Summary
Reasoning with Language Model is Planning with World Model (RAP)
- 核心: 把 LLM 同时当作 reasoning agent 和 world model,用 MCTS 在显式 state-action 空间里做规划,替代 CoT 的纯自回归生成
- 方法: 同一个 LLM 用不同 prompt 分别扮演 policy(生成 action)、world model(预测 next state)、reward model(self-evaluate / state confidence / action likelihood / task heuristic),UCT-MCTS 4 阶段(select / expand / simulate / backprop)建 reasoning tree
- 结果: Blocksworld 6-step 从 CoT 0% → RAP 42%;LLaMA-33B + RAP 在 plan generation 上比 GPT-4 + CoT 相对提升 33%;GSM8K 48.6% (vs CoT 29.4%, +aggr 51.6%);PrOntoQA proof acc 78.8% (vs CoT 64.8%)
- Sources: paper | github
- Rating: 3 - Foundation(inference-time search reasoning 的奠基工作,LLM-as-policy/world-model/reward 的 formulation 被 LLM-Reasoners 库与后续 o1-style test-time scaling / PRM-guided search 工作系统性继承)
Key Takeaways:
- LLM-as-World-Model: 同一个 frozen LLM 通过 prompt 切换可以同时承担 policy / transition / reward 三种角色——不需要单独训一个 world model,世界知识已经压缩在 LLM 权重里
- State 是核心区分点:CoT 只生成 action 序列,RAP 把 state 显式化(Blocksworld 的 block 配置、GSM8K 的中间变量值、PrOntoQA 的当前 fact),这让 reward 计算和 backtracking 成为可能
- MCTS > 自回归 / SC / BFS:在 plan generation 这种需要 backtrack 的任务上,CoT 的”一往无前”是结构性 bug;MCTS 的 explore/exploit balance + Q-value 回传让 LLaMA-33B 反超 GPT-4
- Reward 设计与任务强耦合:action likelihood 对 plan generation 关键,对 math 几乎无用;self-eval 在 logical reasoning 中是主力。“通用”reward 不存在
- Lineage 价值:RAP 是 LLM-Reasoners 库的源头,也是后来一批 inference-time scaling / search-augmented reasoning 工作(ToT、CoRe 等)的同期/起点参考
Teaser. RAP 的整体框架:把 reasoning 显式建模成 MDP,LLM 同时扮演 reasoning agent 和 world model,用 MCTS 在 state-action 树上规划。
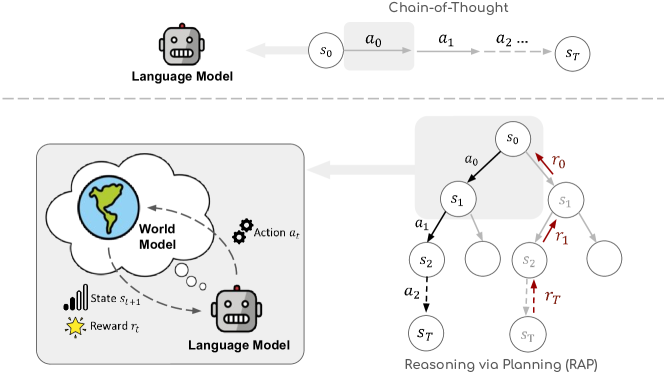
1. Motivation:CoT 缺什么
作者诊断当前 LLM reasoning(以 CoT 为代表)的三个结构性缺陷:
- 缺 world model:没有显式的 state 表征(block 配置、中间变量值),生成下一步只能靠”语感”
- 缺 reward 机制:无法对中间步骤打分,没法知道某步是否走在正确方向上
- 缺 explore/exploit balance:自回归生成本质上是贪心,无法回溯,更无法对 reasoning 树做策略性探索
人类规划时显式做这三件事:模拟未来 state、评估 outcome、迭代 refine。RAP 的设计就是把这套机制还给 LLM。
❓ 这个 motivation 表述很自洽,但隐含一个值得追问的假设:LLM 真的”缺” world model 吗,还是只是没被显式 prompt 出来?RAP 自己的做法(同一个 LLM 通过 prompt 切换扮演 world model)实际上是后者的证据——世界知识在权重里,只是默认 decoding pipeline 没用上它做 lookahead。
2. 方法
2.1 把 reasoning 形式化为 MDP
给定 state ,LLM 作为 policy 采样 action ;同一个 LLM 作为 world model 预测 。c, c' 是不同任务下不同的 prompt(含 in-context demo)。最终 reasoning trace 是 的交替序列。
State / action 在三个任务上的具体实例化(Figure 2):
| Task | State | Action |
|---|---|---|
| Blocksworld (plan gen) | block 当前配置(自然语言描述) | “pickup orange block” 等动作 |
| GSM8K (math) | 已知中间变量的取值 | 提出一个 sub-question |
| PrOntoQA (logic) | 当前关注的 fact | 选一条 rule 做下一步推导 |
Figure 2. 三个任务的 state/action 实例化。
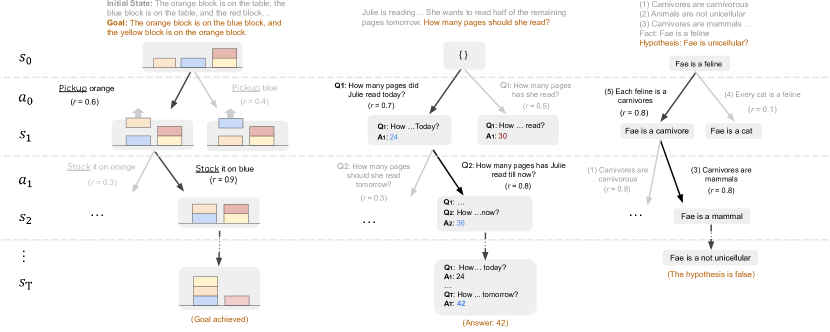
关键观察:action 和 state 的定义是任务相关的人工设计,这是 RAP 的灵活性来源,也是它的”prompt engineering 重活”的来源。
2.2 Reward Design
四类可组合的 reward:
- Likelihood of action :LLM 生成该 action 的对数似然,体现”直觉”先验。Blocksworld 必备
- Confidence of state:从 world model 多次采样 next state,取众数比例。GSM8K 中用来评估 sub-question 答案的稳定性
- Self-evaluation:直接 prompt LLM “Is this reasoning step correct?” 取 “Yes” token 概率。PrOntoQA 主力
- Task-specific heuristics:例如 Blocksworld 中比较预测 state 与 goal 的满足条件数
GSM8K 用加权几何平均融合 self-eval 和 confidence:。
2.3 MCTS Planning(4 阶段)
Figure 3. MCTS 一次迭代的四个阶段。
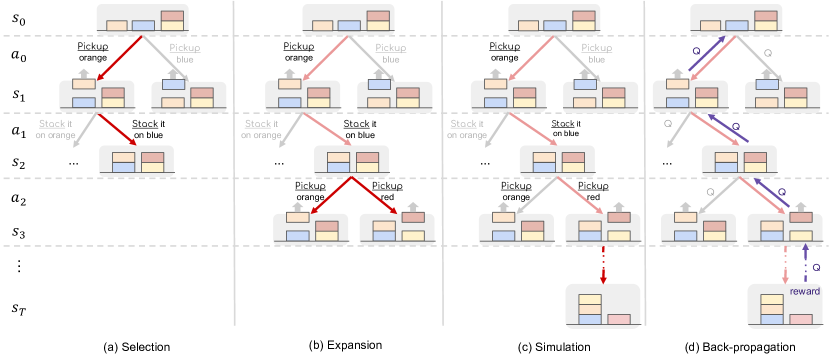
Selection:从根节点开始按 UCT 选子节点
符号: 是状态-动作价值估计, 是访问次数, 控制 exploration 权重。第二项越大表示该子节点越未充分探索。
Expansion:到达 leaf 后,让 LLM 采样 个 action,对每个用 world model 预测 next state,扩展出 个子节点。
Simulation:从当前节点 roll-out 到 terminal,roll-out 时用 lightweight reward(去掉昂贵的 state confidence 项)greedy 选 action。
Back-propagation:终态 reward 沿路径回传,更新 。GSM8K 用 future avg reward 的 max 而非 sum,避免长 trace 被惩罚:
Trace 选择:跑完预算后从树里选一条 trace。论文实验发现”选历史 iteration 中最高 reward 的 trace”通常最好,优于”逐步贪心选 max-Q 子节点”和”选访问次数最多的 leaf”。
2.4 RAP-Aggregation
对只关心最终答案的任务(GSM8K),把多次 MCTS iteration 产生的多条 trace 的最终答案做 majority vote,类似 self-consistency 但聚合的是 search 出的高质量 trace。Plan generation / logical inference 需要完整 trace,不适用。
3. 实验
3.1 Blocksworld (Plan Generation)
LLaMA-33B baseline,按最少需要的 action 数分组。
Table 1. Blocksworld 主结果。
| Method | 2-step | 4-step | 6-step |
|---|---|---|---|
| CoT | 0.17 | 0.02 | 0.00 |
| CoT - pass@10 | 0.23 | 0.07 | 0.00 |
| CoT (GPT-4) | 0.50 | 0.63 | 0.40 |
| RAP (10 iter) | 1.00 | 0.86 | 0.26 |
| RAP (20 iter) | 1.00 | 0.88 | 0.42 |
核心 finding:LLaMA-33B + RAP(20) 在 6-step 上 0.42 vs GPT-4+CoT 的 0.40,平均 33% 相对提升超过 GPT-4。CoT 在 6-step 完全失败(0%)说明这不是 LLM 知识不够,是 decoding pipeline 不行。
Figure 4. CoT vs RAP 在 Blocksworld 上的 trace 对比。 CoT 先满足”orange on red”导致第一个 goal 无法达成,且无法回溯;RAP 通过 MCTS backtrack 找到了正确的子目标顺序。
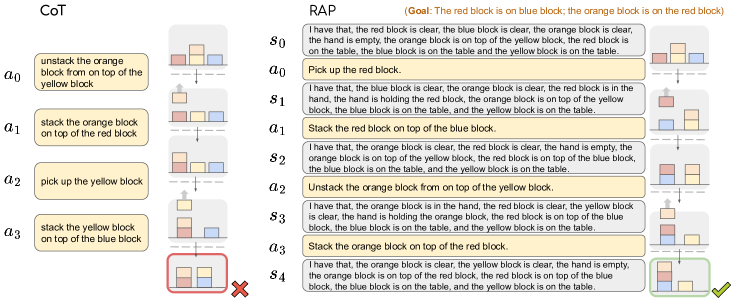
case study 还指出一个 subtle 优点:计算 时只把 current state(而非完整历史)feed 给 LLM,相当于把后期决策变成”看起来更短”的新问题,节省迭代预算给前期更难的决策。
3.2 GSM8K (Math)
Table 2. GSM8K 主结果。
| Method | Accuracy (%) |
|---|---|
| Chain-of-Thought | 29.4 |
| + SC (10) | 46.8 |
| Least-to-Most | 25.5 |
| + SC (10) | 42.5 |
| RAP (1) | 40.0 |
| RAP (10) | 48.6 |
| + aggr | 51.6 |
Figure 5. GSM8K 在不同 sample / iteration 数下的对比。 RAP 在所有预算下都优于 CoT-SC 和 L2M-SC,预算越小优势越明显。
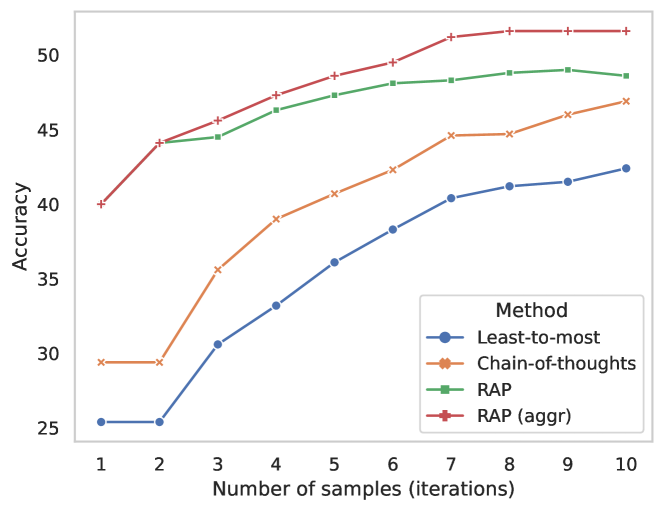
关键比较:RAP(1)=40% 已经超过 CoT(1)=29.4%,说明搜索带来的提升不只是来自”多采样”——单次 MCTS 也利用了 world model + reward 提供的中间信号。
3.3 PrOntoQA (Logical Reasoning)
Table 3. PrOntoQA 主结果(500 samples,混合 3/4/5 hop)。
| Method | Pred Acc | Proof Acc |
|---|---|---|
| CoT | 87.8 | 64.8 |
| CoT + SC | 89.8 | - |
| RAP | 94.2 | 78.8 |
Proof accuracy(要求整个推理链对)的 +14% 提升远大于 prediction accuracy 的 +4.4%——这恰好是 RAP 设计的核心 payoff:reward + backtrack 能 catch 错误的中间步。
3.4 Scaling 到 Llama-2 70B + 全量 Blocksworld
Table 4. 全量 Blocksworld 用 Llama-2 70B(602 cases),按 2-12 step 分组,分 Easy/Hard 两 setting。
| Setting | Method | 2-step | 4-step | 6-step | 8-step | 10-step | 12-step | All |
|---|---|---|---|---|---|---|---|---|
| Easy | CoT | 0.49 | 0.18 | 0.06 | 0.01 | 0.01 | 0.00 | 0.08 |
| Easy | RAP (10) | 1.00 | 0.99 | 0.75 | 0.61 | 0.32 | 0.32 | 0.65 |
| Hard | CoT | 0.22 | 0.14 | 0.02 | 0.02 | 0.00 | 0.00 | 0.05 |
| Hard | RAP (10) | 0.67 | 0.76 | 0.74 | 0.48 | 0.17 | 0.09 | 0.51 |
CoT 在 6-step+ 上几乎完全崩溃,RAP 在 8-step 仍有 48-61%。结论:LLM 容量更大也救不了 CoT 的结构性缺陷,必须改 decoding 范式。
3.5 Reward Choice 消融(Section 5.2)
简化结论:组合多种 reward 通常更好;但 reward 的有效性强烈依赖任务(action likelihood 对 plan generation 关键,对 math 没用)。论文没给”通用 recipe”——这本身也是一个有用的 negative finding。
关联工作
基于
- CoT (Wei et al. 2022): 直接对比的 baseline;RAP 的核心论点是 CoT 的自回归 + 无 state 是结构缺陷
- Self-Consistency (Wang et al. 2022): RAP-Aggregation 的灵感来源;RAP 把 SC 的”多 sample + vote”升级为”search + vote”
- Least-to-Most (Zhou et al. 2022): GSM8K 的 sub-question 分解思路与 RAP 类似;区别是 L2M 一次性生成所有 sub-question,RAP 基于 current state 增量生成
- MCTS / UCT (Kocsis & Szepesvári 2006): Planning algorithm 主体
并行 / 同期
- Tree of Thoughts (Yao et al. 2023): 同期工作,BFS/DFS 在 reasoning tree 上搜索;RAP 用 MCTS + 显式 world model + reward,方法上更系统
- CoRe: fine-tune verifier + MCTS for math,与 RAP 思路相近但需训练
后续 / 衍生
- LLM-Reasoners (Ber666/llm-reasoners): 同作者把 RAP 工程化为通用 inference-time reasoning library,是 RAP 的”产品化”版本
- 后续 inference-time scaling 工作: o1/o3-style test-time compute、process reward model(PRM)、search-augmented reasoning 大量引用 RAP 作为 search-based reasoning 的奠基工作之一
相关概念
- World Model Survey: world model 概念在 reasoning 而非 video prediction 语境下的应用——RAP 的 “LLM as world model” 是这个概念在 LLM 时代的具体实例
- Embodied CoT: CoT for action 的扩展,与 RAP 同样关注 reasoning + action 的结合,但走的是 explicit reasoning trace 路线而非 search
论文点评
Strengths
- Conceptually clean:把 reasoning 显式建模为 MDP,把 LLM 解耦成 policy + world model + reward 三种角色,这个抽象后来被 LLM-Reasoners 库工程化,成为 inference-time search 工作的通用 framework
- Strong evidence:Blocksworld 的 CoT(GPT-4) 0.40 vs RAP(LLaMA-33B) 0.42 这种 cross-model 比较有说服力——证明了搜索带来的不是边际改进,而是对 CoT 结构性缺陷的补救
- 跨任务一致性:在 plan / math / logic 三类完全不同的 reasoning 任务上同框架都 work,且性能提升来自不同 reward(action likelihood vs confidence vs self-eval),说明 framework 真正是通用的
- 诚实的 limitation 标注:Section 5.2 明确指出 reward 的任务依赖性,没有 oversell “通用 reward”
Weaknesses
- Prompt engineering 重:每个任务需要为 policy / world model / reward / self-eval 分别设计 prompt 和 in-context demo,复制起来工作量大;论文没系统讨论 prompt 鲁棒性
- State 抽象的人工成本:把 raw text 抽象成”显式 state”(block 配置、中间变量)需要人在 loop 里设计,对 open-domain 任务(如 long-form writing、复杂科学问题)扩展困难——论文也承认这点(intro 末尾对比 LLM+P 的局限)
- 计算成本未充分讨论:MCTS 20 iter × 每 iter 多次 LLM call,cost 应该是 CoT 的 50-100x。Table 5/6 应该报 inference compute 配平的 baseline,否则 vs SC 的比较不完全公平
- World model 的”自洽幻觉”风险:用 LLM 做 world model 会继承 LLM 的 bias——如果 LLM 对某个错误 state transition 很 confident,reward 也是 LLM 算的,整个搜索会在错误的 state space 里”自信地探索”。论文没有针对这种 systematic error 做诊断
- 缺 fine-tuning baseline:所有实验都是 frozen LLM + prompting。如果允许 fine-tune(哪怕只 finetune world model 那部分),是 RAP 优势更大还是缩小?这是 follow-up 才回答的问题
可信评估
Artifact 可获取性
- 代码: 已开源。原 repo
Ber666/RAP含三个任务的实现;后被合并/扩展到Ber666/llm-reasoners通用库(论文 v2 的 comments 字段也指向这个) - 模型权重: 不适用——RAP 是 inference-time framework,使用的是公开 base model(LLaMA-33B、Llama-2 70B、GPT-4)
- 训练细节: 不适用(无训练);prompts 全部在 Appendix C,可复现
- 数据集: 全部公开 benchmark:Blocksworld(Valmeekam et al.)、GSM8K、PrOntoQA
Claim 可验证性
- ✅ “LLaMA-33B + RAP 在 Blocksworld plan generation 上超 GPT-4 + CoT 33%“:Table 1 数据对应,benchmark 公开,可独立复现(且第三方多次复现过)
- ✅ “GSM8K 48.6%, +aggr 51.6%“:Table 2 + Figure 5 多预算曲线,可信
- ✅ “PrOntoQA proof acc 78.8% (vs CoT 64.8%)“:Table 3,benchmark 公开
- ⚠️ “Llama-2 70B 全量 Blocksworld 上 Easy 0.65 / Hard 0.51”(Table 4):Easy setting 假设知道最少 action 数并用同 step 的 demo,这是相当强的 oracle 信息,“Easy”的命名容易让 casual reader 高估;Hard setting 数据更可信
- ⚠️ “RAP(1)=40% 已经超 CoT(1)=29.4%“(GSM8K):单次 MCTS 仍然内部包含多次 LLM call(expand + rollout),与 CoT 单次解码的 compute 不对等;论文没明确报 compute-matched 比较
- ⚠️ “world model 由 LLM 自身担任”:在 Blocksworld 这种 closed-domain 上 state transition 简单(move block),LLM 容易 predict 对;但论文没量化 world model 的 prediction accuracy,所以”LLM is a good world model” 这个 implicit claim 在更复杂 domain 上的有效性是开放问题
Notes
- 这篇是 LLM reasoning 从”prompt engineering”转向”inference-time search”的关键转折点之一。即使方法本身已经被后来的工作(PRM-guided search、o1-style training)超越,formulation(LLM as policy + world model + reward, MCTS planning)仍是 must-cite。
- 对我(agentic-RL / task-planning 方向)的具体启发:
- State 显式化是 unlock backtrack 的前提——任何想做 multi-step agent 的工作都该问”我的 state 表征是什么?” 现在的 GUI agent / web agent 大多数没有显式 state,本质上还在 CoT 范式
- Reward 设计 task-specific 这个 finding 对 agentic-RL 是一个警示:寄希望于”通用 reward model”可能 overoptimistic,更可能要 per-domain 设计或学习
- LLM-as-world-model 在 closed domain(Blocksworld)work 不代表在 open-world / GUI 这种状态空间庞大且部分可观测的环境也 work——这是 GUI agent / CUA 后续工作(如基于 screenshot 做 world model)必须验证的开放问题
- ❓ 一个值得追问的实验:如果把 world model 换成 ground-truth simulator(Blocksworld 有),RAP 能涨多少?这能 disentangle “MCTS 本身的贡献” vs “LLM-as-world-model 的贡献”。论文没做这个 ablation,但其实代价很小。
Rating
Metrics (as of 2026-04-24): citation=952, influential=124 (13.0%), velocity=27.20/mo; HF upvotes=4; github 2342⭐ / forks=203 / 90d commits=0 / pushed 318d ago · stale
分数:3 - Foundation
理由:RAP 是 inference-time search reasoning 的奠基工作之一——Strengths #1 已指出它把 LLM 解耦成 policy / world model / reward 的 formulation 被同作者工程化为 LLM-Reasoners 通用库,且在”关联工作 / 后续衍生”里确认它成为 o1-style test-time scaling、PRM-guided search 等整条 inference-time compute 路线的 must-cite。与 Rating 2 的区别是:RAP 不只是当时的 SOTA 或 baseline,而是提供了一个被后续范式继承的抽象;即使具体数字被 PRM / RL 方法超越,LLM-as-world-model + MCTS 的 framing 仍是该方向理解脉络的必读。