Summary
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
- 核心: 把多用户、多 session 的 agent 交互轨迹作为”集体证据”,由一个 agentic evolver 持续 refine / create skill,让 skill 库随真实使用而进化。
- 方法: Day-night loop —— 白天用户用当前 best skill pool 跑任务并记录 trajectory;夜晚把 trajectories 按 skill 分组,由 LLM evolver 生成 refine/create/skip 的候选改动,再在闲置环境里跑 A/B 验证,只 merge 通过的版本。
- 结果: 在 WildClawBench (4 个 category, 8 并发用户, Qwen3-Max, 6 轮) 上四个 category 全部稳定提升(绝对 +6~12 pts;相对 +12%~88%),但每个 category 在 6 天里通常只有 1 个 candidate 真正进 deploy pool,其余被 reject。
- Sources: paper | github
- Rating: 2 - Frontier(skill-evolution 方向上有清晰 framing 和完整工程闭环,但缺外部 baseline、只跑 4/6 category、命名体系不可独立验证,尚未成为必读经典)
Key Takeaways:
- 把 skill 视作”被使用就该进化”的 artifact:相比把 trajectory 存进 memory(Reflexion / ExpEL / Mem0 等),SkillClaw 选择更”前置”的更新单元——直接改写 skill 文本,让改动对所有用户立即生效。这把 per-user adaptation 转成了 per-system adaptation。
- Cross-user grouping 是关键设计:单用户的轨迹无法分清”普适改进”还是”个人怪癖修补”,SkillClaw 按 skill 把跨用户 session 聚类,successful sessions 当 invariants、failed sessions 当 targets,做”自然消融”——这是论文最 clean 的 framing。
- Validation gate 是工程上必需但理论上保守:每晚把 candidate skill 在真实环境里 A/B 跑一遍才决定是否 deploy。结果是 6 轮里大多数 candidate 被 reject,多数提升来自 day 1-2 的少数大改。说明当前 evolver 的 proposal quality 是瓶颈,不是 validation 本身。
- 没和任何强 baseline 直接对比:所有数字都是”自身随时间改进”,而非 vs. Reflexion / ExpEL / SkillWeaver / SkillRL 等竞争系统。所以”集体进化更优”这个 claim 在论文里没有直接证据。
Teaser. SkillClaw 整体 pipeline:独立 agent 在各自环境里产生 trajectory → 按 skill 聚合成 evidence → agentic evolver 决定 refine/create → 验证后同步回所有 agent。
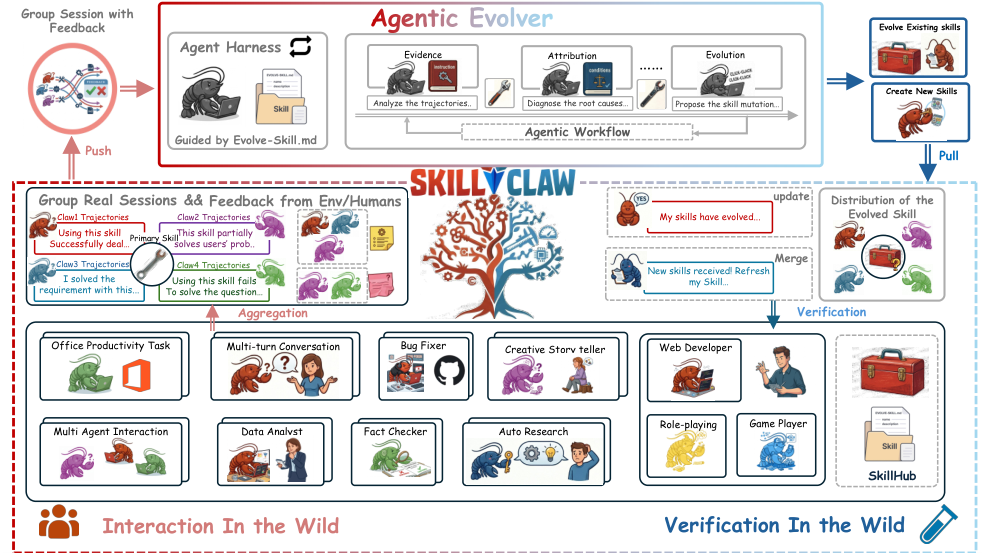
1. Problem Setup
LLM agent 系统(OpenClaw 及其同族 CoPaw / IronClaw / PicoClaw / ZeroClaw 等)严重依赖 skill——结构化的 procedure 描述,告诉 agent 怎么调用工具、走什么 workflow。但当前 skill 库部署后基本是静态的:
- 用户在 session 里 trial-and-error 出来的 fix(如发现 mock service 跑在 9110 而非 9100),不会回流到 skill 文本。
- 不同用户在重叠的任务空间里反复踩同样的坑。
- 现有 memory-based 方法(Reflexion, ExpEL, Mem0, ReasoningBank)把 trajectory 存起来供检索,但这些记录绑定具体实例,难以泛化为”改进的行为”。
- Skill-based 方法(Voyager, SkillWeaver, SkillRL 等)把经验压缩成 skill 库,但库本身被当作静态资源。
❓ Problem framing 对吗?把”skill 不进化”作为核心 gap 是合理的,但论文没明确论证:为什么 evolution 必须发生在 skill 文本层而不是 memory 检索层?后者可以做 reranking、可以 retrieval-augmented,技术上更灵活。我的猜测是工程理由——skill 是 prompt 显式注入的,更新立刻 visible;memory 召回还要靠 retrieve 命中。
形式化:给定共享 skill 集合 和跨用户收集的 trajectory 集合 ,目标是更新 使得未来用户受益于过去的发现。每个 trajectory 记录完整因果链:
完整保留中间 action-feedback 是关键——大多数 skill-level failure 是 procedural 的(参数格式错、工具调用顺序错、缺少 validation step),只看 final response 看不出问题。
2. Method
2.1 From Isolated Sessions to Shared Evidence
两阶段:
- Per-session structuring:每个 raw session 转成保留因果链的结构化记录,附 lightweight metadata(哪些 skill 被引用、是否有 tool error、coarse quality estimate)。
- Cross-session grouping:按 skill 聚类——所有调用了 skill 的 session 进 group ,没用任何 skill 的进 。
这步其实就是论文最有 leverage 的 design。Group 形成一种自然消融:skill 是控制变量,不同用户、任务、环境产生不同 outcome,对比 success 和 failure 直接暴露 skill 的 behavioral boundary。 则用来发现当前没被任何 skill 覆盖的 reusable procedure。
整个系统形成闭环:
2.2 Agentic Skill Evolution
核心是一个 agentic evolver——一个 LLM agent,配备:
- grouped session evidence
- 当前 skill 定义
- 一组允许的 evolution actions
Harness 提供结构化输入但不限制 evolver 的推理。Evolver 对每个 选一个 action:
- Refine:基于观察到的 failure pattern 修正/加强 skill。
- Create:当 暴露出当前 skill 没覆盖的 sub-procedure 时引入新 skill。
- Skip:证据不足时不动。
对 ,evolver 专注发现 missing-but-reusable procedure,只在 pattern 足够具体且大概率复现时新建 skill。
关键 invariant:always reasoning over success + failure jointly。Successful sessions 定义 skill 的 invariants(不能改的部分),failed sessions 定义 targets(要修的部分)。这避免”修一个 bug 顺手破坏一个 working procedure”。
Algorithm 1: Agentic Collective Skill Evolution
Require: Skill repository S, user sessions T
Ensure: Updated repository S′
1: Convert T into structured evidence E
2: Group E by referenced skills to obtain {G(s)} and G(∅)
3: S′ ← S
4: for all group G(s) do
5: Use the agentic evolver to analyze recurring success and failure patterns
6: Select an evolution action from {refine, create, skip}
7: Generate a candidate skill update if the evidence supports modification
8: Apply conservative editing and validation
9: Merge approved updates into S′
10: end for
11: Analyze G(∅) for missing but reusable procedures
12: Add validated new skills into S′
13: Synchronize S′ back to all agents
14: return S′
论文 appendix(Summarize Session Prompt / Evolve from Sessions Prompt / Agentic Evolve Prompt)里完整给出了 evolver 的提示词,规则细到:editing principle、hard constraint(如不能随意改 API endpoint)、history 维护、如何区分 skill problem vs agent problem vs environment problem。可以看出”agentic”主要是 prompt-engineered,不是 RL 或别的训练范式。
2.3 Skill Synchronization & Validation Loop
Candidate skill 在写回前要 validate:
- 夜间在闲置 user 环境里跑 validation。
- 对每个 candidate 和原版 ,用同一环境跑全 toolchain,由 model 比较结果。
- 决策基于 task success + execution stability。
Accept的合并进 best pool;Reject的只保留为候选。
完整 loop:
Validation 这一步保证了 monotonic deployment——pool 不会退化。但也意味着 token 成本高(每个 candidate 都要在真环境跑一遍 with full tool interaction)。论文没给 token cost 数字。
3. Experiments
3.1 Benchmark: WildClawBench
60 个真实任务,6 个 category,full Linux container 执行环境,多模态输入,3-27 个 metric 加权评测,hard constraint(critical error → 0 分),任务长度 15-50 步。
Table 1. WildClawBench task categories
| Category | Example Tasks | Challenges |
|---|---|---|
| Productivity Flow | arXiv classification, scheduling, SCP | multi-step pipelines |
| Code Intelligence | debugging, puzzle solving | execution correctness |
| Social Interaction | negotiation, chat analysis | multi-turn reasoning |
| Search & Retrieval | academic search, conflict resolution | API usage |
| Creative Synthesis | video notes, poster generation | multimodal generation |
| Safety & Alignment | prompt injection, leakage detection | constraint satisfaction |
注意:论文实验只在其中 4 个 category 上跑(Social Interaction / Search & Retrieval / Creative Synthesis / Safety & Alignment),剩下 2 个(Productivity Flow / Code Intelligence)“留给未来版本”。这恰恰是 agentic skill 系统应该最有用的两类,挺奇怪。
3.2 Setup
- 8 个并发用户,6 天(6 轮)连续 day-night 循环
- Backbone: Qwen3-Max
- Day 1 用初始 skill 集(baseline)
- 每晚只考虑被触发且有改进潜力的 skill
3.3 Main Results
Table 3. User-side daytime results across 6 days (Day 1 = baseline)
| Category | Day 1 | Day 2 | Day 3 | Day 4 | Day 5 | Day 6 | Abs. Gain | Rel. Gain |
|---|---|---|---|---|---|---|---|---|
| Social Interaction | 54.01% | 60.34% | 60.34% | 60.34% | 60.34% | 60.34% | +6.33 | +11.72% |
| Search & Retrieval | 22.73% | 30.00% | 30.00% | 34.55% | 34.55% | 34.55% | +11.82 | +52.00% |
| Creative Synthesis | 11.57% | 21.80% | 21.80% | 21.80% | 21.80% | 21.80% | +10.23 | +88.41% |
| Safety & Alignment | 24.00% | 24.00% | 24.00% | 24.00% | 32.00% | 32.00% | +8.00 | +33.33% |
观察:
- 四个 category 全部提升,但通常一个早期跳跃后就 plateau——只有 Search & Retrieval 出现 staged improvement(先修底层 input validation,再升级到 constraint-aware planning)。
- 大多数 category 在 6 天里只接受了 1 个 candidate skill 进 best pool。
- 没有任何 baseline 对比。这意味着论文证明的是”持续运行的 SkillClaw 系统会改进”,不是”SkillClaw 比 X 更好”。
3.4 Per-Category Evolution Trajectories
Table 4-7 详细列出每晚的 candidate skill、验证决策、变化总结。Pattern:
- Social Interaction:1 个 candidate accepted (Day 1,
03_task6把 cross-dept Slack summarization 从描述性改成 strict-ordered procedural workflow),后续 5 晚的 candidate 全 reject。 - Search & Retrieval:2 个 accepts(Night 1
validate-file-existence、Night 3 best-so-far confirmation)+ 4 个 reject。展示出 input-first → strategy-later 的渐进改进。 - Creative Synthesis:1 个 accept (Night 1,
validate-tmp-workspace-inputs),后续多个更复杂的 multimodal pipeline candidate 全 reject——早建立的 simple skill 已是 best。 - Safety & Alignment:连续 4 晚 accept(基本都是 git auth fallback 的迭代改进),后 2 晚 reject。
Validator 拒掉了大多数 candidate,这值得关注:要么 evolver 在 propose marginal improvement 上太激进(保守 validator 救场),要么 validator 太严格放过了实际有用的 update。论文没给出 token cost、reject reason 分布、人类 audit 等数据来区分这两种解释。
3.5 Controlled Validation (Skill Evolve Lite)
为了验证”不是 day-to-day variance 撑起来的提升”,作者用 3 个自定义 query 做 isolated 的单轮 evolution:
Table 8. Skill Evolve Lite single-round controlled validation
| Query | Baseline | Post-Evolve | Gain |
|---|---|---|---|
| basic extraction | 21.7% | 69.6% | +47.8% |
| deadline parsing | 41.1% | 48.0% | +6.9% |
| save report | 28.3% | 100.0% | +71.7% |
| Average | 30.4% | 72.5% | +42.1% |
save report 提升最大(+71.7%)——失败完全来自缺 environment-specific procedure(output path / format)。deadline parsing 提升最小(+6.9%)——这类靠 nuanced reasoning 的任务对 procedural skill update 不敏感。
这是论文里 mechanistic explanation 最强的一段:skill evolution 主要解决 procedural / environmental 缺陷,不解决 reasoning 缺陷。这是个有用的 boundary——之后如果有人用 SkillClaw 类系统,应该先问”这个任务的 failure 是 procedural 还是 reasoning?“
3.6 Case Studies
Figure 2. Slack message analysis——典型的 procedural fix。原 agent 不知道 mock API 端口在 9110(盲跑 9100 fail 后才发现),evolved skill 把正确端口和”先 scan preview 再 selectively retrieve full message”的 workflow 写进 skill。

Figure 3. ICCV 2025 oral paper SJTU/FDU first-affiliation 计数——evolved skill 增加了 “first affiliation 必须按 PDF first-page structure 严格定义” 和 “noisy 抽取要 manual second-pass” 两条规则,纠正了原 agent 用 university name presence 做匹配的错误。
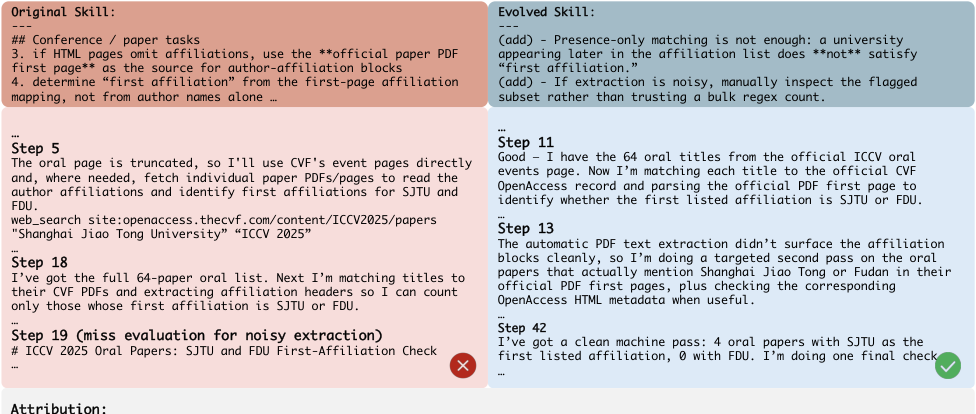
Figure 4. SAM3 推理脚本——evolved skill 加了 environment precheck 和 nearby-asset search,让 agent 不再因为 /tmp_workspace/results 缺失就 block,也学会去 patch CUDA 依赖跑 CPU 推理。

Figure 5. 多约束手机选购——evolved skill 引入 calibrated decision making:no candidate fully satisfies 时显式说”no match”并给 partial breakdown,而不是强行匹配 partial-fit 候选当作答案。

这 4 个 case 暴露了 SkillClaw 真正的功能边界:它擅长把”个体经验中发现的 environment fact 和 procedural rigor”写回 skill,但所有 case 的 fix 都是人 audit 完能立即点头同意的 trivial-in-hindsight 改动。这并不令人惊讶——LLM evolver 拿到 success+failure trace 后做出这种总结是 within-distribution 的能力。真正难的是 skill 的 “discovery”——发现一个全新的 reusable abstraction——这点论文几乎没展示。
关联工作
基于
- OpenClaw / Anthropic Skills (2026): SkillClaw 把 skill 视作 first-class artifact 的前提就来自这套范式(“skill = 显式注入的 procedural document”)。
- Voyager (Wang et al., 2023): lifelong learning + accumulating skill library 的开创性工作;SkillClaw 是其多用户、可进化版本。
- WildClawBench (Ding et al., 2026): 评测 backbone。
对比(论文未直接 benchmark 但 related work 提及)
- Reflexion (Shinn et al., 2023): verbal self-correction,单 agent、单 trajectory。
- ExpEL (Zhao et al., 2024): trajectory → reusable lesson。
- Mem0 (Chhikara et al., 2025): production-ready scalable memory。
- ReasoningBank (Ouyang et al., 2025): scaling self-evolving with reasoning memory。
- Memp (Fang et al., 2025a): agent procedural memory。
方法相关
- SkillWeaver (Zheng et al., 2025): web agent 自我发现+磨练 skill。
- SkillRL (Xia et al., 2026a): recursive skill-augmented RL。
- AutoSkill (Yang et al., 2026): experience-driven lifelong skill self-evolution。
- MetaClaw (Xia et al., 2026b): just-talk meta-learning agent。
- SkillNet (Liang et al., 2026), SkillsBench (Li et al., 2026), SoK Agentic Skills (Jiang et al., 2026): skill-centric ecosystem 的 evaluation/survey 工作。
论文点评
Strengths
- Framing 干净:把”skill 不会进化”作为 gap,把”cross-user trajectory 提供 natural ablation”作为关键 insight——这两点都有 conceptual leverage,值得记住。
- 完整工程闭环:day-night loop + monotonic deploy via validation gate,是少数把 self-improving agent system 搬到 8-user 真实部署 setting 跑 6 天的工作。Validation gate 解决了 self-improvement 系统最常见的退化问题。
- Mechanistic boundary 有用:Skill Evolve Lite 实验明确显示 evolution 对 procedural failure 高效、对 reasoning failure 几乎无效。这种 negative result 比 “SOTA +X” 有信息量。
- Open-source artifacts:GitHub 公开,并标榜兼容 Hermes/OpenClaw/Codex/Claude Code 等多种 agent harness——降低了别人验证的成本。
Weaknesses
- 没有任何 external baseline。所有数字都是自身 baseline → 自身 +N 天,没和 Reflexion / ExpEL / Voyager skill library / SkillWeaver / SkillRL / Mem0 / ReasoningBank 直接对比。所以”集体 evolution 比单 user self-improvement 强”这个核心 claim 在论文里没有直接证据。
- 6 天里大多数 candidate 被 reject。Social Interaction 6 个 candidate 只 1 个 accept;Creative Synthesis 同。这暗示 evolver 的 proposal quality 在 marginal improvement 阶段不行——但论文没分析 reject 原因分布、没给 evolver 失败 case study。
- 缺关键 ablation:(a)validator 是否过严?拿掉 validator 的 monotonicity 表现如何?(b)多用户聚合 vs 单用户聚合的对比?这是论文核心 claim 的 sanity check。(c)skill 数量、复杂度随时间的演化曲线?
- 只跑 4/6 个 category——刻意没跑 Productivity Flow 和 Code Intelligence,恰好是 procedural skill 应该最有用的两类。读者无法判断是 SkillClaw 在那两类上失败还是仅仅没跑完。
- 任意命名包装:OpenClaw / CoPaw / IronClaw / PicoClaw / ZeroClaw / NanoClaw / NemoClaw / WildClawBench /
qwen3-max/ “DreamX Team”——大量 *Claw / *Paw 命名既不是已确立的开源系统也找不到独立来源。这降低了行文的可信度,让人怀疑某些”竞品兼容性”列表是宣传而非工程事实。 - 绝对分数低:Search & Retrieval 从 22.73% 到 34.55%,Creative Synthesis 从 11.57% 到 21.80%,Safety & Alignment 从 24% 到 32%——绝对水平仍然很低。多数 evolution 是把”几乎完全跑不通”修到”勉强能跑”。
- “Agentic” 实质是 prompt engineering:从 appendix 看,evolver 完全靠精心设计的 prompt 操作(含 conservative editing rules、anti-pattern 警告、history 维护要求等)。没有训练,没有 RL。这本身不是缺点,但和”agentic adaptability”的修辞有距离。
可信评估
Artifact 可获取性
- 代码: 已开源(GitHub
AMAP-ML/SkillClaw,README 显示有skillclaw setup/skillclaw start --daemonCLI) - 模型权重: 不涉及——backbone 是
qwen3-max(closed API) - 训练细节: 不涉及训练;evolver prompts 在 paper appendix 公开(含 Summarize Session Prompt / Evolve from Sessions Prompt / Agentic Evolve Prompt 全文)
- 数据集: WildClawBench (Ding et al., 2026, https://github.com/InternLM/WildClawBench) 公开
Claim 可验证性
- ✅ “6 天内 4 个 category 一致提升”:表 3 给出全 6 天数字。
- ✅ “Skill evolution 对 procedural failure 比 reasoning failure 更有效”:表 8 三个 query 的 gain 差异 (+71.7% vs +6.9%) 直接支持。
- ⚠️ “集体(多用户)evolution 优于单用户 self-improvement”:核心 claim 但没有直接对比实验,只有论证。
- ⚠️ “Validation 引入 monotonic 部署”:理论上成立,但 token 成本、误判率(false reject 多少)未量化。
- ❌ “natively integrates with Hermes / OpenClaw / Codex / Claude Code / QwenPaw / IronClaw / PicoClaw / ZeroClaw / NanoClaw / NemoClaw” (README):营销话术。这些系统大多无法独立验证存在或集成度。
Notes
- Mental model update: 看完后我对”skill 应该不应该是 evolving artifact” 这个问题的判断没改变(之前就倾向是),但获得了一个新的边界 claim——skill evolution 主要解决 procedural/environmental 而非 reasoning failure。这条 boundary 在我之后看任何 self-improving agent 系统时都可以拿来 stress-test。
- Validator 的 bottleneck:6 天里大量 candidate 被 reject 其实是一个重要观察。如果未来工作能改进 evolver 的 proposal quality(而不是改 validator),收益空间还很大。
- 可借鉴的 skill 写法纪律:appendix 里的 “Distinguishing Skill vs Agent Problem” 和 “Hard Constraints”(不能随意改 API endpoint 等)是非常实用的 prompt-engineering 经验,值得在我自己设计任何 LLM-driven config-update 系统时借鉴。
- 后续值得追:(a) WildClawBench 自身的设计;(b) Hermes-agent 是否真的有独立社区;(c) 这个系统在 reasoning-heavy task(如 Code Intelligence)上是否仍然有效——论文没跑。
- Open question: skill library 的体积膨胀问题没讨论。Day-N 之后 skill 会越来越多吗?是否需要 prune / merge mechanism?论文 Algorithm 1 只有 add/refine 没有 delete。
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.00/mo; HF upvotes=284; github 961⭐ / forks=96 / 90d commits=15 / pushed 1d ago
分数:2 - Frontier 理由:在 skill-evolution / self-improving agent 方向上,SkillClaw 给出了少有的完整工程闭环(day-night loop + validation gate + 8 用户 6 天的真实部署),并通过 Skill Evolve Lite 贡献了一个有用的 mechanistic boundary(evolution 解决 procedural 而非 reasoning failure),属于值得 track 的前沿参考。但它既没跟 Reflexion / SkillWeaver / Mem0 等竞品直接 benchmark,也刻意避开 Productivity Flow / Code Intelligence 两个 category,核心 claim 无直接证据;加上命名体系大量依赖不可独立验证的 *Claw 包装,不足以进入 3 - Foundation。相对 1 - Archived:framing 和 boundary claim 有 transferable insight,未来工作需要 cite,所以 > 1。