Summary
World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
- 核心: 让 video world model 和 VLA policy 通过 GRPO RL 在虚拟环境内 co-evolve——policy 失败 rollout 反哺 world model fine-tuning,迭代提升彼此的精度。
- 方法: (1) SANS 数据集:成功 + near-success 轨迹强制 world model 学到细粒度 action-outcome 区分;(2) 在 Cosmos-Predict 2 DiT 上加 reward head 与视频生成联合监督;(3) world model 替换 SimpleVLA-RL pipeline 中的物理仿真器;(4) RL 后的 policy 在真实环境采集失败 rollout 回填 SANS。
- 结果: LIBERO 三 suite 平均 +12.7% SR;real-world 任务从 SFT 13.3% → RL 一轮 36.7% → 二轮 50.0%;world model 视觉 / reward alignment 均 ~87% 左右。
- Sources: paper | website | github
- Rating: 2 - Frontier(落在 world-model-as-RL-simulator 前沿,co-evolving loop + SANS 是新颖贡献,但 real-world 样本量小、代码未发、与 WMPO / VLA-RFT / World-Env 等并行工作未分出胜负,尚未到 de facto 标准)
Key Takeaways:
- Action-following 是 video world model 用作 RL 仿真器的瓶颈:现有 Cosmos-Predict 2 等模型在错误 action 下也 hallucinate 成功,无法提供可靠 reward。
- Near-success trajectories 是关键 ingredient:和成功轨迹差别小,迫使 world model 关注 fine-grained 物理动力学;ablation 显示去掉后 visual alignment 掉 ~30%。
- 联合 reward 监督 + 视频生成是双赢:reward head 与 DiT 共享 backbone,既比 Qwen3-VL judge(50–55%)准很多,又反过来提升视频质量。
- Co-evolving loop 提供超过单轮 RL 的增益:单轮 RL +23.4%,第二轮迭代再 +13.3%,证明 policy distribution shift 后 world model 必须同步更新。
- 局限性明确:autoregressive video 在 >200 帧 (~20s) 长程任务出现质量漂移,所以直接放弃 LIBERO-Long;reward 仍是 sparse 终态信号。
Teaser. World-VLA-Loop 与现有 world-model-based RL 范式的对比,以及 real-world 任务在两轮 co-evolution 后 +36.7% 的成功率提升。

1. Motivation:现有 world model 为什么不能直接当 RL 仿真器
把 VLA policy 放到真实环境跑 RL 太贵——千次量级 rollout、人工 reset、安全风险,连 这样的工业级努力也仍然 prohibitive。所以社区把希望寄托在虚拟环境上:
- 手工 digital twin(如 RoboTwin 2.0):缺 photorealism。
- 3D reconstruction(GWM、Drawer、PolaRiS):在采集到的视角内精确,OOD 几何 / 物理动力学难泛化,无法支持 random exploration。
- Action-conditioned video world model(Cosmos-Predict 2、World-Env、WMPO 等):generalization 好,但严重的 action-following 偏差——给错误 action 也常生成成功视频。
Figure 2. Cosmos-Predict 2 的失败案例:透明 overlay 是 GT 抓取轨迹(实际 fail),而模型生成的视频却显示 “成功” 抓取。 这说明现有 video world model 依赖视觉 prior 而非真正的物理动力学建模,所以它产出的 reward 信号不可信。

❓ 这个观察相当于把 “world model 作为 RL simulator” 的核心假设打了一个洞:如果 world model 只能 mimic 训练分布,那 policy 在 RL 探索阶段一定会找到它无法判别的 region 进行 reward hacking。本文后面 Section 4.5 也确实观察到这种现象(policy 学会去抓杯子背面)。
2. Method:state-aware world model + co-evolving loop
Figure 3. World-VLA-Loop 全流程:(1) 通过遥操作 + policy rollout 收集 SANS;(2) 在 Cosmos-Predict 2 上联合视频和 reward 监督;(3) policy 在 world model 内做 GRPO;(4) refined policy 部署回真实环境,收集新失败轨迹回填 SANS,进入下一轮迭代。
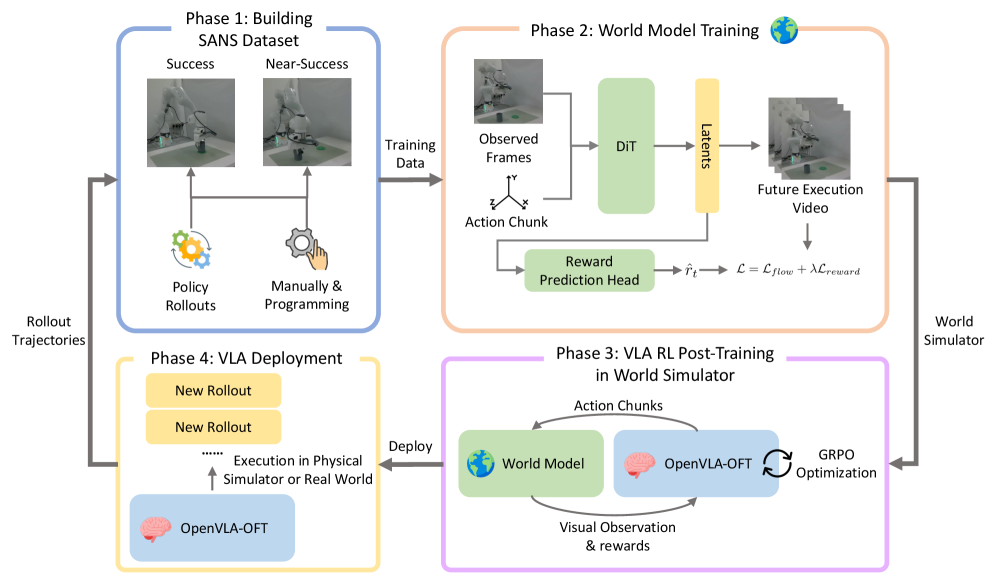
2.1 SANS Dataset:Success + Near-Success Trajectories
现有开源机器人数据集(含 Open X-Embodiment 等)几乎全是成功轨迹——为 imitation learning 准备的,所以 world model 没机会学到 “差一点点就抓到” 这类边界。RoboFAC 和 AHA 开始关注 failure,但只有 QA 标注、没有 action,且只在 sim 内。
SANS 的核心定义:near-success trajectory = 几乎完成目标但因末端定位的微小偏差而失败的轨迹。两条理由:
- 这类轨迹和成功轨迹视觉上极难区分,强迫 world model 学习 fine-grained spatial dynamics。
- RL 探索时 policy 实际频繁产生 near-success 行为,virtual env 的失败模式必须覆盖这些。
数据采集:
- ManiSkill:用 GT object pose 写脚本得成功轨迹,对 pose 加扰动得失败轨迹。约 35k video-action pair,覆盖 23 个任务,作为预训练数据。
- LIBERO:用 OpenVLA-OFT 跑 rollout 自然采集失败模式。每任务 ~50 success + 50 failure。
- Real-world:人工遥操作制造失败 + OpenVLA-OFT 自然 rollout。
- 所有 step 都附带 binary sparse reward。
2.2 State-Aware Video World Simulator
Backbone 是 Cosmos-Predict 2(DiT-based 自回归 video diffusion)。条件是历史 帧观察 和未来 步 6-DoF end-effector pose + gripper open/close 状态 。每个 action 经一个 MLP embedder,加到 DiT 的 timestep embedding 上。
关键架构改动:reward prediction head。在 DiT 输出 diffusion latent 之后接一个 MLP ,预测 step-wise scalar reward ,与 GT sparse reward 联合监督:
权重 按 EDM 框架根据 noise level 动态调整,避免高方差早期 latent 干扰 reward head。
为什么这个设计 work:
- Reward 来自 generated video latent,所以和实际视觉输出本质对齐——比外接 VLM judge 或 heuristic proxy reward 更可信。
- 联合训练让 video generator 自身被迫区分 success vs failure 的 visual outcome——文章后面 ablation 显示去掉 reward head,visual alignment 也掉 30%。这是个有趣的双向收益。
2.3 Closed-Loop RL Post-Training
VLA backbone 取 OpenVLA-OFT,RL pipeline 取 SimpleVLA-RL(基于 GRPO)。把 SimpleVLA-RL 中的物理仿真器整体替换成 world model:
- 初始帧来自数据集,后续帧由 world model 在 policy action chunk 条件下自回归生成。
- 每 step 由 reward head 输出 reward,超过阈值(0.9)即视为 success,作为 GRPO 的 group binary reward。
- Engineering:world model 作为 backend server 接 batch 请求;H100 单节点上 24 帧 chunk 约 7s;50 优化 step 总训练时长约 30 小时 / 任务。
Iterative refinement loop:
- Step 0:SANS = 人工采集的成功 + near-success + SFT baseline 的失败 rollout。RL 出 policy v1。
- Step 1:policy v1 部署到真实环境,新采集的成功 / 失败 rollout 回填 SANS。world model 再 fine-tune,policy 从 SFT base 重新开始 RL。
❓ 注意每一轮 RL 都是从 SFT base 开始而不是 incremental——这避免了 policy 在过拟合的 world model 上累积偏差。但代价是不能利用上一轮 policy improvement。这是个保守选择,未来可以研究 incremental 的 stability。
3. Experiments
3.1 Setup
LIBERO benchmark + 自建实验室设置。硬件:Franka research arm + 单个 RealSense D435 第三人称相机,10Hz。Action chunk size = 24。
注意:因 LIBERO-100 长程任务超过 200 帧导致 video model 严重质量漂移,作者明确 leave for future work——这是个诚实的局限承认。
3.2 World Model 生成质量
Table 1. 视频生成质量:LIBERO 和 real-world 上 SSIM ~0.9,PSNR 26–30,LPIPS < 0.06。
| Scenario | SSIM ↑ | PSNR ↑ | LPIPS ↓ | MSE ↓ |
|---|---|---|---|---|
| LIBERO | 0.90 | 26.57 | 0.031 | 0.0024 |
| Real-World | 0.91 | 29.61 | 0.059 | 0.0019 |
| Average | 0.91 | 28.09 | 0.045 | 0.0022 |
Table 2. Outcome alignment(每任务 20 样本,统计预测 success/failure 与 GT 一致的比例)。
| Metric | LIB-Obj T1 | T2 | LIB-Goal T1 | T2 | LIB-Spat T1 | T2 | Real-World |
|---|---|---|---|---|---|---|---|
| Visual Alignment | 85% | 95% | 90% | 75% | 85% | 95% | 90% |
| Reward Alignment | 75% | 90% | 85% | 75% | 90% | 95% | 95% |
平均 visual / reward alignment ~87%,且两者高度一致——说明 reward head 学到的 success 边界和人类判断对齐。
3.3 RL Post-Training
Table 3. OpenVLA-OFT SR:LIBERO 500 rollouts、real-world 30 物理 rollouts。
| Model | LIB-Obj T1 | T2 | LIB-Goal T1 | T2 | LIB-Spat T1 | T2 | Real-World |
|---|---|---|---|---|---|---|---|
| SFT Base | 73.9% | 73.9% | 91.9% | 86.1% | 83.9% | 87.9% | 13.3% |
| World-VLA-Loop RL | 97.9% | 91.9% | 100% | 96.2% | 93.9% | 94.0% | 36.7% |
| Δ | +24.0 | +18.0 | +8.1 | +10.1 | +10.0 | +6.1 | +23.4 |
Iterative refinement(real-world):SFT 13.3% → 第 1 轮 RL 36.7% → 第 2 轮 RL 50.0%。第二轮带来额外 +13.3%,说明 policy 分布漂移后必须更新 world model。
❓ Real-world 30 rollouts 样本量偏小,13.3% → 50% 的绝对差异虽显著但置信区间宽。理想情况应给每个 step 跑多个 seed 或更多 trials。
3.4 Ablations
Table 4. Ablation on LIBERO-Object(核心两项)。
| Configuration | T1 | T2 |
|---|---|---|
| Visual Alignment (w/o near-success data) | 60% | 65% |
| Visual Alignment (w/o reward head) | 60% | 70% |
| Reward Alignment (Qwen3-VL judge) | 50% | 55% |
| Visual Alignment (full) | 85% | 95% |
| Reward Alignment (full) | 75% | 90% |
两个核心结论:
- 去掉 near-success 数据:visual alignment 掉 ~30%,证明 SANS 的关键作用。
- 去掉 reward head:visual alignment 也掉 ~30%——非常有趣的副作用,说明 reward 监督起到 regularizer 作用,而非仅是 reward signal。
- Qwen3-VL 作为 judge:仅 50–55%,远不如 reward head。文章把这归因为 VLM hallucination;不过没排除 task-specific fine-tune 后的 VLM。
3.5 Qualitative
Figure 5. World model rollout 与实际 policy 执行对比。 SFT baseline 抓取位置不准,第一轮 RL 后开始 reward hack——抓杯子背面,因为第一轮 world model 没有正确建模这种边界 case 的失败。第二轮 SANS 增强后,world model 学会拒绝这种 grasp,policy 才学到精确抓取。

这个 narrative 是 paper 最有意义的实证:reward hacking 不是 bug,是 co-evolving loop 必要性的直接证据——一次性训练好的 world model 总会有 policy 能利用的盲区,必须迭代闭环。
Figure 6. World model 在未见 action 序列上的泛化(OOD action)。 模型对完全未见的 trajectory 仍能生成物理合理的运动,说明它学到的是 control-to-kinematics 的映射,不只是记忆训练序列。

Real-world world model 生成示例:成功(左)vs 失败(右)轨迹。
RL 后的 real-world VLA policy 执行视频。
关联工作
基于
- OpenVLA-OFT: 用作 base VLA policy
- Cosmos-Predict 2: 用作 video world model backbone
- SimpleVLA-RL (arXiv 2509.09674): GRPO RL pipeline,被 World-VLA-Loop 把仿真器替换成 world model
- LIBERO (Liu et al.): 主要评测 benchmark
- ManiSkill 3 (arXiv 2410.00425): 35k 预训练数据来源
对比
- World-Env (arXiv 2509.24948): 同样把 video world model 当作 VLA RL 虚拟环境,但缺少 co-evolving loop 与 near-success 数据
- WMPO (arXiv 2511.09515) / VLA-RFT (arXiv 2510.00406): world model + VLA RL 的并行工作
- Reinforcing Action Policies by Prophesying (arXiv 2511.20633): 类似方向
- GWM (Gaussian world model) / Drawer / PolaRiS (arXiv 2512.16881): 3D 重建路线
- Cosmos Policy (arXiv 2601.16163): 联合预测 action 和 video 的 unified 路线
方法相关
- π0 / (arXiv 2511.14759) / (arXiv 2510.25889): VLA RL 路线
- VLA-RL (arXiv 2505.18719): learned reward model 路线
- Flow Matching (arXiv 2210.02747): Cosmos-Predict 2 的训练目标
- EDM (Karras et al.): noise-level-aware loss 权重调度
- DeepSeekMath GRPO (arXiv 2402.03300): RL 算法基础
- RoboFAC (arXiv 2505.12224) / AHA (arXiv 2410.00371): failure-aware 数据集前置工作
论文点评
Strengths
- Problem framing 清晰且诚实:直接指出 “video world model action-following 太烂,无法当 RL simulator” 这个未被广泛承认的痛点,并给出 Cosmos-Predict 2 hallucinate 成功的反例图,比一般 introduction 的 hand-waving 更有说服力。
- Reward head 与视频生成的双向收益:去掉 reward head 不仅 reward 没了,visual alignment 也掉 30%,说明 sparse reward 在 dense video 监督下起到 regularizer 作用。这是 method 设计的非平凡发现。
- Co-evolving 用 reward hacking 的实证 narrative 论证:Section 4.5 描述 policy 在第一轮 RL 学会抓杯子背面(exploit world model 盲区),第二轮 SANS 修补后才学到正确 grasp——这是 closed-loop 必要性的直接证据,比单纯比较数字更有说服力。
- Engineering 落地诚实:H100 单节点 24 帧 7s、50 step 30 小时/任务 这种数字明确给出,方便复现成本评估。
Weaknesses
- 样本量太小:Real-world 仅 30 rollouts;每个 LIBERO suite 只评 2 个任务(不是全部 10 个)。声称的 +12.7% LIBERO 平均改进只覆盖 6 个任务,且 SFT baseline 在 LIBERO-Goal/Spatial 上已 86–91%,剩余空间本来就小,提升幅度的 generalizability 不强。
- 明确放弃 LIBERO-Long:autoregressive video drift > 200 帧。但 real-world 操作很多就是 long-horizon——这是把 paper main weakness 轻轻带过的做法。
- Iterative loop 只跑了 2 轮:没有展示第 3、4 轮的收敛性,无法判断是否会饱和或退化。
- VLM judge 对比不公平:直接 zero-shot Qwen3-VL 50% 当然差,但 fine-tuned VLM judge(如 RoboFAC、AHA 思路)才是更强 baseline,文章用一句 “会增加 pipeline 复杂度” 绕开。
- Reward 仍是 sparse 终态:作者自己也提到,dense step-wise reward 才能更好提升 RL 收敛——这是未来工作而非现有贡献。
- 代码未发布:README 写 “In preparation!”,目前不可复现。
可信评估
Artifact 可获取性
- 代码: 未开源(README 注明 “Source Code In preparation!“)
- 模型权重: 未发布
- 训练细节: 仅高层描述(提到从 Cosmos-Predict 2 transfer、SimpleVLA-RL pipeline、24 chunk size、10Hz、H100 7s/24 帧、30 小时/任务),缺少超参、loss 权重 具体调度、SANS 各任务详细统计
- 数据集: SANS 未说明是否会公开;预训练 35k Maniskill pairs 也未说明开源计划
Claim 可验证性
- ✅ World model 视觉/reward alignment ~87%:有 Table 2 完整数字、website video 可视检查 sample
- ✅ Reward head 对 visual alignment 也有 +30% 提升:Ablation Table 4/5 直接对比
- ✅ Real-world 二轮迭代 13.3% → 50.0%:有 Figure 1(b),但 30 rollouts 样本量小
- ⚠️ “12.7% average improvement on LIBERO”:只评了 2/10 任务/suite,且 SFT 已经很高,泛化到全 suite 不一定成立
- ⚠️ “World model 在 unseen action 序列上 generalize”:Figure 6 / website video 是定性展示,没有定量 OOD benchmark
- ⚠️ Qwen3-VL judge 仅 50–55%:只跑 zero-shot,未尝试 fine-tuned VLM judge baseline,对比强度受限
- 暂未发现明显营销话术;声明的局限(long-horizon drift、sparse reward、real-world 高成本)都坦率列出
Notes
- 核心 insight:作者把 “video world model 不适合做 RL simulator” 这个一直被忽视的 gap 摆到桌面上,并用 reward hacking 的 narrative 论证了 closed-loop 的必要性。这比单纯堆 SR 提升数字有更长尾的影响。
- 可借鉴:reward head + diffusion latent 联合监督起到双向 regularizer 的发现,可能在其他 generative simulator 工作中复用(例如 driving world model 也存在同样的 action-following 问题)。
- 风险:长程任务的 quality drift 是 autoregressive video model 的根本限制,不是这个 framework 能解决的。如果未来 real-world 任务普遍是 long-horizon,这套方法的天花板很低。或许应该等 video generation 长程稳定性突破后再考虑这个方向。
- 对我自己研究的启示:在 VLA RL 方向上,“什么样的 reward 信号最适合 GRPO” 是一个值得追问的 sub-question——这篇论文给的是 binary threshold,但 step-wise dense signal、preference-based reward 都没在 video world model 框架下被认真探索。
- Open question:iterative refinement 收敛性?多少轮后会停止改进或退化?policy 与 world model 哪个 bottleneck 更先 hit?这些数据 paper 里没有,对实际工程化非常关键。
Rating
Metrics (as of 2026-04-24): citation=3, influential=0 (0.0%), velocity=1.2/mo; HF upvotes=0; github 21⭐ / forks=2 / 90d commits=21 / pushed 58d ago
分数:2 - Frontier 理由:这是 world-model-as-RL-simulator 方向 2026 年的一篇重要前沿工作——Strengths 里记录的 “reward head 双向 regularizer” 和 “reward hacking 实证 co-evolving loop 必要性” 是非平凡的方法贡献,直接推进了 WMPO / VLA-RFT / World-Env 未触及的问题;但不到 Foundation 档:Weaknesses 中的 real-world 仅 30 rollouts、LIBERO 只评 2/10 任务、主动放弃 LIBERO-Long、代码 “In preparation”、与多篇并行工作(2511–2601 之间的 WMPO / VLA-RFT / Cosmos Policy)尚未分出高下,所以还不是方向的必读奠基。也不算 Archived——它提出的 SANS + closed-loop 是此后 video-world-model-RL 绕不开的 reference。