set 上 over-fit。
4. SkillBank 内容(Appendix E)
代表性 skill 文件示例(结构化 procedural knowledge):
| Skill 类别 | Principle | When to Apply |
|---|---|---|
| ALFWorld/general → Systematic Exploration | 每个 plausible 容器搜一次再回访 | 目标未达且仍有未探索区域 |
| ALFWorld/clean → Phase-Ordered Plan | 固定执行:定位/获取 → 水池清洗 → 导航 → 放置 | 目标要求物体清洗后放置 |
| Search/general → Decompose Then Search | 拆分子问题,每个用独立 query | 任意复杂或多跳问题 |
| Search/multi_hop_reasoning → Collect-Then-Compare | 先取所有值再比较 | 涉及日期、地点、数量的对比任务 |
skill 是高度结构化、人工 curated 的”行动启发式”——这也是 limitation 之一:依赖初始 SkillBank 质量,新 domain 需要重新 group。
5. Theoretical Analysis(Appendix A)
线性预算下,相邻阶段的 visual context 偏移和策略 KL 发散都有 Lipschitz 上界:
并在加性效用近似下, greedy top- 选择是局部最优:
❓ 这个加性近似在多 skill 互补/冲突时会破——比如两个 skill 单独 helpful 但叠加产生矛盾指令。论文没讨论这种 interaction,实践中是否真有这种 case?
关联工作
基于
- AgentOCR (2601.04786):OCR-based visual context 压缩、复合奖励 的形式、prompt rendering 配置都直接继承
- SkillRL:SkillBank 的初始内容直接复用;本文是 SkillRL 的”内化版”——SkillRL 推理时仍依赖 skill,Skill0 把它干掉
- GRPO:基础 RL 算法(group-normalized advantage + clip + KL)
- GiGPO:ALFWorld 训练数据 split 来源
对比
- EvolveR:通过 evolution 改进 skill 库,仍是 augmentation 范式;7B Search-QA 上仍领先 Skill0 (43.1 vs 44.4 接近)
- Mem0 / ExpeL / MemRL / MemP / SimpleMem:memory-augmented agent,存原始 trajectory,本文用 distilled skill 而非 raw history
- Search-R1 / ZeroSearch / O²-Searcher / StepSearch:search-augmented RL,本文在 multi-hop QA 上显著超出(尤其 Bamboogle 63.7 vs Search-R1 26.4)
- ReAct / Reflexion:prompt-based agent baseline,作为 SkillBank-free 的下界对照
- GPT-4o / Gemini-2.5-Pro:闭源大模型 baseline,3B/7B Skill0 在 ALFWorld 上反超(87.9/89.8 vs 48.0/60.3)——但这更多反映 ALFWorld 的特定结构而非通用能力
方法相关
- Curriculum Learning:核心是 helpfulness-driven adaptive curriculum,与传统 difficulty-based curriculum 正交
- In-Context Learning → Internalization:与 RLHF/RLVR 的”指令跟随→内化偏好”机制类比;可能跟 distillation-style 训练有共通点
- Procedural Memory:Skill 作为 procedural knowledge 的载体,与认知科学的 declarative/procedural memory 区分相关
论文点评
Strengths
- 问题 formulation 干净:把”skill internalization”作为可优化的训练目标——之前的 skill 工作几乎都在 retrieval / organization / evolution 上打转,这篇正面回应”skill 能否被学到参数里”
- Helpfulness-driven curriculum 是 elegant 设计: 用 with/without 对照量化每个 skill 对当前策略的剩余价值,自然实现”已学会的自动淘汰”。Figure 6 的 rise-then-fall 是漂亮的机制证据
- 可叠加性强:OCR 压缩(context 维度)+ Skill internalization(知识维度)正交叠加,1/5 的 token cost 维持 SOTA
- Ablation 充分:Skill Budget、Filter、Rank、Validation Interval 四个维度都有对照;尤其 w/o Rank -13.7 这个 negative result 把 “rank by helpfulness” 的必要性证得很硬
Weaknesses
- 依赖高质量初始 SkillBank:Skill 来自 SkillRL 的人工 curated 库;新 domain 需要重新 partition 子任务并 curate skill 文件,scaling 到 open-world 不显然
- Helpfulness 评估开销未量化:每 步要在所有 个子任务上跑双倍 validation rollout,但论文没报 wall-clock training cost 对比
- 7B 上对 SkillRL 的优势收窄:Search-QA 上 Skill0 (44.4) < SkillRL (47.1);论文用 token cost 解释,但需要更大模型实验确认 internalization 收益是否随 scale 衰减
- 课程阶段数 缺敏感性分析:为什么 3 而非 5/10?表 4 里有 (即 )的结果更差 (-16.0),但只一个 budget 不能下定论是 的问题还是衰减速率的问题
- Limitation 部分非常单薄:只承认”依赖 SkillBank 质量”,回避了 skill interaction、helpfulness 噪声放大、长尾任务覆盖等更深的问题
可信评估
Artifact 可获取性
- 代码:inference + training 完整开源(ZJU-REAL/SkillZero),含 ALFWorld 和 Search-QA 的训练脚本与数据预处理
- 模型权重:未在 README 或论文中明确发布 checkpoint
- 训练细节:超参完整(180 steps、4× H800、batch size、prompt length、、),SkillBank 直接复用 SkillRL 的开源版本
- 数据集:开源(ALFWorld、Search-R1 数据 pipeline 完整给出,含 retrieval index 下载脚本)
Claim 可验证性
- ✅ ALFWorld +9.7 / Search-QA +6.6 over AgentOCR:完整训练脚本 + 公开 baseline 实现,可复现
- ✅ Token cost <0.5k/step:OCR 渲染机制透明,可独立测算
- ✅ Helpfulness rise-then-fall pattern (Figure 6):训练动态曲线 + 完整算法描述,可复现
- ✅ w/o Rank 崩盘 -13.7%:硬 ablation,机制解释清晰
- ⚠️ “skill internalization 是 RL 的自然路径”:motivation 中的人类技能习得类比偏 narrative,缺脑科学/cognitive science 的硬 grounding——把它当作 inductive bias 而非 truth
- ⚠️ “training-inference gap” 的解释(Section 4.4 Skill Budget 部分):固定 性能塌的原因可能不止”over-reliance”,也可能是 visual context 分布在 inference 时彻底改变。论文没区分这两个 confounder
Notes
- 这篇的 “rise-then-fall helpfulness curve”(Figure 6)是过去半年 agentic RL 领域少见的清爽机制证据。值得收进 mental model:当训练目标包含一个”逐步可移除的 scaffold”,scaffold 的 utility 应该是单峰的——上升 → 内化 → 下降。这可以反过来作为”是否真的 internalize”的诊断指标
- ICRL 的设计哲学(训练时给 / 推理时撤)跟 π0 / VLA 里的 KI(Knowledge Insulating)有相似的 motivation:都是想”让某些信号只在训练时起作用”。但 KI 是冻结模块,Skill0 是 anneal context——Skill0 更轻量,但需要 helpfulness signal 来驱动
- 一个有意思的延伸:能不能把 Skill0 的 helpfulness-driven annealing 用到 chain-of-thought / reasoning trace 上?给训练时的 CoT scaffold,推理时撤掉,强迫模型把推理内化到隐藏状态——这跟 latent reasoning / quiet-STaR 的思路 converge
- ⚠️ 实际部署中 “新 domain 重新 partition skill” 是非常重的限制。如果想 scale 到 open-world agent,需要某种自动 skill grouping 机制(用 LLM 离线 cluster?),这部分论文完全没碰
- Search-QA 上 Bamboogle 异常高(3B: 63.7 vs Search-R1 26.4,差距 +37.3)。这种巨大 gap 在主表里没单独讨论,可能是 in-context skill 帮助多跳分解的特定优势——也可能是评估细节差异,值得 sanity check
Rating
Metrics (as of 2026-04-24): citation=2, influential=0 (0%), velocity=2.00/mo; HF upvotes=96; github 227⭐ / forks=6 / 90d commits=25 / pushed 17d ago
分数:2 - Frontier 理由:把 “skill internalization” 正面 formulate 成可优化的训练目标,helpfulness-driven curriculum + Figure 6 的 rise-then-fall 是 agentic RL 难得的清爽机制证据(见 Strengths 1-2),属于当前 agentic RL 方向必须比较的 Baseline;但依赖高质量初始 SkillBank、7B 上对 SkillRL 的优势收窄(Weaknesses 1, 3),尚未成为”只读它就能看懂方向脉络”的 Foundation;相对 1-Archived,它明确推进了 skill 范式的认知边界,不是 incremental。