Publications
* Equal contribution, ✉ Corresponding author
2025










2024














2023




2022
- Close the Loop of Neural Perception, Grammar Parsing, and Symbolic ReasoningUniversity of California, Los Angeles, 2022
2021





2020


2019


2018



2017
-
 Learning Hierarchical Video Representation for Action RecognitionInternational Journal of Multimedia Information Retrieval, 2017
Learning Hierarchical Video Representation for Action RecognitionInternational Journal of Multimedia Information Retrieval, 2017

2016
-
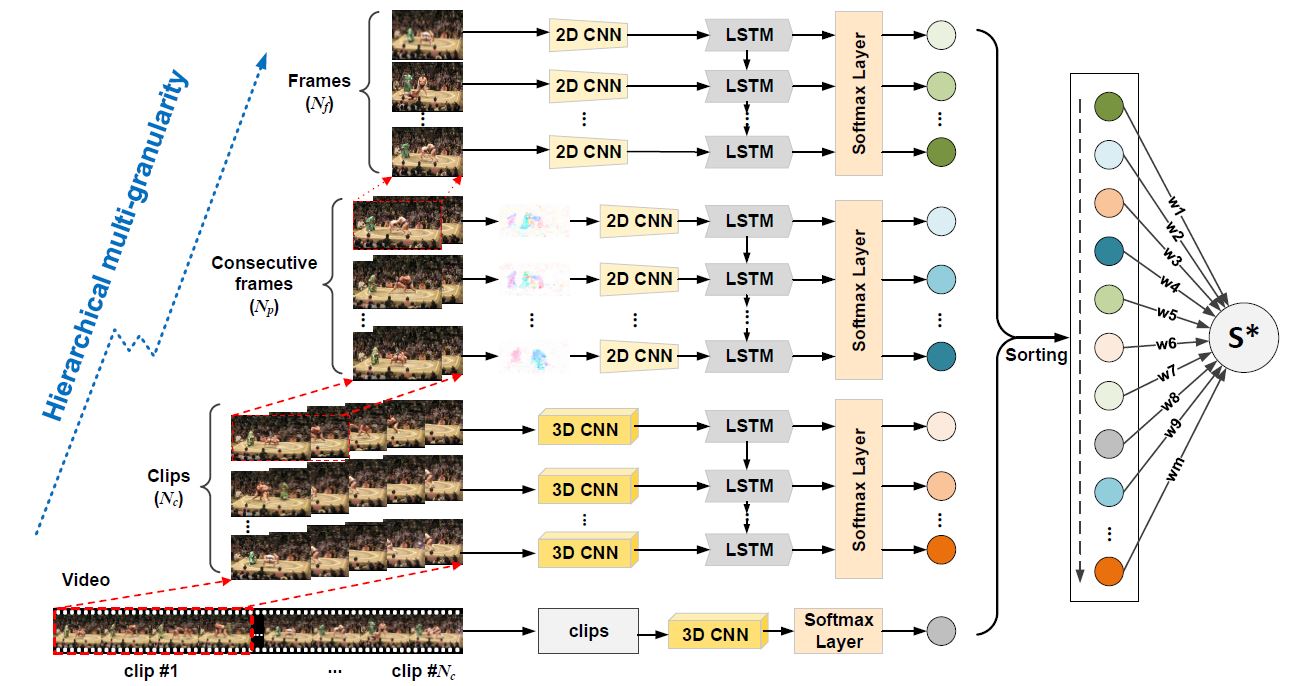 Action Recognition by Learning Deep Multi-Granular Spatio-Temporal Video Representation Best Paper FinalistInternational Conference on Multimedia Retrieval, 2016
Action Recognition by Learning Deep Multi-Granular Spatio-Temporal Video Representation Best Paper FinalistInternational Conference on Multimedia Retrieval, 2016
