Summary
Natural Language Actor-Critic
- 核心: 把 actor-critic 整体搬进 natural language space——critic 不再吐 scalar Q-value,而是生成对动作的文本式 critique;通过一个 language Bellman backup 让 critic 可以 off-policy 训练,规避 NLRL 必须 in-context 聚合 on-policy rollouts 的瓶颈。
- 方法: critic 作为 language successor model 用 one-step transition + bootstrap 出的下一步未来描述做 TD-style 训练;policy 通过 distill 一个看 critic 输出后产生 refined action 的 refinement policy 来更新;策略与 critic 共享同一个 LLM,通过不同 prompt 区分。
- 结果: 在 Qwen2.5-7B-Instruct / QwQ-32B 上跨 MATH500-Hard、20Q、τ-bench 评测,NLAC 在长 horizon 任务上比 PPO/GRPO/NLRL 提升明显(如 20Q 从 PPO 的 17.2→26.0;τ-retail 0.31→0.42),sample efficiency 也更好;single-step 的 math 任务上和其他方法持平。
- Sources: paper | website | github
- Rating: 2 - Frontier(将 distributional Bellman backup 系统性搬进 language space,解决 NLRL 的 scale 瓶颈,是 agentic-RL 方向当前的前沿 baseline;理论假设偏强、critic 可信度未独立验证,暂不到 Foundation)
Key Takeaways:
- Language Bellman backup 是核心创新: 把 distributional RL 里的分布式 Bellman backup 推广到文本——target 由 “immediate next state + bootstrap 出的 future description” 组合而成,不再需要采样多条完整 rollouts,因此 critic 可以 off-policy 训练。
- Refinement-as-policy-improvement 绕开了离散动作枚举: LLM 动作空间在 token vocab 上是组合爆炸的,无法做传统的 argmax-over-actions。NLAC 直接 distill 一个 “看了 critique 后能修正自己” 的 refinement policy,避免 enumeration。
- 理论上和 successor features 同构: 在 reward 线性可表示 + Bellman backup 在 representation 空间是 discounted sum 的两个假设下,learned 文本 critic 的隐表示恰好收敛到 successor features,从而存在 monotonic mapping 把文本 Q 映射到真 scalar Q,policy iteration 收敛到最优策略。
- NLRL 不 scale 的根因被精准识别: NLRL 把 multiple rollouts 塞进 context 做 in-context 聚合,长 horizon 下 intractable 且 critic 输出几乎全 positive(被 instruction-tuned 模型的 sycophancy 污染);NLAC 用 TD bootstrap 把 horizon 折成 one-step samples 解决了这点。
Teaser. Method overview. 整体训练流程:critic 以 language Bellman backup 在文本空间做 policy evaluation,policy 通过 distill refinement policy 实现 policy improvement。

Background & Motivation
LLM agent 任务(reasoning、tool-use、dialogue)天然是 multi-turn、long-horizon、sparse-reward 的。三类已有思路都有明显短板:
- Policy gradient (PPO/GRPO): 长 horizon 下 credit assignment 差、训练不稳定;scalar reward 把丰富的失败模式压成一个数。
- Scalar actor-critic: critic 学得不好就崩;scalar Q 对 language action space 提供的指导极少——只告诉你 “这步差”,不说 “为什么差、怎么改”。
- NLRL(Feng et al., 2024): 提出在 language space 里做 policy evaluation/improvement,但实现上靠 in-context 聚合多条 on-policy rollouts,长 horizon 不可扩展,至今基本只在 gridworld 一类简单任务上验证过。
NLAC 的判断:language critic 思路对,但必须跳出 in-context aggregation 这个瓶颈,找到一种像 TD learning 那样能 bootstrap 的语言版本。
❓ 笔者的怀疑:作者反复 claim “critique 解释了 why action 不好”,但 critic 和 policy 共用同一个 LLM。如果这个 LLM 本身有错觉、对环境动力学建模错了,critique 就是有自信的胡说。论文没系统报告 critic accuracy,也没和 oracle critic 做对照——见 Weaknesses。
Method
Policy Evaluation in Language Space
定义 language successor model :给定 ,概率性地生成对未来 rollout 及最终 reward 的紧凑文本摘要。这是 critic 的核心承重组件——critic 的最终评价 通过 evaluator 聚合多条 sampled future descriptions 得到(in-context aggregation 在 evaluator 这一步保留,但只在固定的 short prompt 上做,不再 scale 到整条 rollout)。
Equation 1. Language Bellman backup(核心创新)
其中 ,, 是把 immediate next state/action 与 bootstrap 出的 future description 拼接(同时 “discount” future 部分,让 immediate 部分更突出)的 LLM 调用。
含义:本质是 distributional RL 的 distributional Bellman backup 的语言版——用 one-step samples + bootstrapped continuation 构造 target,从而完全 off-policy 可训。
Critic loss 是 reverse KL(保留 future 多样性):
其中 是 EMA target net 参数(防 generative collapse)。
最终的 critique:
实验中 已够。
Policy Improvement via Refinement Distillation
LLM action space 是 ,无法 argmax。Refinement policy 接收 (state, base action, critique),输出 refined action ,期望 ;可迭代 轮。
Policy improvement 目标是把 base policy distill 到 refinement policy:
实验中 也够。整个算法只训练一个共享 LLM,policy / critic / successor / evaluator / refinement 全靠不同 prompt 切换。
Algorithm 1:每 iteration 收 on-policy transition 入 replay buffer,然后从 buffer 采 batch 同时优化 (critic)和 (policy),并 EMA 更新 。
Theoretical Result
在两个假设下:
- A.1: 线性可表示
- A.2: language Bellman backup 在底层 representation 上等价于
可证明 critic 隐表示 收敛到 successor features(Banach 不动点 + γ-contraction),进而存在 monotonic 使 (Theorem 4.5/A.3),policy iteration 收敛到最优策略(Theorem A.4)。
❓ Assumption A.2 是把 “Bellman backup 在文本里如何 compose” 直接抽象成线性递推。这是个很强的隐含约束——LLM 实际拼接 description 时是非线性、有 entropy 的,论文没给出可经验测量这个假设的方法。理论结果更像 sanity check,不是真正预测实证行为的工具。
Experiments
Tasks
- MATH500-Hard: MATH dataset 最难的 500 题;其余 12k 训练。单步任务——对 NLAC 而言只能退化为用 generative reward model 做 self-distillation。
- 20 Questions (20Q): guesser LLM 用 GPT-5 oracle 判断答对,1823 个 THINGS 数据集对象,1000 训练 / 500 测试。多轮对话。
- τ-bench: customer service,dialogue + tool-use 混合,需遵守严格的 policy guidelines。retail 2500 训练 / 500 测试,airline 500 测试(zero-shot generalization)。
Main Results
Table 1. Performance on each benchmark(30,720 gradient steps, 3 runs avg)
| Paradigm | Method | MATH500-Hard | 20Q | τ-Retail | τ-Airline |
|---|---|---|---|---|---|
| Prompting GPT-5 | ReAct | 80.8 | 30.2 | 0.44 | 0.32 |
| Qwen2.5-7B-Instruct | RFT | 49.8 | 12.6 | 0.21 | 0.13 |
| PPO | 52.3 | 17.2 | 0.31 | 0.14 | |
| GRPO | 52.5 | 18.4 | 0.32 | 0.11 | |
| NLRL | 53.4 | 25.8 | 0.25 | 0.16 | |
| Self-Distillation (abl.) | 57.1 | 12.4 | 0.24 | 0.14 | |
| NLQL (abl.) | 56.4 | 24.2 | 0.29 | 0.19 | |
| NLAC (ours) | 56.2 | 26.0 | 0.42 | 0.22 | |
| QwQ-32B | RFT | 69.4 | 22.0 | 0.35 | 0.29 |
| PPO | 73.4 | 24.0 | 0.52 | 0.41 | |
| GRPO | 71.8 | 25.6 | 0.49 | 0.39 | |
| NLRL | 71.5 | 31.8 | 0.44 | 0.31 | |
| Self-Distillation (abl.) | 70.1 | 26.8 | 0.35 | 0.29 | |
| NLQL (abl.) | 71.2 | 31.4 | 0.51 | 0.36 | |
| NLAC (ours) | 72.7 | 32.1 | 0.56 | 0.43 |
关键观察:
- 长 horizon 任务(20Q、τ-bench)NLAC 显著领先;甚至 7B 的 NLAC 在 τ-retail 上接近 GPT-5 ReAct(0.42 vs 0.44)。
- Math 单步任务 NLAC ≈ Self-Distillation(critic 退化为 reward predictor)。
- 7B 上 NLAC > NLRL 提升明显(τ-retail 0.42 vs 0.25);32B 上差距收窄但仍存在。
- Sample efficiency:Figure 4 显示 NLAC 比 PPO 用更少 gradient steps 达到峰值。
Qualitative Examples
Figure 2. 20Q failure mode:base agent 已经把目标缩到 “non-red fruit found in salads”(实际是 raisin),却继续 linear-search “color”——更差的 discriminator。NLAC 的 critic 显式指出该 linear-search 策略次优,refinement policy 改去问 taste/size。

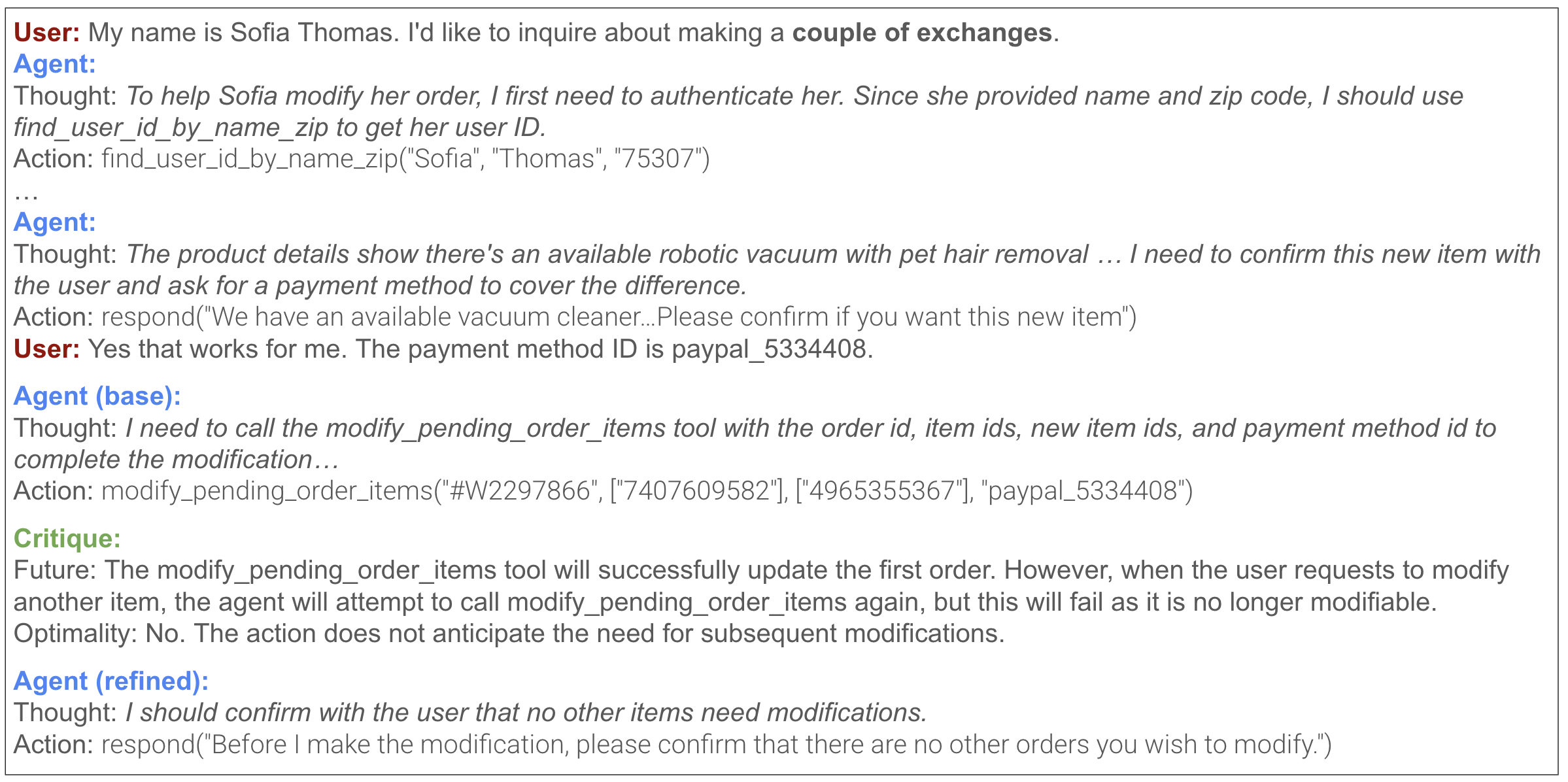
Figure 3. τ-bench failure mode:用户要求 “make a couple of exchanges”,但 policy guideline 限制 database 修改只能一次 tool-call。Base agent 急着 modify 第一件 → 违规。NLAC critic 直接命中是哪条 guideline 被违反,refinement policy 改为先收集所有 exchange 再单次提交。
❓ 所有 qualitative examples 都来自 cherry-picked 成功 case。论文没展示 critic 给出错误诊断时 refinement 是被带偏还是被纠正。这是 evaluator/critic 不准时的关键风险点。
Ablations
- Self-Distillation (refinement on raw rollouts, no critic): 长 horizon 全面下降,证明 learned 紧凑摘要 比塞 raw rollouts 进 context 强。
- NLQL (sample 4 actions, distill highest-sentiment): 比 self-distill 强但不如 refinement——枚举 + reweight 探索动作空间不足。
两个 ablation 共同证明:language successor + refinement-distillation 缺一不可。
关联工作
基于
- NLRL (Feng et al., 2024, “Natural Language Reinforcement Learning”, arXiv:2402.07157): NLAC 的直接前身。NLRL 提出在 language space 做 RL 但靠 in-context aggregation;NLAC 用 language Bellman backup 把这一步换成 TD bootstrap。
- Distributional RL (Bellemare et al., 2017): language Bellman backup 是 distributional Bellman backup 的语言类比。
- Successor Features (Barreto et al., 2017): 理论分析的核心工具。NLAC 证明 critic 隐表示收敛到 successor features。
- SAC (Haarnoja et al., 2018): policy improvement step(distill from refinement policy)形式上类似 SAC 的 policy update。
对比
- PPO / GRPO: 代表性 policy gradient baseline,被 NLAC 在长 horizon 任务上明显超越。
- Reflexion (Shinn et al., 2023): 同样用 self-correction 思路,但纯 prompting + 需要 backtrack;NLAC 的 refinement policy 是 trained 且单次。
- Self-Distillation ablation: 等价于不要 critic 直接 distill from raw-rollout-conditioned policy。
方法相关
- Process Reward Models (Math-Shepherd, OmegaPRM, ReST-MCTS*): 同样想做 step-level 信号;NLAC critic 可视为 language-output PRM。论文未直接对比。
- ReAct prompting (Yao et al., 2022): NLAC 默认用 ReAct prompt 作为 policy 的 action 格式(thought + env action)。
- τ-bench (Yao et al., 2024): customer service 评测平台。
- Distillation from refinement policy: 和 ECoT 等 chain-of-thought 蒸馏思路同源——把 “看推理后再做” 的能力 distill 回 base policy。
论文点评
Strengths
- Problem formulation 切中要害:精准识别了 NLRL 不 scale 的根因(in-context aggregation over on-policy rollouts),并用 distributional Bellman backup 的语言版本这一干净的类比解决——这是典型的 “用对的抽象解决对的问题” 而非堆 trick。
- Sample efficiency claim 有 learning curve 支撑(Figure 4),不只是终态对比;off-policy 训练能复用 replay buffer 在长 horizon 任务上潜力大。
- 理论与实证有对应:把语言 critic 的隐表示与 successor features 挂钩,给出收敛性证明;虽然假设强(A.1/A.2),但提供了一个可检验的 mental model。
- One-LLM-five-roles 的工程简化:policy/critic/successor/evaluator/refinement 全是 prompt 切换的同一个 LLM,避免维护多套权重;与 SAC 等传统 actor-critic 的 multi-net 工程负担相比是显著的简化。
- τ-bench 上 7B 模型逼近 GPT-5 ReAct 是有力的 motivating result——说明长 horizon 任务上 RL 训练 + language critic 真的能弥补模型规模差距。
Weaknesses
- Critic 和 policy 共享 LLM 是双刃剑:方便归方便,但当 base LLM 的世界模型有偏(successor model 想象的 future 不准),critic 会 confidently 给出错误 critique,refinement 跟着错。论文完全没报 critic accuracy,也没做 oracle critic ablation 来 isolate “critique quality” 的影响。
- Assumption A.2(Bellman backup 在 representation 上是 discounted sum)几乎不可验证:是把抽象证明硬塞进 informal 的 LLM 行为里。这种 “证明” 更像 narrative 而非 predictive theory。
- τ-airline 的 zero-shot generalization 提升幅度可疑:retail→airline 的 transfer 上 NLAC(0.43)比 GRPO(0.39)只多 0.04,但 prompting GPT-5(0.32)反而差——是不是 base Qwen/QwQ 已经在 airline 上有更好先验?没做 base 模型 zero-shot 对比就声称 generalization 站不住。
- 数据规模 + 单一 seed 风格:QwQ-32B + 30k gradient steps × 三任务,3 runs 取平均。20Q 上 NLAC 32.1 vs NLRL 31.8 的差距在三 seed std 内大概率不显著——论文没报 std。
- NLRL 被故意 cap 在 4 个 in-context rollouts “for tractability”,但作者自己强调 NLAC “effectively 看到 4× 更少 samples”——这是把 NLRL 推到不利配置,公平性需打折。
- Catastrophic forgetting 被 “we trained in low-data regimes” 一笔带过:scaling 到大数据 / 多任务的现实场景下这是核心问题,附录的 mitigation 是事后补丁。
- 没和最近 process reward model(PRM)类工作对比:NLAC 自己说 critic 可看作 PRM,但 baseline 里完全没 OmegaPRM、ReST-MCTS、Math-Shepherd 等。
- “Refinement policy 由 base reasoning capabilities 驱动” 默认了 base LLM 的 self-correction 能力——这恰是已知的脆弱能力(Huang et al. 2024 论证 LLM 不能可靠 self-correct)。这个 dependency 没讨论清楚。
可信评估
Artifact 可获取性
- 代码: 已开源(github.com/jxihong/nlac),README 说明 codebase 包含 NLAC 实现;具体训练 script 完整性需 clone 验证。
- 模型权重: 未说明是否发布 checkpoint。
- 训练细节: 仅高层描述(30,720 gradient steps、3 runs、、EMA target);prompts 和具体超参指向 Appendix B,未在主文阐述完整。
- 数据集: 全部公开(MATH、THINGS for 20Q、τ-bench retail/airline);oracle 是 GPT-5。
Claim 可验证性
- ✅ NLAC > PPO/GRPO/NLRL on long-horizon tasks:Table 1 实测,3 runs 平均;7B 上提升幅度足够明显(不太可能纯 noise)。
- ✅ Sample efficiency:Figure 4 提供 learning curve。
- ⚠️ “Critic explains why an action is suboptimal”:仅靠 cherry-picked qualitative examples(Fig 2/3),无 critic accuracy / faithfulness 量化。
- ⚠️ Convergence to optimal policy(Theorem A.4):依赖 A.1 + A.2 两个不可经验测量的假设;属于 “在抽象空间内自洽” 的结果,对实际系统的预测力有限。
- ⚠️ Generalization to airline:只比一个 retail-trained 的 baseline 对比,缺 base-model zero-shot 控制组。
- ⚠️ NLRL 对比公平性:刻意限制 NLRL 在 4 in-context rollouts,结论 “NLRL 在 τ-bench 弱” 应解读为 “在该资源配置下”。
- ❌ 暂无明显的纯 marketing 修辞——claim 普遍 hedged。
Notes
- 论文的核心 selling point 不是 architecture 而是 “把 distributional RL 的 trick 翻译进 language space”——这种类比能力本身值得 internalize:以后遇到 “X 在 scalar 空间能做但 language 不行” 的情形,可优先尝试 distributional / TD-style 改造。
- Refinement policy 的 quality 完全寄托在 base LLM 的 self-correction 能力。Huang et al. 2024 (ICLR) 的 “Large Language Models Cannot Self-Correct Reasoning Yet” 直接挑战这个 dependency——值得读完两篇做交叉验证。
- 对我自己的研究:Agentic RL 方向上,NLAC 的 “off-policy + language critic” 是个值得 borrow 的 ingredient,特别是在 GUI agent / computer-use 这类长 horizon、reward 稀疏、动作空间 combinatorial 的场景。但需先回答:critic 如何在没有 oracle reward 的部分可观测环境里 ground truth?论文里 reward 还是 binary success——真实任务里这个假设会破。
- 一个延伸 idea:能否把 language successor model 单独拿出来做 world model 用?文本式的 next-state prediction 本身就是 world model 接口,配合 planning 算法(MCTS over text states)可能比单纯 actor-critic 更强。
Rating
Metrics (as of 2026-04-24): citation=4, influential=0 (0.0%), velocity=0.87/mo; HF upvotes=N/A; github 3⭐ / forks=0 / 90d commits=0 / pushed 106d ago
分数:2 - Frontier 理由:NLAC 在 agentic-RL 方向上是当前前沿的方法级贡献——Strengths 已确认它精准定位了 NLRL 的 scale 瓶颈并用 distributional Bellman backup 的语言版本干净解决,τ-retail 上 7B 逼近 GPT-5 ReAct 的数值也支撑其作为必须对比的 baseline;但它距 Foundation 还差两步:(1) 方法刚发布(2025-12),社区采纳度尚未沉淀,暂未被主要后续工作作为 de facto baseline;(2) Weaknesses 中的 critic 可信度未独立验证、A.2 假设不可经验测量、NLRL 对比被 cap 在不利配置,这些未解风险使它暂不具备 “必读必引奠基工作” 的地位。不到 Archived 档则因为它不是 incremental,而是有清晰方法学 pivot 的代表工作。2026-04 复核:4.6 月 4 citation / 影响力 0 / github 仅 3⭐ / 近 90 天无提交,社区采纳信号偏弱;但 framing 与方法贡献(language Bellman backup)在 agentic-RL 方向仍有 indexed 参考价值,暂维持 Frontier,后续若继续无采纳则考虑降至 Archived。