
Qing Li 李庆
Email: dylan.liqing[at]gmail[dot]com
I am a research scientist and team lead at Beijing Institute for General Artificial Intelligence (BIGAI), China. I received my Ph.D. in 2022 from University of California, Los Angeles (UCLA), advised by Professor Song-Chun Zhu. During my Ph.D., I have interned at Google Research, Microsoft Azure AI and Amazon Alexa. Before UCLA, I obtained my degrees of Bachelor in 2015 and Master in 2018 from University of Science and Technology of China (USTC).
Currently, I focus on developing language agents for general computer use via agentic RL.
News
| 2025-09 | Three papers are accepted by NeurIPS 2025! Check out these works: SPORT Agent, Anywhere3D, and NEP. |
|---|---|
| 2025-06 | Two papers are accepted by ICCV 2025! Check out these works: MTU3D (receiving perfect review scores) and Embodied VideoAgent. |
| 2025-04 | I am invited as an Area Chair for NeurIPS 2025. |
| 2025-03 | Two papers are accepted by CVPR 2025! |
| 2025-01 | Two papers are accepted by ICLR 2025! Check out these awesome works: Multimodal Knowledge Editing and Multimodal Agent Tuning (Spotlight). |
Selected Publications
* Equal contribution, ✉ Corresponding author
-
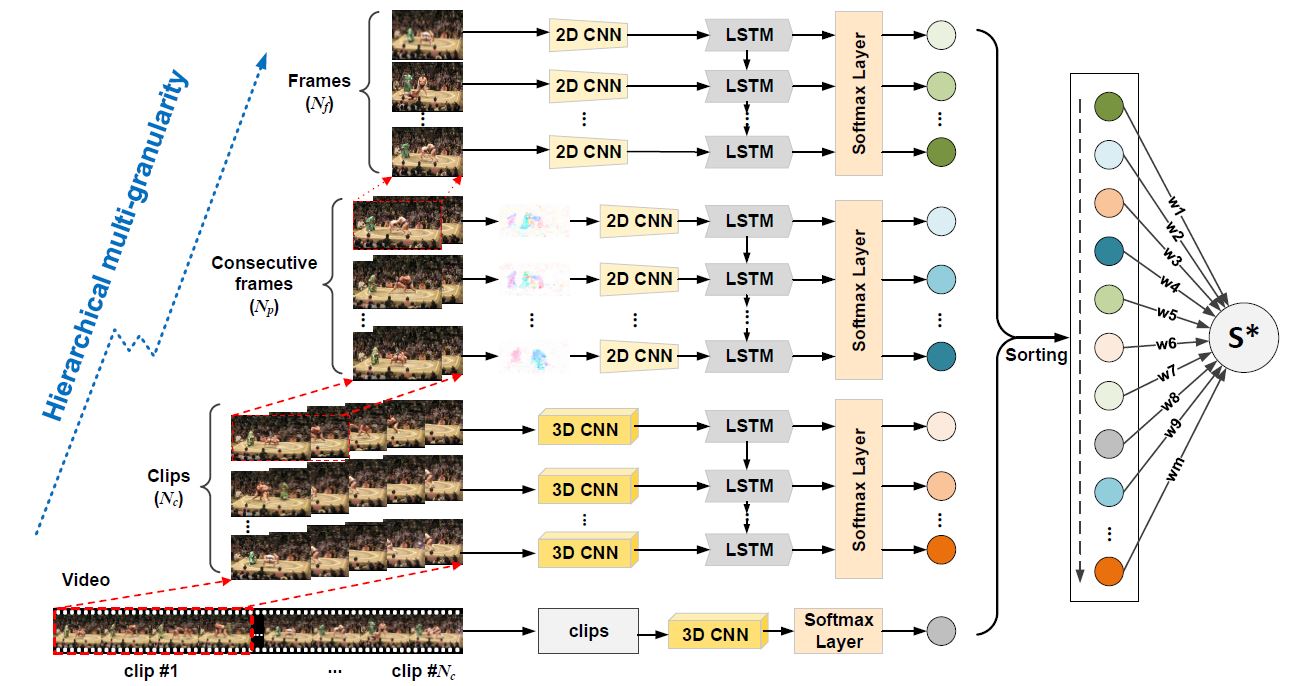 Action Recognition by Learning Deep Multi-Granular Spatio-Temporal Video Representation Best Paper FinalistInternational Conference on Multimedia Retrieval, 2016
Action Recognition by Learning Deep Multi-Granular Spatio-Temporal Video Representation Best Paper FinalistInternational Conference on Multimedia Retrieval, 2016



































