Summary
BEHAVIOR-1K
- 核心: 基于人类需求调查的 1,000 活动 Embodied AI benchmark + OmniGibson 高保真仿真器
- 方法: BDDL 谓词逻辑定义活动 + OmniGibson (Omniverse + PhysX 5) 支持刚体/可变形体/流体仿真
- 结果: 端到端 RL 完全失败;action primitives + 辅助抓取可达 ~50-88% 成功率;sim-to-real 迁移差距显著(0% 真实成功率)
- Sources: paper | website | github
- Rating: 2 - Frontier(1000 活动 + 物理仿真多样性为 embodied AI 提供前所未有的 benchmark 规模,2025 年举办 BEHAVIOR Challenge 被社区采纳,但尚未像 ImageNet/DROID 那样成为 de facto 标准,且仅 3 个活动的实验未充分验证 benchmark 整体难度分布)
Key Takeaways:
- Human-grounded activity sourcing: 通过 1,461 名参与者的调查确定人类最希望机器人完成的活动,而非由研究者自行设计任务,保证 benchmark 真正反映人类需求
- Diversity + Realism 的统一: 1,000 活动 × 50 场景 × 9,000+ 物体,同时 OmniGibson 支持刚体、可变形体、流体、柔性材料的物理仿真,打破了既有 benchmark diversity-realism 的 trade-off
- 当前 AI 远未解决: 端到端 visuomotor RL 完全失败(0% 成功率),即使注入 action primitives + 辅助抓取仍难以可靠完成长 horizon 任务;sim-to-real 迁移差距显著
Teaser. 人类需求调查结果与 OmniGibson 仿真可视化

Introduction
现有 Embodied AI benchmark 的活动由研究者设计,未经验证是否真正反映人类需求。BEHAVIOR-1K 的核心动机是让 benchmark 不仅 for human needs,而且 from human needs。
作者观察到人类日常需求的两个关键维度:
- Diversity: 最需要的活动从 “wash floor” 到 “clean bathtub”,跨越了远超真实世界机器人挑战赛所能覆盖的种类
- Realism: 仿真环境必须准确再现现实条件(流体、可变形体、温度变化等),否则 sim-to-real 迁移无从谈起
BEHAVIOR-1K 由两个核心组件构成:
- BEHAVIOR-1K Dataset: 1,000 活动定义(BDDL 谓词逻辑)+ 50 场景 + 9,000+ 物体模型(含丰富物理和语义标注)
- OmniGibson: 基于 NVIDIA Omniverse + PhysX 5 的仿真环境,支持刚体、可变形体、流体的物理仿真和光线追踪渲染
Creating a Benchmark Grounded in Human Needs: A Survey Study
活动来源于时间使用调查(American/European/Multinational Time Use Surveys)和 WikiHow 文章,共收集约 2,000 个候选活动。通过 Amazon Mechanical Turk 对 1,461 名参与者进行 10-point Likert scale 调查,收集每个活动的 “你多想让机器人帮你做这件事” 偏好评分。
核心发现:
- 偏好分布具有高度统计离散性(Gini index = 0.158),人类希望机器人完成多样化的活动
- 繁琐的清洁任务(如 “scrubbing the bathroom floor”)评分最高,娱乐活动评分最低
- 约 200 个清洁活动和 200+ 个烹饪活动位列前茅
最终选取偏好评分最高的 909 个活动 + BEHAVIOR-100 的 91 个活动,共 1,000 个。
BEHAVIOR-1K Dataset
Figure 2. BEHAVIOR-1K 的组成要素

活动定义:BDDL
活动通过 BEHAVIOR Domain Definition Language (BDDL) 定义——基于谓词逻辑,允许非专业人员以直觉语义层面描述活动的初始条件和目标条件。与几何/图像/视频目标规范不同,BDDL 以物体和物体状态为基本元素,允许同一活动有多种合法的初始化和解法。
知识库
物体空间从 5,000 篇 WikiHow 文章中提取,映射到 2,964 个 WordNet 叶级 synset。每个物体标注了完整可仿真的物体状态(如 apple → cooked, sliced;但非 toggledOn)。许多物体-属性对带有连续参数(如 “apple 的烹饪温度”),利用 OmniGibson 的连续扩展状态提升真实性。此外还定义了 transition rules(如番茄 + 盐 → 酱汁,砂纸去锈)。
标注质量:5 名经验丰富的 ML 标注员验证所有类型标注的子集,批准率 > 96.8%。
3D 资产
- 场景: 50 个全交互场景(房屋、花园、办公室、餐厅、商店等),8 种场景类型
- 物体: 9,000+ 物体实例,跨 1,900+ 类别,每个物体标注摩擦力、质量、铰接结构等物理属性和语义类别
OmniGibson: Instantiating BEHAVIOR-1K with Realistic Simulation
OmniGibson 基于 NVIDIA Omniverse + PhysX 5 构建,支持:
- 刚体物理仿真
- 可变形体(cloth、soft body)仿真
- 流体动力学仿真
- 柔性材料仿真
- 光线追踪 / 路径追踪渲染(视觉质量评分 3.20,远超其他 benchmark 的 ~1.7)
扩展物体状态
OmniGibson 在 Omniverse 原生能力之上模拟了额外的非运动学扩展状态:温度(靠近热源时升温)、浸泡程度、脏污程度等。还实现了 Transition Machine——指定物体组在满足条件时的自定义转换(如面团放入达到一定温度的烤箱 → 变成派)。
仿真覆盖率
Figure 4. 各仿真能力解锁的活动数量与物体分布

没有 OmniGibson 的这些特性,超过一半的 BEHAVIOR-1K 活动无法仿真。例如 Habitat 2.0 仅能支持 23% 的活动。Top-10 高频物体类别中就有流体和柔性材料,凸显了这些仿真特性的必要性。
Evaluating BEHAVIOR-1K Solutions in OmniGibson
三个代表性活动:
- CollectTrash: 收集空瓶杯丢入垃圾桶(刚体操作)
- StoreDecoration: 将物品存入抽屉(铰接物体操作)
- CleanTable: 用浸湿的布擦脏桌子(柔性材料 + 流体操作)
三种 baseline:
- RL-VMC: 端到端 visuomotor control(SAC),图像 → 关节命令
- RL-Prim.: PPO + action primitives(pick, place, push, navigate, dip, wipe)
- RL-Prim.Hist.: RL-Prim. + 3 步观察历史
Table 2. 任务成功率
| Method | Primitives | History | StoreDecoration | CollectTrash | CleanTable |
|---|---|---|---|---|---|
| RL-VMC | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 | ||
| RL-Prim. | ✓ | 0.48 ± 0.06 | 0.42 ± 0.02 | 0.77 ± 0.08 | |
| RL-Prim.Hist. | ✓ | ✓ | 0.55 ± 0.05 | 0.63 ± 0.03 | 0.88 ± 0.02 |
Insights: 端到端 RL 在所有活动上完全失败(0%),说明 BEHAVIOR-1K 的长 horizon 特性使得信用分配和深度探索成为根本瓶颈。Action primitives 提供了必要的动作空间抽象。观察历史对长 horizon + 观察混叠的任务(如 CollectTrash,最少需 16 步 primitive)提升尤为显著。
Table 4. 抓取与运动执行简化假设的消融
| Phys. Grasping | Full Motion | StoreDecoration | CollectTrash | CleanTable |
|---|---|---|---|---|
| ✓ | ✓ | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| ✓ | 0.46 ± 0.04 | 0.36 ± 0.08 | 0.73 ± 0.03 | |
| 0.48 ± 0.06 | 0.42 ± 0.02 | 0.77 ± 0.08 |
Insights: 启用完全基于物理的抓取后性能暴跌至 0%——抓取本身就是一个 open problem。而启用完整轨迹运动执行(motion planning)的性能降幅很小,说明训练时用运动规划加速是合理的简化。
Evaluating BEHAVIOR-1K Solutions on a Real Robot
Figure 5. Sim-Real Gap 分析:左/中为 sim 与 real 场景的 side-by-side 对比(高分辨率下相似,但木纹材质与相机特性差异导致 agent 视觉输入存在显著 gap);右为失败来源分解——Sim、Real-Trained Policy、Real-Optimal Policy 三种条件下,actuation(实色)vs perception(条纹)的失败占比。


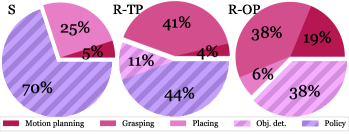
在真实 mockup apartment 中使用双臂移动操作器 Tiago 执行 CollectTrash,评估两种策略:
- Optimal policy(人类输入):27 次试验,~22% 成功率
- Trained policy(OmniGibson 训练的 RL-Prim.):26 次试验,0% 成功率
Sim-to-real gap 来源分析:
- 抓取:~40% 的真实世界失败来自抓取(仿真中使用辅助抓取故不存在此问题)
- 视觉感知:训练策略 44% 错误来自视觉差异(相机动态范围差、材质建模不精确等导致错误的 primitive 选择)
- 导航误差累积:真实中导航不精确导致机器人 base 位置不利,进而引发操作失败——这种 compounding error 在仿真中因完美定位假设而不存在
Discussion and Limitations
局限性:
- 渲染速度 vs 真实性 trade-off:光线追踪渲染约 60 fps(vs iGibson 2.0 的 ~100 fps)
- 不含人类交互:所有活动不涉及与人的交互,真实人类仿真仍是开放问题
- Sim-to-real 差距:感知和执行的噪声模型仍有改进空间
关联工作
基于
- BEHAVIOR-100: BEHAVIOR-1K 的前身,提供了活动来源(ATUS)、BDDL 定义语言、评估指标等设计选择,BEHAVIOR-1K 将活动数量从 100 扩展到 1,000
- iGibson 2.0: OmniGibson 的前身仿真器,但物理仿真能力不足以支撑 BEHAVIOR-1K 的多样活动
对比
- AI2-THOR / ALFRED: 指令跟随 benchmark,场景和物体多样但物理真实性有限
- Habitat 2.0 HAB: 支持真实动作执行但任务种类极少(3 个)
- VirtualHome: 活动多样(549 个)但无低层物理仿真
- SoftGym / RFUniverse: 仿真特性最接近 OmniGibson 但缺乏任务多样性
方法相关
- BDDL (BEHAVIOR Domain Definition Language): 基于谓词逻辑的活动定义语言,支持语义级别的目标规范
- NVIDIA Omniverse + PhysX 5: OmniGibson 的底层物理引擎,提供刚体/可变形体/流体仿真
论文点评
Strengths
- Human-grounded benchmark design: 从实际人类需求出发而非研究者直觉,这是 Embodied AI benchmark 设计哲学上的根本性改进。1,461 人的大规模调查提供了坚实的统计基础
- 前所未有的规模与多样性: 1,000 活动 × 50 场景 × 9,000+ 物体 × 1,900+ 类别,数量级上超越所有现有 benchmark
- 物理仿真的全面性: 刚体 + 可变形体 + 流体 + 柔性材料 + 扩展状态(温度、浸泡等),使得超过 50% 原本无法仿真的日常活动成为可能
- Sim-to-real gap 的诚实分析: 真实机器人实验虽然结果不佳,但系统性地诊断了 gap 来源(抓取 > 视觉 > 导航累积),为后续研究提供了清晰的优先级
Weaknesses
- 实验评估活动数量有限: 1,000 个活动中只实验了 3 个,无法全面评估 benchmark 的真实难度分布
- Baseline 过于基础: 仅用 SAC 和 PPO,未评估更先进的方法(如 hierarchical RL、LLM-based planning、imitation learning)
- Sim-to-real 迁移方案薄弱: 仅使用简单的图像增强进行 domain randomization,0% 的真实世界成功率说明需要更系统的迁移方法
- 渲染速度制约: 60 fps 对大规模 RL 训练而言仍然偏慢,限制了 sample efficiency 本就不高的方法的可用性
可信评估
Artifact 可获取性
- 代码: inference+training(OmniGibson 模拟器 + BDDL 任务定义完整开源)
- 模型权重: 无预训练模型发布(benchmark 而非方法论文)
- 训练细节: 仅高层描述(超参在 Appendix 但未提供训练代码/脚本)
- 数据集: 开源(50 场景 + 9,000+ 物体模型通过项目网站获取)
Claim 可验证性
- ✅ “1,000 activities grounded in human needs”:有 1,461 人调查的完整统计数据支撑
- ✅ “RL-VMC 0% 成功率”:三个活动的可重复实验
- ⚠️ “OmniGibson 视觉质量评分 3.20”:5 分制人类评估但评估细节(评估者数量、评估协议)未充分披露
- ⚠️ “Habitat 2.0 仅支持 23% 活动”:计算方式依赖于对各 simulator 能力的手动判断,存在主观性
Notes
Rating
Metrics (as of 2026-04-24): citation=119, influential=10 (8.4%), velocity=4.7/mo; HF upvotes=1; github 1435⭐ / forks=185 / 90d commits=100+ / pushed 0d ago
分数:2 - Frontier 理由:benchmark 规模(1000 活动 × 50 场景 × 9000+ 物体)和物理仿真多样性(刚体/可变形体/流体/柔性材料)在 embodied AI 领域目前无出其右,2025 年举办 BEHAVIOR Challenge 表明社区正在围绕它组织评测;但相较 3 - Foundation(如 ImageNet / DROID 级别的 de facto 标准),embodied AI 的 benchmark 生态仍碎片化在 Habitat / AI2-THOR / RoboCasa 等多个平台,BEHAVIOR-1K 尚未成为跨方法必跑的唯一基准。相较 1 - Archived,Strengths 里的 human-grounded 设计和 OmniGibson 独有仿真能力明显在前沿,不构成过气风险。