Summary
Watch Before You Answer: Learning from Visually Grounded Post-Training
- 核心: Long-video benchmark 与 post-training 数据中 40–60% 的问题不看视频也能答对 (linguistic shortcutting); 把这些 text-only answerable (TA) 样本从 post-training 数据里直接过滤掉,比堆复杂 RL 算法更有效。
- 方法: 用 GPT-5-mini 在 text-only 模式下回答 Video-R1-260K 的全部题目,剔除答对的 TA 题,保留 181,710 / 263,071 (69.1%) 的 visually grounded (VG) 子集,再用 GRPO + token-level loss + asymmetric clipping post-train Qwen2.5-VL-7B。
- 结果: 在 VideoMME / VideoMMMU / MMVU 三个 benchmark + 16/32/64 帧设置下全面超过 Video-R1, TW-GRPO, LongVILA-R1, Video-RTS; 相对 Video-R1 在 64 帧上 Full Avg +6.2,VG Avg +5.0;相对 base Qwen2.5-VL-7B Full Avg +2.2~+2.4。
- Sources: paper | website
- Rating: 2 - Frontier(方法本身朴素,但对 “video benchmark 的视觉含量” 这一方向性问题给出了极简洁有力的证据,是当下 video VLM post-training 的必读 frontier 参考)
Key Takeaways:
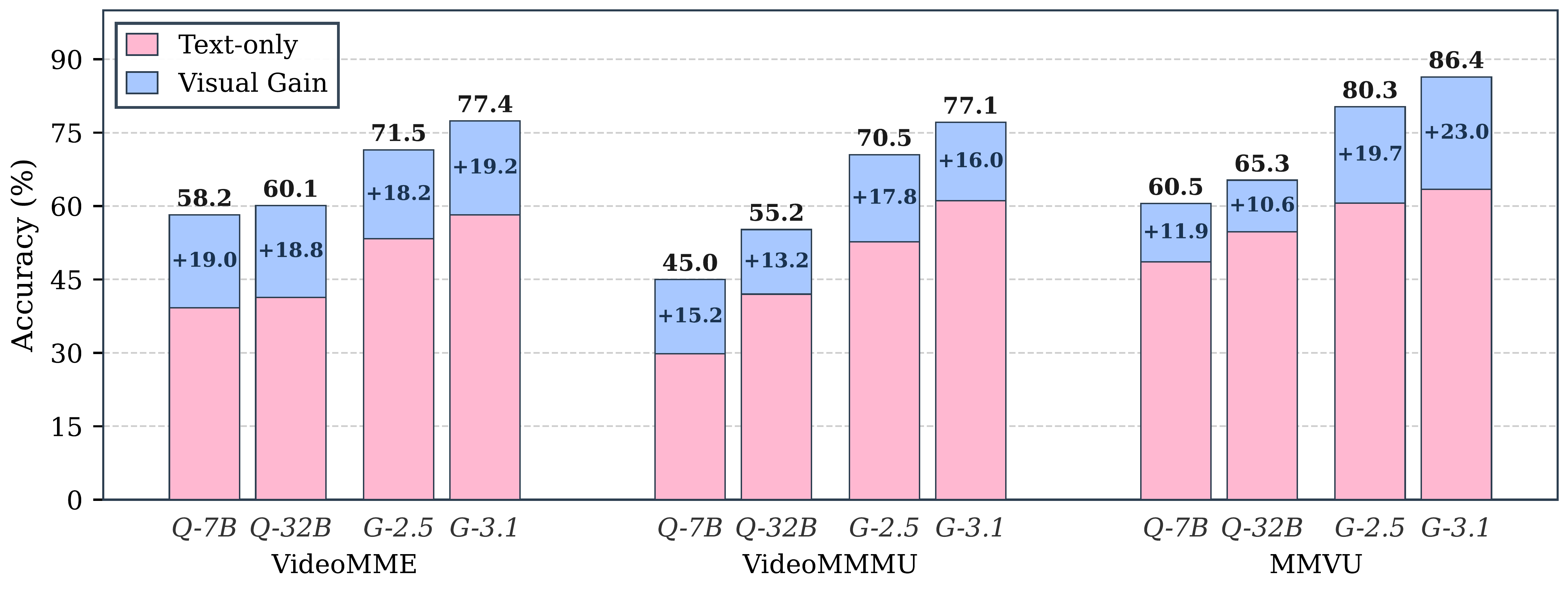
- Video benchmarks 不如想象中 visual: 用 text-only 方式喂 GPT-5 / Gemini-3.1-Pro / Claude-Opus-4.6,VideoMME 48–58%、VideoMMMU 41–61%、MMVU 57–63% 都能答对,远高于 25% / 9.8% / 19.8% 的 random chance。常被 cite 的 “video understanding 进步” 大部分其实来自 LLM backbone 的语言先验。
- Post-training 数据同样污染: Video-R1-260K 中 30.9% 是 TA 题;用这些数据 post-train 反而强化 language prior,让 Video-R1 在多个 benchmark 上比 base Qwen2.5-VL-7B 更差。
- Drop-in filter 比新算法更值钱: 一个粗暴的 GPT-5-mini text-only filter + 朴素 GRPO 就打过 TW-GRPO / Video-RTS / LongVILA-R1 这些专门设计的 RL 变体,且只用 69.1% 的数据。Data quality 是 video VLM post-training 的真正瓶颈。
- TA 失败模式可被分类: textual shortcuts / external knowledge / inferential elimination / imagined content 四类 cover 几乎所有 TA 案例 —— 这同时是构造未来 visually grounded benchmark 的清单。
Teaser. Performance decomposition: 大模型变强,主要是 text-only 部分变强 (粉色), visual gain (蓝色) 反而停滞甚至倒退
1. Motivation: Linguistic Shortcutting in Video Understanding
VQA 早就被指出会被 language prior 主导(Goyal 2017),但 video 领域被默认认为天然需要跨帧聚合视觉信息,shortcutting 应该没那么严重 —— 本文用一个非常简单的实验证伪了这个 default assumption: 把视频拿掉,只给 question + 选项喂给 frontier LLM,看准确率比 random chance 高多少。
Table 1. Text-only answerability across video benchmarks (+x = vs random chance)
| Model | VideoMME | VideoMMMU | MMVU |
|---|---|---|---|
| Random | 25.0 | 9.8 | 19.8 |
| GPT-4o | 47.0 (+22.0) | 38.6 (+28.8) | 46.6 (+26.8) |
| GPT-5-mini | 45.2 (+20.2) | 37.9 (+28.1) | 53.3 (+33.5) |
| GPT-5 | 48.2 (+23.2) | 41.0 (+31.2) | 57.1 (+37.3) |
| Gemini-2.5-Pro | 53.3 (+28.3) | 52.7 (+42.9) | 60.6 (+40.8) |
| Gemini-3.1-Pro | 58.2 (+33.2) | 61.1 (+51.3) | 63.4 (+43.6) |
| Claude-Sonnet-4.5 | 47.7 (+22.7) | 44.3 (+34.5) | 55.4 (+35.6) |
| Claude-Opus-4.6 | 51.3 (+26.3) | 52.7 (+42.9) | 61.0 (+41.2) |
读法:Gemini-3.1-Pro 不看视频就能拿到 VideoMME 58.2、VideoMMMU 61.1。这数字甚至比许多带视频的 7B baseline 还高。意味着 leaderboard 上 +1 / +2 个点的 “video understanding 进步” 很可能只是 LLM backbone 的换代红利。
❓ 一个有趣的细节: TA 比例随模型变强是 单调上升 的(GPT-4o 47% → Gemini-3.1-Pro 58.2% on VideoMME)。这意味着 text-only answerability 不是 benchmark 的固有属性,而是 frontier model 能力增长的函数 —— 同一道题目在 GPT-4 时代是 VG,在 GPT-5/Gemini-3 时代就成了 TA。Benchmark 设计的”反 shortcut”标准本身在被 inflated。
类似的污染也发生在 post-training 数据上:Video-R1-260K(一个 R1 风格 video reasoning 的标准 corpus)有 30.9% 的 TA 题。
1.1 Four canonical TA failure modes
作者人工分类后,把 TA 题归为四类:
- Textual shortcuts — 题面措辞泄题(“How does the cookie change after being decorated?” → “It becomes more colorful”)。
- External knowledge — 世界常识可解(“What does the person rely on for support while descending the cliffside?” → “A rope”)。
- Inferential / elimination — 干扰项不合常理可排除(pouring oil “into the sink / floor / counter” 显然错,“into the wok” 是唯一合理)。
- Imagined (hallucinated) content — 模型脑补出最 plausible 的视频内容刚好对(“What is the cat doing?” → “grooming itself”)。
Figure 2. Representative TA examples in Video-R1-260K training data (左: VG vs TA 占比; 右: 案例)

Figure 3. Representative TA examples in VideoMME 评测集 — 同样四类失败模式 (说明评估集也被污染)

2. Method: VidGround = VG filter + GRPO
VidGround 的全部”创新”就一句话:post-training 之前,把所有 GPT-5-mini 不看视频也能答对的题扔掉。
2.1 Selection pipeline
- 对 Video-R1-260K 里每个 (question, options) 喂 GPT-5-mini(no video)
- 答对 → 标 TA,丢弃;答错 → 标 VG,保留
- 得到 VG 子集 = 181,710 / 263,071 = 69.1%
Robustness checks:
- 这 181,710 VG 题里,85% 也是 Qwen2.5-VL-7B 在 text-only 模式下答不出来的 → 不是 GPT-5-mini 一家之言。
- 用 Gemini-3.1-Pro 做 circular evaluation(轮换 MCQ 选项位置)后 97% 一致 → 选择对位置 bias 鲁棒。
Table 2. Three data variants used for ablation
| Variant | Samples | TA Ratio | Description |
|---|---|---|---|
| Full | 263,071 | 30.9% | 标准 post-training (no curation) |
| TA | 81,361 | 100% | 仅 text-only answerable |
| VG (VidGround) | 181,710 | 0% | 仅需要视觉 |
2.2 RL backbone
朴素 GRPO,但加了来自 DAPO 的两个技巧:
- Token-level policy gradient loss(不是 sequence-level 平均)
- Asymmetric “clip-higher”:上截断 比下截断 大,鼓励上行更新
Equation. GRPO objective with asymmetric clipping
符号: video-question 输入; 第 个采样回答; group size; group-normalized advantage; KL 正则强度; 下/上 clip 边界。
含义:本质就是 GRPO + token-level + asymmetric clip。这部分不是本文的贡献,作者明确说他们的 contribution 是 orthogonal 的 data filter。
2.3 Training config
- Backbone: Qwen2.5-VL-7B-Instruct
- 16 frames per video (训练时)
- 700 GRPO steps
3. Experiments
Benchmarks: VideoMME (general perception+reasoning), VideoMMMU (expert-level reasoning), MMVU (college-level knowledge),分别在 16/32/64 frames 评测。Baseline 都是从 Qwen2.5-VL-7B post-train 的同 family 方法(除 LongVILA-R1)。
3.1 Main results
Table 3. Main comparison at 16/32/64 frames (Full Avg = 整 benchmark, VG Avg = 仅 VG 子集)
| Frames | Method | VideoMME | VideoMMMU | MMVU | Full Avg | VG Avg |
|---|---|---|---|---|---|---|
| 16 | Qwen2.5-VL-7B (base) | 58.2 | 45.0 | 60.5 | 54.6 | 42.9 |
| 16 | TW-GRPO | 58.2 | 48.6 | 61.8 | 56.2 (+1.6) | 44.1 (+1.2) |
| 16 | LongVILA-R1-7B | 55.5 | 38.8 | 59.1 | 51.1 (−3.5) | 39.7 (−3.2) |
| 16 | Video-RTS | 58.7 | 47.1 | 61.8 | 55.9 (+1.3) | 43.5 (+0.6) |
| 16 | Qwen2.5-VL-7B-SFT | 58.2 | 43.1 | 51.3 | 50.9 (−3.7) | 41.1 (−1.8) |
| 16 | Video-R1 | 56.9 | 44.7 | 54.5 | 52.0 (−2.6) | 41.7 (−1.2) |
| 16 | VidGround | 58.7 | 47.4 | 64.2 | 56.8 (+2.2) | 45.2 (+2.3) |
| 32 | VidGround | 61.5 | 48.3 | 65.8 | 58.5 (+2.4) | 47.6 (+3.2) |
| 64 | VidGround | 63.4 | 49.4 | 65.6 | 59.5 (+2.3) | 47.9 (+1.6) |
观察:
- Video-R1, Qwen-SFT, LongVILA-R1 都比 base 倒退 — 在 contaminated data 上做 post-training 反而有害,这非常 ironic。
- VidGround vs Video-R1(同 base、同 corpus、差异只在 VG filter):64 帧 +6.2 Full / +5.0 VG,几乎是 ablation 干净的因果归因。
- 在 64 帧上 VidGround VG Avg (47.9) 略输给 TW-GRPO (48.2) —— 不过 TW-GRPO 在 16/32 帧都被 VidGround 反超,整体 trend 仍是 VidGround 更稳。
3.2 Frame-count scaling
Figure 4. Models trained on VG data 随帧数稳定上升; trained on Full 数据则不稳
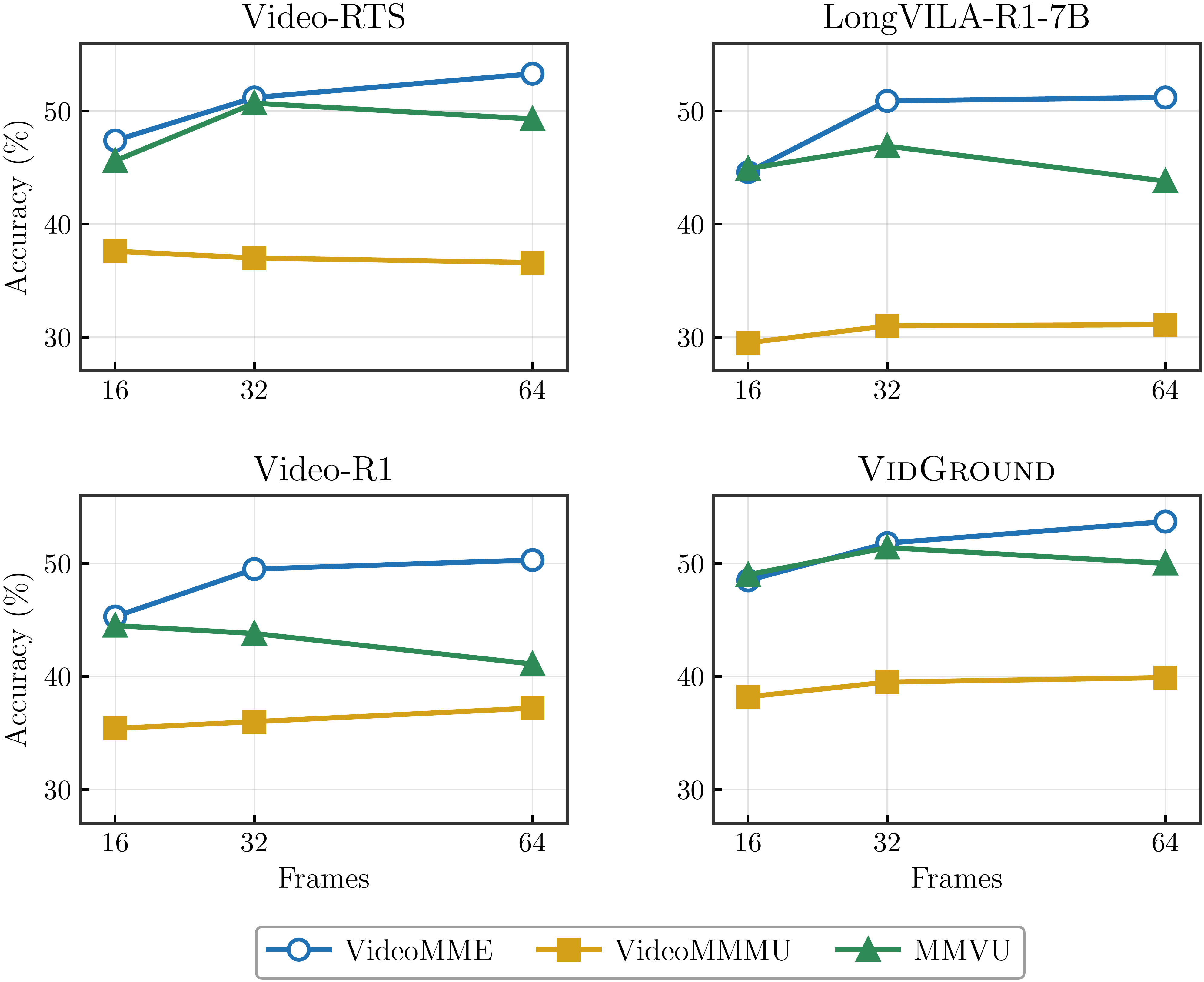
这是一个挺有意思的二次结论:linguistic shortcut 不只是 evaluation 噪声,它还会损害模型在更多帧上 scale 的能力。直觉是:在 TA 数据上学到的策略不依赖时序信息,所以加帧拿不到更多信号。
3.3 Ablation: VG filter alone explains the gain
Table 4. GRPO on VG vs Full (其他完全一样)
| Frames | Method | Data | Full Avg | VG Avg |
|---|---|---|---|---|
| 16 | GRPO | Full | 52.0 (−2.6) | 41.7 (−1.2) |
| 16 | GRPO | VG | 56.8 (+2.2) | 45.2 (+2.3) |
| 16 | +clip-higher | VG | 56.5 (+1.9) | 45.1 (+2.2) |
| 32 | GRPO | Full | 53.9 (−2.2) | 43.1 (−1.3) |
| 32 | GRPO | VG | 58.5 (+2.4) | 47.6 (+3.2) |
| 64 | GRPO | Full | 53.3 (−3.9) | 42.9 (−3.4) |
| 64 | GRPO | VG | 59.5 (+2.3) | 47.9 (+1.6) |
控制变量后,唯一的差别就是数据,从 −2.6 翻到 +2.2 / 从 −3.9 翻到 +2.3 全部归功于 filter。Clip-higher 的边际贡献近乎为 0。
3.4 Filter-variant robustness
Table 5. Single-model 过滤 vs Multi-model consensus 过滤
| Frames | Method | Full Avg | VG Avg |
|---|---|---|---|
| 16 | Video-R1 (Full, 263K) | 52.0 (−2.6) | 41.7 (−1.2) |
| 16 | VidGround (VG, 181K) | 56.8 (+2.2) | 45.2 (+2.3) |
| 16 | VidGround-M1 (161K, ≥2 模型同意 TA) | 57.0 (+2.4) | 45.9 (+3.0) |
| 16 | VidGround-M2 (148K, 更严格) | 55.7 (+1.1) | 43.8 (+0.9) |
| 32 | VidGround-M1 (161K) | 58.9 (+2.8) | 47.5 (+3.1) |
| 32 | VidGround-M2 (148K) | 58.2 (+2.1) | 46.6 (+2.2) |
读法:M1 (中度严格) 略好,M2 (太严格) 反而下降 —— filter 不是越激进越好,适度的 noise 反而有正则化作用。但单模型版本 (VidGround) 已经接近 ceiling。
3.5 Qualitative
Figure 5. VG-trained model 显式 reference frame-level 观察, baseline 靠常识或语言模式

Figure 6. 即使是看起来 “linguistically easy” 的题, VG 模型仍然回到视频找证据

关联工作
基于
- Video-R1 (Feng et al. 2025): 提供 base corpus (Video-R1-260K) 和 baseline GRPO setup;本文证明 Video-R1 的核心问题就是它的训练数据。
- GRPO (DeepSeek-Math): RL backbone。
- DAPO: token-level policy gradient + clip-higher 来源。
- Qwen2.5-VL-7B-Instruct: base VLM。
对比
- TW-GRPO (token-weighted GRPO): 在算法侧 down-weight redundant tokens;本文从数据侧 down-weight TA samples。
- LongVILA-R1: scale 到长视频的 R1 风格 RL;表现最差,作者归因于其 base model 不同。
- Video-RTS: sparse-to-dense test-time scaling;和 VidGround 在 Full Avg 上接近,VG Avg 上被 VidGround 超过。
- Qwen2.5-VL-7B-SFT: SFT baseline,多数设置下比 base 倒退,验证了 RL > SFT 的 prior finding。
方法相关
- Video-MME-v2: 同时期试图通过重新设计 evaluation 来缓解 linguistic shortcut,路径互补 (评测侧 vs 训练侧)。
- Goyal et al. 2017 (VQA v2): VQA 中 linguistic shortcut 的 seminal study;本文是其 video extension。
- Counterfactual VQA / modality dropout 系列: 早期 mitigate language prior 的方法,本文未直接对比。
论文点评
Strengths
- 问题选择极好: “你以为的 video understanding 进步其实大部分是 LLM 进步” 这个 claim 简洁、可证伪、impact 大;text-only probe 的实验设计成本极低却切中要害。
- 方法朴素到 embarrassing 的程度 —— 一个 LLM-as-filter pass + 朴素 GRPO,没有任何新损失函数 / 新架构 / 新奖励,却打过同期所有 fancy RL variant。这正是 simple-and-scalable 的样本。
- Causal analysis 干净: VidGround vs Video-R1 是同 base / 同算法 / 同 corpus 的对比,差异只在 data filter,因果归因非常清楚。
- Frame scaling 的次级结论: 揭示 contaminated data 不只伤准确率,还伤 scaling property —— 这是比 main result 更深的 insight。
- TA 失败模式分类: textual shortcut / external knowledge / inferential elimination / imagined content 这四类 taxonomy 很好用,可以直接成为未来 video benchmark design 的 negative checklist。
Weaknesses
- Filter 的依赖被 hidden: VG 子集是用 GPT-5-mini 选的,意味着这个 pipeline 必须有一个比 base model 更强的 LLM 在场。如果 base model 已经接近 GPT-5 水平(比如要 post-train 一个 GPT-5-class 模型),这套 filter 还能 work 吗?没人测。
- Benchmark 同源: 评测的 VideoMME / VideoMMMU / MMVU 也是用 GPT-5-mini 标 VG / TA 的;选择性偏差未控制 —— 训练用 GPT-5-mini 选的 VG,评测的 “VG Avg” 也是同一个 GPT-5-mini 选的 VG,不算独立验证。
- 没和 Gemini-3.1-Pro filter 比: Table 1 说 Gemini-3.1-Pro 比 GPT-5-mini 多识别 ~10 个点的 TA 题;用更强的 filter 重新筛 + retrain 会更好吗?Filter quality 的 scaling 没做。
- 只 train 700 步: 不清楚是 compute 限制还是 early stop;longer training 会让 Full 反超 VG 吗(因为 Full 有更多样本)?没说。
- 没和”显式去除 language prior”的方法比 (e.g. counterfactual VQA, modality dropout): 这些是 inference-time / training-time 的替代路径,作者只比 RL family。
- 缺一个 obvious baseline: GRPO on Full + 用 advantage 自动 down-weight TA 的 sample reweight 版本。这是更 principled 的做法,没对比。
可信评估
Artifact 可获取性
- 代码: 未说明(项目页未含 GitHub link)
- 模型权重: 未说明
- 训练细节: 部分披露(700 GRPO steps、Qwen2.5-VL-7B base、GRPO + DAPO 的 token-level loss + asymmetric clipping,超参未列;filter prompt 未列)
- 数据集: 派生自公开的 Video-R1-260K;筛后 VG 子集 ID 列表未说明是否会发布
Claim 可验证性
- ✅ “VideoMME / VideoMMMU / MMVU 40–60% 题目可 text-only 答对”:用 8 个 frontier model × 3 benchmark 的 Table 1 直接支持,且 categorize 给了案例。
- ✅ “VidGround 比 Video-R1 在三 benchmark × 三帧数全部更好”:Table 3 完全列出。
- ✅ “去除 TA 题、用更少数据反而更好”:Table 4 Full vs VG 同方法对比,控制变量干净。
- ⚠️ “data quality 是 video VLM post-training 的 major bottleneck”:从 1 个 corpus (Video-R1-260K) + 3 benchmark + 1 base model 的实验外推到全 video VLM post-training。结论方向上 likely true,但样本不够 saturating。
- ⚠️ “outperforms several more complex post-training techniques”:所选 baseline (TW-GRPO / Video-RTS / LongVILA-R1) 都没 access 到同样的 filter,比较的是 “VG filter + GRPO” vs “no filter + 复杂 RL”,并不能 isolate “复杂 RL 不如简单 RL” 这个更强的 claim —— 严格说应该把 baseline 也用 VG 数据 retrain 才公平。
- ⚠️ “VG-trained model scales better with frame count”:Figure 4 visually compelling,但只在 16/32/64 三个点上,scaling claim 略 thin。
Notes
- 这篇可以放进 mental model 里作为 “data > algorithm” in video VLM post-training 的代表性证据;如果将来要 propose 任何 video RL 方法,必须在 VG filter 后的 corpus 上测,否则无法区分”算法 work”和”数据帮你滤掉 TA”。
- TA taxonomy (textual shortcut / external knowledge / inferential elimination / imagined content) 可以直接挪用,做为 benchmark / dataset audit 的 checklist。
- ❓ 一个 follow-up: filter 的 “ground truth” 取决于 GPT-5-mini 当下的能力。明年 GPT-6 出来,今天的 VG 子集会有多少变成 TA?这意味着 VG/TA 是 model-relative 而非 absolute label,benchmark 维护需要定期重 audit。
- ❓ 另一个: 既然 text-only filter 有效,那 “video-only filter”(去掉问题让模型看视频生成 caption,再判断 caption 能否唯一推出答案)是否也是个 complementary signal?真正的 visually grounded 题应该是 既不能 text-only 答,也不能 caption-only 答 的双重 hard 题。
- 项目页域名 etuagi.com (Etude AI) 是一家小厂的域名,不是常见 lab 主页 —— 不影响内容质量,但留意复现门槛。
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.00/mo; HF upvotes=35; github=N/A (无代码仓库)
分数:2 - Frontier 理由:按 field-centric rubric,这是 video VLM post-training / video understanding 方向当下的重要 frontier 参考,而非 foundational。一方面,它对”video benchmark 视觉含量不足”这一问题给出了干净且可复现的证据 (Table 1) 并带出一个极简 drop-in filter 打过同期 fancy RL baseline (Table 3, 4)——这是近期 video RL 论文做比较时绕不开的节点;另一方面,贡献仍是单一经验性 finding + 单一 base model + 单一 corpus 的外推,既没有奠定范式 (Foundation),也不是 one-off 查阅型工作 (Archived),因此定为 Frontier。