Summary
AirNav: A Large-Scale Real-World UAV Vision-and-Language Navigation Dataset with Natural and Diverse Instructions
- 核心: 提出 AirNav——基于真实城市航拍数据(SensatUrban)构建的 143K 样本 UAV-VLN benchmark,配合 persona-conditioned LLM 生成的”自然+多样”指令,再训出 AirVLN-R1(Qwen2.5-VL-7B + SFT + GRPO RFT)作为 baseline。
- 方法: 4 步 pipeline 构造数据(起终点采样 → 路标规划 → look-ahead trajectory 合成 → 10 种 persona 指令生成);模型用 Progressive Interval Sampling 压缩历史观测,RFT 阶段设计 distance-to-subgoal / heading-alignment / stop-consistency / format 四类 reward。
- 结果: 在 test-unseen 上 SR=51.75%,显著好于 GPT-4o(4.29%)、GPT-5(2.62%)和 Qwen3-VL-235B-A22B(4.94%);real-world 测试 SR=6/20 (NE=67.29)。
- Sources: paper | website | github
- Rating: 2 - Frontier(UAV-VLN 方向的 frontier dataset + R1-style baseline;benchmark 规模和 persona 设计有实际价值,但方法 novelty 弱,未成为 de facto 标准)
Key Takeaways:
- “Real-world data”≠“real flight”:所谓 real urban data 仍来自 SensatUrban 的 photogrammetric point cloud + CityFlight 模拟器渲染,并非真实 onboard camera。视觉真实度 vs. AerialVLN/OpenUAV 的 game-engine 提升有限,但 spatial structure 更贴近真实城市。
- Persona-conditioned instructions 是主要的”naturalness”杠杆:用 10 种社会角色(小学生 / 快递员 / 退休老人 …)prompt LLM,配合 human-authored few-shot examples,把 instruction 风格从模板化推到 GPT-4o 评分 3.75/5(vs. 其他 benchmark <3)。但评分本身用 GPT-4o 自评,存在 self-preference bias。
- SFT+RFT 真正起作用的是 SFT:Qwen2.5-VL-7B SFT-only 已达 SR=43.89/40.68/39.56(seen/unseen/test),加 RFT 涨到 51.79/51.66/51.75——RFT 提升 ~7-12 pp 但属于”在 SFT 强基础上的精修”;RFT-only 只有 ~2% SR,验证了 cold-start RL 在 sparse-reward navigation 上的失败。
- Sim-to-real gap 仍巨大:benchmark SR ~52% vs. real-world SR=6/20=30%(且只 20 个 task)。论文没有量化 indoor vs outdoor 的差异,real-world 评测细节都在 appendix。
Teaser. AirNav benchmark 4 步构造 pipeline——SensatUrban 提供 3D 点云、CityRefer 提供物体描述、CityFlight 作为交互环境;MLLM 负责起终点筛选、路标识别、指令生成。

1. Motivation
现有 UAV VLN benchmark 的三个核心问题:
- 环境合成化:LANI / AerialVLN / OpenUAV / OpenFly 主要基于 game engine 或纯虚拟环境,缺少真实城市的复杂 spatial structure 和 texture。
- 指令模板化:CityNav/OpenUAV 只描述目标,不给 intermediate landmark;其他用 template 生成的指令风格单一。
- 规模有限:大多数 <30K 样本,无法支撑 large-scale model evaluation。
❓ 这里有个微妙的 framing 问题:AirNav 自称 “real-world”,但其数据源 SensatUrban 是 photogrammetric reconstruction 后的 point cloud,CityFlight 是模拟器渲染,本质仍是 sim 数据。论文用 “real urban aerial data” 这个表述容易让读者误以为是真飞行数据。
2. AirNav Benchmark
2.1 Task Definition
UAV VLN 被建模为部分可观测序列决策问题。每步 ,agent 接收多模态观测 :
- :first-person 图像
- :UAV 状态(位置 + heading)
- :历史动作
- :自然语言指令
策略 输出一个变长动作序列 ,可选动作:forward / turning left / turning right / stop。
Success criteria: 终点距离 < 20m。Metrics: NE / SR / OSR / SPL(参 SOON, CityNav)。
2.2 数据构造 4 步 Pipeline
| Step | 操作 |
|---|---|
| 1. Start & Target Selection | 在地图上随机采可行起点,选择 well-defined boundary 的物体作为目标,MLLM 生成目标自然语言描述 |
| 2. Landmark Planning | MLLM 在起点—终点之间识别代表性 landmark,要求相邻 landmark 距离不太大;对每个 landmark 描述做 fact-checking + rewrite |
| 3. Trajectory Synthesis | 对每对相邻节点,用 look-ahead 策略生成动作序列;拼接成完整轨迹 |
| 4. Instruction Generation | 输入 trajectory + map + 节点位置和描述,结合 10 种 user persona + few-shot human examples,让 MLLM 生成最终指令 |
2.3 Dataset Statistics
Table 1. AirNav vs. 现有 UAV VLN 数据集
| Dataset | Collection Env. | Action Space | Size | Sub-goals | Naturalness | Vocab |
|---|---|---|---|---|---|---|
| LANI (2018) | Virtual | 2 DoF | 6,000 | Yes | Medium | 2.3K |
| AVDN (2022) | Real-world | 3 DoF | 3,064 | Yes | Medium | 3.3K |
| AerialVLN (2023) | Virtual | 4 DoF | 8,446 | Yes | Medium | 4.5K |
| CityNav (2024) | Real-world | 4 DoF | 32,637 | No | N/A | 6.4K |
| OpenUAV (2024) | Virtual | 6 DoF | 12,149 | No | N/A | 10.8K |
| OpenFly (2025) | Virtual+Real | 4 DoF | 100k | Yes | Medium | 15.6K |
| AirNav (Ours) | Real-world | 4 DoF | 143k | Yes | High | 20.7K |
注:这里的 “Real-world” 指数据源是 real aerial point cloud / map,而非 game engine——但仍是 sim-rendered 视觉。
难度分级:训练集路径长度的 33/66 分位数(135m / 235m)作为阈值,分 Easy / Medium / Hard。Splits: Train / Val-seen / Val-unseen / Test-unseen。
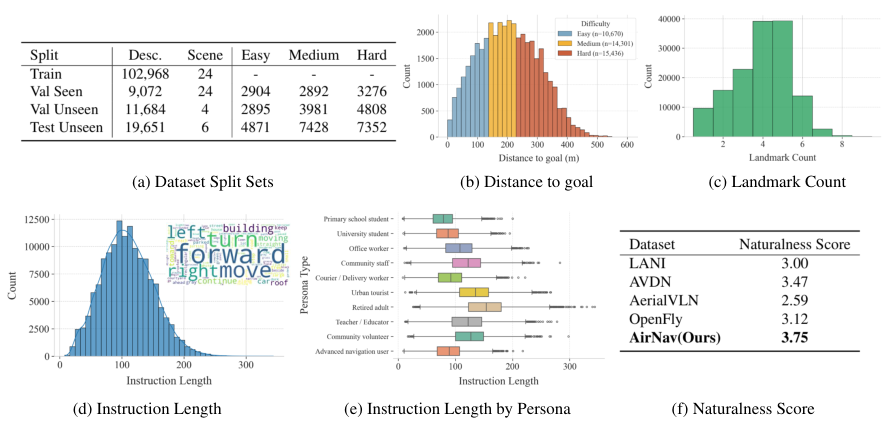
Figure 2. 数据集分析。 (a) 各 split 统计;(b) 距离分布;(c) landmark 数(多数 4-5 个);(d) 指令长度(peak ~100 词);(e) persona-specific 指令长度(退休老人最长,学生最短);(f) naturalness 分数对比(AirNav 3.75 居首)。
Persona 设计:10 种 persona(P1 小学生—P10 高级导航用户),按年龄、社会角色、表达偏好划分,覆盖典型城市导航场景。
Naturalness 评估:每个 dataset 抽 2000 条指令,GPT-4o 用统一 prompt 打 1-5 分(每条独立打 3 次取均值)。AirNav 3.75 vs 其他 benchmark 均 <3。
❓ 用 GPT-4o 评估 GPT-生成的指令的 “naturalness”,会不会有 self-preference bias?论文做了人类 annotator 校准(在 Appendix F),但 inter-annotator agreement 数值没在正文给出。
3. AirVLN-R1 Model
3.1 整体架构
AirVLN-R1 = Qwen2.5-VL-7B + 两阶段训练(SFT → GRPO RFT),在 8×A100 上训练。
每步接收:
- Text:instruction、current state (x, y, z, yaw)、historical action sequence
- Visual:current view + 选择性的 historical views
输出:变长动作序列(最多 8 步)。
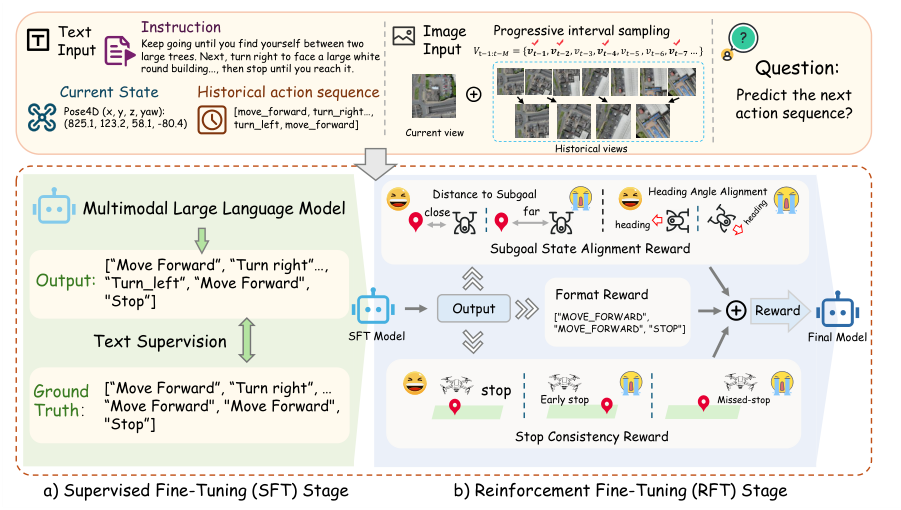
Figure 3. AirVLN-R1 架构总览。 左:SFT 阶段做 next-token prediction 监督;右:RFT 阶段用 distance-to-subgoal、heading-alignment、stop-consistency、format 四类 reward 优化策略。
3.2 Progressive Interval Sampling
直接用全部历史图会爆显存。用一个递归定义的 sampling offset ,近期密、远期稀:
即 offsets 形如 0, 1, 3, 6, 10, …(最多保留 N 张)。直觉上 recent observation 信息密度高、需要细粒度,远期只需粗粒度上下文。
3.3 Reward 设计
借鉴 VLN-R1 和 DeepSeek-R1 的 GRPO 思路,设计 4 类 reward:
1. Subgoal State Alignment
- Distance-to-Subgoal: 鼓励减小 UAV 到 subgoal 距离
- Heading Alignment: 衡量执行后的 heading 与 subgoal heading 的对齐度
其中 为容忍度(如 60°)。
2. Stop Consistency Reward: 预测和 GT 都以 stop 结尾给 ;都不以 stop 结尾给 ;其余为 0。意图防止 early-stop / missed-stop。
3. Format Reward: 输出 well-formed 给 ,否则 0。
Overall:
3.4 训练范式
- SFT 阶段:next-token prediction,cross-entropy on (multimodal obs → action seq)
- RFT 阶段:GRPO 优化以上 reward
- 灵感自 DeepSeek-R1 的 SFT→RL 两段式
4. Experiments
4.1 Main Results
Table 2. AirNav benchmark 主结果(粗体为 best)
| Method | Val-Seen NE↓ / SR↑ / OSR↑ / SPL↑ | Val-Unseen | Test-Unseen |
|---|---|---|---|
| Random | 222.3 / 0.79 / 5.59 / 0.71 | 225.0 / 0.72 / 4.57 / 0.64 | 218.9 / 0.77 / 5.31 / 0.67 |
| Seq2Seq | 321.5 / 1.58 / 9.50 / 1.40 | 348.8 / 0.92 / 9.35 / 0.72 | 336.1 / 1.28 / 10.31 / 1.08 |
| CMA | 185.9 / 5.13 / 15.96 / 4.73 | 203.6 / 4.03 / 15.71 / 3.62 | 190.3 / 4.48 / 17.06 / 4.03 |
| Qwen2.5-VL-7B (zero-shot) | 183.1 / 1.82 / 2.18 / 1.68 | 194.1 / 1.57 / 1.74 / 1.38 | 186.2 / 1.65 / 1.88 / 1.46 |
| Qwen2.5-VL-32B (zero-shot) | 161.6 / 3.02 / 3.36 / 2.73 | 172.1 / 2.64 / 2.94 / 2.36 | 164.4 / 2.84 / 3.09 / 2.52 |
| Qwen3-VL-235B-A22B | 157.6 / 5.50 / 9.12 / 5.12 | 169.1 / 5.18 / 8.32 / 4.66 | 157.1 / 4.94 / 7.98 / 4.48 |
| LLaMA-3.2-11B-Vision | 180.5 / 1.10 / 5.29 / 0.93 | 194.3 / 1.37 / 4.45 / 1.23 | 178.6 / 1.31 / 1.44 / 1.03 |
| GPT-4o | 155.4 / 4.53 / 8.53 / 4.07 | 165.8 / 4.13 / 7.06 / 3.71 | 157.9 / 4.29 / 7.48 / 3.88 |
| GPT-5 | 151.2 / 2.87 / 3.19 / 2.59 | 157.0 / 2.52 / 2.62 / 2.20 | 154.4 / 2.62 / 2.79 / 2.34 |
| Qwen2.5-VL-7B SFT-only | 45.8 / 43.89 / 54.56 / 42.66 | 49.2 / 40.68 / 52.03 / 39.61 | 48.3 / 39.56 / 52.41 / 38.52 |
| Qwen2.5-VL-7B RFT-only | 165.7 / 2.33 / 4.75 / 2.10 | 175.0 / 2.07 / 3.86 / 1.82 | 165.8 / 2.31 / 4.39 / 2.03 |
| AirVLN-R1 (Ours) | 39.6 / 51.79 / 61.45 / 50.63 | 41.0 / 51.66 / 61.68 / 50.45 | 40.0 / 51.75 / 62.29 / 50.57 |
关键观察:
- 所有 zero-shot MLLM(包括 GPT-5、Qwen3-235B)SR < 6%——这个 task 对 frontier MLLM 仍是 hard task
- SFT-only 已经把 SR 从 ~5% 拉到 40+%;RFT 再提 ~10 pp
- AirVLN-R1(7B)反超 32B/235B baseline,task-specific supervision >> model scale on this benchmark
- val-seen → val-unseen → test-unseen 的 SR 几乎不掉,generalization 表现稳定
4.2 Ablation:训练范式
- SFT-only:建立 multimodal→action 基础映射,但局限于 trajectory imitation,unseen 泛化差
- RFT-only:cold-start 下 reward 太稀疏,policy 收敛在 suboptimal
- SFT+RFT:SFT 提供初始策略,RFT 精修决策——best & most stable
这与 DeepSeek-R1 的发现一致:sparse-reward task 需要 SFT cold-start。“R1-Zero” 风格在 navigation 这种 long-horizon sparse-reward 任务上仍不可行。
4.3 Real-World Test
部署到真实 UAV 平台,10 个 indoor + 10 个 outdoor task,无任何 fine-tuning。
- Traditional baselines: 0/20 success
- Zero-shot MLLM: 极少数成功
- GPT-4o: notable improvement,但仍有限
- AirVLN-R1: SR = 6/20, NE = 67.29——最佳,但绝对值很低
failure modes 和 sim-to-real challenges 在 Appendix N。
❓ Real-world SR=30% 而 sim SR=52%,gap 22 pp。论文没有拆分 indoor/outdoor SR。indoor 测试用城市训练数据训出来的模型 zero-shot 测,性能能跨域迁移本身就奇怪——值得追问 indoor task 是否过度简化。
5. Limitations(来自论文)
- 数据源单一:SensatUrban + CityRefer 限制了 city style / season / 视角分布
- 离散动作 vs 连续控制 gap:8 步离散 action 序列在精细操控时有近似误差
- Sim-to-real gap 量化不足:real-world 测试规模和复杂度都有限
关联工作
基于
- SensatUrban (Hu et al., 2022): 真实城市 photogrammetric point cloud 数据源,提供 Cambridge + Birmingham
- CityRefer (Miyanishi et al., 2023): SensatUrban 上的物体自然语言描述
- CityFlight (Lee et al., 2024): 把 SensatUrban 与 OpenStreetMap 对齐的交互 flight 环境
- Qwen2.5-VL-7B: AirVLN-R1 的 base model
- DeepSeek-R1 (DeepSeek-AI 2025): 两阶段 SFT→RL 训练范式的灵感来源;GRPO 算法直接复用
对比 (UAV VLN benchmarks)
- LANI (Misra 2018): 最早的 UAV VLN,simplified scene
- AVDN (Fan 2022): real-world dialog, 但规模小
- AerialVLN (Liu 2023): simulated env,明确包含 intermediate steps
- CityNav (Lee 2024): real-world aerial imagery,但只有 target description, 无 intermediate guidance
- OpenUAV (Wang 2024): 6-DoF + LLM-generated + human-refined,但仍是 sim
- OpenFly (Gao 2025): multi-source rendering + automated toolchain,但 instruction 全 LLM 生成,缺自然性
方法相关
- VLN-R1: ground VLN 上的 SFT+GRPO RFT,技术路线高度相似——本文可视为其在 UAV/aerial 领域的对应
- GRPO (DeepSeek-Math/R1): policy optimization 算法
- CMA (cross-modal alignment): VLN 的经典 baseline
- SOON (Zhu 2021): VLN 评估指标体系
论文点评
Strengths
- 数据规模和指令多样性确实是 community 进步:143K 样本 + 20.7K 词汇量 + persona-conditioned 生成,对训练大模型有实际价值
- 完备的 baseline 体系:从 Seq2Seq、CMA 到 GPT-5、Qwen3-235B 全套覆盖,给后续 benchmark user 一个清晰的 reference table
- GRPO reward 设计务实:distance-to-subgoal + heading-alignment 把 sparse navigation reward dense 化,stop-consistency 直击 VLN 核心 failure mode
- Real-world deployment 至少做了:尽管规模有限,但展示了 sim-trained 模型在真机上的初步可用性
Weaknesses
- “Real-world” framing 有 overclaim 嫌疑:数据源仍是 photogrammetric reconstruction → CityFlight 渲染。视觉上和 game engine 的差距没有定量比较。真要 claim real-world,应该用真实 onboard camera 数据
- Naturalness 评估 self-validation:用 GPT-4o 给 GPT-4o 生成的指令打分,是 circular reasoning 的弱形式。Human calibration 数据应该在主文给出 Cohen’s kappa 等具体数值
- AirVLN-R1 的 novelty 较弱:架构 = Qwen2.5-VL-7B + SFT + GRPO + 4 个 rule-based reward,这套范式 VLN-R1 已经在 ground VLN 上做过。本文的 contribution 主要在 dataset 上而非 model 上
- 缺少 task complexity vs SR 的细分:Easy/Medium/Hard 分类已定义但主表里没拆,无法判断模型在 long-horizon (>235m) 上的真实表现
- GPT-5 比 GPT-4o 差这种反常现象没有讨论——可能 prompt 不公平 or GPT-5 倾向于过度 reasoning 导致输出 format 不符
- Real-world SR 6/20 + 没有 video demo:缺少最关键的 qualitative evidence
可信评估
Artifact 可获取性
- 代码: 已开源在 https://github.com/nopride03/AirNav,README 显示有 data_generation pipeline 和环境配置
- 模型权重: 未说明
- 训练细节: 仅高层描述(Qwen2.5-VL-7B + 8×A100),具体超参在 Appendix J(未读完整 PDF 此部分)
- 数据集: 开源(与代码同 repo),143K 样本
Claim 可验证性
- ✅ AirNav benchmark SR 数字 (Table 2): 论文中表格清晰,benchmark 公开可独立复现
- ✅ SFT >> RFT-only 的训练范式 finding: ablation 数据完整,结论扎实
- ⚠️ “Naturalness 3.75 显著高于其他 benchmark”: 评估器(GPT-4o)和被评对象(GPT-生成的指令)同源,存在 self-preference bias;human calibration 数据需查 Appendix F
- ⚠️ “Real urban data”: 实际是 sim-rendered 视觉,称谓与读者预期不符
- ⚠️ Real-world SR=6/20 (30%): 任务量小(20 个),且没有 video qualitative evidence;实际部署可靠性存疑
- ⚠️ “Strong cross-scene generalization”: val-seen/unseen/test 性能几乎相同确实漂亮,但所有 split 都来自同一个 SensatUrban 数据源(Cambridge + Birmingham),跨城市/跨国家 generalization 未验证
- ❌ “Initial evidence of feasibility and consistency of sim-to-real transfer”: 6/20 SR + 缺乏 failure analysis 难以支撑这个 claim 强度
Notes
- 这篇本质是**“benchmark + R1-style training recipe 在 aerial VLN 的应用”**,benchmark 是主 contribution。模型层面 novelty 弱,但作为 community resource 有价值。
- 追问:persona-conditioned instruction 的真实价值是什么?如果只是让指令”听起来自然”但 task 难度不变,那对模型训练的 transfer value 是不清楚的。需要做 ablation: 用模板化指令 vs persona 指令训出的模型,在真实人类指令上的表现差异。
- 可借鉴的设计:look-ahead trajectory synthesis + persona-prompted instruction generation 这套 data pipeline 可迁移到其他 navigation/embodied 任务做 data scaling。
- 下一步问题:(1) 跨城市/跨国家 generalization 如何?(2) Easy vs Hard task 上的 SR 差距?(3) Real-world 的 indoor 和 outdoor 分别 SR 是多少?(4) 用 GPT-5 表现差是 prompt 问题还是 model 问题?
- 与 VLN-R1 对比:VLN-R1 在 ground VLN 上做同样的 SFT+GRPO;AirNav 把这套搬到 aerial。说明 R1-style recipe 在各 navigation domain 都有效,但也说明这条路 commoditize 得很快——做 follow-up 需要更深的方法 novelty。
Rating
Metrics (as of 2026-04-24): citation=2, influential=1 (50.0%), velocity=0.57/mo; HF upvotes=N/A; github 19⭐ / forks=1 / 90d commits=6 / pushed 3d ago
分数:2 - Frontier 理由:作为 UAV-VLN 方向的 benchmark + R1-style training recipe,143K 样本 + persona-conditioned instruction 的规模和多样性在现有 aerial VLN dataset 中居首(见 Table 1,相比 OpenFly 100K / CityNav 32K),有被后续工作作为 baseline 的潜力——这是 Frontier 档的典型特征。不够 3 - Foundation 是因为:(1) 论文 2026-01 新发,尚未形成社区采纳证据;(2) “real-world” framing 有 overclaim 嫌疑,视觉仍是 sim-rendered;(3) 方法层面与 VLN-R1 高度重合,novelty 主要在 dataset 而非 method;这些风险让它难以成为 de facto 标准。不降到 1 - Archived 是因为 dataset 本身质量和规模有实打实的 community 价值,不属于 incremental / niche。2026-04 复核:3.5 月 2 citation / 1 influential (50%,仅 2 篇基数偏小) / github 19⭐ 但近 3 天仍有提交(活跃维护),属典型 <3mo 新发 benchmark 的早期信号形态,维持 Frontier。