Summary
Kimi K2.5: Visual Agentic Intelligence
- 核心: 把 1T-param MoE 文本模型 (Kimi K2) 通过 ~15T mixed vision-text token 的 continual pre-training 升级为原生多模态 agentic 模型;同时引入 Agent Swarm,让 orchestrator 通过 PARL 学习并行调度 frozen 子 agent。
- 方法: (1) Native multimodal pre-training (early fusion + low vision ratio) + zero-vision SFT + 联合多模态 RL;(2) MoonViT-3D 共享图像/视频编码空间;(3) Parallel-Agent RL — 训练 orchestrator + 冻结子 agent,用 critical-steps 作为资源约束。
- 结果: 在 reasoning / coding / vision / agentic benchmark 上对位 Claude Opus 4.5 / GPT-5.2 / Gemini 3 Pro;Agent Swarm 在 BrowseComp 78.4%(超 GPT-5.2 Pro 77.9)、WideSearch 79.0%;wide-search 上比单 agent 快 3-4.5×。
- Sources: paper | website | github
- Rating: 2 - Frontier(open-weight frontier VLM + 首个 system-level RL-trained agent swarm,在 agentic / video benchmark 上 frontier,但方法论以工程整合为主,未达 Foundation 的奠基性)
Key Takeaways:
- Early fusion 优于 late fusion:固定 vision-text token 预算下,10:90 ratio 全程混合 > 50:50 后期注入,挑战了”先训文本再贴视觉”的主流做法。
- Zero-vision SFT 即可激活视觉 agentic 能力:text-only SFT(图像操作通过 IPython 代码完成)比 text-vision SFT 更通用,因为 joint pre-training 已建立 vision-text 对齐——加视觉 SFT 反而损害泛化。
- Vision RL 反向增益 text:MMLU-Pro +1.7、GPQA-Diamond +2.1、LongBench v2 +2.2,说明视觉 RL 改善了 calibration & 结构化抽取,跨模态泛化是 free lunch。
- Agent Swarm = 主动 context 管理:通过 sub-agent 分片(context sharding)替代被动截断/总结,单 agent (60.6%) → swarm (78.4%) 的 BrowseComp 提升不只是速度。
- PARL 决耦训练:orchestrator trainable + sub-agent frozen,回避 credit assignment ambiguity;用
critical steps(最长并行支路长度之和)作 resource metric 抑制 spurious parallelism。
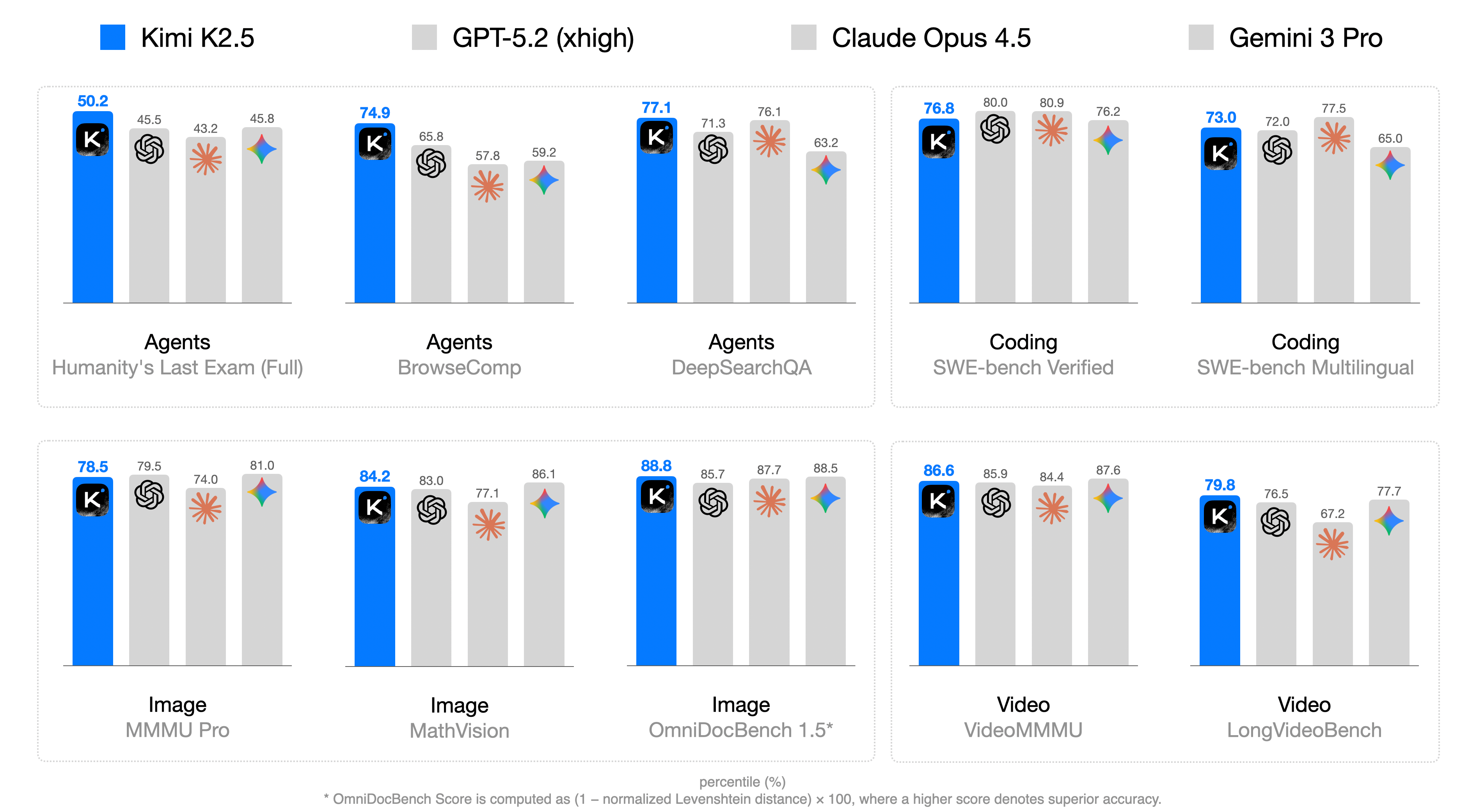
Teaser. Kimi K2.5 主结果总览:跨 reasoning / coding / vision / agentic 的多面雷达图,对比 Claude Opus 4.5 / GPT-5.2 / Gemini 3 Pro / DeepSeek-V3.2 / Qwen3-VL。
1. Motivation 与定位
LLM agent 当前两个核心瓶颈:
- 模态分裂:vision 通常作为后期 adapter 加在文本 backbone 上,导致 vision/text 互相竞争而非互相增益。
- 顺序执行的延迟天花板:即使是 Kimi K2-Thinking 这种支持上百 step reasoning 的系统,inference time 仍线性 scale,限制可处理任务的复杂度。
K2.5 的两条主要 bet:
- Joint Optimization of Text and Vision — 从 pre-training 到 RL 全程统一两模态。
- Agent Swarm + PARL — 把任务复杂度从 linear scaling 拆成 parallel processing。
❓ 论文反复强调”native multimodal”和”joint optimization”,但 K2.5 是从 K2 文本 checkpoint 续训的,本质上仍是 mid-fusion 的工程性 continual pre-training。它和 Gemini / GPT-4o 那种”从零原生多模态”还是有区别——更像是”激进 early fusion 的 continual pre-training”。
2. Joint Optimization of Text and Vision
2.1 Native Multimodal Pre-training
Table 1. 不同 vision-text joint-training 策略对比(固定总 token 预算)
| Vision Injection Timing | Vision-Text Ratio | Vision Knowledge | Vision Reasoning | OCR | Text Knowledge | Text Reasoning | Code | |
|---|---|---|---|---|---|---|---|---|
| Early | 0% | 10:90 | 25.8 | 43.8 | 65.7 | 45.5 | 58.5 | 24.8 |
| Mid | 50% | 20:80 | 25.0 | 40.7 | 64.1 | 43.9 | 58.6 | 24.0 |
| Late | 80% | 50:50 | 24.2 | 39.0 | 61.5 | 43.1 | 57.8 | 24.0 |
关键 insight:早期低比例融合(10:90)反而更优。Appendix 进一步揭示 mid/late fusion 中存在 “dip-and-recover” 模式——突然引入 vision token 会破坏已建立的 linguistic representation space,逼模型短期牺牲文本能力换跨模态对齐。Early fusion 全程平稳。
这个发现挺反直觉。直觉上”先把语言学好再加视觉”更像 curriculum learning,但实测 representation space 的”重构成本”远大于早期同时学的”塑形成本”。这点对 VLA / Video LLM 的训练 recipe 都有借鉴意义。
2.2 Zero-Vision SFT
Pretrained VLM 不会主动 vision-based tool calling,是 multimodal RL 的 cold start 难题。常见做法是手工 CoT 数据,但多样性差,往往限制在简单 crop/rotate/flip。
K2.5 做法:只用 text SFT 数据,所有图像操作 proxy 为 IPython 代码(binarization、object size estimation via counting 等)。这相当于把传统 “vision tool use” 推广为通用编程操作。
发现:text-vision SFT 反而更差。作者归因为 joint pre-training 已建立 vision-text alignment,所以 text SFT 的 reasoning 行为可以自然 generalize 到 visual tasks;引入低质量 vision SFT 反而引入 noise。
❓ 这个 “text-vision SFT 反而更差” 的对照是否严谨?如果是因为 vision SFT 数据质量差而非方法本身有问题,那 zero-vision 的优越性就被夸大了。论文未给出 vision SFT 数据的细节。
2.3 Joint Multimodal RL
Outcome-based visual RL 用三类需要视觉理解才能解的任务:
- Visual grounding & counting
- Chart & document understanding
- Vision-critical STEM problems
Table 2. 视觉 RL 改进文本性能(cross-modal transfer)
| Benchmark | Before Vision-RL | After Vision-RL | Δ |
|---|---|---|---|
| MMLU-Pro | 84.7 | 86.4 | +1.7 |
| GPQA-Diamond | 84.3 | 86.4 | +2.1 |
| LongBench v2 | 56.7 | 58.9 | +2.2 |
作者的解释是 visual RL 改善了 structured information extraction 的 calibration,比如 counting / OCR 类查询的 grounding。
K2.5 在 RL 中按能力而非模态分组(knowledge / reasoning / coding / agentic),所有 domain expert 同时学 text 和 multimodal query,GRM 也跨模态评估。
3. Agent Swarm 与 PARL
3.1 设计动机
Sequential agent 存在 reasoning depth & tool-call budget 的硬性上限。K2.5 主张:parallelism 是否有利不预设,让 RL 学。
3.2 架构
Figure 3. Agent Swarm 架构:trainable orchestrator + frozen sub-agent,orchestrator 学动态任务分解、子 agent 实例化、并行调度。

PARL 的核心 design choice:sub-agent 冻结,只把 trajectory 当 environmental observation。这避免了端到端协同优化的两个老大难问题:
- Credit assignment ambiguity:稀疏 outcome reward 下,无法把成败归因到单个 sub-agent。
- Training instability:多 agent 联合优化的方差爆炸。
代价:sub-agent 的能力上限被冻结时点决定;得在 orchestrator 学习中分阶段切换 sub-agent 大小。
3.3 PARL Reward
Equation. PARL reward
符号说明:
r_parallel防止 serial collapse(orchestrator 退化成单 agent)r_finish防止 spurious parallelism(spawn 一堆无意义 sub-agent 刷并行度指标)λ₁, λ₂在训练中 anneal 到 0,最终只优化主任务 reward
3.4 Critical Steps as Resource Constraint
Equation. Critical Steps(类比 computation graph 的 critical path)
只算每个并行组里最长子 agent 的 step 数。这从 metric 层面对齐了”实际 wall-clock 时间”,逼 orchestrator 做平衡分解而非滥造 sub-agent。
这个设计很聪明。简单用”总 step 数”作约束会鼓励 orchestrator 减少并行;改用 critical path 后,balanced parallelism 才是 reward maximizer。
3.5 Prompt Engineering for Capability Induction
合成两类任务:
- Wide search:同时探索很多独立信息源
- Deep search:多分支 reasoning + delayed aggregation
外加 long-context document analysis 与 large-scale file downloading。不显式告诉模型要并行——只是让顺序执行的预算不够,逼并行策略自然涌现。
4. 架构与训练
4.1 Foundation: Kimi K2
- 1.04T total / 32B activated MoE
- 384 expert,每 token 激活 8 个(sparsity 48)
- MuonClip optimizer + QK-Clip 稳定性
- 15T text tokens 预训练
4.2 MoonViT-3D
- 从 SigLIP-SO-400M 初始化,沿用 NaViT patch packing 处理原生分辨率
- 视频处理:连续 4 帧打包成时空 volume,2D patch 联合 flatten + temporal pooling 4× 压缩
- 完全 weight-shared between image / video,便于知识从 image 迁移到 video
Table 3. 训练 stages
| Stage | ViT Training | Joint Pre-training | Joint Long-context Mid-training |
|---|---|---|---|
| Data | Alt text / Caption / Grounding / OCR / Video | + Text, Knowledge Interleaving, Video, OS Screenshot | + High-quality Text & Multimodal, Long Text, Long Video Reasoning, Long-CoT |
| Sequence length | 4096 | 4096 | 32768 → 262144 |
| Tokens | 1T | 15T | 500B → 200B |
| Trainable | ViT | ViT & LLM | ViT & LLM |
4.3 Token Efficient RL — Toggle
观察:固定 token budget RL 会导致 length-overfitting——模型无法利用更多 inference token 解难题。
Toggle:每 m 步交替两个 phase
- Phase 0 (budget limited):仅当某 prompt 的 mean accuracy > λ 时才施加 budget
- Phase 1 (standard scaling):放开到最大 token 限制
效果:Kimi K2-Thinking 输出 token 减少 25-30%,性能近乎无损;且 math/code 训出的能力可泛化到 GPQA/MMLU-Pro。
4.4 Decoupled Encoder Process (DEP)
多模态训练的核心 infra trick:
- Balanced Vision Forward:所有 GPU 复制 ViT,按 patch 数 load-balance vision encoder forward,仅保留输出 activation
- Backbone Training:text-only 的并行策略可直接复用,gradient 累积到 ViT 输出
- Vision Recomputation & Backward:重算 vision forward + backward
效果:multimodal training 效率达 text-only 的 90%,并提到 LongCat-Flash-Omni 同期独立提出类似设计。
5. 评估
5.1 主表(节选)
Table 4. 跨 benchmark 与 Claude Opus 4.5 / GPT-5.2 / Gemini 3 Pro / DeepSeek-V3.2 / Qwen3-VL 对比(节选关键行)
| Benchmark | K2.5 | Claude Opus 4.5 | GPT-5.2 (xhigh) | Gemini 3 Pro | DeepSeek-V3.2 |
|---|---|---|---|---|---|
| HLE-Full (w/ tools) | 50.2 | 43.2 | 45.5 | 45.8 | 40.8† |
| AIME 2025 | 96.1 | 92.8 | 100 | 95.0 | 93.1 |
| GPQA-Diamond | 87.6 | 87.0 | 92.4 | 91.9 | 82.4 |
| SWE-Bench Verified | 76.8 | 80.9 | 80.0 | 76.2 | 73.1 |
| BrowseComp | 60.6 | 37.0 | 65.8 | 37.8 | 51.4 |
| BrowseComp (Swarm) | 78.4 | - | - | - | - |
| WideSearch | 72.7 | 76.2 | - | 57.0 | 32.5 |
| WideSearch (Swarm) | 79.0 | - | - | - | - |
| OSWorld-Verified | 63.3 | 66.3 | 8.6 | 20.7 | - |
| MMMU-Pro | 78.5 | 74.0 | 79.5 | 81.0 | - |
| LongVideoBench | 79.8 | 67.2 | 76.5 | 77.7 | - |
观察:
- agentic search 强:BrowseComp (Discard-all 上下文管理) 74.9 单 agent,加 swarm 78.4;OSWorld 63.3 接近 Claude Opus 4.5(66.3),远超其他 open / proprietary。
- video understanding 全 SOTA:LVBench 75.9 / LongVideoBench 79.8 全部领先,显示 MoonViT-3D 共享 image/video 设计是 effective 的。
- frontier reasoning 仍弱于 GPT-5.2:HLE-Full 30.1 vs GPT-5.2 的 34.5;AIME 96.1 vs 100。
- SimpleQA Verified 远落后 Gemini 3 Pro(36.9 vs 72.1),世界知识仍是短板。
5.2 Agent Swarm 详细结果
Table 6. Agent Swarm vs single agent vs proprietary baseline
| Benchmark | K2.5 Agent Swarm | K2.5 (single) | Claude Opus 4.5 | GPT-5.2 | GPT-5.2 Pro |
|---|---|---|---|---|---|
| BrowseComp | 78.4 | 60.6 | 37.0 | 65.8 | 77.9 |
| WideSearch | 79.0 | 72.7 | 76.2 | - | - |
| In-house Swarm Bench | 58.3 | 41.6 | 45.8 | - | - |
In-house Swarm Bench 提升最大 (+16.7%),因为任务设计就是为 parallel decomposition 量身定做。
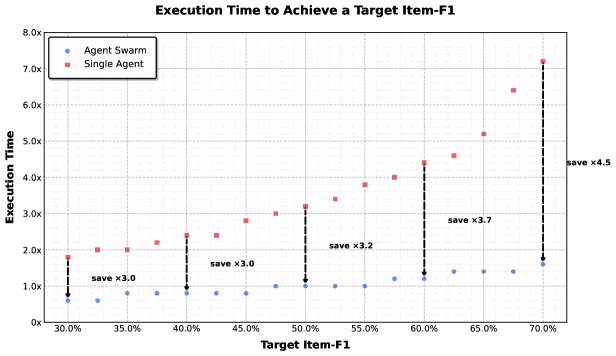
Figure 8. Agent Swarm 在 WideSearch 上的执行时间对比:随着目标 Item-F1 从 30% 升到 70%,单 agent 时间从 1.8× 涨到 7.0×,Agent Swarm 维持在 0.6-1.6× 区间——即 3-4.5× 加速。
5.3 Agent Swarm as Proactive Context Management
论文一个重要 framing:Agent Swarm 不只是加速,更是 proactive context management。
- 传统 reactive 方案:Hide-Tool-Result / Summary / Discard-all 都是 context overflow 后被动 truncate。
- Agent Swarm 用 context sharding:每个 sub-agent 有 bounded local context,只把 task-relevant 输出回送 orchestrator。
效果:在 BrowseComp 上既快又准,超过 Discard-all。
这是个挺有意思的视角——把 multi-agent 重新解读为”一种正交的 context scaling 维度”,而不只是并行加速。如果属实,single agent 的 context window scaling 就有了竞争维度。
关联工作
基于
- Kimi K2 (1T MoE base):K2.5 全部能力的语言基础,MuonClip optimizer / QK-Clip 直接继承
- Kimi-VL (MoonViT):MoonViT-3D 的 image-only 前身
- Kimi K2-Thinking:作为 sub-agent 框架的 baseline,被 Toggle 优化(25-30% token 减少)
- SigLIP-SO-400M + NaViT:MoonViT-3D 初始化 + patch packing 策略
对比
- Claude Opus 4.5 / GPT-5.2 / Gemini 3 Pro:proprietary frontier baseline
- DeepSeek-V3.2:open-source text reasoning baseline
- Qwen3-VL-235B-A22B-Thinking:open-source vision baseline
- LongCat-Flash-Omni:concurrent work 同样采用 decoupled vision encoder 思路
方法相关
- Parallel agent / multi-agent orchestration:与 LangGraph、AutoGen、LLM-Compiler 等系统级方案对比,但 K2.5 是 RL trained orchestrator 而非 LLM-as-orchestrator prompting
- Context management:Hide-Tool-Result、Summary、Discard-all 是 reactive baseline,K2.5 主张 proactive sharding
- Token-efficient RL:Toggle 与 length-budget RL 工作(K1.5)一脉相承
- Native multimodal pre-training:与 Chameleon、Gemini 早期混合训练思路一致,但 K2.5 强调”low ratio + early”是 Pareto optimal
论文点评
Strengths
- Native multimodal pre-training 的 ablation 有说服力:Table 1 + Figure 9 的 dip-and-recover 现象给出 early fusion 的实证依据,这是 community 反直觉但有用的 finding。
- Zero-vision SFT 优雅:把 image manipulation 统一为 IPython 代码,绕过手工 vision CoT 数据的 diversity bottleneck,思路漂亮。
- PARL 的工程性 design:frozen sub-agent + critical steps + r_parallel/r_finish 的反 reward-hacking 设计,把 multi-agent RL 的训练问题拆得很干净。
- Cross-modal RL transfer 的发现:vision RL 提升 text benchmark 是个正面 free lunch,如果可复现会改变多模态 post-training 的范式。
- 真开源:post-trained checkpoints 在 HF 上可下载(虽然 GitHub README 较薄)。
Weaknesses
- 方法栈过于 incremental:每个组件单独看都不算 novel——early fusion、joint RL、parallel agent、frozen sub-agent 都各自有先行研究。论文是 well-engineered 的 system paper,但缺少根本性的 conceptual contribution。
- In-house Swarm Bench 不开源:Agent Swarm 最亮眼的性能提升(+16.7%)来自 internal benchmark,无法独立复现。
- PARL 的 frozen sub-agent 是 ceiling:sub-agent 能力受冻结时点限制,长期来看 orchestrator 与 sub-agent 的 co-evolution 必然会成为瓶颈。论文未讨论 scaling 到更大 sub-agent 时的 transfer 策略。
- Visual RL → text 提升 +1.7~+2.2 的归因含糊:作者解释为 calibration 改善,但缺少对照实验(如 RL 总 step 数、数据多样性)排除”训练时间更长”等替代解释。
- HLE / SimpleQA 大幅落后:核心 frontier reasoning 与世界知识仍弱于 GPT-5.2 / Gemini 3 Pro,“SOTA”主要在 agentic + 视频场景。
- Toggle 算法描述粗糙:phase 切换的 m 取值、λ 阈值如何设定都没给,复现门槛高。
可信评估
Artifact 可获取性
- 代码: README 仅给出基本介绍,无明确 inference / training code 链接。可推断为 inference-only via API & HF。
- 模型权重: Kimi K2.5 post-trained checkpoint 在 HuggingFace
moonshotai/Kimi-K2.5发布(Modified MIT License);同时通过 platform.kimi.ai API 提供。 - 训练细节: 高层方法描述完整(stage 分配、token 量、sequence length),但具体超参(learning rate schedule、RL batch size、Toggle 的 m/λ/ρ)大多未披露;DEP 算法层面有描述无伪代码。
- 数据集: 大部分私有(in-house benchmark、SFT data、RL prompts);评估 benchmark 全部公开。Agent Swarm 的训练 prompt 设计描述较泛,无法精确复现。
Claim 可验证性
- ✅ agent swarm 在 wide-search 上 3-4.5× 加速:论文 Figure 8 给出 WideSearch 上随目标 Item-F1 变化的曲线,metric 定义清晰(Item-F1 + 执行时间),可验证。
- ✅ BrowseComp 60.6 单 agent / 78.4 swarm:公开 benchmark,可在 API 端复测。
- ✅ Early fusion 优于 late fusion(Table 1):标准 ablation 设计,token 预算固定,结论 well-supported。
- ⚠️ Visual RL 提升 text +1.7~+2.2:单一前后对照,缺少对照组排除”训练时间 / 数据多样性”等混淆变量。
- ⚠️ In-house Swarm Bench 提升 +16.7%:benchmark 不开源,无法独立验证。
- ⚠️ “agent swarm = proactive context management”:framing 漂亮,但只在 BrowseComp 一个 benchmark 上对比 Discard-all,泛化性证据弱。
- ❌ “new SOTA in visual-to-code generation”:作者称 internal evaluations 显示 SOTA,无 public benchmark 数据,是 marketing claim。
- ❌ “open-source” 模糊定义:发布的是 post-trained checkpoint + Modified MIT;training code、PARL 实现、in-house data pipeline 全部未开源。技术报告级别的”open”。
Notes
- 对我的研究 takeaway:
- Agent Swarm + PARL 的 frozen sub-agent 设计对 GUI agent / computer-use agent 的 hierarchical RL 训练有借鉴意义,特别是 critical-steps 这个 metric 能直接搬到 long-horizon GUI 任务里。
- Zero-vision SFT 的思路对 VLA 也有启发:是否可以 text-only SFT + IPython-style action proxy 来 bootstrap manipulation policy?需要思考 text → action 的 grounding 是否成立(文本 IPython 操作有自然 grounding,物理动作没有)。
- “Visual RL improves text” 如果是真现象,对 VLM 的 RL training data mix 设计有实践意义——别怕加视觉数据。
- 疑问:
- PARL 中 sub-agent 完全 frozen,那 orchestrator 学到的 task decomposition 策略是否会 over-fit 到当前 sub-agent 的能力分布?升级 sub-agent 后 orchestrator 是否需要重训?
- “Joint pre-training establishes vision-text alignment, so text SFT generalizes”——这个解释是否能用 representation analysis (probing) 验证?
- 后续:值得追踪 Moonshot 是否后续放出 PARL 训练代码 / In-house Swarm Bench;如开源,PARL 应是值得复现的 baseline。
Rating
Metrics (as of 2026-04-24): citation=95, influential=5 (5.3%), velocity=35.19/mo; HF upvotes=267; github 1848⭐ / forks=215 / 90d commits=2 / pushed 83d ago
分数:2 - Frontier 理由:K2.5 在 open-weight VLM 里属于 frontier——BrowseComp 单 agent 60.6 / swarm 78.4、OSWorld 63.3、LongVideoBench 79.8 均对位或超过 Claude Opus 4.5 / GPT-5.2(见正文 §5.1),且 PARL + critical-steps 是首个 system-level RL-trained agent swarm 的公开方案,这是 agentic RL 方向必须 cite 的参考点。之所以不到 3 - Foundation:方法栈偏 incremental(early fusion、frozen sub-agent 各有先行),核心 novelty(PARL)的训练代码与 in-house Swarm Bench 未开源导致难以成为 de facto baseline;之所以不降到 1 - Archived:发布仅 2 个月,open-weight 同档位 VLM 竞争者有限,仍会被直接 cite 和复测。