Summary
PersonaVLM: Long-Term Personalized Multimodal LLMs
- 核心: 把 general MLLM 改造成具备长期个性化能力的 agent,通过显式 memory 架构 + 多步 retrieval reasoning + 动态 personality 评估解决 “preferences shift over time” 的问题
- 方法: 4 类 memory(core/semantic/episodic/procedural)+ Big Five 人格向量 + EMA 式 Personality Evolving Mechanism (PEM),在 Qwen2.5-VL-7B 上做 SFT + GRPO 两阶段训练
- 结果: 在自建 Persona-MME 上比 baseline +22.4%、超过 GPT-4o +5.2%(128k 设置);同时构建 30k+ 交互、500 personas 的合成训练集和 2000+ case 的评测 benchmark
- Sources: paper | website | github
- Rating: 2 - Frontier(Persona-MME benchmark 与 agentic memory framing 填补空白且 artifacts 全开源;但方法组件均为已有 building blocks 组合,尚未成为方向的 de facto 标准)
Key Takeaways:
- 问题 framing 有意思: 把 “personalization” 从静态的 input augmentation / output alignment,重新 framing 成需要长期 memory 管理 + 动态人格建模的 agent 任务。这个 framing 本身比方法更值得记。
- Memory 架构是 MemGPT 的多模态延伸: 4 类 memory 对应不同更新粒度(semantic 每轮 / core+procedural 每 session / episodic 按 topic 分段),明显照搬 cognitive memory taxonomy。
- PEM = Big Five + EMA: 把人格量化成 5 维向量,用 cosine-decay 的 EMA 平滑。简单到几乎是工程 trick,但提供了一个可解释的 “user state” handle。
- GRPO 训 multi-turn retrieval: reward = accuracy × consistency + 0.5 × format,用 Qwen3-30B-A3B 做 LLM-as-Judge。这是一个标准的 agentic-RL pattern,多轮 retrieval 上限设为 3 次。
- Benchmark 是主要贡献: Persona-MME 7 维度 / 14 任务 / 2000+ case,可能比方法更被引用。
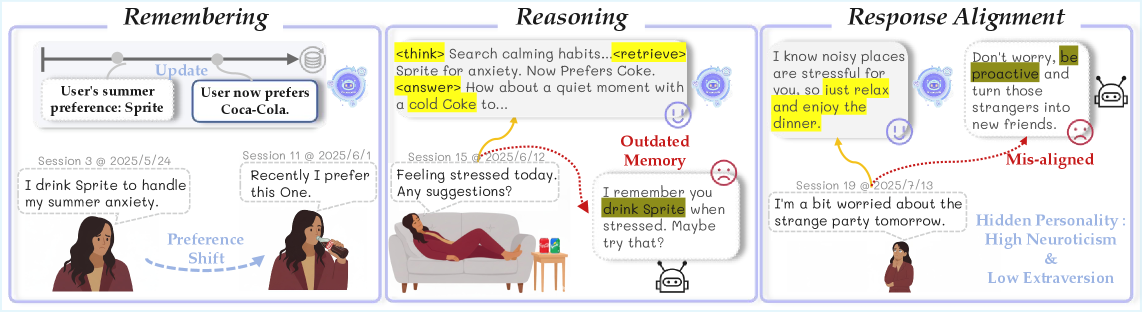
Teaser. PersonaVLM 三大核心能力示意。 用户先表达喜欢 Sprite,后切换到 Coca-Cola;当用户后续表达 stress 时,传统 RAG 会基于过期 memory 推荐 Sprite,而 PersonaVLM 能捕捉 preference shift 并基于人格(introverted + neurotic)调整回复语气。
1. Motivation: Why Long-Term Personalization is Hard
作者列举的两个失败模式很具体(值得记):
- Input augmentation 派(Yo’LLaVA、RAP)擅长识别 user-specific concept,但没有 update / delete memory 的机制——所以无法捕捉 “Sprite → Coca-Cola” 这种偏好迁移。
- Output alignment 派(ALIGNXPERT、Personality-Activation Search)预设 user trait 是静态的——所以无法适应通过零散对话逐步暴露的 introversion。
❓ 第一类问题更像是 memory engineering,第二类才是真正的 alignment。把它们打包成 “long-term personalization” 是营销,但论文的方法确实分别 address 了两者。
由此提出两个 pillar:
- Personalized Memory Architecture: 主动构建并管理一个 user-centric 的多模态数据库
- Memory Utilization & Response Alignment: 利用这个数据库做 reasoning + retrieval,生成与 user 演化中的特征对齐的 response
2. Method: PersonaVLM Framework
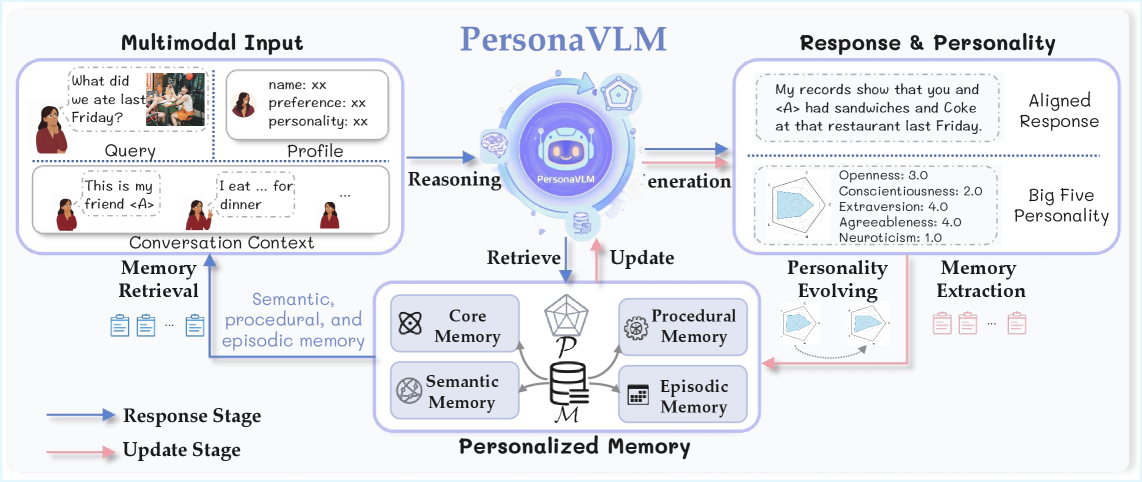
Figure 2. PersonaVLM 整体框架。 蓝色箭头是 Response Stage(处理输入 → 检索 memory → 生成对齐 response),粉色箭头是 Update Stage(分析完整交互 → 提取关键 memory + 更新人格画像)。
2.1 Personalized Memory Architecture
整个 architecture 由两部分组成:
(1) User Personality Profile : Big Five 维度的标量向量(Openness、Conscientiousness、Extraversion、Agreeableness、Neuroticism)。
(2) Multi-Type Memory Database : 支持 CRUD 的 timeline 化 agentic 系统,4 类 memory:
| Memory 类型 | 内容 | 更新频率 | 存储 |
|---|---|---|---|
| Core | user 基础属性(human + persona blocks,inspired by MemGPT) | 每个 session 末尾 | 仅最新版本 |
| Semantic | 事件无关的抽象知识(实体、关系、多模态 concept) | 每轮对话 | 按时间累积 |
| Episodic | 原子化、带时间戳的事件(summary + 对话回合 + keywords) | 按 topic 分段 | 按时间累积 |
| Procedural | user-centric 计划、目标、习惯 | 每个 session 末尾 | 仅最新版本 |
❓ 这个分类几乎是 cognitive psychology 的 memory taxonomy 直接搬过来,没有验证 4 类是否真的正交、是否都必要。Appendix 有 ablation 但只在合并/移除粒度上做。
2.2 Response Stage
Equation 1. Response 生成。
符号说明:
- :user query(text + 可选 image + timestamp)
- :dialogue context(最近 时间窗内的历史对话)
- :当前 memory 状态
含义:每轮 response 是对当前 query、近期 context、累计 memory 的函数。实现上是 multi-step interaction:
- 模型基于 query + context + consolidated profile (core memory + personality) 输出推理 +
action - 若信息不足,输出
<retrieve>标签包含time period+keywords - Agent 先按 time period 过滤,再在 semantic/episodic/procedural 三类上并行检索 top-k
- 结果回灌进模型,进入下一轮推理。最多 3 轮。
两个设计 insight(作者明确写出,值得记):
- User query 常含 anaphora(“that thing we just talked about”),直接 semantic retrieval 不准 → 需要 multi-turn agentic retrieval
- 现有 query rewriting 方法忽略了 temporal cue(“this morning”)→ 让模型显式输出
time period
2.3 Update Stage
Equation 2. Memory + Personality 更新。
Personality Evolving Mechanism (PEM):核心是一个 EMA 更新规则。
其中 是从当前 query 推断出的 turn-specific 人格向量, 是 cosine-decay schedule 的平滑因子——前期低 快速适应,后期高 保持稳定。
这个 EMA 设计简单到几乎不算贡献,但合理:长期对话不应该被单次 query 大幅扰动,又不应该完全 freeze。
Memory 更新逻辑(不同类型不同节奏):
- Semantic: 每轮提取偏好、多模态概念、显式记忆请求
- Core / Procedural: session 末尾分析完整对话做 CRUD
- Episodic: 按 topic 分段,每段含 summary + keywords + 对话回合
2.4 Training: SFT + GRPO
Backbone: Qwen2.5-VL-7B。
Stage 1 - SFT: 78k 合成样本,覆盖 (a) memory 操作(人格推断 + 4 类 CRUD)和 (b) 完整 multi-step reasoning trajectories。目的是让模型能输出格式正确的 reasoning + retrieval action。
Stage 2 - GRPO: 强制结构化输出格式:
<think>...</think>推理过程<retrieve>...</retrieve>或<answer>...</answer>二选一
Equation 3. Reward 设计。
符号说明:
- : 与 preferred response 的准确度
- : 推理过程与最终回答的逻辑一致性
- : 格式合规度
和 由 Qwen3-30B-A3B 做 LLM-as-Judge 零样本评分。每条 trajectory 最多 3 次 retrieval。GRPO 通过 group 内 reward 标准化得到 advantage。
⚠️ Reward 用 acc × cons 而非 acc + cons,意味着 reasoning 不一致时整体 reward 归零——这个设计强力但可能压制 exploration。论文没有 ablation 这点。
3. Dataset & Benchmark: 主要贡献
Figure 3. 数据合成 pipeline + Persona-MME 概览。 (a) 从 PersonaHub 采样 base persona,注入随机人格特质,用 Seed1.6-thinking 生成长对话;(b) Persona-MME 7 维度 / 14 任务;(c) 提供 32k 和 128k 两套 context 配置,共 2000+ in-situ case。

3.1 Synthesis Pipeline
3 个原则:
- Long-term Dynamics: 对话覆盖几百轮,模拟数周/月时长,概率性引入 preference / topic / personality shift
- Multimodality & Diversity: >15% 对话含多模态元素,覆盖专业任务到日常闲聊
- Structured Supervision: 不仅生成对话,还生成中间的 reasoning / retrieval / memorization 步骤——这些是训练 agentic 行为的关键监督信号
最终:30k+ 交互,500 unique personas。
3.2 Persona-MME Benchmark
7 个维度: Memory、Intent、Preference、Behavior、Relationship、Growth、Alignment 14 个细粒度任务(详细见 Table 5) 2 套 context 配置: 32k(<100 turns)/ 128k(更长) 每 case 包含: (1) 多选题评估 memory + understanding(2) 可选的 personality test 评估 alignment
这是论文最 reusable 的 artifact——已在 HuggingFace 开源(ClareNie/Persona-MME)。但 200 personas 的多样性是否足以代表真实用户分布存疑。
4. Experiments
4.1 Personalized Understanding (RQ1)
Table 1. 在 Persona-MME 和 PERSONAMEM 上的主结果(节选)。
| Context | Model | Persona-MME Overall | PERSONAMEM |
|---|---|---|---|
| 32k-Full | GPT-4o | 72.35 | 39.20 |
| 32k-Full | InternVL3-38B | 71.04 | 57.93 |
| 32k-RAG | Qwen2.5-VL-7B (baseline) | 61.20 | 45.67 |
| 32k-RAG | PersonaVLM-RL | 71.48 (+10.28) | 56.53 (+10.86) |
| 128k-Full | GPT-4o | 69.23 | 45.32 |
| 128k-Full | InternVL3-38B | 67.18 | 46.56 |
| 128k-RAG | Qwen2.5-VL-7B (baseline) | 59.01 | 37.88 |
| 128k-RAG | PersonaVLM-RL | 71.05 (+12.04) | 47.28 (+9.4) |
关键观察:
- 7B 的 PersonaVLM 超过 38B 的 InternVL3-38B(128k 设置下 +3.87%),也超过 GPT-4o +5.2%
- 简单 RAG 在短 context 上反而有害(preference 任务 -9.33%),但在长 context 上 +4.53%——验证了 retrieval 设计需要更精细
- SFT → RL 阶段平均 +5.35%,证明 GRPO 训 multi-turn agentic retrieval 的必要性
Figure 4. 在 PERSONAMEM (32k) 七个任务上的细分对比。
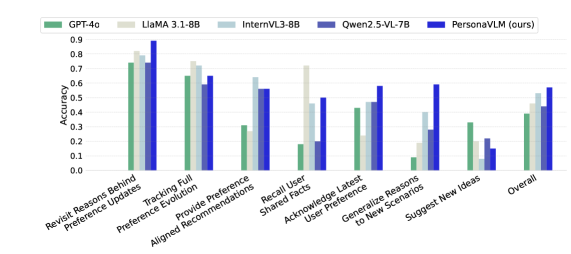
PersonaVLM 在 memory recall 上略输 GPT-4o(与 [^18] 一致),但在 Growth Modeling 和 Behavioral Awareness 上领先 10%+。这个 trade-off 暗示:proprietary 大模型在静态记忆上仍占优,agentic memory 架构的优势在于动态推断。
4.2 Personalized Alignment (RQ2)
Table 2. Alignment 评估(Persona-MME alignment 子任务 + P-SOUPS)。
| Model | Persona-MME 32k | Persona-MME 128k | P-SOUPS Overall |
|---|---|---|---|
| Qwen2.5-VL-7B (baseline) | 69.91 | 52.27 | 37.11 |
| InternVL3-38B | 64.60 | 63.01 | 46.32 |
| Qwen3-30B-A3B | 80.09 | 83.06 | 47.14 |
| Self-Critic | 59.73 | 57.66 | 37.50 |
| Few-Shot | - | - | 39.67 |
| PersonaVLM (ours) | 89.16 | 92.22 | 49.60 |
- 比 next-best 模型在 Persona-MME 上 +9.16%,比 baseline 整体 +12%
- 有趣发现:纯语言模型 Qwen3-30B-A3B 在 alignment 上比多模态 InternVL3-38B 强 20%——多模态训练可能损害了 personality alignment 能力
4.3 Open-Ended Generation (RQ3)
200 个 Persona-MME 问题,Gemini-2.5-Pro 做 judge,pairwise 比较 Accuracy + Personality Alignment。
Figure 5. Open-ended 生成的定性评估(Gemini-2.5-Pro 评判)。
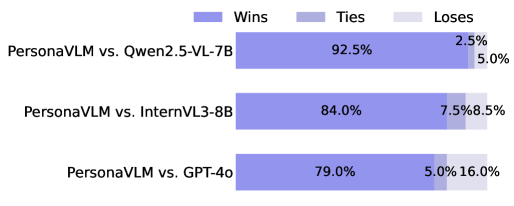
PersonaVLM vs GPT-4o:79% win / 16% loss——这是论文最引人注目的数字。
Figure 6. 案例分析。 PersonaVLM 在 visual recall + contextual integration + 长期人格一致性三方面优于 baseline 和 GPT-4o;其他模型出现 memory hallucination 或 tonal misalignment。

❓ Pairwise judging 用 Gemini-2.5-Pro 而 reward model 用 Qwen3-30B-A3B——judge model 的选择是否影响 win rate?没有交叉验证。79% vs 16% 在 LLM-judge 评估里几乎是上限信号,需要警惕 reward hacking。
关联工作
基于
- MemGPT (Packer et al., 2024): 4 类 memory 的 core/semantic/episodic 划分明显借鉴 MemGPT 的 OS-style memory 管理
- Qwen2.5-VL-7B: backbone
- GRPO (Shao et al., 2024): RL 训练算法,原本来自 DeepSeek-Math
- PersonaHub: 训练 / 测试 persona 的来源
对比
- Yo’LLaVA / RAP(input augmentation 派): 只能识别 user-specific concept,无 memory update 机制
- ALIGNXPERT / PAS(output alignment 派): 假设 trait 静态,无法适应演化
- PERSONAMEM: 第三方 benchmark,PersonaVLM 在其上验证泛化
- GPT-4o / InternVL3-8B/38B / LLaVA-OneVision-1.5-8B / Qwen3-30B-A3B: 主要 baseline
方法相关
- Big Five 人格模型: 心理学经典框架,PEM 假设其足以表征用户
- Note on naming collision: PersonaVLM 引用的 [^11] “RAP” 是 Retrieval-Augmented Personalization,与 vault 中已有的 2305-RAP(Reasoning as Planning, EMNLP 2023)是同名不同工作,注意区分
论文点评
Strengths
- Problem framing 清晰: 把 personalization 从 “concept recognition” 升级为 “long-term agentic memory + dynamic personality”,这个 reframing 本身比方法更有价值
- Benchmark 是真贡献: Persona-MME 7 维度 / 14 任务 / 2000+ case + 32k/128k 两套配置,填补了多模态长期个性化评估的空白
- Memory 架构落地实在: 4 类 memory + 不同更新粒度 + timeline 检索,工程上可复制
- 完整 open-source: code + model weights + training data + benchmark 都已发布
- Agentic RL 应用合理: GRPO 训 multi-turn retrieval 是该问题的自然 fit
Weaknesses
- 方法的每个组件都不新: MemGPT 的 4 类 memory、EMA 平滑、GRPO + LLM-as-Judge——都是已有 building block 的组合。novelty 集中在 framing 和系统集成
- Big Five 假设可疑: 把 user personality 量化成 5 维向量是心理学的简化模型,对一个工程系统是否够用、是否会因为强表征而 overfit 到这个假设上,没有讨论
- 合成数据的代表性存疑: 500 personas 来自 PersonaHub 采样,对话由 Seed1.6-thinking 生成——训练和测试都依赖同一个 generator 的 distribution,可能存在 distribution shift 到真实用户行为
- Win rate 79% vs GPT-4o 太高: LLM-as-Judge 在格式偏好、长度偏好上有已知 bias,Gemini 评判 PersonaVLM (Qwen 系) vs GPT-4o 缺少 cross-judge 验证
- Reward 设计未 ablate: 中乘法 vs 加法、format weight 的选择都没有 sensitivity analysis
可信评估
Artifact 可获取性
- 代码: inference + training(GitHub
MiG-NJU/PersonaVLM,README 提供了 quick start 和 Gradio demo) - 模型权重: 已发布
ClareNie/PersonaVLM(HuggingFace) - 训练细节: Appendix B.2 提供了超参 + 数据配比 + 训练步数等完整信息
- 数据集: 开源——训练集
ClareNie/PersonaVLM-Dataset,benchmarkClareNie/Persona-MME
Claim 可验证性
- ✅ “在 Persona-MME / PERSONAMEM 上超过 baseline 22.4% / 9.8%“:自建 benchmark 已开源,可独立复现
- ✅ “memory 架构 + 多步 retrieval”:方法描述清晰,代码已开源
- ⚠️ “比 GPT-4o 高 5.2%“:在自建 benchmark 上的提升,PERSONAMEM 上的 +2.0% 才是真正在第三方 benchmark 上的提升
- ⚠️ “79% win rate vs GPT-4o”:单一 LLM judge (Gemini-2.5-Pro),未做 cross-judge 验证或人工评估
- ⚠️ “PEM 有效”:Appendix Table 9 有 P-SOUPS ablation,但主文没展示 PEM on/off 的对比
- ❌ 无明显营销话术
Notes
- 这篇论文最有价值的两个东西:(1) Persona-MME benchmark;(2) 把 personalization 重新 frame 为 agentic memory 问题。方法本身是已知组件的组合
- 对我个人研究的启示:agentic memory 架构 + multi-turn retrieval RL + LLM-as-Judge reward 是一个正在成熟的 pattern,可以直接迁移到其他 long-context agent 任务(如 computer-use agent 的 task history、embodied agent 的 episodic memory)
- 一个值得关注的 negative finding:简单 RAG 在短 context 反而损害性能(preference -9.33%)——这与 “RAG always helps” 的 conventional wisdom 矛盾,值得记
- Reward 设计 的乘法形式很激进,如果迁移到其他任务需要小心
- ❓ Big Five 是否真的够用?人格心理学有更现代的 facet-level 模型(HEXACO 等),用 5 维标量可能丢失太多信息——但工程上简单
- ❓ Episodic memory 按 “topic 分段” 的具体算法没说清楚,如何检测 topic boundary 是非平凡的子问题
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.0/mo; HF upvotes=45; github 83⭐ / forks=4 / 90d commits=1 / pushed 8d ago
分数:2 - Frontier 理由:论文贡献主要集中在 (1) Persona-MME benchmark(7 维度 / 14 任务 / 2000+ case,全开源,填补多模态长期个性化评估空白)和 (2) 把 personalization 重新 framing 成 agentic memory + 动态人格问题——这两点让它在方向前沿有明确占位,适合做 baseline 和参考。但方法层面每个组件(MemGPT 4 类 memory、EMA、GRPO + LLM-as-Judge)都是已有 building block 的组合,且 benchmark 尚未被多篇后续工作采纳为 de facto 标准,不到 Foundation 档位;远好过 Archived(全开源 + 方向前沿 framing + 合理 agentic RL 应用)。