Summary
KITE: Keyframe-Indexed Tokenized Evidence for VLM-Based Robot Failure Analysis
- 核心: 一个 training-free 的视频前端,把长 robot rollout 浓缩成「motion-salient 关键帧 + pseudo-BEV 示意图 + 序列化 evidence tokens」,让通用 VLM 直接做失败检测/识别/定位/解释/纠正
- 方法: 光流峰值选关键帧 → GroundingDINO 检测 + Depth-Anything-V2 深度 → 每帧渲染非度量 BEV 示意图(/ 轴 + 圆点尺寸∝置信度)→ 拼接 [ROBOT][PLAN][KF][CONTACT][GLOBAL_SCENE] tokens 喂给 Qwen2.5-VL
- 结果: RoboFAC simulation 上 training-free 比 vanilla Qwen2.5-VL-7B 涨 +36% FD / +18% FI / +33% FL;加 QLoRA 后超过 RoboFAC-7B fine-tuned baseline
- Sources: paper | website | github
- Rating: 2 - Frontier(representation-as-prompt 思路 simple 且 training-free,在 RoboFAC sim 上涨幅显著;但单 backbone 单 benchmark 验证,real-world 涨幅微弱且 qualitative,尚未定型为该方向的必读奠基)
Key Takeaways:
- Representation-as-prompt: 不训新模型,把 evidence 显式 externalize 成 VLM 易读的 schematic(BEV 示意图 + token 化场景关系),让 off-the-shelf VLM 跨七种失败分析任务通用
- Motion-saliency keyframe 是关键: 替换为 uniform sampling 在 FL 上掉 18 个点(0.74 → 0.56)——失败常发生在 motion 异常的瞬间,均匀采样会漏掉关键证据帧
- Pseudo-BEV 是辅助而非主力: 移除 BEV 在 FE 上掉 0.05 ROUGE-L,但对 MCQ 影响较小;本质上是给 VLM 一个 “易读的示意 cheatsheet”,不是几何重建
- 训练-free 在 simulation 涨幅大、real-world 涨幅小: sim 上 +36 FD,real 上仅 +1 FD——暗示该 framework 真正补的是 sim 中 VLM 看不懂的 abstract 视觉,而 real-world 视觉本身已经在 VLM 训练分布内
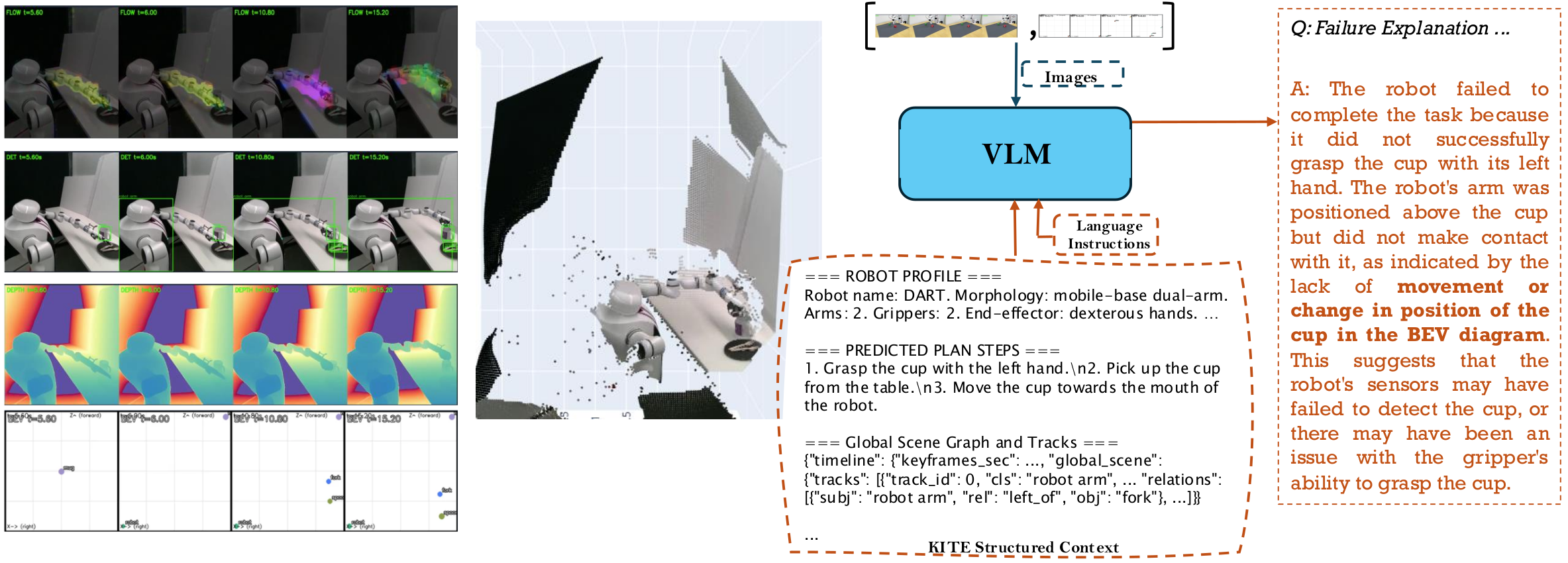
Teaser. KITE pipeline 在真实双臂机器人 (DART) 上的失败解释 demo——左侧展示 optical flow / RGB 关键帧+检测 / depth / pseudo-BEV,右侧 VLM 引用 BEV 推理出 “杯子位置未变” 这个 grounding 结论。
Video. 完整 pipeline demo——从原始视频到 grounded 失败解释。
Motivation
长程操作中机器人会在平凡但要命的地方失败:gripper 偏轴滑落、handle 接触时机错误、双臂 handover 时空错位。要解释这些失败必须组合 where(layout / contact / 相对 pose)、when(execution 偏离的瞬间)、what(task intent)。这些 cue 在原始视频中往往分散在时间轴上、难以从 raw video 直接恢复。
VLM/LLM 已经是机器人通用推理接口,但当输入是 long raw execution video 时它们的优势被削弱:subtle failure cues 被淹没在 dense visual detail 中、temporal context 被稀释、关键证据没有以 VLM 易读的形式呈现。已有工作要么需 task-specific 训练(AHA、RoboFAC fine-tuned),要么基于 summarized memory(REFLECT)——尚无一个 training-free 的前端直接把 raw video 转成对 off-the-shelf VLM 友好的 evidence。KITE 想填的就是这个 representation interface 的空白。
❓ “VLM 看不懂 raw video” 这个 framing 是否成立?这个论点其实模糊地把 “context length 限制” 和 “时序推理能力不足” 混在一起。如果是前者,KITE 是合理的工程解;如果是后者,VLM 即使看了 KITE 总结的 8 帧,仍可能推理失败。论文没区分这两类失败模式。
Method: KITE Front-End
KITE 是一个 training-free、model-agnostic 的前端,把 long execution video 转成一个 compact bundle:motion-salient 关键帧 + 示意 pseudo-BEV + 序列化 evidence tokens。每个组件都是为了 externalize 一个 VLM 难以从 raw video 可靠推断的因子:when 用关键帧、where 用 pseudo-BEV 和 scene relations、what/how 用 robot-profile 和 task-context tokens。
Figure 2. KITE pipeline overview——raw video → 光流峰值选关键帧 → 每帧 OVD 检测机器人和物体 → 渲染 pseudo-BEV 示意图 → 配合 structured context 构成统一 VLM prompt → 回答多种失败分析 QA + 生成 grounded 解释和叙事。

Notation
视频 ,选 个关键帧
每个关键帧 上有:(i) open-vocab 检测集 (box + class + 置信度),(ii) 相对深度图 ;相邻关键帧之间还有 contact-transition token
总结 gripper 与最近物体的粗糙交互变化。
Keyframe Selection
固定关键帧 budget ,优先 motion-salient 帧。计算逐帧 dense optical flow 平均幅度,时间维度 NMS 找局部峰值;不够 个就用 uniform 采样补齐保证覆盖。
为何用 dense 而非 sparse flow:目标不是 correspondence tracking,而是稳定的 scene-wide saliency 信号——manipulation 失败常涉及 arm/gripper/object 的分布式 motion,sparse keypoints 在 texture-poor / 部分遮挡的机器人场景下不可靠。selector 是模块化的,可换 entropy-based 或 learned policy。
Per-Keyframe Perception
- OVD: GroundingDINO (Swin-T) 检测物体和机械臂/夹爪,跨关键帧用 instance ID 关联;timestamp overlay 到 RGB 上,每帧最多 5 个检测。
- Single-View Depth: Depth-Anything-V2-Large,仅作 相对 深度排序 cue,不是 metric geometry;超过 0.8 quantile 的极端值会被压制。
- Contact-Transition Proxy: 当 gripper 和候选物体在相邻关键帧都被高置信度检测到时,记 为 gripper 到最近物体的中心距离, 为 bbox IoU,定义
阈值 。这是个有意粗糙的信号——捕捉 interaction trend 趋势,不需要力觉 / 精确 contact estimation。
3D Scene Graph
每帧建一个 local scene graph :节点是 中的检测,3D 中心由相对深度 + 相机几何近似;pairwise 关系从
中按 centroid offset 的符号和量级编码(带小容差)。跨帧通过 instance track 聚合到全局 graph。
❓ 用粗糙 3D(来自单目深度)替代纯 2D:作者论点是 “front/back ordering 在图像坐标下歧义”,但 Depth-Anything-V2 的 single-view depth 在 robot 工作空间里也很容易系统性偏差(反光面、薄物体、自遮挡)。论文没报这个 noisy depth 在 BEV 上是否引入伪影。
Pseudo-BEV Schematic(layout prior)
不做照片级重建,渲染 schematic、non-metric top-down BEV——每个关键帧一张:
- 固定坐标轴( 向右、 向前)+ 箭头
- 每个 tracked object 一个圆,半径 ∝ 置信度 (clip 到 [3, 10] px)
- 物体类别标签 + 与 RGB overlay 一致的 instance ID
- 时间戳 和关键帧 index
画在 白色 canvas 上。BEV 不是 metric map,是给 VLM 读的示意 cheatsheet,让 spatial relations 更易”看”出。
KITE Structured Context
序列化的 context prefix :
PLAN 字段在没有 plan steps 时省略。每个 QA:图像 bundle = 张图( 个 RGB overlay + 个 BEV),text prompt = + 简短说明 “BEV 是 schematic, not to scale, 仅做 relative layout reasoning” + target question。
Failure Localization Prompting
要 VLM 输出 strict JSON:
{"candidates":[{"frame_num": INT, "confidence": FLOAT}, ...]}
最多 3 个候选 + 置信度,简单 parser 取 top-1 作为 evidence frame。Narrative summary 阶段则给 VLM storyboard montage(所有关键帧 + BEV),让它生成引用 keyframe ID + 时间戳的 causal 叙事,并提一个 high-level + 一个 low-level correction。
由于所有 perception 仅在 个关键帧上跑,总 cost 关于原始视频长度 ,固定 后线性。
Experiments
Setup
- Benchmark: RoboFAC —— QA-style 失败分析 benchmark,60K 训练 QA + 10K sim test + 8K real test,8 类问题(TI / TP / FD / FI / FL / FE / HL / LL);KITE 报除 TP 之外的 7 类
- In-lab qualitative: RealMan dual-arm compound robot (DART) + ALOHA-2 stationary——zero-shot 测试 transfer 到双臂场景
- Backbone: Qwen2.5-VL(3B / 7B);reference baseline 含 Gemini-2.0、GPT-4o、RoboFAC-7B (RoboFAC fine-tuned)
- Hardware: 全 single A6000,QLoRA rank=8、4-bit、1 epoch、lr=1e-5
MCQ 主结果
Table I. RoboFAC MCQ success rate—— 标记 RoboFAC-tuned 模型
| Model | Sim FD | Sim FI | Sim FL | Real FD | Real FI | Real FL |
|---|---|---|---|---|---|---|
| Gemini-2.0 | 0.48 | 0.27 | 0.75 | 0.60 | 0.11 | 0.18 |
| GPT-4o | 0.64 | 0.21 | 0.71 | 0.96 | 0.43 | 0.52 |
| Qwen2.5-VL-3B | 0.38 | 0.04 | 0.51 | 0.04 | 0.03 | 0.07 |
| Qwen2.5-VL-7B | 0.52 | 0.26 | 0.22 | 0.83 | 0.38 | 0.72 |
| KITE + Qwen2.5-VL-7B | 0.88 | 0.44 | 0.55 | 0.84 | 0.43 | 0.74 |
| RoboFAC-7B | 0.91 | 0.63 | 0.94 | 0.80 | 0.56 | 0.71 |
| KITE + Qwen2.5-7B + QLoRA | 0.93 | 0.69 | 0.92 | 0.89 | 0.58 | 0.77 |
观察:
- Sim 上 training-free KITE 涨幅惊人: vs vanilla Qwen2.5-VL-7B 涨 +36 FD / +18 FI / +33 FL
- Real 上涨幅微弱: +1 FD / +5 FI / +2 FL —— 提示 vanilla VLM 已经在 real domain 表现尚可,KITE 主要补 sim 的 abstract 视觉
- GPT-4o 在 real FD 上 0.96 全场最高——说明强 backbone 本身即可,但在 sim 上仍只有 0.64,KITE+7B 反而碾压 GPT-4o(0.88 vs 0.64);这又是 sim/real domain shift 的体现
- QLoRA 加成: 进一步把 KITE 推过 RoboFAC-7B 在 5/6 维度上
Free-language 结果(ROUGE-L / SBERT)
Table II. RoboFAC free-language metrics(缩写:TI/FE/HL/LL = Task ID / Failure Explanation / High-Level / Low-Level Correction)
| Model | Sim TI | Sim FE | Sim HL | Sim LL | Sim TI SB | Sim FE SB | Sim HL SB | Sim LL SB |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-VL-7B | 0.206 | 0.194 | 0.230 | 0.157 | 0.546 | 0.448 | 0.683 | 0.657 |
| KITE + Qwen2.5-VL-7B | 0.295 | 0.248 | 0.241 | 0.190 | 0.680 | 0.829 | 0.798 | 0.779 |
| RoboFAC-7B | 0.323 | 0.299 | 0.301 | 0.245 | 0.701 | 0.842 | 0.808 | 0.794 |
| KITE+QLoRA | 0.326 | 0.314 | 0.302 | 0.296 | 0.698 | 0.845 | 0.806 | 0.803 |
KITE training-free 在 SBERT 上最大提升是 FE 项(+0.38 sim),ROUGE-L 上各项都涨。SBERT 提升远大于 ROUGE-L 提升暗示生成内容在语义上更接近 GT,但 surface form 还有 gap——QLoRA 主要补这个 surface gap。
Ablations
Table III. Real-world 上 ablate pseudo-BEV 和 keyframe selector( 表示移除)
| Config | FD | FI | FL | TI | FE | HL | LL |
|---|---|---|---|---|---|---|---|
| Full (KITE) | 0.84 | 0.43 | 0.74 | 0.300 | 0.252 | 0.223 | 0.232 |
| pseudo-BEV | 0.81 | 0.37 | 0.70 | 0.302 | 0.202 | 0.221 | 0.228 |
| uniform keyframe | 0.69 | 0.33 | 0.56 | 0.298 | 0.189 | 0.217 | 0.190 |
- Pseudo-BEV 主要影响 FE(-0.05 ROUGE-L),对 MCQ 影响 3-6 pt
- Motion keyframe selector 比 uniform 重要得多——FL 掉 18 点,FD 掉 15 点;symptomatic 失败往往在 motion 异常瞬间,uniform 采样会错过证据帧
Qualitative
Figure 3. Sim 定性(PegInsertionSide)——每个 panel 展示 RGB+检测 / optical flow / pseudo-BEV / depth / KITE context excerpt / 失败定位输出 / narrative summary

Figure 4. Real-world ALOHA-2 双臂 handover——物体在 handover 中被 drop,KITE 的 narrative 显式 tie 失败到 robot embodiment(双臂协调)和观察序列。Robot-profile 信息在 structured context 中的价值在这里体现

关联工作
基于
- Qwen2.5-VL: 主 backbone,方法本身完全依赖 VLM 的 in-context 多图推理能力
- GroundingDINO: open-vocabulary detection 模块
- Depth-Anything-V2: 单目相对深度,BEV 渲染 + 3D scene graph 构建的几何 cue
- QLoRA: 轻量 fine-tune 方案
对比
- REFLECT (Liu et al. 2023, CoRL): 同样做失败 retrospection,但基于 multisensory log 的 LLM 总结;KITE 把 representation 锁定在 video front-end 这一层
- AHA (Duan et al. 2025, ICLR): 训练 failure-specific VLM;KITE 主张 training-free + 通用 backbone
- RoboFAC-7B: KITE 直接对标的 fine-tuned baseline,用 KITE+QLoRA 在多数指标上反超
方法相关
- Talk2BEV(Choudhary et al. ICRA 2024): BEV-as-prompt 在 driving 中的先例;KITE 把 BEV 概念迁到 manipulation 失败诊断
- 3D scene graphs for task grounding (SayPlan): 同样用结构化场景图给 LLM 注入 inductive bias
- Set-of-Marks / 视觉 prompt overlay: 概念上同源——把 VLM 难以推理的信息 externalize 到图像 overlay 上
论文点评
Strengths
- Representation engineering 替代 fine-tuning ——用 schematic + serialized tokens 把 VLM 不擅长的 spatiotemporal 信息 externalize 出来,方向上和 set-of-marks / scene-graph-as-prompt 一脉相承,simple 且无需训练
- Ablation 设计合理且 negative-result 诚实 ——Pseudo-BEV 在 MCQ 上仅小幅贡献而非 “banner contribution” 被如实报告;motion keyframe vs uniform 的差距是论文最 informative 的对比
- 失败定位的 strict-JSON 协议值得复用——很多 VLM-as-judge / VLM-as-detector 的工作输出 free text 难以下游消费,KITE 用 schema + parser 把 frame-level 输出 commit 成 structured 是工程上的好实践
- Cost 关于视频长度 —— 固定 后无论视频多长 perception 成本不变,对 long-horizon rollouts 有结构性优势
Weaknesses
- Sim vs Real 涨幅差距巨大但未深究 ——Sim 上 +36 FD,Real 上 +1 FD。论文没分析为什么——是 vanilla VLM 在 real 上已经”够好”,还是 KITE 的 BEV/keyframe 抽象在 sim 的非真实纹理上反而更帮助?这是 reviewer 必问的点
- Qualitative real-world 评估非常弱 ——DART 和 ALOHA-2 的结果是定性的、单 case 展示,没有量化 user study 或第二位 annotator。论文自己也承认这是 limitation
- Pseudo-BEV 作为”为 VLM 渲染的示意图”假设没有正面验证 ——作者声称 BEV 比照片级重建更易被 VLM 解析,但没有对比实验(如 BEV vs 真实 top-down render)。“VLM 看示意图更易”是个可证伪假说,应该实验
- 依赖 GroundingDINO + Depth-Anything-V2 的 failure cascade 没分析 ——OVD 漏检或 depth 错误会直接污染 BEV 和 contact-transition token,但论文没报错误传播分析
- 3D scene graph 的关系集合极简(仅 3 种) ——
on_top_of、inside、touching这些对 manipulation 至关重要的 predicate 全部缺失。limitation 章节自己承认了,但这其实直接限制了能诊断的失败类别
可信评估
Artifact 可获取性
- 代码: inference + evaluation 已开源,QLoRA 训练脚本未发布(GitHub README 的 ToDo list 明确:“QLoRA fine-tuning scripts & training recipes” 未完成)
- 模型权重:
m80hz/KITE-7B-Instruct已在 HuggingFace 发布 - 训练细节: QLoRA 超参完整(rank=8, 4-bit, 1 epoch, lr=1e-5),但训练数据配比、采样策略未细化披露
- 数据集: 完全开源——RoboFAC 原始数据公开(含已知 path mismatch issue MINT-SJTU/RoboFAC#2)
Claim 可验证性
- ✅ Training-free KITE + Qwen2.5-VL-7B 在 sim FD/FI/FL 上比 vanilla 涨 +36/+18/+33:grounding 在 Table I,benchmark 公开,可复现
- ✅ Pseudo-BEV 移除后 FE 掉 0.05 ROUGE-L:Table III ablation 直接支持
- ✅ Motion keyframe > uniform keyframe:Table III FL 0.74 → 0.56 显著
- ⚠️ KITE 在 real dual-arm 上”transfers well”:仅 2 个 qualitative case(DART, ALOHA-2 各一),样本量不足以支撑 generalization claim
- ⚠️ “Pseudo-BEV is more parseable for VLMs than photorealistic reconstructions”:方法 motivation 中给出的 design rationale,但论文未做实证比较——是 design hypothesis 而非 verified claim
- ⚠️ “代表性 representation interface”: 作者把 KITE 定位为”representation problem”的解,但只在 RoboFAC 一个 benchmark 上量化评估,不能 claim general representation interface
Notes
- Insight: 这是典型的”prompt engineering 升级到 representation engineering”的工作——核心 claim 不是新模型/新数据/新算法,而是”VLM 能力天花板被 input representation 卡住,换个表示就能涨大”。这种工作的价值取决于该 representation 是否 generalize 到其他 backbone 和其他 task。论文只验证了一个 benchmark 一个 backbone,generalization 是 open question
- 可借鉴: BEV-as-schematic 的设计思路(圆点尺寸编码置信度、固定坐标轴 + arrow、instance ID 跨 RGB/BEV 一致)对任何想给 VLM 喂空间信息的工作都是 good template
- 可质疑: Sim/real 涨幅差距是否暗示 KITE 实际”修的”是 sim 视觉的 distribution gap 而非 VLM 失败推理的 representation gap?如果换一个在 sim 上预训练更好的 VLM,涨幅可能消失
- 后续可做: 拿同一套 KITE front-end 跑 GPT-4o / Gemini-2.0 / Claude 等 closed-source backbone,看涨幅是否一致——能验证这是 representation 的功劳还是 Qwen 特定的能力补丁
- 与我研究的 connect: KITE 的”keyframe + structured context”思路对 long-horizon video understanding 普遍适用——video LLM 处理 long video 的核心痛点都是 temporal context 稀释,KITE 的 motion saliency + token serialize 是一种简单可借鉴的 distillation 协议
Rating
Metrics (as of 2026-04-24): citation=0, influential=0 (0%), velocity=0.00/mo; HF upvotes=0; github 6⭐ / forks=0 / 90d commits=6 / pushed 11d ago
分数:2 - Frontier 理由:training-free 的 representation-as-prompt 前端在 RoboFAC sim 上 FD/FI/FL 涨 +36/+18/+33 并靠 QLoRA 反超 RoboFAC-7B,是失败分析方向一个值得跟进的 frontier baseline;但只在单一 benchmark + 单一 backbone 上做量化验证,real-world 涨幅仅 +1 FD 且仅 2 个 qualitative case,尚未证明 representation 的跨 backbone 普适性——还没到方向必读奠基的 Foundation 档,但也不是 incremental/被取代的 Archived。