Summary
Thinker: A vision-language foundation model for embodied intelligence
- 核心: UBTECH 出品的 ~10B 级 VLM 基座,瞄准机器人任务规划,主打修正一般 VLM 的”第一/第三人称视角混淆”和”视频末端信息忽视”两类失败模式
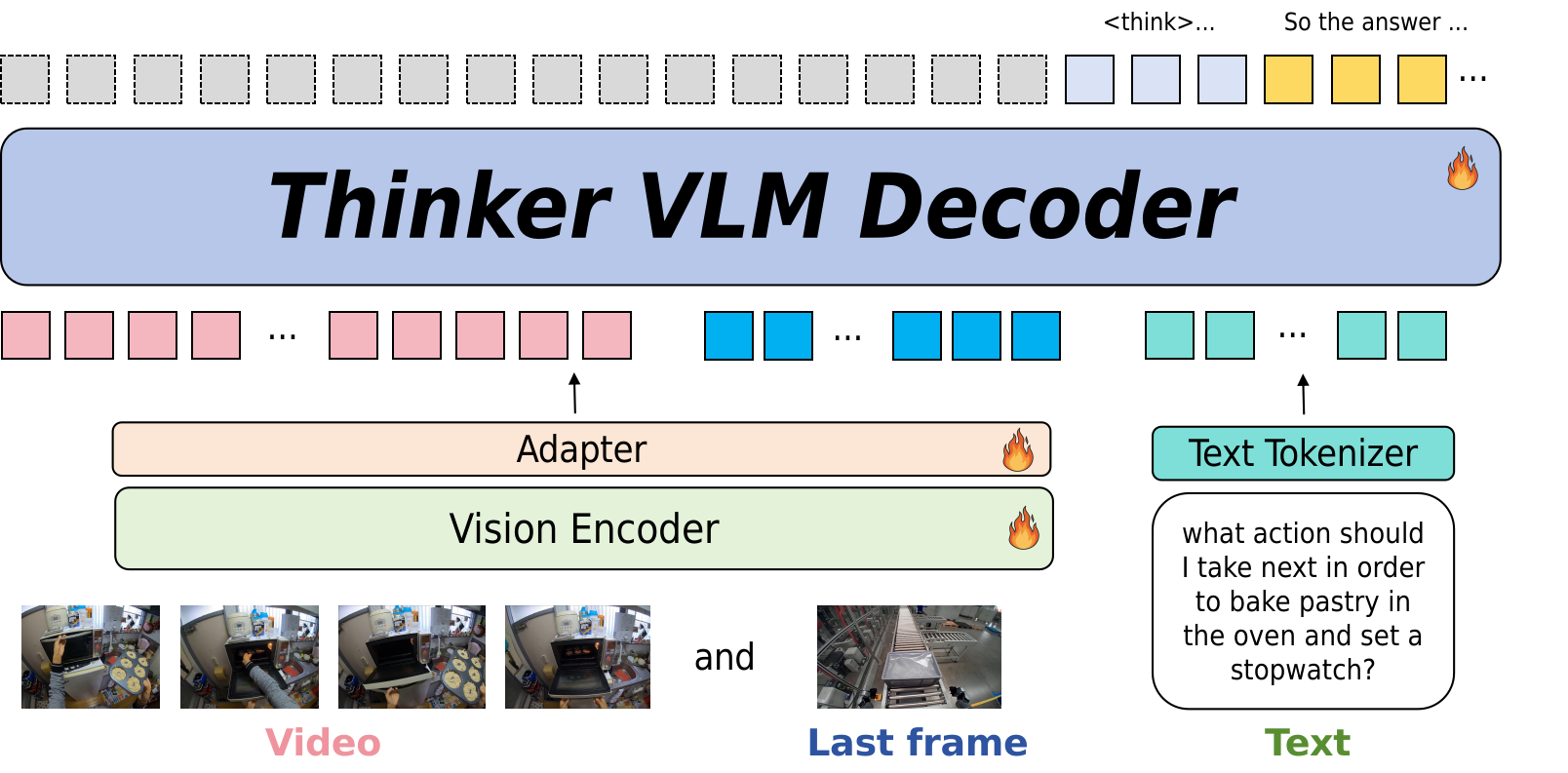
- 方法: (1) 拼装 4 类共 ~3.8M 样本的具身数据集(visual grounding + ego-view + manipulation planning + 自家 Industroplan),(2) 训练时把 video 的 last/key frame 作为辅助输入额外送入,(3) two-stage:基础能力 SFT → 下游 industroplan SFT
- 结果: Thinker-7B 在 RoboVQA(BLEU-avg 63.5)和 EgoPlan-Bench2(58.21 overall)上压过 RoboBrain-7B / RoboBrain2-32B / ThinkAct-7B 等
- Sources: paper | github
- Rating: 2 - Frontier(问题诊断有 insight,EgoPlan-Bench2 上 7B 反超 32B 是真实信号;但 short report 技术细节匮乏、ablation 缺失,够不上 Foundation)
Key Takeaways:
- 问题诊断比方法更值得关注:作者明确指出现有 VLM 在机器人场景下的两类典型 failure mode——视角混淆 + 视频尾部信息丢失。前者源于训练分布(VQA/caption 几乎全是第三人称),后者是 video token 截断/采样的副作用
- “key frame + full video 双输入”是个朴素但有效的工程修补:把 video clip 的末帧作为 auxiliary input 显式送进模型,绕开了 video encoder 对结尾帧的注意力衰减问题
- 数据是真正的 lever:4 类共 ~3.8M 的拼盘(含自家 Industroplan-200K)才是 7B 模型在 EgoPlan-Bench2 反超 RoboBrain2-32B 的主要动力,模型架构本身没有新东西(Qwen3-VL 全家桶)
- 报告本身只 4 页,技术细节几乎不披露——架构没说清是哪个 backbone(github 透露是 Qwen3-VL),训练超参、数据配比、消融全无。属于 “占坑式” short report
Teaser. 训练数据与工作流概览

Background & Motivation
作者把现有 VLM 应用到 robotics 时观察到两个反复出现的低级错误:
- 第一/第三人称视角混淆:通用 VLM 主要在 VQA / image caption 数据上训练,这些数据几乎全是第三人称。机器人 ego-view 输入下模型经常把”机械臂正在抓的物体”当成”远处别人在抓的物体”
- 视频尾部信息忽视:长视频任务规划时,关键状态往往出现在 clip 末尾(“刚抓起的物体”),但 video encoder 的均匀采样 + LLM 的 attention 偏移导致末端 token 影响力被稀释
这两个观察其实是 robotics 领域 VLM 实用化的真实痛点,比”再涨 0.3% SOTA”更有 insight。下文方法就是围绕这两点拼数据 + 改输入。
❓ paper 没给视角混淆 / 末端信息丢失的定量证据(比如对照实验:用同一 clip 改首/末帧顺序看 accuracy 差异),claim 停留在 motivation 层。
Training Data
Thinker 的训练数据由 4 类共 ~3.8M 样本拼成,绝大多数来自公开数据集 + 一份自家 Industroplan-200K。
Table 1. 四类构造数据集概览
| 类别 | 来源 | 规模 |
|---|---|---|
| Visual Grounding | Lvis-520K + Sharerobot-affordance-6.5K + Pixmopoint-570K + Robopoint-667K | 1.7M |
| Ego-View Reasoning | Egoplan-it-100K | 100K |
| Robotic Manipulation Planning | Robovqa-800K + Sharerobot-1M | 1.8M |
| Industrial Task Planning | Industroplan-200K(自家) | 200K |
各类的关键加工:
- Visual Grounding:bbox 部分 Lvis-520K 基于 PACO,用 GPT-4o 生成”哪个部分负责 X 功能”类 QA(功能性 grounding,比纯 detection 信息密度高);point 部分把 Pixmopoint / Robopoint 中 outdoor + 多于 10 点的样本剔掉
- Ego-View Reasoning:Egoplan-it-100K 基于 Egoplan-it 重构,每条包含 video clip + 末帧。设计了 open-ended 和 multi-choice 两种格式,多选题用真实 action 作正确答案,从其它序列随机抽 ≥3 个 action 做干扰项
- Manipulation Planning:Robovideo-1.8M 是 Robovqa-800K + Sharerobot-1M 的合并,覆盖 102 场景 + 12 robot embodiments(Open-X-Embodiment 派生)
- Industroplan-200K:自家工业场景多目标搬运任务,每条带 video demo + task goal + chain-of-thought 标注,强调 long-horizon
❓ 没说 CoT 标注是人工还是 GPT 蒸馏;Industroplan 是否会开源也没提。
Model Architecture
声称是”~10B 级 VLM”,论文正文里只画了一个 4 模块的抽象框图:text tokenizer + visual encoder + MLP projector + LLM backbone。具体 backbone 是什么没说。
Figure 2. Model architecture(抽象框图)
GitHub README 才透露真相:放出的 checkpoint 是 Thinker-4B,基于 Qwen3-VL(Qwen3VLForConditionalGeneration + AutoProcessor)。也就是说 paper 报的 “Thinker-7B” 和 release 的 “Thinker-4B” 是两个版本,且 backbone 都是 Qwen3-VL 的派生。
❓ paper 报 7B 数字,release 是 4B,正文又说 “ten billion level parameters”——三个量级的不一致很奇怪。是 7B 用了不同 backbone?还是写作时还在大模型上跑、release 时退回小模型?没有解释。
Training Strategy
Two-stage SFT:
- Stage-1 — Building Embodied Capabilities:在 general data + spatial understanding data + 大规模 planning data 的混合上做 fine-tune;关键技巧:训练 video understanding 时把 clip 的 last frame 作为 auxiliary input 一起送进去
- Stage-2 — Downstream Task Fine-Tuning:在 Industroplan-200K 上做 SFT,把通用 reasoning 能力对齐到具体工业任务
“key frame + full video 双输入” 是这篇论文 motivation 层最值得记的东西——朴素直接,但贴合”VLM 容易忽视视频尾部”这个 failure mode。它不需要改架构,纯从输入侧用工程手段绕开问题。
❓ paper 没给 ablation 量化”加 last frame” 到底涨了多少点,所以无法判断这是核心 contributor 还是 marginal trick。
Infrastructure(无具体数字)
Section IV 谈了一些 infra:unified sampling schema、dynamic sampler(按 validation feedback 动态调任务配比)、sharded loading、selective freezing、periodic checkpointing、per-task loss 监控。全是高层描述,没有 throughput / cluster 规模 / training time / 任何超参。可信度 = 0,不可复现。
Evaluation Results
Table 2. RoboVQA 与 EgoPlan-Bench2 上的对比(粗体=最优)
| Model | RoboVQA BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | BLEU-avg | EgoPlan Daily | Work | Recreation | Hobbies | Overall |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen2.5-VL-7B | 62.2 | 54.6 | 48.7 | 45.0 | 52.6 | 31.4 | 26.7 | 29.5 | 28.6 | 29.1 |
| GPT-4V | 32.2 | 26.5 | 24.7 | 23.9 | 26.8 | 36.7 | 27.7 | 33.9 | 32.5 | 32.6 |
| Cosmos-Reason1-7B | / | / | / | / | / | 30.7 | 31.6 | 20.3 | 20.3 | 26.8 |
| ThinkAct-7B | 69.1 | 61.8 | 56.0 | 52.4 | 59.8 | 50.1 | 49.8 | 44.8 | 45.2 | 48.2 |
| RoboBrain-7B | 72.05 | 65.35 | 59.39 | 55.05 | 62.7 | / | / | / | / | / |
| RoboBrain2-7B | 37.4 | 31.0 | 27.1 | 25.8 | 30.0 | 39.41 | 32.20 | 33.88 | 26.98 | 33.23 |
| RoboBrain2-32B | / | / | / | / | / | 64.01 | 53.22 | 57.92 | 52.48 | 57.23 |
| Thinker-7B | 72.7 | 65.7 | 59.5 | 56.0 | 63.5 | 63.78 | 54.95 | 61.20 | 52.54 | 58.21 |
主要观察:
- RoboVQA:Thinker-7B 比 RoboBrain-7B 仅高 0.8(63.5 vs 62.7)。BLEU 上的小幅领先在 free-form 文本评测里基本是噪声范围
- EgoPlan-Bench2:Thinker-7B (58.21) 反超 RoboBrain2-32B (57.23),4/4 类别中 3 个第一。这个对比更有说服力,因为打过了 4× 参数的对手
- 注意 RoboBrain2-7B 在 RoboVQA 上只有 30.0 BLEU-avg——和它 7B 上的 EgoPlan 33.23 一致,说明 RoboBrain2 系列的小尺寸版本明显能力不足,这给 Thinker 留出了 baseline 空间
❓ baseline 选择有挑选感:缺了 LLaVA-OneVision、InternVL3、Qwen2.5-VL-72B 等同 size 范围的强 video VLM。
Performance 解读
paper 自评:
- RoboVQA 上 Thinker-7B 全 BLEU 第一,说明能”parse fine-grained spatiotemporal cues and decompose complex long-range planning tasks”
- EgoPlan-Bench2 上跨 4 域 3 个第一,“adept at common household and recreational tasks but also exhibits competitive planning ability in professional and work-related scenarios”
我的判断:在 EgoPlan-Bench2 上反超 4× 大小的 RoboBrain2-32B 是真实 signal,归因大概率是 (a) 数据配方包含 EgoPlan-it-100K 同源数据,(b) last-frame 辅助输入贴合 EgoPlan benchmark 的”看视频选下一动作”格式。但论文没做 ablation 隔离这两个因素的贡献。
关联工作
基于
- Qwen3-VL: github release 的 Thinker-4B 是 Qwen3-VL 派生(
Qwen3VLForConditionalGeneration),这是真正的 backbone 来源 - Open-X-Embodiment: Sharerobot-1M 派生自其 102 场景 + 12 embodiments
对比
- RoboBrain (CVPR 2025): RoboVQA 上同尺寸最强 baseline (62.7 BLEU-avg),被 Thinker-7B 险胜 0.8
- RoboBrain 2.0: EgoPlan-Bench2 上的 32B 巨兽 (57.23 overall),被 7B Thinker 反超
- ThinkAct: VLA reasoning via reinforced visual latent planning (arXiv 2507.16815),在 EgoPlan/RoboVQA 都参评
- Cosmos-Reason1: NVIDIA 的具身推理 VLM,同尺寸但 EgoPlan 表现弱 (26.8)
- Qwen2.5-VL-7B / GPT-4V: 通用 VLM 基线
方法相关
- EgoPlan / EgoPlan-Bench2: 训练数据 (Egoplan-it-100K) 和评测 benchmark 都来自这一系列
- RoboVQA: 既是数据来源 (Robovqa-800K) 又是评测 benchmark——存在 train/test 同源风险,作者未澄清是否做了切分隔离
- RoboPoint (arXiv 2406.10721): point grounding 数据来源
- Molmo / Pixmo: Pixmopoint-570K 数据来源
- PACO (CVPR 2023): Lvis-520K 的功能性 grounding 数据基底
论文点评
Strengths
- 问题观察接地气:视角混淆 + 视频尾部信息丢失这两个 failure mode 是真实存在且 underexplored 的,比”再涨 0.x SOTA”更有 insight 价值
- “key frame + full video 双输入” 简单直接:不改架构,从输入侧绕开问题,scalable 且 compatible 任意 video VLM
- 数据工程扎实:4 类 ~3.8M 拼盘 + 自家 Industroplan-200K,覆盖空间/时间/规划/工业,给了 7B 模型反超 32B 的弹药
- 结果有亮点:EgoPlan-Bench2 上以 7B 战胜 32B 是真实的小模型胜利
Weaknesses
- 极度缺乏技术细节:4 页 short report,无超参、无数据配比、无消融、无训练 time/compute,“key frame 输入” 这个核心 trick 到底涨了多少点完全不知道
- 架构”~10B”含糊不清:paper 报 7B,release 4B,正文写 “ten billion level”,三个数不一致也不解释
- Infra section 几乎全是空话:“unified sampling schema""dynamic sampler” 这些词没有具体指代,可信度 = 0
- baseline 选择有挑选感:缺了同 size 段的强 video VLM 对比
- Industroplan 不开源:作为关键差异化数据集,没说会不会开放,限制了独立复现
- 论文 vs release 的 model 不一致:paper 评测的是 Thinker-7B,HuggingFace 上只有 Thinker-4B,没有交代两个 model 关系或 4B 的对应数字
可信评估
Artifact 可获取性
- 代码: inference-only(github 给了 transformers 推理 snippet,无训练代码)
- 模型权重: Thinker-4B(Qwen3-VL 派生)已发 HuggingFace
UBTECH-Robotics/Thinker-4B;Thinker-Thinking-4B 标 “coming soon”;paper 评测的 Thinker-7B 未发布 - 训练细节: 仅高层描述(two-stage SFT,last-frame auxiliary input),无超参/无数据配比/无 step 数
- 数据集: 部分公开(拼盘组件 Lvis / Pixmopoint / Robopoint / Egoplan-it / Robovqa / Sharerobot 均开源),Industroplan-200K 私有未说明开源计划
Claim 可验证性
- ✅ RoboVQA / EgoPlan-Bench2 数字:标准 benchmark,可由第三方在发布的 4B 上复现验证(虽然 paper 报的是 7B)
- ⚠️ “视角混淆 + 视频尾部忽视” 是 main failure mode:仅 motivation 层定性叙述,无对照实验定量证据
- ⚠️ “key frame + full video 双输入” 显著提升 video understanding:方法 section 声称 “substantially enhances”,但无 ablation 数字支撑
- ⚠️ “~10B parameters”:与 release 的 4B 矛盾,paper 评测的 7B 也未公开,参数量 claim 半可信
- ❌ Infra 章节的工程亮点:“unified sampling schema""dynamic sampler” 等词无具体指代,属营销话术
Notes
- arxiv id
2601.21199看着像月份越界(21199 末尾),但实际是 2026-01 的合法 id(arxiv 2026 年改了编号格式,5 位序号) - 文章 Future works 提到 “soon release the full technical report… open-source architecture and weights”,目前只放了 4B,等正式技术报告
- Train/test contamination 风险:Robovqa-800K 在训练集里,RoboVQA 又是评测 benchmark;Egoplan-it-100K 在训练集里,EgoPlan-Bench2 是评测——不算严重违规(标准做法是 train/test split),但论文没明确说切分协议
- 这篇属于”为开源 model 占坑发的 short report”。RoboBrain 系列已经把 robotic VLM 这个赛道竞争得很激烈,UBTECH 作为商用人形机器人厂商发自家 model,更多是商业品牌信号而非纯学术贡献
- 值得追踪:full technical report 出来后再看是否真有 insight;Industroplan 数据集是否会开源
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.00/mo; HF upvotes=0; github 40⭐ / forks=6 / 90d commits=59 / pushed 57d ago
分数:2 - Frontier 理由:这篇作为 4 页 short report,问题诊断(视角混淆 + 视频尾部忽视)接地气、“last frame auxiliary input” 方法朴素且可被后续 video VLM 继承,EgoPlan-Bench2 上 7B 反超 32B RoboBrain2 是真实 signal——够得上被 robotic VLM 方向作为 baseline 参考的 Frontier 档。够不上 Foundation 是因为技术细节严重缺失(无超参/无 ablation/Infra 章节空话)、论文报的 7B 与 release 的 4B 不一致、Industroplan 不开源;也高于 Archived 是因为方向相关、baseline 价值未被取代,full technical report 出来后还值得回看。2026-04 复核:发表 2.8 月(<3mo 豁免窗口)citation=0/influential=0 但 github 40⭐ + 近 90 天 59 commits 显示活跃维护,属典型 <3mo 早期 signal 形态,维持 Frontier。