Summary
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
- 核心: 通过 “混合压缩/稀疏注意力 + mHC + Muon + FP4 QAT” 把 1M-context 的 inference FLOPs 压到 DS-V3.2 的 27%、KV cache 压到 10%,同时以 two-stage 后训练(多领域 expert + full-vocab On-Policy Distillation)把 open-source SOTA 推到逼近前沿闭源模型水平
- 方法: CSA(m=4 token 压缩 + DSA top-k 稀疏)与 HCA(m’=128 token 重压缩)交错;mHC 用 Birkhoff 流形约束 residual;32T token 预训练;post-train 用 SFT+GRPO 炼 10+ domain expert 再 OPD 到统一 model
- 结果: DeepSeek-V4-Pro-Max (1.6T/49B act) 在 LiveCodeBench (93.5)、Codeforces (3206) 等超过所有开源和多数闭源,SimpleQA-Verified 以 20pt 领先开源;落后 GPT-5.4 / Gemini-3.1-Pro “约 3–6 个月”
- Sources: paper | website
- Rating: 2 - Frontier(开源最强、1M-context 效率上是阶段性 SOTA,但在 attention 架构上是 CSA/HCA/DSA 等已有思路的工程集成,非奠基性创新;方法复杂度也偏高,作者自己承认”需要后续蒸简”)
Key Takeaways:
- Hybrid Attention = CSA + HCA 交错: CSA 先把每 m=4 个 KV 压成一个,再用 DSA Lightning Indexer 选 top-k;HCA 用 m’=128 的重压缩但保持 dense。两种 layer 交替堆叠,在 1M context 下 Pro 只需 27% FLOPs / 10% KV cache。
- mHC (Manifold-Constrained Hyper-Connections): 把 residual 展宽 n_hc=4 倍,并用 Sinkhorn-Knopp 把 residual 变换矩阵 B 约束到 Birkhoff polytope(doubly stochastic),保证 spectral norm ≤ 1,解决 naive Hyper-Connections 在深层堆叠时的数值不稳定。
- Muon + AdamW 混合 + FP4 QAT: Muon 用于大部分参数(含 MoE expert),AdamW 守住 embedding / prediction head / norms;hybrid Newton-Schulz 10 步。MoE 专家权重和 CSA indexer 的 QK path 用 MXFP4(FP4 → FP8 无损反量化),rollout 阶段用真 FP4。
- Two-Stage Post-Training: 先对 math / code / agent / IF 等 domain 分别跑 SFT+GRPO 得到 specialist,再用 full-vocabulary On-Policy Distillation(reverse KL)把 10+ teacher 蒸馏到单一 student——放弃了 DS-V3.2 的 mixed RL。
- 训练稳定性两个 empirical trick: Anticipatory Routing(用 θ_{t-Δ} 算 routing index)+ SwiGLU Clamping(linear ∈ [-10,10],gate ≤ 10),作者承认”机理尚不清楚但确实有效”。
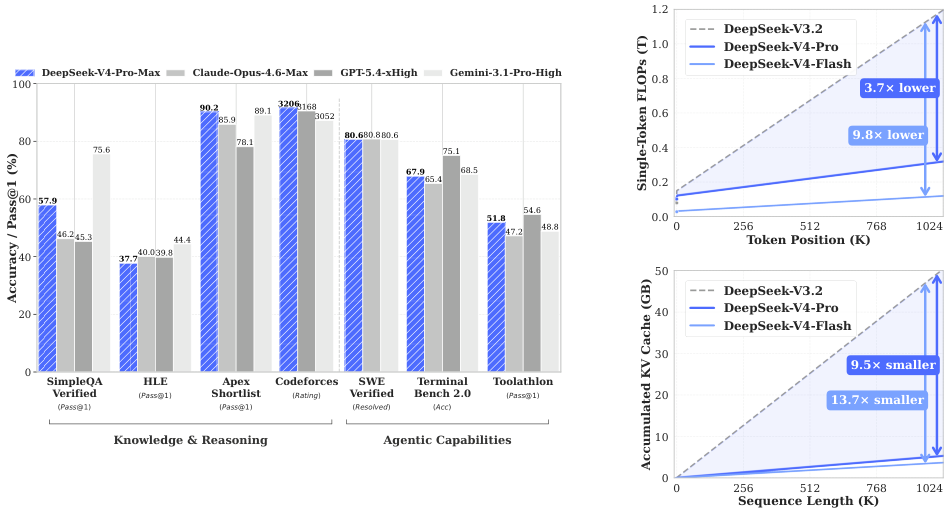
Teaser. 总览图:左为 benchmark,右为 1M context 下的 FLOPs/KV cache 对比。 这张图是全文 thesis——Pro-Max 性能接近前沿、但 FLOPs/KV 显著下降。注意右图 y 轴是 accumulated KV cache,Flash 在 1M 时比 V3.2 小 13.7×,Pro 小 9.5×。
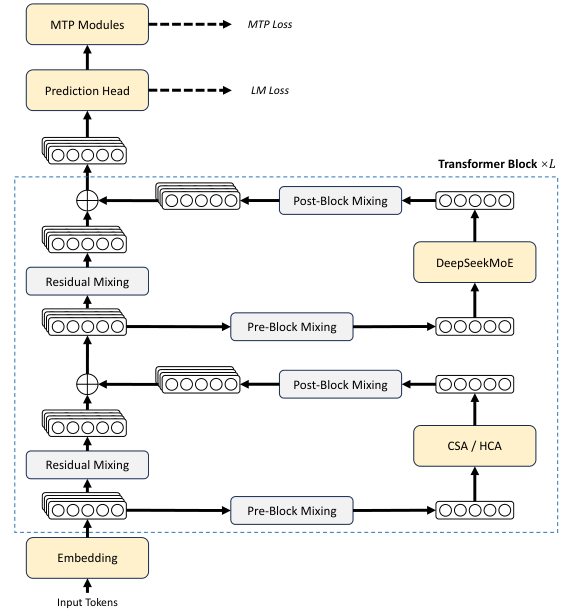
1. 架构
总体继承 DeepSeek-V3 的 DeepSeekMoE + MTP,主要改了三件事:residual 换 mHC、attention 换 hybrid CSA/HCA、optimizer 换 Muon。
Figure 2. DeepSeek-V4 整体架构——attention 层是 CSA 或 HCA,FFN 是 DeepSeekMoE,residual 被 mHC 替换。
1.1 Manifold-Constrained Hyper-Connections (mHC)
Standard HC 把 residual stream 从 展宽到 ,通过三个线性映射 把 residual 更新解耦——提供了一个与 hidden size 正交的新 scaling axis。但堆叠多层时训练数值爆炸。
mHC 的 fix:约束 到 Birkhoff polytope (双随机矩阵流形):
这保证 ,residual transformation 是 non-expansive。 对乘法封闭,所以多层堆叠仍稳定。 用 sigmoid 限制为非负有界,避免 signal cancellation。
投影到 用 Sinkhorn-Knopp 20 轮迭代:,然后交替行/列归一化到收敛。
❓ Sinkhorn-Knopp 每步前向都要跑 20 轮迭代,虽然可以 fuse 成 kernel,但对于 61 层的 Pro 意味着每 token 1220 次迭代。论文声称 “overhead 6.7% of 1F1B pipeline stage”,但没给 mHC-off 的 ablation,很难判断这 6.7% 换来的收益是否值得。
1.2 Hybrid Attention: CSA + HCA
这是效率的主源头。核心 idea:长 context 下 attention 成本主要是 KV cache 的读取而非 compute,所以压缩 KV 序列长度。两种压缩层交错堆叠:
CSA (Compressed Sparse Attention)
Figure 3. CSA 先把每 m 个 token 的 KV 压成一个 entry,然后用 DSA Lightning Indexer 选 top-k 稀疏 attention,另加 sliding window 分支保局部细粒度。
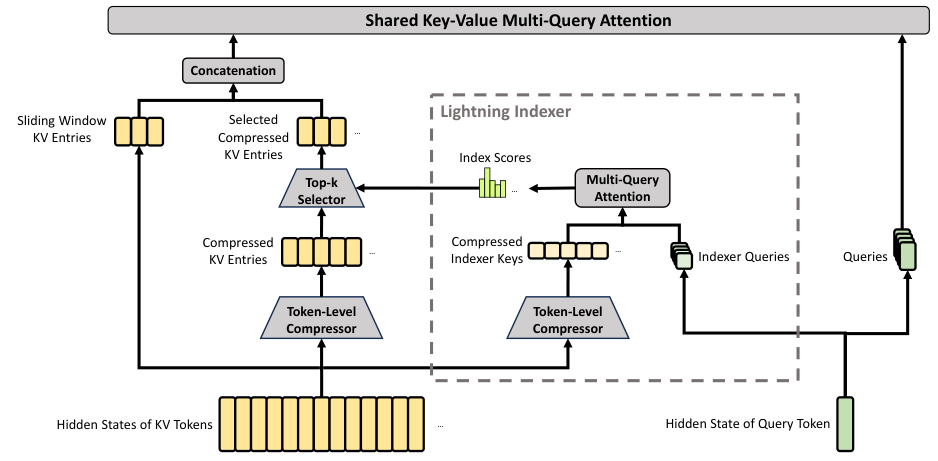
机制分三步:
- Token 压缩:生成两路 KV entries 及权重 ,然后按 m 个 token 为一组用 softmax 加权合并(带 overlap,相邻压缩块共享 ),把序列长度压成 。
- DSA Lightning Indexer:从压缩的 indexer key 和 low-rank indexer query 计算 index score ,top-k selector 选 个压缩块给 core attention。Indexer 的 QK 用 FP4 计算。
- Shared-KV MQA + Grouped Output Projection:core attention 是 MQA(key 和 value 用同一份压缩 entry),输出分 组做 projection 降低 的开销。
Pro 配置:;Flash:。
HCA (Heavily Compressed Attention)
Figure 4. HCA 压缩比更激进(m’ >> m),但保留 dense attention 而非 top-k;同样有 sliding window 分支。
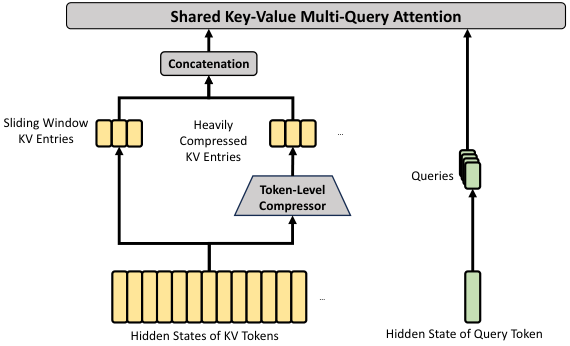
HCA 用 m’=128 的无 overlap 大块压缩,直接在压缩序列上做 dense MQA。因为压缩率更高(~1/128),即便 dense 也比 full attention 便宜。与 CSA 交错堆叠,层级上做分工。
其他细节
- Partial RoPE: 只对 query 和 KV entry 的最后 64 维加 RoPE;由于 KV entry 同时当 key 和 value,为了让输出也带相对位置,对 core attention output 的最后 64 维再施加 position 的 RoPE。
- Sliding Window 分支: 两种 attention 都额外跑 token 的未压缩 SWA,补回 causality 被压缩块吃掉的本地细粒度。
- Attention Sink: 每个 head 学一个 sink logit ,加到 softmax 分母——允许 attention 总和 < 1,有利于长 context 不 overflow。
- Mixed-precision KV storage: RoPE 维度 BF16,其余 FP8,KV cache 近半压缩。
Efficiency 收益:相对 BF16 GQA8 (head dim 128) baseline,DS-V4 在 1M context 下 KV cache 仅为 ~2%。
1.3 Muon Optimizer
Muon 负责 embedding / prediction head / mHC 静态偏置 / RMSNorm 以外的所有参数。核心是用 Newton-Schulz 迭代把 momentum-smoothed gradient 正交化。V4 的三个工程差异:
- Hybrid Newton-Schulz: 前 8 步系数 快速收敛;后 2 步 把奇异值稳在 1。
- Update rescale: 乘 复用 AdamW 超参(γ=0.18)。
- QK-Clip 不用:因为 RMSNorm 已经加在 Q/K 上,attention logit 不会爆炸。
2. Infrastructure
这一节写得非常详细,信息量很大,下面只挑关键的。
2.1 Fine-Grained EP Overlap (MegaMoE)
Figure 5. 把 experts 切成多个 wave,让 dispatch/combine 通信和 linear 计算以 wave 为粒度流水——比之前的 Comet 更细粒度。
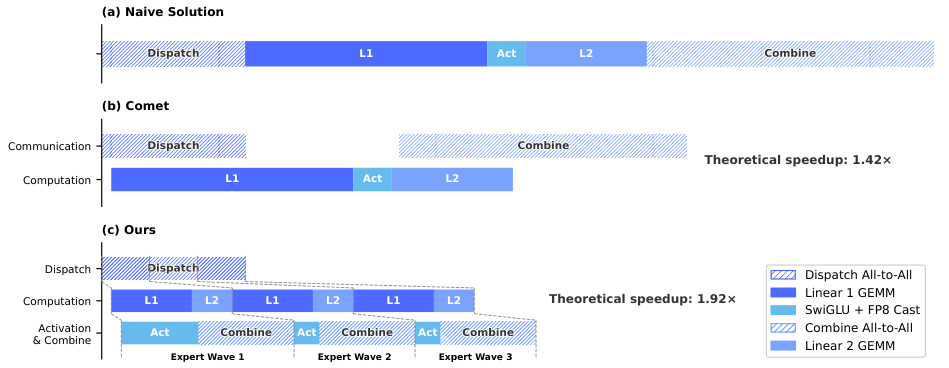
单 MoE layer 分 Dispatch (comm) / Linear-1 (comp) / Linear-2 (comp) / Combine (comm) 四阶段。切成 wave 后,当前 wave 的 compute、next wave 的 token transfer、已完成 expert 的结果回传可以同时跑。实测 1.50–1.73× speedup,RL rollout 等小 batch 场景 up to 1.96×。开源为 DeepGEMM 的 MegaMoE kernel。
一个有意思的 observation:一个 token-expert pair 需要 FLOPs 但只要 bytes 通信,每 GBps 带宽只需匹配 6.1 TFLOP/s compute——超过此比例再堆带宽 diminishing returns。作者因此建议硬件厂商不要无脑堆带宽。
2.2 TileLang + SMT + Batch Invariance
- TileLang (Wang et al., 2026) 作为 kernel DSL 替代手写 CUDA;Host Codegen 把 per-invocation overhead 从几十-上百 μs 降到 < 1 μs。
- Z3 SMT Solver 整合进 integer 代数系统,做 vectorization、memory hazard detection 等 pass 的 formal analysis。
- Batch invariance + determinism:abandon cuBLAS 用 DeepGEMM;attention decode 用 dual-kernel 方案(一 SM 整序列 vs 多 SM 小 tail);MoE backward 用 buffer 隔离保序;mHC 里 output dim 只有 24 的 matmul 用 split-k + deterministic reduction。
2.3 FP4 QAT (MXFP4)
两处用 FP4:
- MoE expert weights:FP32 master → FP4 → 无损 dequant 回 FP8 再算。FP8 (E4M3) 比 FP4 (E2M1) 多 2 exponent bits,只要 128×128 FP8 block 内的 32-tile FP4 scale 比值不超阈值,就能把 fine-grained scale 完全吸收。
- CSA 的 indexer QK path:QK activation 全 FP4 cache+load+multiply;index score 再从 FP32 → BF16,top-k selector 2× 加速但 KV recall 还有 99.7%。
推理/rollout 时用真 FP4 kernel,训练时用 simulated(FP4→FP8 dequant)复用 FP8 training framework。
2.4 KV Cache 布局
Figure 6. KV cache 分两块:classical KV cache(CSA/HCA 压缩后的 entries,按 lcm(m,m’) 对齐分块)+ state cache(SWA 的 n_win 个 token + 尚不够压缩的 tail token)。

异构 attention 违反 PagedAttention 的基本假设(固定 block size、统一 eviction policy)。V4 的做法:把 SWA + 未压缩 tail 当成 sequence-specific state 分离管理,剩下用 classical paged layout,block 对齐到 。
On-disk KV cache:CSA/HCA 的压缩 entries 全存盘;SWA entry 因为每层都有 + 未压缩,体积是压缩 entry 的 ~8 倍,给了三档策略(Full / Periodic Checkpoint / Zero SWA Caching)按部署需求选。
3. Pre-Training
- Data: 在 V3 的基础上扩充,强调长文档(科学论文、技术报告)、多语种、agentic data;filtering 批量 auto-generated 和 templated 内容防 model collapse。>32T tokens。
- Tokenizer: 继承 V3 的 128K vocab,加几个 special token 做 context 构造;保留 token-splitting + FIM。
- Flash (284B / 13B act): 43 层,d=4096,前 2 层纯 SWA,其后 CSA/HCA 交错;每 MoE 层 1 shared + 256 routed expert, 激活 6 个;MTP depth=1;n_hc=4。32T token。
- Pro (1.6T / 49B act): 61 层,d=7168,前 2 层 HCA;每 MoE 层 1 shared + 384 routed,激活 6 个;MTP depth=1;n_hc=4。33T token。
- LR schedule: Flash peak 2.7e-4 → 2.7e-5 cosine decay;Pro peak 2.0e-4。Seq len 从 4K 逐步扩到 16K → 64K → 1M。前 1T token dense attention warmup,到 64K 时引入 sparse attention。
- Hash routing: 前 3 层 MoE 用 Hash routing(按 token ID 的 hash function 选 expert)替代 dense FFN——这是个新设计。
- Activation 函数变化: affinity score 的 activation 从 sigmoid 改成 (没细说为什么)。
稳定性的两个经验招数
- Anticipatory Routing: step 的前向用 ,但 routing index 用 。作者 empirically 发现解耦 backbone 和 router 的同步更新能消 loss spike。做法是在 step 就预取 step 的数据,预计算 routing 缓存起来。引入自动检测:loss spike 时才切进来,做一阵再切回。总 wall-clock overhead ~20%(触发时)。
- SwiGLU Clamping: linear 分支 clamp 到 , gate cap 在 10。消除 MoE 层的 outlier,empirically 稳定训练。
❓ 这两个都是”经验观察,机理未知”。Anticipatory Routing 听起来像是用旧 router 给新 backbone 分配 token,相当于给 routing 加了一个 momentum;但为什么这能消 spike?是否是 router 频繁震荡触发 outlier 爆发?作者自己也承认”a comprehensive theoretical understanding remains an open question”。
Base model 结果
DS-V4-Flash-Base (13B act, 284B total) 在大多数 benchmark 上超越 DS-V3.2-Base (37B act, 671B total)——更小但更强,归因于架构改进 + 数据 + 训练优化。Pro-Base 进一步全面领先,尤其在 knowledge-intensive 和 long-context 上提升巨大:
Table 1 (节选). V3.2 vs V4-Flash vs V4-Pro base model。
| Benchmark | V3.2-Base | V4-Flash-Base | V4-Pro-Base |
|---|---|---|---|
| MMLU-Pro (5-shot) | 65.5 | 68.3 | 73.5 |
| Simple-QA verified (25-shot) | 28.3 | 30.1 | 55.2 |
| FACTS Parametric (25-shot) | 27.1 | 33.9 | 62.6 |
| HumanEval (Pass@1) | 62.8 | 69.5 | 76.8 |
| MATH (4-shot) | 60.5 | 57.4 | 64.5 |
| LongBench-V2 (EM) | 40.2 | 44.7 | 51.5 |
Simple-QA 从 28.3 → 55.2 和 FACTS 从 27.1 → 62.6 跳跃巨大,说明数据侧(长文档、多语种)投入见效。
4. Post-Training
4.1 Pipeline: Specialist → OPD
- Specialist training: 对 math / code / agent / IF 等各 domain 独立 SFT + GRPO(继承 V3.2 的 GRPO 设置)得到 10+ 个 domain expert。
- 三档推理强度: Non-think / Think High / Think Max;每档用不同长度惩罚和 context window 训出独立模型。Think Max 额外注入系统 prompt “Reasoning Effort: Absolute maximum with no shortcuts permitted…”。
- OPD (On-Policy Distillation) —— 替换掉 V3.2 的 mixed RL:student 在自己 rollout 的 trajectory 上对齐每个 teacher 的 logit,loss 是 reverse KL:
关键工程决策——full-vocabulary logit distillation:不做 token-level KL 近似(避免 per-token advantage 的高方差),直接在全 vocab ≥100K 上算 KL。Full logits 显存压力巨大,做法是只 cache teacher 最后一层 hidden state(而非 logits),训练时过 prediction head 现场重构 logits;按 teacher 排序调度 mini-batch 让同一 head 在 device 上只加载一次;KL 用 TileLang 特殊 kernel。
- Generative Reward Model (GRM): actor 本身兼任 GRM,用 rubric-guided 数据 + RL 联合训练”生成”和”评判”两种能力——省掉额外 scalar reward model 的标注。
4.2 Tool Call 新 schema
引入 <|DSML|> special token 和 XML 风格 tool call:
<|DSML|tool_calls>
<|DSML|invoke name="$TOOL_NAME">
<|DSML|parameter name="$PARAM" string="true|false">$VALUE
</|DSML|parameter>
</|DSML|invoke>
</|DSML|tool_calls>
作者说 XML 比 JSON 减少 escaping 失败和 tool-call error。
4.3 Interleaved Thinking + Quick Instruction
- Tool-calling 保 thinking trace 跨 user turn(V3.2 会清空),让 agent 长 horizon 任务保有累积的 reasoning chain。
- Quick Instruction: 在 prompt 末尾加
<|action|>/<|title|>/<|query|>/<|authority|>/<|domain|>/<|extracted_url|>/<|read_url|>等 special token,复用已算好的 KV cache 做 intent detection / query rewrite 等 auxiliary task,替代单独的小模型——直接砍掉 redundant prefill,降低 TTFT。
4.4 Infra 亮点
- Preemptible & Fault-Tolerant Rollout Service: token-granular Write-Ahead Log + KV cache persistence;preempt 后恢复不需要重跑 rollout。作者强调:如果简单重跑,短 response 被中断概率低会造成 length bias,偏向短输出——这是容易被忽视的 subtle bug。
- DeepSeek Elastic Compute (DSec): 四种执行底座(Function Call / Container / microVM / fullVM)统一 Python SDK;基于 3FS 的 EROFS / overlaybd 快速启动;单 cluster 管理数十万并发 sandbox。
- Scaling RL for 1M context: 拆 rollout data 为 lightweight metadata + heavy per-token field,metadata 用于 global shuffle,per-token field 通过 shared memory 加载、mini-batch 粒度释放。
5. Evaluation
5.1 前沿对比(Max mode)
Table 6 (节选). DS-V4-Pro-Max vs 闭源和开源前沿。 加粗= 最佳,下划线= 次佳。
| Benchmark | Opus-4.6 | GPT-5.4 | Gemini-3.1-Pro | K2.6 | GLM-5.1 | DS-V4-Pro-Max |
|---|---|---|---|---|---|---|
| MMLU-Pro | 89.1 | 87.5 | 91.0 | 87.1 | 86.0 | 87.5 |
| SimpleQA-Verified | 46.2 | 45.3 | 75.6 | 36.9 | 38.1 | 57.9 |
| HLE (Pass@1) | 40.0 | 39.8 | 44.4 | 36.4 | 34.7 | 37.7 |
| LiveCodeBench | 88.8 | — | 91.7 | 89.6 | — | 93.5 |
| Codeforces (Rating) | — | 3168 | 3052 | — | — | 3206 |
| HMMT 2026 Feb | 96.2 | 97.7 | 94.7 | 92.7 | 89.4 | 95.2 |
| IMOAnswerBench | 75.3 | 91.4 | 81.0 | 86.0 | 83.8 | 89.8 |
| MRCR 1M | 92.9 | — | 76.3 | — | — | 83.5 |
| CorpusQA 1M | 71.7 | — | 53.8 | — | — | 62.0 |
| SWE Verified | 80.8 | — | 80.6 | 80.2 | — | 80.6 |
| BrowseComp | 83.7 | 82.7 | 85.9 | 83.2 | 79.3 | 83.4 |
核心观察:
- Code / 数学竞赛:DS-V4-Pro-Max 全面领先;Codeforces rating 3206 超过 GPT-5.4 和 Gemini,第一次 open model 在 Codeforces 上匹敌 closed。作者说它在 Codeforces leaderboard 上排第 23 位(人类之中)。
- Knowledge:SimpleQA-Verified 比所有开源对手领先约 20 pt,但距 Gemini-3.1-Pro 的 75.6 仍差 ~18 pt。
- Long context: CorpusQA 1M 超 Gemini-3.1-Pro;MRCR 1M 超 Gemini 但低于 Opus-4.6。
- Agent: 与 K2.6/GLM-5.1 持平,落后闭源。
作者自己评估:“trails state-of-the-art frontier models by approximately 3 to 6 months”——这是很诚实的 self-assessment。
5.2 1M Context 表现
Figure 9. MRCR 8-needle 从 8K 到 1024K 的 accuracy——128K 以内稳定,超过后有退化,但 1M 仍 0.59/0.66(Flash/Pro)。
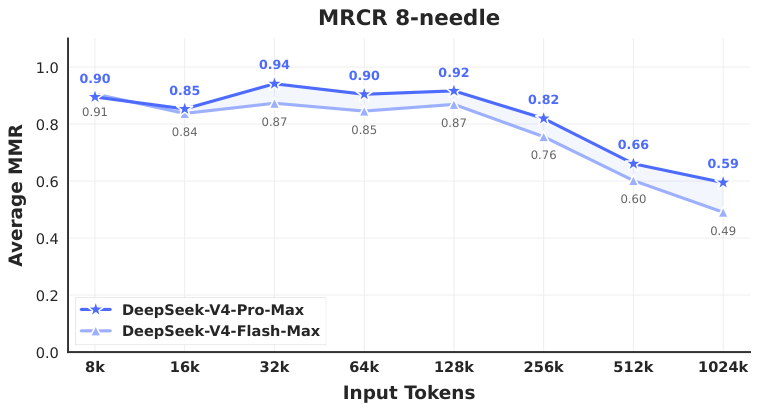
Pro 从 8K→1M 只掉 0.10 pt(0.92→0.82)左右,确实比很多 long-context 宣称的”1M 能用”更有说服力。但 MRCR 本质还是 retrieval,真实 long-horizon reasoning 是否 work 还需 CorpusQA 等更复杂 benchmark 验证。
5.3 Reasoning Effort 的 test-time scaling
Figure 10. HLE 和 Terminal Bench 2.0 上随 total token 增加的 pass@1——Pro 比 V3.2 token-efficiency 显著更高。
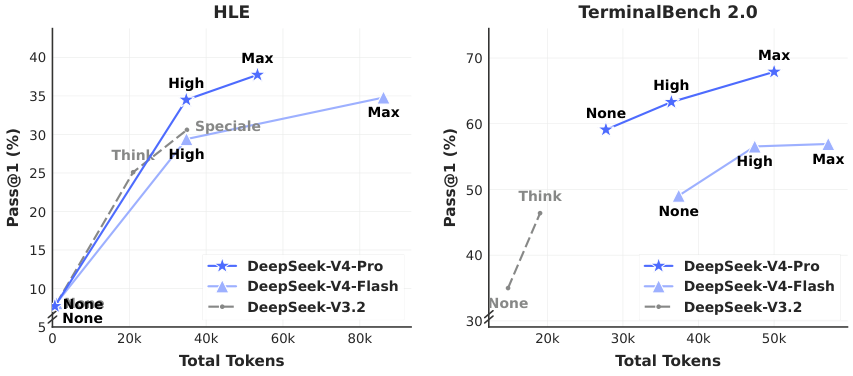
Max mode 在最难 task 上 consistently 优于 High。但边际收益递减——token 翻倍带来的 gain 在 20k→60k 区间明显弱于 0→20k。
5.4 Formal math + Agent 使用案例
- Putnam-2025: DS-V4 reach 120/120 in hybrid informal-formal regime(与 Axiom 并列);Practical regime (Putnam-200 Pass@8) DS-V4-Flash-Max 达 81.00,远超 Seed-2.0-Pro 的 35.50。
- 内部 R&D Coding Benchmark: 30 个真实任务,DS-V4-Pro-Max 67% pass rate,超 Sonnet 4.5 (47%),逼近 Opus 4.5 (70%),落后 Opus 4.6 Thinking (80%)。
- 内部 developer survey (N=85): 52% 说 V4-Pro 可做默认 coding model,39% lean yes,< 9% no。
6. Limitations (作者自述)
- “Bold architectural design” 为降低 risk 保留了很多 preliminarily validated components 和 tricks → 架构偏复杂,未来要 distill 到 essential designs。
- Anticipatory Routing 和 SwiGLU Clamping 机理不清。
- 准备探索 beyond MoE + sparse attention 的 sparsity 轴——例如 sparse embedding (Cheng et al., 2026 即 Engram paper)。
- 多模态能力还没集成。
关联工作
基于
- DeepSeek-V3 (DeepSeek-AI, 2024):所有底座——DeepSeekMoE、MTP、FIM、token-splitting、pre-train infra,V4 只改 attention / residual / optimizer。
- DeepSeek-V3.2 (DeepSeek-AI, 2025):DSA (DeepSeek Sparse Attention) 和 Lightning Indexer 直接被 CSA 复用;post-train pipeline 基础。
- Muon (Jordan et al., 2024; Liu et al., 2025):Newton-Schulz + orthogonalization,V4 加了 hybrid 系数版本。
- Hyper-Connections (Zhu et al., 2025):mHC 的前驱,V4 加上 Birkhoff 流形约束解决不稳定。
- DeepSeekMoE (Dai et al., 2024):fine-grained + shared expert 路由。
- GRPO (DeepSeek-AI, 2025 = R1 paper):Specialist 阶段 RL 算法。
- On-Policy Distillation (Lu & Thinking Machines Lab, 2025):OPD 形式化。
- DeepSeek-AI 2025 Engram paper (Cheng et al., 2026, arXiv:2601.07372):conditional memory,作为”未来 sparsity 轴”被前瞻 reference。
对比
- Kimi K2.6 / GLM-5.1: 开源 frontier baseline,V4-Pro-Max 与其持平或略胜。
- Claude Opus 4.6 / GPT-5.4 / Gemini-3.1-Pro: 闭源 frontier,V4 落后 3-6 月。
- Comet (Zhang et al., 2025b): EP overlap 前作,V4 的 wave-grained fuse 声称 theoretical speedup 1.42× → 1.92×。
- Jenga / Hymba: 现有 hybrid KV cache 方案,V4 另起 state cache + classical cache 分离的设计。
方法相关
- TileLang (Wang et al., 2026):DSL for kernel;V4 大规模使用。
- DeepGEMM (Zhao et al., 2025):替代 cuBLAS 实现 batch-invariant;V4 的 MegaMoE 是它的一个 PR。
- 3FS (DeepSeek-AI, 2025):分布式 FS,DSec 运行在其上。
- Attention Sink (Xiao et al., 2024 / OpenAI, 2025):learnable sink logit。
- FP4 MXFP4 (Rouhani et al., 2023):Microscaling data format。
- DualPipe 1F1B:pipeline 并行。
- Torch.fx (Reed et al., 2022):用于 tensor-level checkpoint。
- GDPval-AA / Apex / HMMT / LiveCodeBench: 主要 benchmark。
- π0-style Benchmark 等不相关(此处无)。
论文点评
Strengths
- 工程整合深度罕见:58 页把 attention 架构、optimizer、precision、kernel DSL、KV cache 管理、rollout 容灾、sandbox 平台全部说清楚。可以当 MoE 大模型工程 checklist 用。
- 1M context 是真 1M:MRCR 在 1024K 下 Pro 仍 0.82 (8-needle),FLOPs 和 KV cache 两个 axis 都给出了相对 V3.2 的量化比较(27% / 10%),不是 marketing 的 “technically supports”。
- Full-vocabulary OPD 值得注意:多数 distill 工作走 token-level KL 近似,V4 硬做 full 100K+ vocab + 10+ teacher 的真 KL——通过 teacher hidden-state caching + 按 teacher 排序调度让它工程上可行。这条路径如果被验证比 mixed RL 更稳,可能改变 post-training 的 default 做法。
- Honest self-assessment:明确说”落后 frontier 3-6 月”、“mHC 和稳定性 trick 机理未知”、“架构需要未来 distill 到 essential”。罕见的不吹。
- 开源:模型权重(FP4+FP8 mixed 和 Base FP8 版本都给)、MegaMoE kernel、inference reference implementation 都在 HF 上。
Weaknesses
- 没有 ablation 回答”哪部分最重要”:CSA vs HCA、mHC vs 标准 HC、Muon vs AdamW、FP4 QAT vs FP8 的隔离比较都没有。全是 full system 对比,很难知道架构改动的单独贡献。
- Attention 架构是”工程集成”而非 “scientific contribution”:CSA = “DSA + token-level compression”,HCA = “大块压缩 + dense MQA”,都是 已有 ideas 的拼装;mHC 是 HC 加 Birkhoff 约束。作者自己在 limitation 承认”为 minimize risk 保留了很多 preliminarily validated components”——这等同于说架构不够优雅。
- 稳定性 trick 机理真空:Anticipatory Routing 和 SwiGLU Clamping 都是”发现能 work 就用”,没有理论或即便是 motivated 的 hypothesis。作为 1.6T 模型的稳定性支柱,这是个问题——换场景是否仍 work?
- 长 context benchmark 太少:只有 MRCR 和 CorpusQA,前者是 retrieval,后者是 reading comprehension。agentic long-horizon(比如 100K+ multi-turn reasoning chain)没覆盖。
- Knowledge 差距仍大:SimpleQA-Verified 57.9 vs Gemini 75.6,Chinese-SimpleQA 84.4 vs 85.9。open-source SOTA 但离前沿还有 diff。
- Preview 版本: 标题就写 “preview version”,意味着还会有后续。现在 digest 是个 snapshot,实际架构可能 refine。
可信评估
Artifact 可获取性
- 代码: inference-only(HF repo 的
inference/子目录);training code 未开源。MegaMoE kernel 开源在 DeepGEMM。 - 模型权重: 已发布 DeepSeek-V4-Flash-Base, DeepSeek-V4-Flash (FP4+FP8), DeepSeek-V4-Pro-Base, DeepSeek-V4-Pro (FP4+FP8)——四个 checkpoint 都在 HF 和 ModelScope,MIT License。
- 训练细节: 高层超参(LR schedule、batch size、Muon γ=0.18、mHC n_hc=4 等)完整披露;但 RL reward model 细节、domain expert 的 rollout 样本数等 post-train 具体配方较少。数据配比只给”> 32T tokens”和高层分类(math/code/web/long-doc/multilingual)。
- 训练硬件: 未披露——paper 只说 MegaMoE kernel 在 NVIDIA GPU 和华为 Ascend NPU 上做了 validation,使用了 thread-block cluster / distributed shared memory(Hopper+ 特性)和 FP8/FP4,但训练集群的卡型、卡数、总 GPU-hour 一概未提。V3 paper 曾披露 H800 × 2048,V3.2 和 V4 都不再披露,应是 export control + 商业敏感的考虑。
- 数据集: 完全私有,未公开。
Claim 可验证性
- ✅ 1M context 的 FLOPs/KV cache 节省:公式 显式给出,KV cache 结构图清楚,可以 reverse-engineer 验证。
- ✅ Benchmark 数字:权重开源,SimpleQA / MRCR 等可独立复现。
- ✅ MegaMoE speedup:kernel 开源到 DeepGEMM。
- ⚠️ mHC 对训练稳定性的贡献:无 ablation,只有 full-system final loss。
- ⚠️ Anticipatory Routing 和 SwiGLU Clamping 有效:empirical claim 没有 controlled experiment,只有 “we found it works”。
- ⚠️ Full-vocab OPD 比 token-level KL approx 更稳:没给定量对比。
- ⚠️ “Codeforces 3206 超过 GPT-5.4”:Codeforces 是作者 internal benchmark(14 contest, 114 problem),评分规则依赖 median human score,采样 + ordering 不同 run 可能有 variance,没给 stderr。
- ❌ 无明显营销话术;self-assessment 偏诚实。
Notes
- OPD 替代 mixed RL 是个 direction-level change,值得关注后续是否成为 post-training 新默认。
- 架构的复杂度和作者自述的 “risk minimization” 是个信号——如果下一版(可能就叫 V5)能把 CSA+HCA 合并或更 elegant,反向印证现在架构的哪些部分是累赘。
- 对 agentic 方向的启示:DSec sandbox 平台 + preemptible rollout + trajectory log 的组合是大规模 agent RL 的 production 级别 infra,可以借鉴。
- 对 research taste:这不是 “0 → 1” 的工作,是 “1 → 2” 的极致工程化。如果目标是理解”高效 million-context 到底什么最重要”,需要继续等或自己做 ablation。
Rating
Metrics (as of 2026-04-24): citation=N/A(未发布到 arXiv,技术报告形式托管于 HuggingFace); influential=N/A(同上); velocity=N/A(同上); HF upvotes=332(deepseek-ai/DeepSeek-V4-Pro model likes,发布 2 天内); github=N/A(deepseek-ai/DeepSeek-V4 repo 尚不存在,仅权重在 HF)
分数:2 - Frontier
理由:阶段性的 open-source SOTA,Codeforces/LiveCodeBench 超过部分闭源是真实 frontier 信号;1M context 的效率数字是实打实的工程优势。但不是 Foundation——attention 架构是 CSA/HCA/DSA/Hyper-Connections 等已有 idea 的集成,非开创性;作者自己也说架构偏复杂有待简化;Muon、mHC、OPD 都是别人先做的。三年后回头看,这大概率会被更 elegant 的后继取代(正如 V3 被 V4 取代)。所以在 Frontier 档(方向的当前 SOTA / 必引 baseline)而非 Foundation 档(奠基、必读)。