Summary
Agent Lightning: Train ANY AI Agents with Reinforcement Learning
- 核心: 通过把 agent 执行抽象为 MDP + 用 transition 而非 concatenated trajectory 组织数据,实现 RL 训练框架与任意 agent 框架(LangChain / OpenAI Agents SDK / AutoGen / from-scratch)之间的完全解耦,几乎零代码修改地训练 agent。
- 方法: (1) Unified data interface,把执行抽象为 (input, output, reward) 的 transition 序列;(2) LightningRL,分层 RL:episode-level return 通过 credit assignment 分给每个 action,再用普通单轮 RL(GRPO/PPO/REINFORCE++)做 token-level 优化;(3) Training-Agent Disaggregation:Lightning Server 管 RL 训练并暴露 OpenAI-like API,Lightning Client 在客户端跑 agent 并用 OpenTelemetry 自动 trace。
- 结果: Spider (text-to-SQL, LangChain, 多 agent 选择性优化)、MuSiQue (RAG, OpenAI Agents SDK)、Calc-X (math+tool, AutoGen) 三个任务上 Llama-3.2-3B-Instruct 训练 reward 均稳定上升。
- Sources: paper | website | github
- Rating: 2 - Frontier(system-level decoupling 抽象扎实且已获 ecosystem adoption,但 algorithm contribution 薄、缺关键对比实验,未到 Foundation 档)
Key Takeaways:
- Decoupling 是核心 contribution,不是算法: 这篇真正有价值的是 system design——观察到 “RL framework 必须了解 agent 执行逻辑” 这个限制其实可以打破,做法是把 trajectory 拆成独立 transition 喂回 single-turn RL。算法(LightningRL)本身只是 episode return 平均分给所有 action,故意保持简单。
- Transition-based 优于 concatenation+masking: 主流 multi-turn RL(RAGEN/Search-R1/Trinity-RFT/rLLM)把多轮对话拼成一个长序列再用 mask 选优化区域。Agent Lightning 把每次 LLM call 当独立样本,避免了 (a) RoPE 位置编码不连续;(b) 累积 context 导致超长序列;(c) 复杂 mask 实现。代价是 inter-turn dependency 信息被丢弃。
- OpenTelemetry 接入 RL 是个好抽象: 既然 agent 已有完整 observability 基础设施(trace/span),就用它做 trajectory collection。这避免了在 agent 代码里插桩,是 “almost zero code change” claim 的工程基础。
- MDP 形式化的语义: 把每次 LLM 调用整体当作一个 action(一个 token sequence),把 LLM-visible 的 input 当作 observation,agent 内部所有变量是 hidden state(POMDP)。multi-LLM 同一系统理论上需要 MARL,但论文实现用了 “selective transition extraction” 的简化做法。
Teaser. Agent Lightning overview.
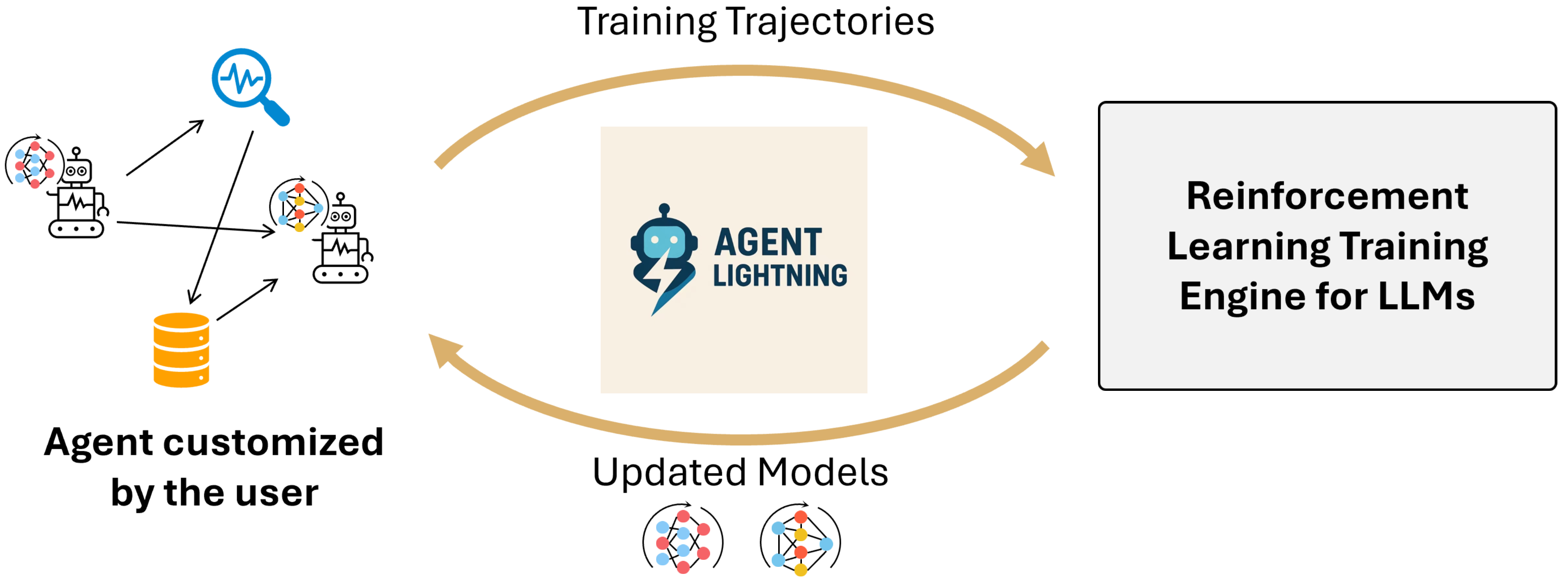
Motivation 与问题定位
LLM agent 在真实场景(complex coding workflow / private domain / unfamiliar tools)依赖 prompt engineering 难以稳定可靠地完成任务,需要在 deployment context 里 fine-tune 模型。RL 比 SL 更适合 agent:依赖 outcome reward,不需要 step-by-step 标注。但把 RL 应用到 agent 有两个 gap:
- Algorithm gap: 现有 RL for LLM 主要面向 single-call task(preference alignment, math reasoning),不处理 multi-LLM-call、tool interaction。
- System gap: 现有 RL 框架(verl / OpenRLHF / TRL)需要把 agent 重写进训练系统内,因为训练侧需要知道 agent 执行逻辑才能正确组织数据(concatenation order、mask 位置)。但真实 agent 用 LangChain / OpenAI Agents SDK / AutoGen / 各种 from-scratch 实现,迁移成本极高。
❓ 这里有个隐含假设:agent 开发者愿意把训练后的模型权重再部署回原 framework。如果 framework 本身有自己的 inference engine 限制(比如某些 SDK 强绑定特定模型 API),decoupling 训练侧并不能解决部署侧的耦合。
3.1 Unified Data Interface
State / Call / Semantic Variable
把 agent 执行抽象为 DAG(节点是 component invocation,边是 dependency)。但完整解析 DAG 是 unnecessary——只需识别 state 和 transition:
Equation 1. State as semantic variables.
State 是 agent execution 的快照:program counter、变量值、call stack、resource context 抽象为一组 semantic variable(程序意图变量,区别于 for loop counter 之类的中间变量;术语借自 Parrot)。
Equation 2-3. Execution as call sequence.
Component (LLM 集合 ∪ Tool 集合)。meta 包含 component name/type/version/endpoint、采样温度等。
Reward
每个执行的 trajectory 附带 reward sequence 。可以是 intermediate(tool 调用成功与否)或仅 terminal 。
Illustrative Example: RAG Agent
Figure 2. Unified data interface 示意(左:执行流;右:trajectory 收集)。
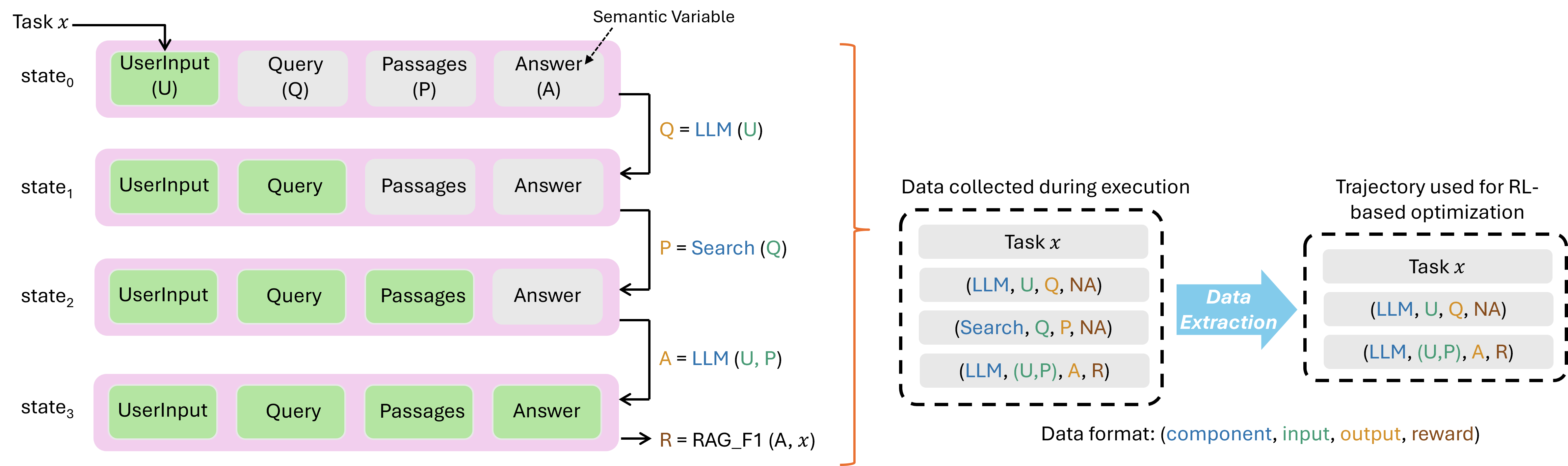
RAG agent 包含 LLM 和 Search tool。执行流:
- User 提交 question (UserInput)
- LLM 生成 search query (Query),conditioned on UserInput
- Search tool 用 Query 检索得到 Passages
- LLM 用 Passages + UserInput 生成 Answer
每个 state 用 4 个 semantic variable 描述(绿框=已赋值,灰框=未赋值)。LLM 第一次调用只能看到 UserInput,第二次能看到 UserInput + Passages。
这个抽象的关键 trade-off:用 transition 替代 DAG 简化了 RL 数据组织,但丢弃了 inter-call 的依赖信息。在简单 sequential agent 上没问题,但对复杂 dependency(比如多个 parallel LLM call 然后 merge)能否还原训练信号是开放问题。
3.2 MDP Formulation
把 agent 内单个 LLM 当 policy,formalize 为 POMDP :
- :所有 agent state
- :所有可能的 LLM 输入(observation = LLM-visible 部分的 state)
- :整个 token sequence 当作一个 action——这是 LightningRL 与传统 token-level RL 的关键区别
- :state transition dynamics(unknown)
- :reward function
Data Extraction for RL:
只保留 LLM call 的 raw input/output/reward——其他执行细节(template rendering、parsing、其他 tool 内部逻辑)全部 abstract 掉。这是 “RL training 不需要知道 agent 执行逻辑” 的关键 trick。
Multi-Agent Extension
- Single-LLM 多 agent: 一个 LLM 通过不同 prompt 扮演多个 role(如 RAG 例子里 query 生成 vs 答案生成)。Agent Lightning 通过选择性提取 transition 实现 selective optimization——比 mask-based 方法更直观。
- Multi-LLM: 论文承认理想是 MARL,但实现上简单地把每个 LLM 当独立 MDP。
3.3 LightningRL: Hierarchical RL Algorithm
与现有 multi-turn RL 的对比
Figure 3. LightningRL vs single-call GRPO vs concatenation-based multi-turn GRPO.
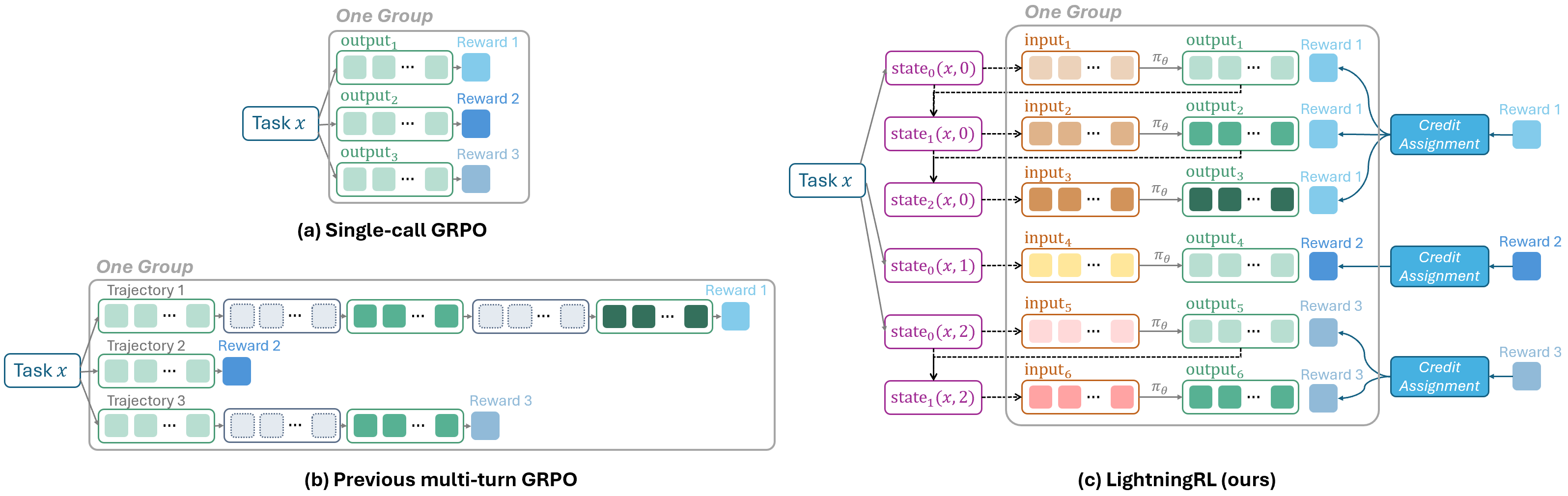
- (a) Single-call GRPO: 同一 prompt 的 N 个 response 一组,计算 advantage。
- (b) Concatenation-based multi-turn GRPO (RAGEN/Search-R1/Trinity-RFT 等):把整条 trajectory 拼成一个长序列,非 LLM 生成的 token(tool output)用 mask 屏蔽。
- (c) LightningRL: 把 trajectory 拆成独立 transition ,同 task 的所有 transition 分到一组算 advantage。
两步分层
- Episode-level → action-level credit assignment: 当前实现简单:每个 action 的 value = final return (identical assignment)。论文承认可以扩展到 learned value function 等更复杂方案。
- Action-level → token-level: 完全用现有 single-turn RL 算法(GRPO/PPO/REINFORCE++)处理,每个 transition 当一个独立的 (prompt, response, reward) 样本。
Token-level loss 沿用单轮 RL:
论文声称的优势 vs concatenation+masking
- 直接复用任何 single-turn RL 算法,无需修改
- 灵活的 observation 构造: 可以是 summary、structured prompt、role instruction,不必是 raw concatenated history
- 不破坏 RoPE 位置连续性: masking 在长序列里制造 “空洞”,干扰 RoPE 假设
- 缓解 context 长度爆炸: transition 单独成样本,不需要把所有 turn 拼起来
- 为 hierarchical RL 等更复杂算法留空间
这里 claim 4 实际是 trade-off 而非 pure win:拆 transition 也意味着失去 cross-turn context(每个 transition 只能看自己的 input),如果 inter-turn 依赖很强,可能需要把历史 summary 显式加进 input——这又把 context 长度问题转移到 prompt construction 侧。
3.4 System Design
Training-Agent Disaggregation
Figure 4. Training-Agent Disaggregation architecture.
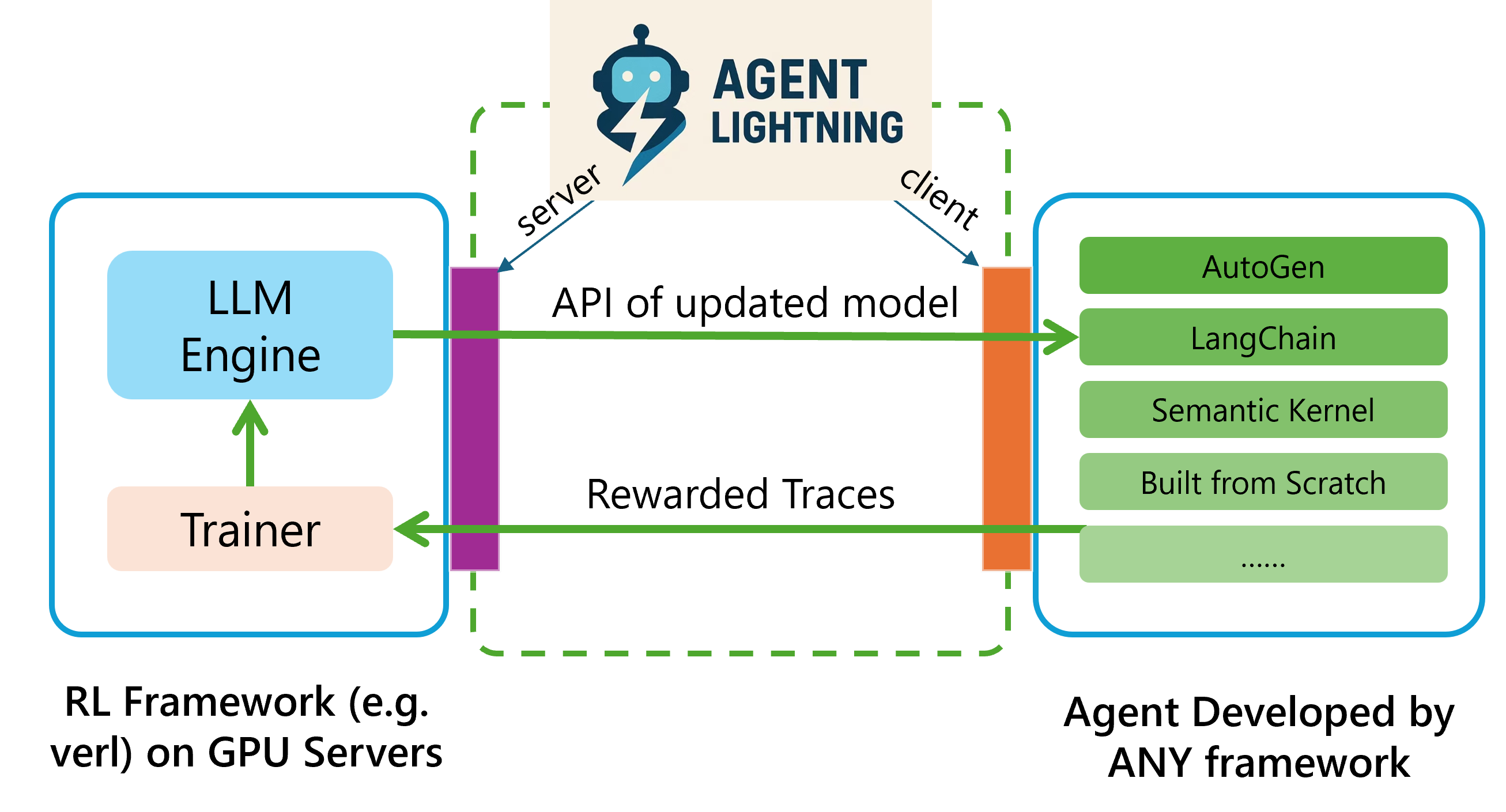
核心 insight: RL 训练框架的两个组件——trainer(更新模型权重,compute-intensive)和 rollout(生成 trajectory)——可以物理 / 逻辑上完全分离。
- Lightning Server (训练侧): 跟 verl 等 RL framework 集成,管 LLM 优化、硬件资源、暴露 OpenAI-like API。Agent-agnostic——不知道 agent 长什么样。
- Lightning Client (agent 侧): 跑 agent runtime,可以放在任何机器上,不需要跟 GPU collocate。Trainer-agnostic——不知道训练框架是什么。
执行流: server 把 task batch + 一个 unique OpenAI-like API endpoint 推给 client → client 跑 agent (agent 内部的 LLM call 走这个 endpoint) → trace + reward 回传 server → server 转给 RL framework 更新权重。
Agent Runtime(Lightning Client)
四个核心机制:
- Data Parallelism: 两级并行——intra-node(一个 client 多 worker)+ inter-node(多 client)。RL training 需要大 batch 来填满 GPU,agent rollout 是瓶颈。
- Data Capture without Code Modification: 两种 instrumentation——
- 基于 OpenTelemetry + AgentOps 的自动 trace(推荐)
- 嵌在 OpenAI-like API endpoint 里的轻量 fallback tracing
- Error Handling: agent crash / network 中断 / invalid output / hanging tool call。RL 由于 exploration 比 inference error 频率高得多,需要主动 retry / reassign。
- Automatic Intermediate Rewarding (AIR): 把系统监控信号(tool call 返回状态)转成 intermediate reward,缓解 sparse reward。
Environment / Reward 服务化
轻量的 env / reward function 直接跑在 agent worker 内;重资源的(mobile emulator、复杂 reward 计算)做成 shared service。
4 Experiments
三个任务对应三种 agent framework,全部用 Llama-3.2-3B-Instruct 作 base model:
Table 1. 实验任务总览。
| Task | Text-to-SQL | Open-Domain QA | Math QA |
|---|---|---|---|
| Framework | LangChain | OpenAI Agents SDK | AutoGen |
| Dataset | Spider | MuSiQue | Calc-X |
| Tool | SQL executor | Wikipedia retriever | Calculator |
| # agents | 3 | 1 | 1 |
| # tuned agents | 2 | 1 | 1 |
4.1 Text-to-SQL (LangChain)
Spider 数据集,3-agent workflow:SQL writer → executor → checker (rewrite or answer)。SQL 生成、checking、re-writing 由同一 LLM 用不同 prompt 扮演(典型 single-LLM multi-agent)。只优化 writer 和 re-writer 两个 agent——展示 selective optimization。Reward 是最终答案正确性。
Figure 5. Spider 训练 reward 曲线。
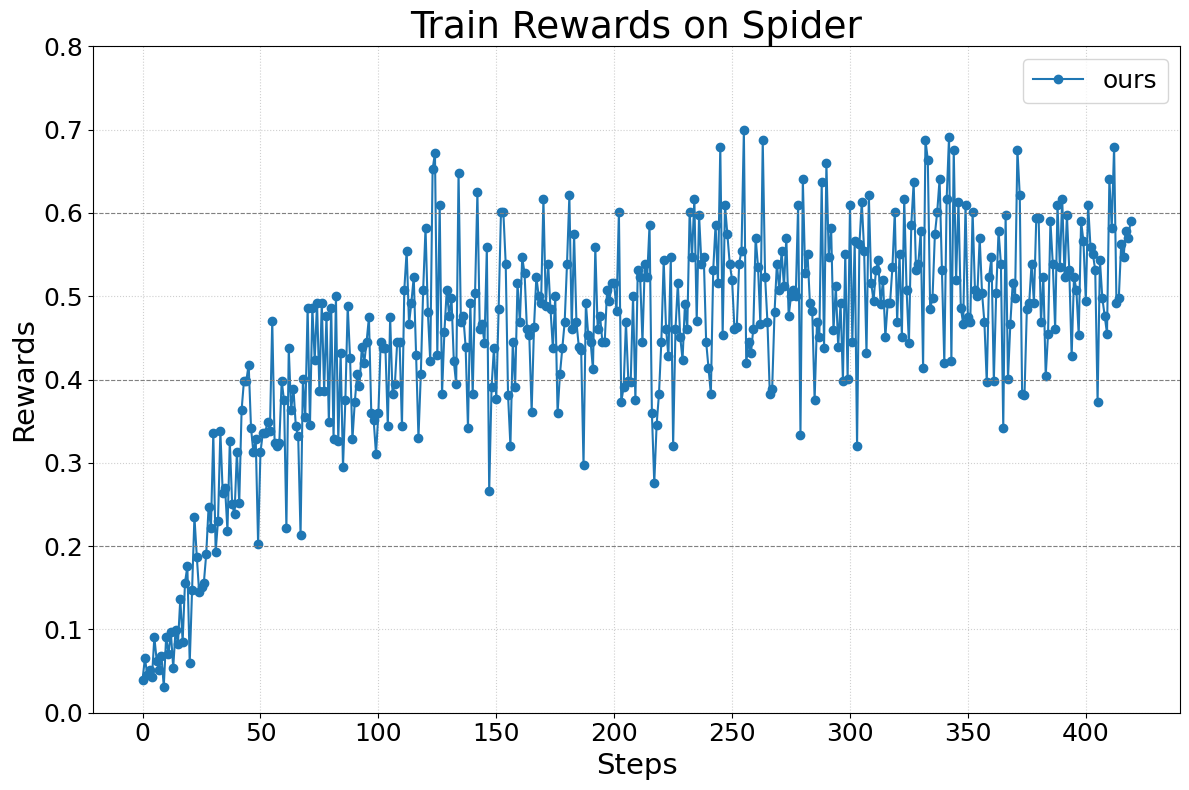
4.2 RAG via OpenAI Agents SDK
MuSiQue(multi-hop QA),BGE retriever 在 21M 文档(整个 Wikipedia)上检索。单 agent,single LLM 决定 query refine vs 答题。Reward:
format reward 检查 <think>...</think>、<query>...</query>、<answer>...</answer> 标签。
Figure 6. MuSiQue 训练 reward 曲线。
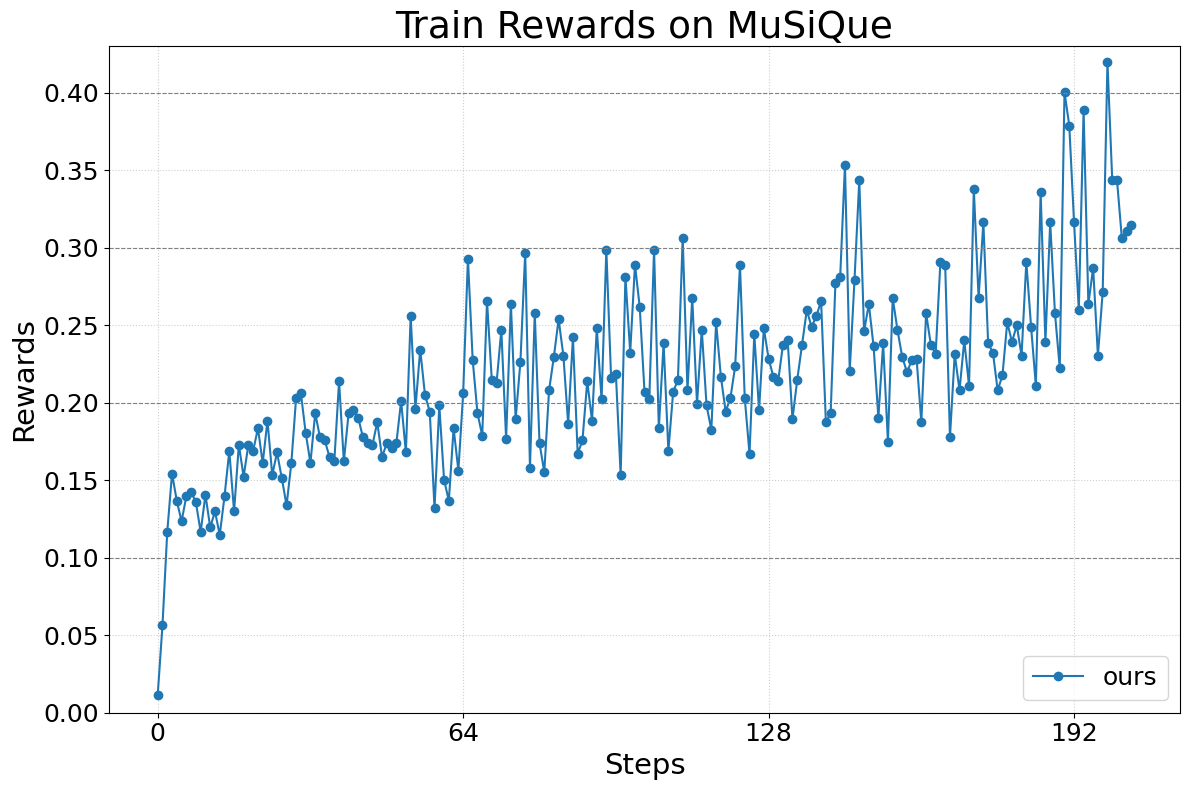
4.3 Math QA + Tool via AutoGen
Calc-X 数据集(在 GSM8K / Ape210K 基础上加入 calculator tool)。单 LLM workflow,决定何时 invoke calculator。Reward:最终答案正确性。
Figure 7. Calc-X 训练 reward 曲线。
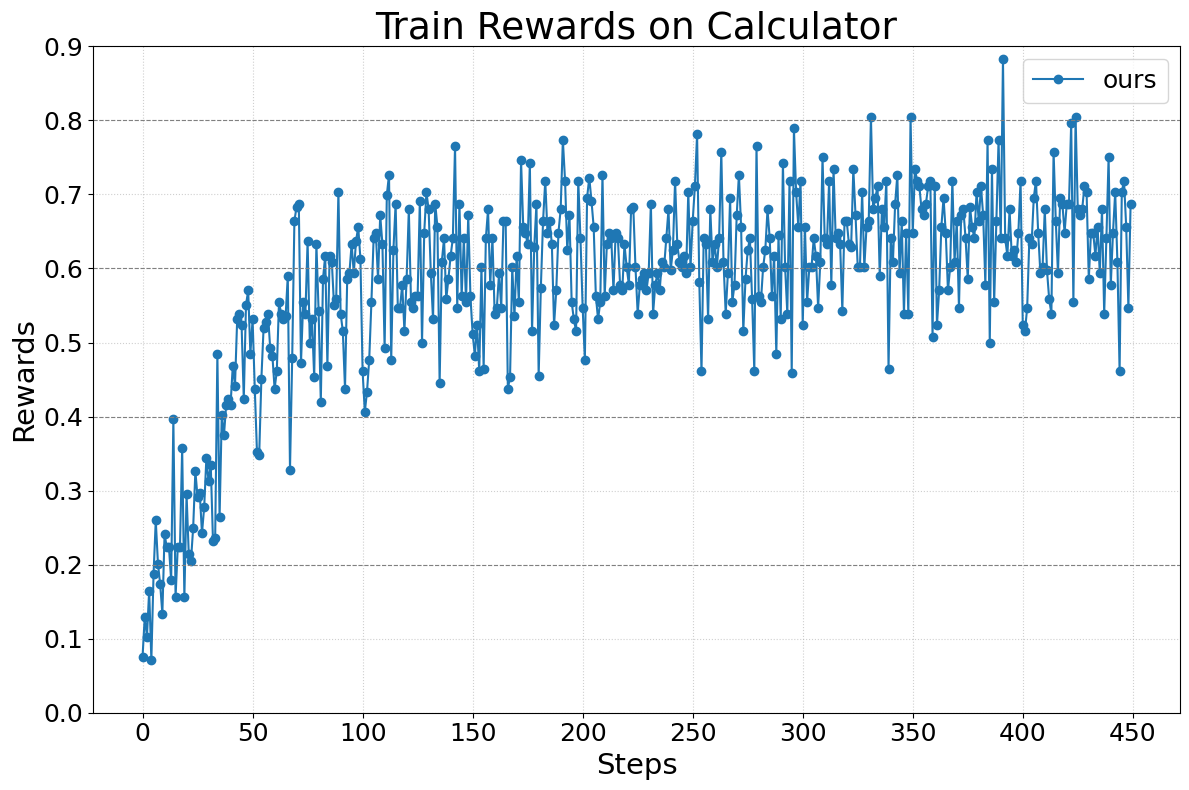
实验整体评价
⚠️ 三个实验 figure 都只有 train reward 曲线,无 test set accuracy、无 baseline 对比(也没有跟 concatenation-based multi-turn RL 直接比较)。所以这些实验只能证明 “框架能跑且 reward 单调上升”,不能证明 LightningRL 比其他方法更好。论文主要 contribution 是 system design,但缺乏 ablation 让人无法判断 transition decomposition 相对 concatenation+masking 的真实差距。
5 Future Work
- Component of Interest (CoI): 把可优化范围扩展到 prompt template(当作一种 tool call 来 trace),支持 prompt optimization 等非 RL 方法。
- More sophisticated credit assignment: 现在是 identical assignment,未来可加 high-level value function。
- Long-horizon credit assignment / off-policy / exploration 等算法改进。
- 进一步系统级 disaggregation: 把 trainer / rollout (inference engine) / agent workflow 三者分离。
关联工作
基于
- Parrot (OSDI’24): 提供了 “Semantic Variable” 概念,Agent Lightning 直接复用来定义 state。
- OpenTelemetry / AgentOps: 提供 agent observability infrastructure,被 reuse 做 trajectory collection。
- verl / HybridFlow: 主要集成的底层 RL training framework。
对比 (Multi-turn RL frameworks,concatenation+masking 路线)
- RAGEN: multi-turn interactive env 的 RL,concatenation-based。
- Search-R1: 训练 LLM 用 search tool,single-task 专用 RL。
- Trinity-RFT: general-purpose RFT framework,也基于 concatenation。
- rLLM: post-training language agent framework。
- SkyRL-v0: 长 horizon agent RL,需要在框架内重写 agent。
对比 (Large-scale RL training systems)
- OpenRLHF / TRL / ROLL / AReaL: 主要面向 single-turn LLM training,agent 扩展需要重写 agent 进训练系统。
方法相关
- GRPO (DeepSeekMath): LightningRL 默认 backbone,每 task 多 sample 算 advantage。
- PPO / REINFORCE++: 也兼容。
- ArCher: hierarchical multi-turn RL,credit assignment 思路相近,但参数规模小(< 1B)。
- DeepSeek-R1 / Kimi k1.5: 启发了 “用 outcome reward 做 RL” 的可行性。
应用对比
- DeepSWE / ReTool / SimpleTIR / R1-Searcher: 任务专用 agent RL,与 Agent Lightning 通用 framework 的定位互补。
论文点评
Strengths
- System-level insight 扎实: “RL framework 不需要知道 agent 执行细节” 这个 decoupling 主张,加上把 OpenTelemetry 接入 RL training 这个具体路径,是有价值的工程贡献。GitHub 上能见到的 ecosystem adoption(Tencent Youtu-Agent 用它做 128-GPU 训练,Tinker × Agent Lightning 教程,AgentFlow,DeepWerewolf)说明 framework 抽象选对了。
- Transition-based 数据组织角度新颖: 相比 concatenation+masking 主流路线,这是一个干净的替代方案。论文对 RoPE 位置编码连续性、mask 实现复杂度的批评是中肯的。
- Selective optimization 的演示: 在 Spider 任务里展示了 multi-agent 系统中只优化部分 agent 的能力,这是 mask-based 方法很难干净做到的。
- 零代码修改的 claim 实际兑现: Appendix A 的代码示例确实只新增了一个
train.py,agent 本身代码不动。这对实际开发者吸引力很大。
Weaknesses
- Algorithm contribution 薄: LightningRL 的 credit assignment 就是 “每个 action 都赋 final return”,本质上跟 GRPO 在 trajectory 级别的处理几乎等价。论文坦诚承认了这点,但相应的是 algorithm 部分的实验完全没有 ablation 来验证 transition-based 是否真的优于 concatenation。
- 缺乏对比实验: 三个实验都只展示 reward 曲线上升,没有跟 RAGEN / Search-R1 / Trinity-RFT / rLLM 等 concatenation-based 方法在同一任务上比较。“我们的方法更通用” 是否换来了 “性能下降” 完全不清楚。
- 缺失关键 metric: 没有 test accuracy、wall-clock training time、GPU utilization 等系统侧 metric。Decoupling 必然有通信开销(agent 跨网络调用 server LLM endpoint),这个 cost 论文完全没量化。
- Multi-LLM 处理是 limitation: 论文承认多 LLM 联合优化时只是把每个 LLM 当独立 MDP,没有 MARL 处理。在真正复杂的 multi-agent 系统(agent 之间有协作/竞争)这是个未解决的问题。
- AIR 机制没有实验验证: Automatic Intermediate Rewarding 在 system 部分被着重介绍,但三个实验任务都只用了 terminal reward,AIR 的实际效果完全没展示。
可信评估
Artifact 可获取性
- 代码: 完全开源(microsoft/agent-lightning,MIT 许可,PyPI
pip install agentlightning)。包含 server / client / 多个 example agent。 - 模型权重: 未发布训练后 checkpoint(base 是公开的 Llama-3.2-3B-Instruct)。
- 训练细节: 论文正文未披露超参 / 训练步数 / batch size 等关键信息(仅说明 base model 与数据集);GitHub 仓库的 examples 可能补充。
- 数据集: 全部公开(Spider / MuSiQue / Calc-X),均已知论文。
Claim 可验证性
- ✅ 零代码修改集成 LangChain/OpenAI Agents SDK/AutoGen:Appendix A 代码 + GitHub examples 可验证。
- ✅ Selective optimization in multi-agent:Spider 实验直接展示了只优化 2/3 agent。
- ⚠️ “训练 reward 稳定上升”:曲线确实单调,但单实验、无 seed 变化、无 test accuracy,stability claim 打折。
- ⚠️ “Transition-based 优于 concatenation+masking”:论文给出理论论证(RoPE 连续性、context 长度、mask 复杂度),但无 head-to-head 实验对比,纯论证可信度有限。
- ⚠️ “Trainer-agnostic”:论文只演示了与 verl 集成,对其他 RL framework(OpenRLHF / TRL / AReaL)的兼容性未实测。
- ❌ “Train ANY AI agent” / “ZERO code change”:标题里的 “ANY” 和 “ZERO” 是营销修辞,正文承认 “almost zero”,且 multi-LLM 联合优化、复杂依赖关系等场景都是 limitation。
Notes
- 这篇 paper 的实际价值不在 algorithm(LightningRL 几乎是最简单的 credit assignment),而在 system abstraction:把 OpenTelemetry trace 当 RL trajectory 来用、把 trainer 和 rollout 物理分离、用 OpenAI-like API 做 contract。这套抽象让任何已有 agent 都能 RL 化,是 ecosystem-friendly 的设计。
- 对 RAGEN 这类 concatenation-based 方法的批评(RoPE 不连续、mask 复杂、context 累积)是有道理的,但论文回避了 transition decomposition 的 trade-off:丢失了 cross-turn 的 implicit reasoning 信号。如果一个 agent 的多轮 LLM call 之间存在强依赖(比如后续 call 需要参考前面 call 的中间推理过程而不仅是输出),transition-based 训练相当于强迫 LLM 在每个 transition 内 self-contained,这可能限制学习到 long-horizon planning 能力。
- AIR (Automatic Intermediate Rewarding) 是个有潜力的方向但论文里几乎没展开——把 OpenTelemetry span 的 attributes(如 tool 是否成功、retry 次数、latency)做成 reward signal,理论上能极大缓解 sparse reward 问题。值得后续单独研究。
- 实验只用 Llama-3.2-3B-Instruct 这种小模型,且没汇报 vs 更强 baseline (如 Qwen2.5-7B) 的迁移性。“任何 agent” 在小模型上 work 不代表在 7B+ 上还有显著 gain。
- Connection to my agenda: framework 层面对 RAGEN / Search-R1 是直接竞争品;对 GUI agent / VLA 这类含视觉 modality 的 agent,能否套用 Agent Lightning 的 OpenAI-like API + transition 抽象是开放问题(需要 multimodal endpoint 和 image trace)。
Rating
Metrics (as of 2026-04-24): citation=30, influential=6 (20.0%), velocity=3.49/mo; HF upvotes=141; github 17004⭐ / forks=1487 / 90d commits=7 / pushed 21d ago
分数:2 - Frontier 理由:Strengths 里的 “system-level decoupling + OpenTelemetry-as-trajectory 抽象扎实、已获 Tencent Youtu-Agent / Tinker / AgentFlow 等 ecosystem adoption” 让它高于 Archived 档——是当前 agentic RL 框架赛道上必须对比的 baseline 之一。但够不到 Foundation:Weaknesses 指出 algorithm contribution 薄(credit assignment 就是 identical final return)、无 head-to-head 对比 concatenation+masking 路线、缺 test accuracy / 通信开销等关键 metric,尚未成为 de facto 标准,且赛道仍在快速演化(RAGEN / rLLM / SkyRL 等并行竞争),尚未被时间验证为必读奠基。